
 |  |
Chapter 5. Internationalization
Contents:
Character-Set Metadata
The Encoding Declaration
Text Declarations
XML-Defined Character Sets
Unicode
ISO Character Sets
Platform-Dependent Character Sets
Converting Between Character Sets
The Default Character Set for XML Documents
Character References
xml:lang
We've told
you that XML documents contain text, but we haven't
yet told you what kind of text they contain. In this chapter we
rectify that omission. XML documents contain Unicode text. Unicode is a character
set large enough to include all the world's living
languages and a few dead ones. It can be written in a variety of
encodings, including UCS-2 and the ASCII superset UTF-8. However,
since Unicode text editors are relatively uncommon, XML documents may
also be written in other character sets and encodings, which are
converted to Unicode when the document is parsed. The encoding
declaration specifies which character set a document uses. You can
use character references, such as θ, to
insert Unicode characters like 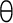 that
aren't available in the legacy character set in
which a document is written.
that
aren't available in the legacy character set in
which a document is written.
Computers don't really understand text. They
don't recognize the Latin letter Z,
the Greek letter 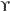 , or the Han ideograph
, or the Han ideograph  . All a computer understands are numbers such as 90, 947, or 40,821. A character set maps particular characters, like Z, to particular numbers, like 90. These numbers are called code points. A character encoding determines how those code points are represented in bytes. For instance, the code point 90 can be encoded as a signed byte, a little-endian unsigned short, a 4-byte, two's complement, big-endian integer, or in some still more complicated fashion.
. All a computer understands are numbers such as 90, 947, or 40,821. A character set maps particular characters, like Z, to particular numbers, like 90. These numbers are called code points. A character encoding determines how those code points are represented in bytes. For instance, the code point 90 can be encoded as a signed byte, a little-endian unsigned short, a 4-byte, two's complement, big-endian integer, or in some still more complicated fashion.
A human script like Cyrillic may be written in multiple character sets, such as KOI8-R, Unicode, or ISO-8859-5. A character set like Unicode may then be encoded in multiple encodings, such as UTF-8, UCS-2, or UTF-16. In general, however, simpler character sets like ASCII and KOI8-R have only one encoding.
5.1. Character-Set Metadata
Some environments keep track of which encodings in which particular documents are written. For instance, web servers that transmit XML documents precede them with an HTTP header that looks something like this:
HTTP/1.1 200 OK Date: Sun, 28 Oct 2001 11:05:42 GMT Server: Apache/1.3.19 (Unix) mod_jk mod_perl/1.25 mod_fastcgi/2.2.10 Connection: close Transfer-Encoding: chunked Content-Type: text/xml; charset=iso-8859-1
The Content-Type field of the HTTP header provides the MIME media type of the document. This may, as shown here, specify in which character set the document is written. An XML parser reading this document from a web server should use this information to determine the document's character encoding.
Many web servers omit the charset parameter from the MIME media type. In this case, if the MIME media type is text/xml , then the document is assumed to be in the us-ascii encoding. If the MIME media type is application/xml, then the parser attempts to guess the character set by reading the first few bytes of the document.
TIP: Since ASCII is almost never an appropriate character set for an XML document, application/xml is much preferred over text/xml. Unfortunately, most web servers including Apache 2.0.36 and earlier are configured to use text/xml by default. It's worth editing your mime.types file to fix this. Alternately, at least with Apache, if you don't have root access to your web server, you can use the AddType and AddCharset directives in your .htaccess files to override the server-wide defaults.
We've focused on MIME types in HTTP headers because that's the most common place where character-set metadata is applied to XML documents. However, MIME types are also used in some filesystems (e.g., the BeOS), in email, and in other environments. Other systems may provide other forms of character-set metadata. If such metadata is available for a document, whatever form it takes, the parser should use it, though in practice this is an area where not all parsers and programs are as conformant as they should be.
|  | |
| 4.4. Namespaces and DTDs |  | 5.2. The Encoding Declaration |

Copyright © 2002 O'Reilly & Associates. All rights reserved.