
 |  |
7.3. Command-Line Processing
We've seen how the shell processes input lines: it deals with single quotes (' '), double quotes (" "), and backslashes (\), and it separates parameter, command and arithmetic expansions into words, according to delimiters in the variable IFS. This is a subset of the things the shell does when processing command lines.
This section completes the discussion, in sometimes excruciating detail. We first examine two additional kinds of substitutions or expansions that the shell performs that may not be universally available. Then we present the full story of the order that the shell processes the command line. Covered next is the use of quoting, which prevents many or all of the substitution steps from occurring. Finally, we cover the eval command, which can be used for additional programmatic control of command line evaluations.
7.3.1. Brace Expansion and Process Substitution
Brace expansion is a feature borrowed from the Berkeley csh command interpreter and also available in the popular bash shell. Brace expansion is a way of saving typing when you have strings that are prefixes or suffixes of each other. For example, suppose you have the following files:
$ ls cpp-args.c cpp-lex.c cpp-out.c cpp-parse.c
You could type vi cpp-{args,lex,parse}.c if you wished to edit three out of the four C files, and the shell would expand this into vi cpp-args.c cpp-lex.c cpp-parse.c. Furthermore, brace substitutions may be nested. For example:
$ print cpp-{args,l{e,o}x,parse}.c
cpp-args.c cpp-lex.c cpp-lox.c cpp-parse.c
This is a handy feature. We haven't covered it up until now because it's possible that your version of ksh may not have it. It is an optional feature that is enabled when ksh is compiled. However, it is enabled by default when ksh93 is compiled from source code.
Process substitution allows you to open multiple process streams and feed them into a single program for processing. For example:
awk '...' <(generate_data) <(generate_more_data)
(Note that the parentheses are part of the syntax; you type them literally.) Here, generate_data and generate_more_data represent arbitrary commands, including pipelines, that produce streams of data. The awk program processes each stream in turn, not realizing that the data is coming from multiple sources. This is shown graphically in Figure 7-1.a.
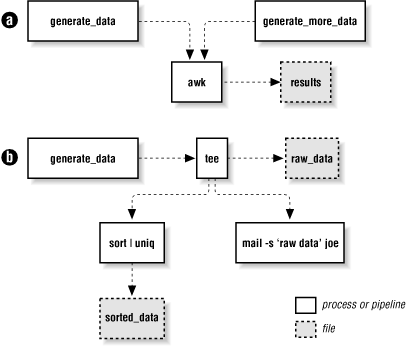
Figure 7-1. Process substitution for both input and output data streams
Process substitution may also be used for output, particularly when combined with the tee(1) program, which sends its input to multiple output files and to standard output. For example:
generate_data | tee >(sort | uniq > sorted_data) \
>(mail -s 'raw data' joe) > raw_data
This command uses tee to (1) send the data to a pipeline that sorts and saves the data, (2) send the data to the mail program to user joe, and (3) redirect the original data into a file. This is represented graphically in Figure 7-1.b. Process substitution, combined with tee, allows you to create nonlinear data graphs, freeing you from the straight "one input, one output" paradigm of traditional Unix pipes.
Process substitution is only available on Unix systems that support the /dev/fd/N special files for named access to already open file descriptors. (This is different from the use of /dev/fd/N described earlier in this chapter, where the shell itself interprets the pathname. Here, because external commands must be able to open files in /dev/fd, the feature must be directly supported by the operating system.) Most modern Unix systems, including GNU/Linux, support this feature. Like brace substitution, it must be enabled at compile time, and may not be available in your version of ksh. As with brace expansion, it is enabled by default when ksh93 is compiled from source code.
7.3.2. Substitution Order
We've touched upon command-line processing (see Figure 7-2) throughout this book; now is a good time to make the whole thing explicit.[101] Each line that the shell reads from the standard input or a script is called a pipeline; it contains one or more commands separated by zero or more pipe characters (|). For each pipeline it reads, the shell breaks it up into commands, sets up the I/O for the pipeline, and then does the following for each command:
[101] Even this explanation is slightly simplified to elide the most petty details, e.g., "middles" and "ends" of compound commands, special characters within [[...]] and ((...)) constructs, etc. The last word on this subject is the reference book The New KornShell Command and Programming Language by Morris Bolsky and David Korn, published by Prentice-Hall.
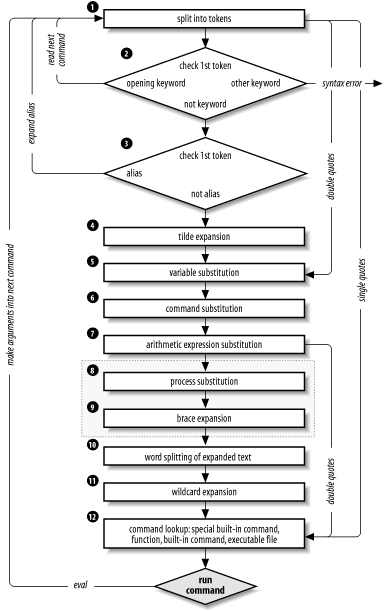
Figure 7-2. Steps in command-line processing
Splits the command into tokens that are separated by the fixed set of metacharacters: space, TAB, newline, ;, (, ), <, >, |, and &. Types of tokens include words, keywords, I/O redirectors, and semicolons.
Checks the first token of each command to see if it is a keyword with no quotes or backslashes. If it's an opening keyword (if and other control-structure openers, function, {, (, ((, or [[), the command is actually a compound command. The shell sets things up internally for the compound command, reads the next command, and starts the process again. If the keyword isn't a compound command opener (e.g., is a control-structure "middle" like then, else, or do, an "end" like fi or done, or a logical operator), the shell signals a syntax error.
Checks the first word of each command against the list of aliases. If a match is found, it substitutes the alias's definition and goes back to Step 1; otherwise, it goes on to Step 4. This scheme allows recursive aliases; see Chapter 3. It also allows aliases for keywords to be defined, e.g., alias aslongas=while or alias procedure=function.
Substitutes the user's home directory ($HOME) for the tilde character (~) if it is at the beginning of a word. Substitutes user's home directory for ~user.[102]
[102] Two obscure variations on this: the shell substitutes the current directory ($PWD) for ~+ and the previous directory ($OLDPWD) for ~-.
Tilde substitution occurs at the following places:
As the first unquoted character of a word on the command line
After the = in a variable assignment and after any : in the value of a variable assignment
For the word part of variable substitutions of the form ${variable op word} (see Chapter 4)
Performs parameter (variable) substitution for any expression that starts with a dollar sign ($).
Does command substitution for any expression of the form $(string) or `string`.
Performs process substitution, if that feature is compiled into the shell and your system supports /dev/fd.
Performs brace expansion, if that feature is compiled into the shell.
Takes the parts of the line that resulted from parameter, command, and arithmetic substitution and splits them into words again. This time it uses the characters in $IFS as delimiters instead of the set of metacharacters in Step 1.
Normally, successive multiple input occurrences of characters in IFS act as a single delimiter, which is what you would expect. This is true only for whitespace characters, such as space and TAB. For non-whitespace characters, this is not true. For example, when reading the colon-separated fields of /etc/passwd, two successive colons delimit an empty field. For example:
IFS=: while read name passwd uid gid fullname homedir shell do
... done < /etc/passwdTo get this behavior with whitespace-delimited fields (for example, where TAB characters delimit each field), put two successive instances of the delimiter character into IFS.
ksh ignores any inherited (environment) value of IFS. Upon startup, it sets the value of IFS to the default of space, TAB, and newline.
-
Performs filename generation, a.k.a. wildcard expansion, for any occurrences of *, ?, and [ ] pairs. It also processes the regular expression operators that we saw in Chapter 4.
Uses the first word as a command by looking up its location according to the rest of the list in Chapter 4, i.e., as a special built-in command, then as a function, then as a regular built-in command, and finally as a file in any of the directories in $PATH.
Runs the command after setting up I/O redirection and other such things.
That's a lot of steps -- and it's not even the whole story! But before we go on, an example should make this process clearer. Assume that the following command has been run:
alias ll="ls -l"
Further assume that a file exists called .hist537 in user fred's home directory, which is /home/fred, and that there is a double-dollar-sign variable $$ whose value is 2537 (we'll see what this special variable is in the next chapter).
Now let's see how the shell processes the following command:
ll $(whence cc) ~fred/.*$(($$%1000))
Here is what happens to this line:
ll $(whence cc) ~fred/.*$(($$%1000))
Splitting the input into words.
ll is not a keyword, so step 2 does nothing.
ls -l $(whence cc) ~fred/.*$(($$%1000))
Substituting ls -l for its alias "ll". The shell then repeats steps 1 through 3; step 2 splits the ls -l into two words.
ls -l $(whence cc) /home/fred/.*$(($$%1000))
Expanding ~fred into /home/fred.
ls -l $(whence cc) /home/fred/.*$((2537%1000))
Substituting 2537 for $$.
ls -l /usr/bin/cc /home/fred/.*$((2537%1000))
Doing command substitution on "whence cc."
ls -l /usr/bin/cc /home/fred/.*537
Evaluating the arithmetic expression 2537%1000.
ls -l /usr/bin/cc /home/fred/.*537
This step does nothing. (No process substitution.)
ls -l /usr/bin/cc /home/fred/.*537
This step does nothing. (No braces to expand.)
-
ls -l /usr/bin/cc /home/fred/.*537
This step does nothing. (No expanded text to split.)
ls -l /usr/bin/cc /home/fred/.hist537
Substituting the filename for the wildcard expression .*537.
The command ls is found in /usr/bin.
/usr/bin/ls is run with the option -l and the two arguments.
Although this list of steps is fairly straightforward, it is not the whole story. There are still two ways to subvert the process: by quoting, and by using the advanced command eval.
7.3.3. Quoting
You can think of quoting as a way of getting the shell to skip some of the 13 steps above. In particular:
Single quotes ('...') bypass everything through Step 11, including aliasing. All characters inside a pair of single quotes are untouched. You can't have single quotes inside single quotes, even if you precede them with backslashes.[103]
[103] However, as we saw in Chapter 1, '\'' (i.e., single quote, backslash, single quote, single quote) acts pretty much like a single quote in the middle of a single-quoted string; e.g., 'abc'\''def' evaluates to abc'def.
Double quotes ("...") bypass steps 1 through 4, plus steps 8 through 11. That is, they ignore pipe characters, aliases, tilde substitution, wildcard expansion, process substitution, brace expansion, and splitting into words via delimiters (e.g., spaces) inside the double quotes. Single quotes inside double quotes have no effect. But double quotes do allow parameter substitution, command substitution, and arithmetic expression evaluation. You can include a double quote inside a double-quoted string by preceding it with a backslash (\). You must also backslash-escape $, ` (the archaic command substitution delimiter), and \ itself.
Table 7-8 contains some simple examples that show how these work; they assume the statement dave=bob was run and user fred's home directory is /home/fred.
If you are wondering whether to use single or double quotes in a particular shell programming situation, it is safest to use single quotes unless you specifically need parameter, command, or arithmetic substitution.
Table 7-8. Examples of quoting rules
| Expression | Value |
|---|---|
| $dave | bob |
| "$dave" | bob |
| \$dave | $dave |
| '$dave' | $dave |
| \'$dave\' | 'bob' |
| "'$dave'" | 'bob' |
| ~fred | /home/fred |
| "~fred" | ~fred |
| '~fred' | ~fred |
Using double quotes on variable values is increasingly important when dealing with the results of wildcard expansion. Today, it is not unusual to have files and directories available on Unix systems that actually physically exist on Microsoft Windows and Apple Macintosh systems. On those systems, spaces and other unusual characters, such as apostrophes and back-quotes, are common in filenames. Thus, to pass the full pathname into your application, be sure you quote things properly.
Task 7-5 is a more advanced example of command-line processing that should give you deeper insight into the overall process.
Task 7-5
Customize your primary prompt string so that it contains the current directory with tilde (~) notation.
Recall from Chapter 4 that we found a simple way to set up the prompt string PS1 so that it always contains the current directory: PS1='($PWD)-> '.
One problem with this setup is that the resulting prompt strings can get very long. One way to shorten them is to substitute tilde notation for users' home directories. This cannot be done with a simple string expression analogous to the above. The solution is somewhat complicated and takes advantage of the command-line processing rules.
The basic idea is to create a "wrapper" around the cd command, as we did in Chapter 5, that installs the current directory with tilde notation as the prompt string. We will see how to make this wrapper function shortly. The code we need to insert tilde notation is complicated in its own right; we develop it first.
We start with a function that, given a pathname as argument, prints its equivalent in tilde notation if possible. In order to write this function, we assume that we already have an associative array named tilde_ids, in which the subscripts are home directories and the values are user names. Thus, print ${tilde_ids[/home/arnold]} would print the value arnold. Here's the function, named tildize:
function tildize {
# subdir of our home directory
if [[ $1 == $HOME* ]]; then
print "\~${1#$HOME}"
return 0
fi
# loop over homedirs trying to match current dir
typeset homedir
for homedir in ${!tilde_ids[*]}; do
if [[ $1 == ${homedir}?(/*) ]]; then
print "\~${tilde_ids[$homedir]}${1#$homedir}"
return 0
fi
done
print "$1"
return 1
}
The first if clause checks if the given pathname is under the user's home directory. If so, it substitutes tilde (~) for the home directory in the pathname and returns.
If not, we loop over all the subscripts in tilde_ids, comparing each one to our current directory. The test matches home directories by themselves or with some other directory appended (the ?(/*) part.) If a user's home directory is found, ~user is substituted for the full home directory in the given pathname, the result is printed, and the function exits.
Finally, if the for loop exhausts all users without finding a home directory that is a prefix of the given pathname, tildize simply echoes back its input.
Now, how do we create the tilde_ids array? We use the function init_tilde_db. It should be called once, from the .profile file when we log in. The tilde_ids array must be explicitly declared as an associative array using typeset -A:
# tilde_ids[] is global associative array
# mapping directories to user names
typeset -A tilde_ids
function init_tilde_db {
typeset user homedir # local vars
awk -F: '{ print $1, $6 }' /etc/passwd |
while read user homedir; do
if [[ $homedir != / ]]; then
tilde_ids[$homedir]=$user
fi
done
}
We use the awk utility to extract the first and sixth fields of the file /etc/passwd, which contain user IDs and home directories, respectively.[104] In this case, awk acts like cut. The -F: is analogous to -d:, which we saw in Chapter 4, except that awk prints the values on each line separated by spaces, not colons (:).
[104] In large multi-machine environments, you may need to use something like ypcat passwd | awk ... or niscat passwd.org_dir | awk ... to get the same information. Check with your system administrator.
awk's output is fed into a while loop that checks the pathname given as argument to see if it contains some user's home directory. (The conditional expression eliminates "users" like daemon and root, whose home directories are root and therefore are contained in every full pathname.)
Now that we have the tildize function, you might think we could use it in a command substitution expression like this:
PS1='$(tildize $PWD)> '
In fact, you'd be right.[105] But there's a hidden cost here. The function is run every time that the shell prints the prompt. Even if all you do is hit ENTER, the shell runs the tildize function. If there are lots of users on your system, the shell loops through all of the home directories, each time. To avoid this, we write a cd function that only updates the prompt when we actually change directories. The following code should go into your .profile or environment file, along with the definition of tilde_ids and tildize:
[105] This doesn't work in ksh88, though.
init_tilde_db # set up array once, upon login
function cd {
command cd "$@" # run real cd
typeset es=$? # save exit status in a local var
PS1="$(tildize $PWD)> "
return $es
}
cd $PWD # set prompt
As we saw in Chapter 5, writing a function with the same name as a built-in command looks pretty strange at first glance. But, following the POSIX standard, the Korn shell distinguishes between "special" built-in commands and regular built-in commands. When the shell looks for commands to execute, it finds functions before it finds regular built-in commands. cd is a regular built-in command, so this works. Within the function, we use the the cleverly named command command to actually get at the real cd command.[106] The statement command cd "$@" passes the function's arguments on to the real cd in order to change the directory. (As a side note, the shell defines an alias command='command ', which allows you to use command with aliases.)
[106] As mentioned earlier, command is not a special built-in. Woe be to the shell programmer who writes a function named command!
When you log in, this code sets PS1 to the initial current directory (presumably your home directory). Then, whenever you enter a cd command, the function runs to change the directory and reset the prompt.
Of course, the function tildize can be any code that formats the directory string. See the exercises at the end of this chapter for a couple of suggestions.
7.3.3.1. Extended quoting
Single and double quoting have been in the Bourne shell and its derivatives from the beginning (although the original Bourne shell doesn't do arithmetic or $(...) substitution). The Korn shell offers variant versions of both single- and double-quoted strings, as follows.
- $"..."
- This version is the simplest. It is just like a regular double-quoted string. However, these strings are subject to locale translation at runtime. This is described further, below.
- $'...'
- This string is similar to a regular single-quoted string in that none of the shell's substitutions or expansions are performed on the contents. However, the contents are processed for escape sequences, similar to those used by the print command. ksh documentation refers to these as ANSI C strings.
The Korn shell's internationalization features are beyond the scope of this book, but briefly, it works like this. When ksh is invoked on a script with the -D option, it prints a list of all $"..." strings to standard output. This list can then be saved and used to produce translations that are used at runtime when the script is actually executed. Thus, in a French locale, if a translation is available for this program:
print $"hello, world" A well-known greeting among computer scientists
ksh would print bonjour, monde when the program runs.
The print command makes it possible to use C-style escape sequences for output. And most of the time, this is all you need. But occasionally, it's useful to use the same notation in arguments to other programs. This is the purpose of the $'...' string. The contents are not processed for variable, command, or arithmetic substitution. But they are processed for escape sequences, as shown in Table 7-9.
Table 7-9. String escape sequences
| Sequence | Meaning | Sequence | Meaning |
|---|---|---|---|
| \a | Alert, ASCII bell | \t | TAB |
| \b | Backspace | \v | Vertical tab |
| \cX | \xHH | Character with value of hexadecimal digits HH |
|
| \C[.ce.] | The collating element ce.[107][108] (A collating element is two or more characters that are treated as one unit for sorting purposes.) |
\x{digs} | Hexadecimal value of digs. Use the braces when following characters are hexadecimal digits that should not be interpreted.[107][108] |
| \e | \0 | Rest of string ignored after this[108] |
|
| \E | ASCII Escape character[107] |
\ddd | Character with value of octal digits ddd |
| \f | Form feed | \' | Single quote |
| \n | Newline | \" | Double quote |
| \r | Carriage return | \\ | Literal backslash |
[107] Not in the C language.
[108] New, starting with ksh93l.
Of primary value is the fact that you can easily get single and double quotes inside the $'...' kind of string:
$ print $'A string with \'single quotes\' and \"double quotes\" in it' A string with 'single quotes' and "double quotes" in it
Of interest is the fact that the double quote doesn't really need to be escaped, but that doing so doesn't hurt anything, either.
7.3.4. eval
We have seen that quoting lets you skip steps in command-line processing. Then there's the eval command, which lets you go through the process again. Performing command-line processing twice may seem strange, but it's actually very powerful: it lets you write scripts that create command strings on the fly and then pass them to the shell for execution. This means that you can give scripts "intelligence" to modify their own behavior as they are running.
The eval statement tells the shell to take eval's arguments and run them through the command-line processing steps all over again. To help you understand the implications of eval, we'll start with a trivial example and work our way up to a situation in which we're constructing and running commands on the fly.
eval ls passes the string ls to the shell to execute; the shell prints a list of files in the current directory. Very simple; there is nothing about the string ls that needs to be sent through the command-processing steps twice. But consider this:
listpage="ls | more" $listpage
Instead of producing a paginated file listing, the shell treats | and more as arguments to ls, and ls complains that no files of those names exist. Why? Because the pipe character "appears" in step 5 when the shell evaluates the variable, after it has actually looked for pipe characters (in step 2). The variable's expansion isn't even parsed until step 10. As a result, the shell treats | and more as arguments to ls, so that ls tries to find files called | and more in the current directory!
Now consider eval $listpage instead of just $listpage. When the shell gets to the last step, it runs the command eval with arguments ls, |, and more. This causes the shell to go back to Step 1 with a line that consists of these arguments. It finds | in Step 2 and splits the line into two commands, ls and more. Each command is processed in the normal (and in both cases trivial) way. The result is a paginated list of the files in your current directory.
Now you may start to see how powerful eval can be. It is an advanced feature that requires considerable programming cleverness to be used most effectively. It even has a bit of the flavor of artificial intelligence, in that it enables you to write programs that can "write" and execute other programs.[109] You probably won't use eval for everyday shell programming, but it's worth taking the time to understand what it can do.
[109] You could actually do this without eval, by printing commands to a temporary file and then "sourcing" that file with . filename. But that is much less efficient.
As a more interesting example, we'll revisit Task 4-1, the very first task in the book. In it, we constructed a simple pipeline that sorts a file and prints out the first N lines, where N defaults to 10. The resulting pipeline was:
sort -nr $1 | head -${2:-10}
The first argument specifies the file to sort; $2 is the number of lines to print.
Now suppose we change the task just a bit so that the default is to print the entire file instead of 10 lines. This means that we don't want to use head at all in the default case. We could do this in the following way:
if [[ -n $2 ]]; then
sort -nr $1 | head -$2
else
sort -nr $1
fi
In other words, we decide which pipeline to run according to whether or not $2 is null. But here is a more compact solution:
eval sort -nr \$1 ${2:+"| head -\$2"}
The last expression in this line evaluates to the string | head -\$2 if $2 exists (is not null); if $2 is null, then the expression is null too. We backslash-escape dollar signs (\$) before variable names to prevent unpredictable results if the variables' values contain special characters like > or |. The backslash effectively puts off the variables' evaluation until the eval command itself runs. So the entire line is either:
eval sort -nr \$1 | head -\$2
if $2 is given or:
eval sort -nr \$1
if $2 is null. Once again, we can't just run this command without eval because the pipe is "uncovered" after the shell tries to break the line up into commands. eval causes the shell to run the correct pipeline when $2 is given.
Next, we'll revisit Task 7-3 from earlier in this chapter, the start function that lets you start a command in the background and save its standard output and standard error in a logfile. Recall that the one-line solution to this task had the restriction that the command could not contain output redirectors or pipes. Although the former doesn't make sense when you think about it, you certainly would want the ability to start a pipeline in this way.
eval is the obvious way to solve this problem:
function start {
eval "$@" > logfile 2>&1 &
}
The only restriction that this imposes on the user is that pipes and other such special characters must be quoted (surrounded by quotes or preceded by backslashes).
Task 7-6 is a way to apply eval in conjunction with various other interesting shell programming concepts.
Task 7-6
Implement the guts of the make(1) utility as a shell script.
make is known primarily as a programmer's tool, but it seems as though someone finds a new use for it every day. Without going into too much extraneous detail, make keeps track of multiple files in a particular project, some of which depend on others (e.g., a document depends on its word processor input file(s)). It makes sure that when you change a file, all of the other files that depend on it are processed.
For example, assume you're writing a book in DocBook XML. You have files for the book's chapters called ch01.xml, ch02.xml, and so on. The generated PostScript output for these files are ch01.ps, ch02.ps, etc. The tool to convert DocBook XML into PostScript is called (for some strange reason) gmat. You run commands like gmat chN.xml to do the processing. (gmat knows to create ch01.ps from ch01.xml; you don't need to use shell redirection.) While you're working on the book, you tend to make changes to several files at a time.
In this situation, you can use make to keep track of which files need to be reprocessed, so that all you need to do is type make, and it figures out what needs to be done. You don't need to remember to reprocess the files that have changed.
How does make do this? Simple: it compares the modification times of the input and output files (called sources and targets in make terminology), and if the input file is newer, make reprocesses it.
You tell make which files to check by building a file called makefile that has constructs like this:
target : source1 source2 ...
commands to make target
This essentially says, "For target to be up to date, it must be newer than all of the sources. If it's not, run the commands to bring it up to date." The commands are on one or more lines that must start with TABs: e.g., to make ch07.ps:
ch07.ps : ch07.xml
gmat ch07.xml
Now suppose that we write a shell function called makecmd that reads and executes a single construct of this form. Assume that the makefile is read from standard input. The function would look like the following code.
function makecmd {
read target colon sources
for src in $sources; do
if [[ $src -nt $target ]]; then
while read cmd && [[ $cmd == \t* ]]; do
print "$cmd"
eval $cmd
done
break
fi
done
}
This function reads the line with the target and sources; the variable colon is just a placeholder for the :. Then it checks each source to see if it's newer than the target, using the -nt file attribute test operator that we saw in Chapter 5. If the source is newer, it reads, prints, and executes the commands until it finds a line that doesn't start with a TAB or it reaches end-of-file. (The real make does more than this; see the exercises at the end of this chapter.) After running the commands, it breaks out of the for loop, so that it doesn't run the commands more than once. (It isn't necessary to strip the initial TAB from the command. The shell discards the leading whitespace automatically.)
7.3.4.1. The C compiler as pipeline
As a final example of eval, we'll revisit our old friend occ, the C compiler front-end from the previous three chapters. Recall that the compiler front-end does its work by calling separate programs to do the actual compile from C to object code (the ccom program), optimization of object code (optimize), assembly of assembler code files (as), and final linking of object code files into an executable program (ld). These separate programs use temporary files to store their outputs.
Now we'll assume that these components (except the linker) pass information in a pipeline to the final object code output. In other words, each component takes standard input and produces standard output instead of taking filename arguments. We'll also change an earlier assumption: instead of compiling a C source file directly to object code, occ compiles C to assembler code, which the assembler then assembles to object code.[110] This lets us suppose that occ works like this:
[110] For what it's worth, many Unix compilers generate assembly code, optimize the assembly code, and then generate object code.
ccom < filename.c | as | optimize > filename.o
Or, if you prefer:
cat filename.c | ccom | as | optimize > filename.o
To get this in the proper framework for eval, let's assume that the variables srcname and objname contain the names of the source and object files, respectively. Then our pipeline becomes:
cat $srcname | ccom | as | optimize > $objname
As we've already seen, this is equivalent to:
eval cat \$srcname \| ccom \| as \| optimize \> \$objname
Knowing what we do about eval, we can transform this into:
eval cat \$srcname " | ccom" " | as" " | optimize" \> \$objname
and from that into:
compile=" | ccom" assemble=" | as" optimize=" | optimize" eval cat \$srcname $compile $assemble $optimize \> \$objname
Now, consider what happens if you don't want to invoke the optimizer -- which is the default case anyway. (Recall that the -O option invokes the optimizer.) We can do this:
optimize=""
if -O given then
optimize=" | optimize"
fi
In the default case, $optimize evaluates to the empty string, causing the final pipeline to "collapse" into:
eval cat $srcname \| ccom \| as \> $objname
Similarly, if you pass occ a file of assembler code (filename.s), you can collapse the compile step:[111]
[111] Astute readers will notice that, according to this rationale, we would handle object-code input files (filename.o) with the pipeline eval cat $srcname > $objname, where the two names are the same. This will cause the shell to destroy filename.o by truncating it to zero length. We won't worry about this here.
assemble="| as"
if $srcname ends in .s then
compile=""
fi
That results in this pipeline:
eval cat \$srcname \| as \> \$objname
Now we're ready to show the full "pipeline" version of occ. It's similar to the previous version, except that for each input file, it constructs and runs a pipeline as above. It processes the -g (debug) option and the link step in the same way as before. Here is the code:
# initialize option-related variables
do_link=true
debug=""
link_libs=""
clib="-lc"
exefile=""
# initialize pipeline components
compile=" | ccom"
assemble=" | as"
optimize=""
# process command-line options
while getopts "cgl:[lib]o:[outfile]O files ..." opt; do
case $opt in
c ) do_link=false ;;
g ) debug="-g" ;;
l ) link_libs+=" -l $OPTARG" ;;
o ) exefile="-o $OPTARG" ;;
O ) optimize=" | optimize" ;;
esac
done
shift $(($OPTIND - 1))
# process the input files
for filename in "$@"; do
case $filename in
*.c )
objname=${filename%.c}.o ;;
*.s )
objname=${filename%.s}.o
compile="" ;;
*.o )
objname=$filename # just link it directly with the rest
compile=""
assemble="" ;;
* )
print "error: $filename is not a source or object file."
exit 1 ;;
esac
# run a pipeline for each input file
eval cat \$filename $compile $assemble $optimize \> \$objname
objfiles+=" $objname"
compile=" | ccom"
assemble=" | as"
done
if [[ $do_link == true ]]; then
ld $exefile $objfiles $link_libs $clib
fi
We could go on forever with increasingly complex examples of eval, but we'll settle for concluding the chapter with a few exercises.
Here are a couple of ways to enhance occ, our C compiler:
Real-world C compilers accept the option -S, which tells the compiler to suppress the assembly step and leave the output in files of assembler code whose names end in .s. Modify occ so that it recognizes this option.
The language C++ is an evolutionary successor to C; it includes advanced features like operator overloading, mandatory function argument type checking, class definitions, templates, and many more. (Don't worry if you don't know what these are.) Some C++ compilers use C as an "assembly language", i.e., they compile C++ source files to C code and then pass them to a C compiler for further processing. Assume that C++ source files have names ending in .cc, and that /lib/cfront is the C++ compiler "front-end" that produces C code on its standard output. Modify occ so that it accepts C++ as well as C, assembler, and object code files.
The possibilities for customizing your prompt string are practically endless. Here are two enhancements to the customization schemes that we've seen already:
Enhance the current-directory-in-the-prompt scheme by limiting the prompt string's length to a number of characters that the user can define with an environment variable.
Read the man page for date(1) and read about the SECONDS variable in the ksh(1) man page. Arrange things so that the shell prints the current time of day in the prompt. (Hint: remember that the shell does variable, command, and arithmetic substitution on the value of PS1 before printing it out.)
The function makecmd in the solution to Task 7-6 represents an oversimplification of the real make's functionality. make actually checks file dependencies recursively, meaning that a source on one line in a makefile can be a target on another line. For example, the book chapters in the example could themselves depend on figures in separate files that were made with a graphics package.
Write a function called readtargets that goes through the makefile and stores all of the targets in a variable or temp file.
Instead of reading the makefile from standard input, read it into an array variable called lines. Use the variable curline as the "current line" index. Modify makecmd so that it reads lines from the array starting with the current line.
makecmd merely checks to see if any of the sources are newer than the given target. It should really be a recursive routine that looks like this:
function makecmd { target=$1 get sources for $target for each source src; do if $src is also a target in this makefile then makecmd $src fi if [[ $src -nt $target ]]; then run commands to make target return fi done }Implement this. Remember to use typeset to create local variables, and think about how associative arrays might be helpful in tracking targets, sources, and commands to execute.
Write the "driver" script that turns the makecmd function into a full make program. This should make the target given as argument, or if none is given, the first target listed in the makefile.
Finally, here are some problems that really test your knowledge of eval and the shell's command-line processing rules. Solve these and you're a true Korn shell wizard!
Advanced shell programmers sometimes use a little trick that includes eval: using the value of a variable as the name of another variable. In other words, you can give a shell script control over the names of variables to which it assigns values. How would you do this? (Hint: if $fred equals `'dave'', and $dave is `'bob'', you might think that you could type print $$fred and get the response bob. This doesn't actually work, but it's on the right track. This exercise is actually easy to solve using namerefs. But it's worth doing it without them to test your understanding of eval and the shell's quoting rules.)
You could use the above technique together with other eval tricks to implement new control structures for the shell. For example, see if you can write a script (or function) that emulates the behavior of the C shell's repeat command:
repeat count command
This works in the obvious way: the command is executed count times.
|  | |
| 7.2. String I/O |  | 8. Process Handling |

Copyright © 2003 O'Reilly & Associates. All rights reserved.