
 |  |
5.10. Character References
Unicode contains more than 95,000 different characters covering almost all of the world's written languages. Predefining entity references for each of these characters, most of which will never be used in any one document, would impose an excessive burden on XML parsers. Rather than pick and choose which characters are worthy of being encoded as entities, XML goes to the other extreme. It predefines entity references only for characters that have special meaning as markup in an XML document: <, >, &, ", and '. All these are ASCII characters that are easy to type in any text editor.
For other characters that may not be accessible from an ASCII text
editor, XML lets you use character references. A
character reference gives the number of the particular Unicode
character it stands for, in either
decimal or hexadecimal. Decimal
character references look like њ;
hexadecimal character references have an extra x
after the &#;, that is, they look like
њ. Both of these references refer to the
same character, 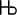 , the Cyrillic small letter "nje" used in
Serbian and Macedonian. For example, suppose you want to include the
Greek maxim "
, the Cyrillic small letter "nje" used in
Serbian and Macedonian. For example, suppose you want to include the
Greek maxim "

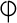 Ó
Ó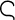
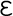

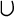
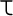 Ó
Ó 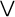
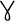
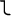
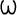
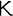 " ("The wise man knows himself") in your XML document. However, you only have an ASCII text editor at your disposal. You can replace each Greek letter with the correct character reference, like this:
" ("The wise man knows himself") in your XML document. However, you only have an ASCII text editor at your disposal. You can replace each Greek letter with the correct character reference, like this:
<maxim> σοφός έαυτόν γιγνώσκει </maxim>
To the XML processor, a document using character entity references referring to Unicode characters that don't exist in the current encoding is equivalent to a Unicode document in which all character references are replaced by the actual characters to which they refer. In other words, this XML document is the same as the previous one:
<maxim>
Ó Ó
</maxim>
Character references may be used in element content, attribute values, and comments. They may not be used in element and attribute names, processing instruction targets, or XML keywords, such as DOCTYPE or ELEMENT. They may be used in the DTD in attribute default values and entity replacement text. Tag and attribute names may be written in languages such as Greek, Russian, Arabic, or Chinese, but you must use a character set that allows you to include the appropriate characters natively. You can't insert these characters with character references. For instance, this is well-formed:
<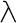 >
σοφός
<>
>
σοφός
<>
This is not well-formed:
<λογος> σοφός </λογος>
There are more than 90,000 Unicode characters that you can include in your XML documents with character entity references. Chapter 26 provides character codes in both decimal and hexadecimal for some of the most useful and widely used alphabetic scripts. The interested reader will find the complete set in The Unicode Standard Version 3.0 by the Unicode Consortium (Addison Wesley, 2000). You can also view the code charts online at http://www.unicode.org/charts/.
If you use a particular group of character references frequently, you may find it easier to define them as entities, then refer to the entities instead. Example 5-3 shows a DTD defining the entities you might use to spell out the Greek words in the previous several examples.
Example 5-3. A DTD defining general entity references for several Greek letters
<!ENTITY sigma "σ"> <!ENTITY omicron_with_tonos "ό"> <!ENTITY phi "φ"> <!ENTITY omicron "ο"> <!ENTITY final_sigma "ς"> <!ENTITY epsilon_with_tonos "έ"> <!ENTITY alpha "α"> <!ENTITY lambda "σ"> <!ENTITY upsilon "υ"> <!ENTITY tau "τ"> <!ENTITY nu "ν"> <!ENTITY gamma "γ"> <!ENTITY iota "ι"> <!ENTITY omega_with_tonos "ώ"> <!ENTITY kappa "κ"> <!ENTITY epsilon "ε">
These entities can even be used in invalid documents, provided either that the declarations are made in the document's internal DTD subset, which all XML parsers are required to process, or that your parser reads the external DTD subset. By convention, DTD fragments that do nothing but define entities have the three-letter suffix, .ent. Generally, these fragments are imported into the document's DTD, using external parameter entity references. Example 5-4 shows how the maxim might be written using these entities, assuming they can be found at the relative URL greek.ent.
Example 5-4. The maxim using entity references instead of character references
<?xml version="1.0" encoding="ISO-8859-1" standalone="no"?> <!DOCTYPE maxim [ <!ENTITY % greek_alphabet SYSTEM "greek.ent"> %greek_alphabet; ]> <maxim> σ&omicron_with_tonos;φο&final_sigma; &epsilon_with_tonos;αυτ&omicron_with_tonos;ν γιγν&omega_with_tonos;σκει </maxim>
A few standard entity subsets are widely available for your own use. The XHTML 1.0 DTD includes three useful entity sets you can adopt in your own work:
- Latin-1 characters, http://www.w3.org/TR/xhtml1/DTD/xhtml-lat1.ent
- The non-ASCII characters from 160 up in ISO-8859-1
- Special characters, http://www.w3.org/TR/xhtml1/DTD/xhtml-special.ent
-
Letters from ISO-8859-2 (Latin-2) that
aren't also in Latin-1, such as
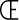 and
various punctuation marks, such as the dagger, the Euro sign, and the
em dash
and
various punctuation marks, such as the dagger, the Euro sign, and the
em dash
- Symbols, http://www.w3.org/TR/xhtml1/DTD/xhtml-symbol.ent
- The Greek alphabet (though accented characters are missing) and various punctuation marks, mathematical operators, and other symbols commonly used in mathematics
Chapter 26 provides complete charts showing of all characters in these entity sets. You can either use these directly from their relatively stable URLs at the W3C or copy them onto your own systems. For example, to use entities from the symbol set in a document, add the following to the document's DTD:
<!ENTITY % HTMLsymbol PUBLIC "-//W3C//ENTITIES Symbols for XHTML//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml-symbol.ent"> %HTMLsymbol;
Since these are fairly standard DTDs, they have both Public IDs and URLs. Other groups and individuals have written entity sets you can use similarly, though no canonical collection of entity sets that covers all of Unicode exists. SGML included almost 20 separate entity sets covering Greek, Cyrillic, extended Latin, mathematical symbols, diacritical marks, box-drawing characters, and publishing marks. These aren't a standard part of XML, but several applications including DocBook (http://www.docbook.org/) and MathML (http://www.w3.org/TR/MathML2/chapter6.html#chars_entity-tables) have ported them to XML. MathML also has several useful entity sets containing more mathematical symbols.
|  | |
| 5.9. The Default Character Set for XML Documents |  | 5.11. xml:lang |

Copyright © 2002 O'Reilly & Associates. All rights reserved.