
 |  |
Chapter 5. Flow Control
Contents:
If you are a programmer, you may have read the last chapter -- with its claim at the outset that the Korn shell has an advanced set of programming capabilities -- and wondered where many features from conventional languages are. Perhaps the most glaringly obvious "hole" in our coverage thus far concerns flow control constructs like if, for, while, and so on.
Flow control gives a programmer the power to specify that only certain portions of a program run, or that certain portions run repeatedly, according to conditions such as the values of variables, whether or not commands execute properly, and others. We call this the ability to control the flow of a program's execution.
Almost every shell script or function shown thus far has had no flow control -- they have just been lists of commands to be run! Yet the Korn shell, like the C and Bourne shells, has all the flow control abilities you would expect and more; we examine them in this chapter. We'll use them to enhance the solutions to some of the programming tasks we saw in the last chapter and to solve tasks that we introduce here.
Although we have attempted to explain flow control so that nonprogrammers can understand it, we also sympathize with programmers who dread having to slog through yet another tabula rasa explanation. For this reason, some of our discussions relate the Korn shell's flow-control mechanisms to those that programmers should know already. Therefore you will be in a better position to understand this chapter if you already have a basic knowledge of flow control concepts.
The Korn shell supports the following flow control constructs:
- if/else
- Execute a list of statements if a certain condition is/is not true.
- for
- Execute a list of statements a fixed number of times.
- while
- Execute a list of statements repeatedly while a certain condition holds true.
- until
- Execute a list of statements repeatedly until a certain condition holds true.
- case
- Execute one of several lists of statements depending on the value of a variable.
In addition, the Korn shell provides a new type of flow-control construct:
We will cover each of these, but be warned: the syntax is unusual.
5.1. if/else
The simplest type of flow control construct is the conditional, embodied in the Korn shell's if statement. You use a conditional when you want to choose whether or not to do something, or to choose among a small number of things to do, according to the truth or falsehood of conditions. Conditions test values of shell variables, characteristics of files, whether or not commands run successfully, and other factors. The shell has a large set of built-in tests that are relevant to the task of shell programming.
The if construct has the following syntax:
if condition
then
statements
[elif condition
then statements ...]
[else
statements]
fi
The simplest form (without the elif and else parts, a.k.a. clauses) executes the statements only if the condition is true. If you add an else clause, you get the ability to execute one set of statements if a condition is true or another set of statements if the condition is false. You can use as many elif (a contraction of "else if") clauses as you wish; they introduce more conditions and thus more choices for which set of statements to execute. If you use one or more elif s, you can think of the else clause as the "if all else fails" part.
5.1.1. Exit Status and Return
Perhaps the only aspect of this syntax that differs from that of conventional languages like C and Pascal is that the "condition" is really a list of statements rather than the more usual Boolean (true or false) expression. How is the truth or falsehood of the condition determined? It has to do with a general Unix concept that we haven't covered yet: the exit status of commands.
Every Unix command, whether it comes from source code in C, some other language, or a shell script/function, returns an integer code to its calling process -- the shell in this case -- when it finishes. This is called the exit status. 0 is usually the "OK" exit status, while anything else (1 to 255) usually denotes an error.[66] The way ksh handles exit statuses for built-in commands is described in more detail later in this section.
[66] Because this is a "convention" and not a "law," there are exceptions. For example, diff(1) (find differences between two files) returns 0 for "no differences," 1 for "differences found," or 2 for an error such as an invalid filename argument.
if checks the exit status of the last statement in the list following the if keyword.[67] (The list is usually just a single statement.) If the status is 0, the condition evaluates to true; if it is anything else, the condition is considered false. The same is true for each condition attached to an elif statement (if any).
This enables us to write code of the form:
if command ran successfully
then
normal processing
else
error processing
fi
More specifically, we can now improve on the pushd function that we saw in the last chapter:
function pushd { # push current directory onto stack
dirname=$1
cd ${dirname:?"missing directory name."}
DIRSTACK="$dirname $DIRSTACK"
print "$DIRSTACK"
}
This function requires a valid directory as its argument. Let's look at how it handles error conditions: if no argument is given, the second line of code prints an error message and exits. This is fine.
However, the function reacts deceptively when an argument is given that isn't a valid directory. In case you didn't figure it out when reading the last chapter, here is what happens: the cd fails, leaving you in the same directory you were in. This is also appropriate. But then the third line of code pushes the bad directory onto the stack anyway, and the last line prints a message that leads you to believe that the push was successful.
We need to prevent the bad directory from being pushed and to print an error message. Here is how we can do this:
function pushd { # push current directory onto stack
dirname=$1
if cd ${dirname:?"missing directory name."} # if cd was successful
then
DIRSTACK="$dirname $DIRSTACK"
print $DIRSTACK
else
print still in $PWD.
fi
}
The call to cd is now inside an if construct. If cd is successful, it returns 0; the next two lines of code are run, finishing the pushd operation. But if the cd fails, it returns with exit status 1, and pushd prints a message saying that you haven't gone anywhere.
You can usually rely on built-in commands and standard Unix utilities to return appropriate exit statuses, but what about your own shell scripts and functions? For example, we'd like pushd to return an appropriate status so that it too can be used in an if statement:
if pushd some-directory
then
what we need to do
else
handle problem case
fi
The problem is that the exit status is reset by every command, so it "disappears" if you don't save it immediately. In this function, the built-in cd's exit status disappears when the print statement runs (and sets its own exit status).
Therefore, we need to save the status that cd sets and use it as the entire function's exit status. Two shell features we haven't seen yet provide the way. First is the special shell variable ?, whose value ($?) is the exit status of the last command that ran. For example:
cd baddir print $?
causes the shell to print 1, while:
cd gooddir print $?
causes the shell to print 0.
5.1.1.1. Return
The second feature we need is the statement return N, which causes the surrounding script or function to exit with exit status N. N is actually optional; it defaults to the exit value of the last command that was run. Scripts that finish without a return statement (i.e., every one we have seen so far) return whatever the last statement returned. If you use return within a function, it just exits the function. (In contrast, the statement exit N exits the entire script, no matter how deeply you are nested in functions.)
Getting back to our example: we save the exit status in both branches of the if, so that we can use it when we're done:
function pushd { # push current directory onto stack
dirname=$1
if cd ${dirname:?"missing directory name."} # if cd was successful
then
es=$?
DIRSTACK="$dirname $DIRSTACK"
print $DIRSTACK
else
es=$?
print still in $PWD.
fi
return $es
}
The assignment es=$? saves the exit status of cd in the variable es; the last line returns it as the function's exit status.
Exit statuses aren't very useful for anything other than their intended purpose. In particular, you may be tempted to use them as "return values" of functions, as you would with functions in C or Pascal. That won't work; you should use variables or command substitution instead to simulate this effect.
5.1.1.2. Advanced example: overriding a built-in command
Using the exit status and the return command, and taking advantage of the shell's command search order, we can write a cd function that overrides the built-in command.
Suppose we want our cd function to print the old and new directories automatically. Here is a version to put in your .profile or environment file:
function cd {
command cd "$@"
es=$?
print "$OLDPWD -> $PWD"
return $es
}
This function relies on the search order for commands listed in the last chapter. cd is a non-special built-in command, which means that it's found after functions. Thus, we can name our function cd, and the shell will find it first.
But how do we get to the "real" cd command? We need it to do the actual changing of directories. The answer is the built-in command named, oddly enough, command. Its job is to do exactly what we need: skip any functions named by the first argument, instead finding the built-in or external command and running it with the supplied arguments. In the Korn shell, using command followed by one of the special built-in commands keeps errors in that command from aborting the script. (This happens to be mandated by POSIX.)
WARNING: The command built-in is not special. If you define a function named command, there's no way to get to the real one anymore (except by removing the function, of course).
Anyway, back to the example. The first line uses command to run cd. It then saves the exit status in es, as we did earlier, so that it can be returned to the calling program or interactive shell. Finally, it prints the desired message and then returns the saved exit status. We'll see a more substantial "wrapper" for cd in Chapter 7.
5.1.1.3. Pipeline exit status
The exit status for a single command is just a simple number, whose value, as we've seen, is available in the special variable $?. But what about a pipeline? After all, you can hook an arbitrary number of commands together with pipes. Is the exit status of a pipeline that of the first command, the last command, or some command in between? By default, it is the exit status of the last command in the pipeline. (This is required by POSIX.)
The advantage to this behavior is that it's well-defined. If a pipeline fails, you know that it was the last command that failed. But if some intermediate process in the pipeline failed, you don't know about it. The set -o pipefail option allows you to change this behavior.[68] When you enable this option, the exit status of the pipeline is changed to that of the last command to fail. If no command fails, the exit status is 0. This still doesn't tell you which command in a pipeline failed, but at least you can tell that something went wrong somewhere and attempt to take corrective action.
[68] This option is available starting with ksh93g.
5.1.1.4. Interpreting exit status values
For ksh93, the exit status values for built-in commands and several exceptional cases have been regularized as follows:
| Value | Meaning |
|---|---|
| 1-125 | Command exited with failure |
| 2 | Invalid usage, with usage message (built-in commands) |
| 126 | Command found, but file is not executable |
| 127 | Command not found |
| 128-255 | External command exited with failure |
 256 256 |
Command died with a signal; subtract 256 to get signal number |
Signals are a more advanced feature; they are described in Chapter 8.
5.1.2. Combinations of Exit Statuses
One of the more obscure parts of Korn shell syntax allows you to combine exit statuses logically, so that you can test more than one thing at a time.
The syntax statement1 && statement2 means, "execute statement1, and if its exit status is 0, execute statement2." The syntax statement1 || statement2 is the converse: it means, "execute statement1, and if its exit status is not 0, execute statement2."
At first, these look like "if/then" and "if not/then" constructs, respectively. But they are really intended for use within conditions of if constructs -- as C programmers will readily understand.
It's much more useful to think of these constructs as "and" and "or," respectively. Consider this:
if statement1 && statement2
then
...
fi
In this case, statement1 is executed. If it returns a 0 status, then presumably it ran without error. Then statement2 runs. The then clause is executed if statement2 returns a 0 status. Conversely, if statement1 fails (returns a nonzero exit status), statement2 doesn't even run; the "last statement" in the condition was statement1, which failed -- so the then clause doesn't run. Taken all together, it's fair to conclude that the then clause runs if statement1 and statement2 both succeeded.
Similarly, consider this:
if statement1 || statement2
then
...
fi
If statement1 succeeds, statement2 does not run. This makes statement1 the last statement, which means that the then clause runs. On the other hand, if statement1 fails, statement2 runs, and whether the then clause runs or not depends on the success of statement2. The upshot is that the then clause runs if statement1 or statement2 succeeds.
As a simple example, assume that we need to write a script that checks a file for the presence of two words and just prints a message saying whether either word is in the file or not. We can use grep for this: it returns exit status 0 if it found the given string in its input, nonzero if not:
filename=$1
word1=$2
word2=$3
if grep $word1 $filename > /dev/null || grep $word2 $filename > /dev/null
then
print "$word1 or $word2 is in $filename."
fi
To ensure that all we get is the exit status, we've redirected the output of both grep invocations to the special file /dev/null, which is colloquially known as the "bit bucket." Any output directed to /dev/null effectively disappears. Without this redirection, the output would include the matching lines that contain the words, as well as our message. (Some versions of grep support a -s option for "silent," meaning no output. POSIX grep uses -q, meaning "quiet," for this. The most portable solution is to redirect output to /dev/null, as we've done here.)
The then clause of this code runs if either grep statement succeeds. Now assume that we want the script to say whether or not the input file contains both words. Here's how to do it:
filename=$1
word1=$2
word2=$3
if grep $word1 $filename > /dev/null && grep $word2 $filename > /dev/null
then
print "$word1 and $word2 are both in $filename."
fi
A minor note: when used with commands, && and || have equal precedence. However, when used inside [[...]] (discussed shortly), && has higher precedence than ||.
We'll see more examples of these logical operators later in this chapter and in the code for the kshdb debugger in Chapter 9.
5.1.3. Reversing the Sense of a Test
Sometimes, the most natural way to phrase a condition is in the negative. ("If Dave isn't there, then ...") Suppose we need to know that neither of two words is in a source file. In most scripts, when such is the case, you will see code like this:
if grep $word1 $filename > /dev/null || grep $word2 $filename > /dev/null
then
: # do nothing
else
print "$word1 and $word2 are both absent from $filename."
fi
The : command does nothing. The meaning, then, is "if word1 or word2 are present in filename, do nothing; otherwise, print a message." The Korn shell lets you do this more elegantly using the ! keyword (introduced in POSIX):
filename=$1
word1=$2
word2=$3
if ! grep $word1 $filename > /dev/null &&
! grep $word2 $filename > /dev/null
then
print "$word1 and $word2 are both absent from $filename."
fi
5.1.4. Condition Tests
Exit statuses are the only things an if construct can test. But that doesn't mean you can check only whether or not commands ran properly. The shell provides a way of testing a variety of conditions with the [[...]] construct.[69]
[69] The Korn shell also accepts the [...] and test commands. (There are built-in commands in all versions of ksh; they behave like the original external versions.) The [[...]] construct has many more options and is better integrated into the Korn shell language: specifically, word splitting and wildcard expansion aren't done within [[ and ]], making quoting less necessary. In addition, you can always tell operators from operands, since the operators cannot be the result of expansion.
You can use the construct to check many different attributes of a file (whether it exists, what type of file it is, what its permissions and ownership are, etc.), compare two files to see which is newer, do comparisons and pattern matching on strings, and more.
[[ condition ]] is actually a statement just like any other, except that the only thing it does is return an exit status that tells whether condition is true. Thus it fits within the if construct's syntax of if statements.
5.1.4.1. String comparisons
The double square brackets ([[...]]) surround expressions that include various types of operators. We start with the string comparison operators, which are listed in Table 5-1. (Notice that there are no operators for "greater than or equal" or "less than or equal.") In the table, str refers to an expression with a string value, and pat refers to a pattern that can contain wildcards (just like the patterns in the string-handling operators we saw in the last chapter). Note that these operators compare the lexicographic values of strings, so "10" < "2".
Table 5-1. String comparison operators
| Operator | True if... |
|---|---|
| str | str is non-null. |
| str == pat | str matches pat. |
| str = pat | str matches pat (obsolete). |
| str != pat | str does not match pat. |
| str1 < str2 | str1 is less than str2. |
| str1 > str2 | str1 is greater than str2. |
| -n str | str is not null (has length greater than 0). |
| -z str | str is null (has length 0). |
We can use one of these operators to improve our popd function, which reacts badly if you try to pop and the stack is empty. Recall that the code for popd is:
function popd { # cd to top, pop it off stack
top=${DIRSTACK%% *}
DIRSTACK=${DIRSTACK#* }
cd $top
print "$PWD"
}
If the stack is empty, $DIRSTACK is the null string, as is the expression ${DIRSTACK%% *}. This means that you will change to your home directory; instead, we want popd to print an error message and do nothing.
To accomplish this, we need to test for an empty stack, i.e., whether $DIRSTACK is null or not. Here is one way to do it:
function popd { # pop directory off the stack, cd there
if [[ -n $DIRSTACK ]]; then
top=${DIRSTACK%% *}
DIRSTACK=${DIRSTACK#* }
cd $top
print "$PWD"
else
print "stack empty, still in $PWD."
return 1
fi
}
Notice that instead of putting then on a separate line, we put it on the same line as the if after a semicolon, which is the shell's standard statement separator character. (There's a subtlety here. The shell only recognizes keywords such as if and then when they are at the beginning of a statement. This is so you can type, for example, print if then else is neat without getting syntax errors. Newlines and semicolons separate statements. Thus, the then on the same line as the if is correctly recognized after a semicolon, whereas without the semicolon, it would not be.)
We could have used operators other than -n. For example, we could have used -z and switched the code in the then and else clauses. We also could have used:
if [[ $DIRSTACK == "" ]]; then
...
While we're cleaning up code we wrote in the last chapter, let's fix up the error handling in the highest script (Task 4-1). The code for that script is:
filename=${1:?"filename missing."}
howmany=${2:-10}
sort -nr $filename | head -$howmany
Recall that if you omit the first argument (the filename), the shell prints the message highest: 1: filename missing. We can make this better by substituting a more standard "usage" message:
if [[ -z $1 ]]; then
print 'usage: highest filename [N]'
else
filename=$1
howmany=${2:-10}
sort -nr $filename | head -$howmany
fi
It is considered better programming style to enclose all of the code in the if-then-else, but such code can get confusing if you are writing a long script in which you need to check for errors and bail out at several points along the way. Therefore, a more usual style for shell programming is this:
if [[ -z $1 ]]; then
print 'usage: highest filename [-N]'
exit 1
fi
filename=$1
howmany=${2:-10}
sort -nr $filename | head -$howmany
The exit statement informs any calling program that needs to know whether it ran successfully or not. (You can also use return, but we feel that return should be reserved for use in functions.)
As an example of the == and != operators, we can add to our solution for Task 4-2, the shell script front-end to a C compiler. Recall that we are given a filename ending in .c (the source code file), and we need to construct a filename that is the same but ends in .o (the object code file). The modifications we will make have to do with other types of files that can be passed to a C compiler.
5.1.4.2. About C compilers
Before we get to the shell code, it is necessary to understand a few things about C compilers. We already know that they translate C source code into object code. Actually, they are part of compilation systems that also perform several other tasks. The term "compiler" is often used instead of "compilation system," so we'll use it in both senses.
We're interested here in two tasks that compilers perform other than compiling C code: they can translate assembly language code into object code, and they can link object code files together to form an executable program.
Assembly language works at a level that is close to the bare computer; each assembly statement is directly translatable into a statement of object code -- as opposed to C or other higher-level languages, in which a single source statement could translate to dozens of object code instructions. Translating a file of assembly language code into object code is called, not surprisingly, assembling the code.
Although many people consider assembly language to be quaintly old-fashioned -- like a typewriter in this age of WYSIWYG word processing and desktop publishing -- some programmers still need to use it when dealing with precise details of computer hardware. It's not uncommon for a program to consist of several files' worth of code in a higher-level language (such as C or C++) and a few low-level routines in assembly language.
The other task we'll worry about is called linking. Most real-world programs, unlike those assigned for a first-year programming class, consist of several files of source code, possibly written by several different programmers. These files are compiled into object code; then the object code must be combined to form the final, runnable program, known as an executable. The task of combining is often called "linking": each object code component usually contains references to other components, and these references must be resolved or "linked" together.
C compilation systems are capable of assembling files of assembly language into object code and linking object code files into executables. In particular, a compiler calls a separate assembler to deal with assembly code and a linker (also known as a "loader," "linking loader," or "link editor") to deal with object code files. These separate tools are known in the Unix world as as and ld, respectively. The C compiler itself is invoked with the command cc.
We can express all of these steps in terms of the suffixes of files passed as arguments to the C compiler. Basically, the compiler does the following:
If the argument ends in .c it's a C source file; compile into a .o object code file.
If the argument ends in .s, it's assembly language; assemble into a .o file.
If the argument ends in .o, do nothing; save for the linking step later.
If the argument ends in some other suffix, print an error message and exit.[70]
[70] For the purposes of this example. We know this isn't strictly true in real life.
Link all .o object code files into an executable file called a.out. This file is usually renamed to something more descriptive.
Step 3 allows object code files that have already been compiled (or assembled) to be reused to build other executables. For example, an object code file that implements an interface to a CD-ROM drive could be useful in any program that reads from CD-ROMs.
Figure 5-1 should make the compilation process clearer; it shows how the compiler processes the C source files a.c and b.c, the assembly language file c.s, and the already-compiled object code file d.o. In other words, it shows how the compiler handles the command cc a.c b.c c.s d.o.
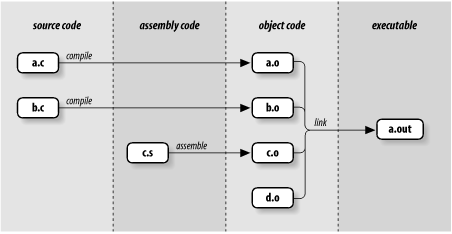
Figure 5-1. Files produced by a C compiler
Here is how we would begin to implement this behavior in a shell script. Assume that the variable filename holds the argument in question, and that ccom is the name of the program that actually compiles a C source file into object code. Assume further that ccom and as (assembler) take arguments for the names of the source and object files:
if [[ $filename == *.c ]]; then
objname=${filename%.c}.o
ccom "$filename" "$objname"
elif [[ $filename == *.s ]]; then
objname=${filename%.s}.o
as "$filename" "$objname"
elif [[ $filename != *.o ]]; then
print "error: $filename is not a source or object file."
exit 1
fi
further processing ...
Recall from the previous chapter that the expression ${filename%.c}.o deletes .c from filename and appends .o; ${filename%.s}.o does the analogous thing for files ending in .s.
The "further processing" is the link step, which we will see when we complete this example later in the chapter.
5.1.4.3. File attribute checking
The other kind of operator that can be used in conditional expressions checks a file for certain properties. There are 24 such operators. We cover those of most general interest here; the rest refer to arcana like sticky bits, sockets, and file descriptors, and thus are of interest only to systems programmers. Refer to Appendix B for the complete list. Table 5-2 lists those that interest us now.
Table 5-2. File attribute operators
| Operator | True if ... |
|---|---|
| -e file | file exists |
| -d file | file is a directory |
| -f file | file is a regular file (i.e., not a directory or other special type of file) |
| -L file | file is a symbolic link |
| -r file | You have read permission on file |
| -s file | file exists and is not empty |
| -w file | You have write permission on file |
| -x file | You have execute permission on file or directory search permission if it is a directory |
| -O file | You own file (the effective UID matches that of file) |
| -G file | Your effective group ID is the same as that of file |
| file1 -nt file2 | file1 is newer than file2[71] |
| file1 -ot file2 | file1 is older than file2 |
| file1 -ef file2 | file1 and file2 are the same file |
[71] Specifically, the -nt and -ot operators compare modification times of two files.
Before we get to an example, you should know that conditional expressions inside [[ and ]] can also be combined using the logical operators && and ||, just as we saw with plain shell commands in Section 5.1.2, earlier in this chapter. It's also possible to combine shell commands with conditional expressions using logical operators, like this:
if command && [[ condition ]]; then
...
Chapter 7 contains an example of this combination.
You can also negate the truth value of a conditional expression by preceding it with an exclamation point (!), so that ! expr evaluates to true only if expr is false. Furthermore, you can make complex logical expressions of conditional operators by grouping them with parentheses. (It turns out that this is true outside of the [[...]] construct as well. As we will see in Chapter 8, the construct (statement list) runs the statement list in a subshell, whose exit status is that of the last statement in the list.)
Here is how we would use two of the file operators to embellish (yet again) our pushd function. Instead of having cd determine whether the argument given is a valid directory -- i.e., by returning with a bad exit status if it's not -- we can do the checking ourselves. Here is the code:
function pushd { # push current directory onto stack
dirname=$1
if [[ -d $dirname && -x $dirname ]]; then
cd "$dirname"
DIRSTACK="$dirname DIRSTACK"
print "$DIRSTACK"
else
print "still in $PWD."
return 1
fi
}
The conditional expression evaluates to true only if the argument $1 is a directory (-d) and the user has permission to change to it (-x).[72] Notice that this conditional also handles the case where the argument is missing: $dirname is null, and since the null string isn't a valid directory name, the conditional will fail.
[72] Remember that the same permission flag that determines execute permission on a regular file determines search permission on a directory. This is why the -x operator checks both things depending on file type.
Task 5-1 presents a more comprehensive example of the use of file operators.
Task 5-1
Write a script that prints essentially the same information as ls -l but in a more user-friendly way.
Although this task requires relatively long-winded code, it is a straightforward application of many of the file operators:
if [[ ! -e $1 ]]; then
print "file $1 does not exist."
return 1
fi
if [[ -d $1 ]]; then
print -n "$1 is a directory that you may "
if [[ ! -x $1 ]]; then
print -n "not "
fi
print "search."
elif [[ -f $1 ]]; then
print "$1 is a regular file."
else
print "$1 is a special type of file."
fi
if [[ -O $1 ]]; then
print 'you own the file.'
else
print 'you do not own the file.'
fi
if [[ -r $1 ]]; then
print 'you have read permission on the file.'
fi
if [[ -w $1 ]]; then
print 'you have write permission on the file.'
fi
if [[ -x $1 && ! -d $1 ]]; then
print 'you have execute permission on the file.'
fi
We'll call this script fileinfo. Here's how it works:
The first conditional tests if the file given as argument does not exist (the exclamation point is the "not" operator; the spaces around it are required). If the file does not exist, the script prints an error message and exits with error status.
The second conditional tests if the file is a directory. If so, the first print prints part of a message; remember that the -n option tells print not to print a newline at the end. The inner conditional checks if you do not have search permission on the directory. If you don't have search permission, the word "not" is added to the partial message. Then, the message is completed with "search." and a newline.
The elif clause checks if the file is a regular file; if so, it prints a message.
The else clause accounts for the various special file types on recent Unix systems, such as sockets, devices, FIFO files, etc. We assume that the casual user isn't interested in their details.
The next conditional tests to see if you own the file (i.e., if its owner ID is the same as your effective User ID). If so, it prints a message saying you own it. (Real and effective User and Group IDs are explained in Chapter 10.)
The next two conditionals test for your read and write permission on the file.
The last conditional checks if you can execute the file. It checks to see if you have execute permission and that the file is not a directory. (If the file were a directory, execute permission would really mean directory search permission.)
As an example of fileinfo's output, assume that you do an ls -l of your current directory and it contains these lines:
-rwxr-xr-x 1 billr other 594 May 28 09:49 bob -rw-r-r- 1 billr other 42715 Apr 21 23:39 custom.tbl drwxr-xr-x 2 billr other 64 Jan 12 13:42 exp -r-r-r- 1 root other 557 Mar 28 12:41 lpst
custom.tbl and lpst are regular text files, exp is a directory, and bob is a shell script. Typing fileinfo bob produces this output:
bob is a regular file. you own the file. you have read permission on the file. you have write permission on the file. you have execute permission on the file.
Typing fileinfo custom.tbl results in this:
custom.tbl is a regular file. you own the file. you have read permission on the file. you have write permission on the file.
Typing fileinfo exp results in this:
exp is a directory that you may search. you own the file. you have read permission on the file. you have write permission on the file.
Finally, typing fileinfo lpst produces this:
lpst is a regular file. you do not own the file. you have read permission on the file.
5.1.4.4. Arithmetic conditionals
The shell also provides a set of arithmetic tests. These are different from character string comparisons like < and >, which compare lexicographic values of strings, not numeric values. For example, "6" is greater than "57" lexicographically, just as "p" is greater than "ox," but of course the opposite is true when they're compared as numbers.
The arithmetic comparison operators are summarized in Table 5-3. Fortran programmers will find their syntax slightly familiar.
Table 5-3. Arithmetic test operators
| Test | Comparison | Test | Comparison |
|---|---|---|---|
| -lt | Less than | -gt | Greater than |
| -le | Less than or equal | -ge | Greater than or equal |
| -eq | Equal | -ne | Not equal |
You'll find these to be of the most use in the context of the numeric variables we'll see in the next chapter. They're necessary if you want to combine numeric tests with other types of tests within the same conditional expression.
However, the shell has a separate syntax for conditional expressions that involve only numbers. (This syntax is covered in Chapter 6.) It's considerably more efficient, as well as more general, so you should use it in preference to the arithmetic test operators listed above.
In fact, some of the ksh93 documentation considers these numeric conditionals to be obsolete. Therefore, if you need to combine [[...]] and numeric tests, do it using the shell's !, &&, and || operators outside the [[...]], instead of inside them. Again, we'll cover the shell's numeric conditionals in the next chapter.
|  | |
| 4.7. Advanced Examples: pushd and popd |  | 5.2. for |

Copyright © 2003 O'Reilly & Associates. All rights reserved.