|
|

The objective of this document is to provide useful information about managing a wholesale dial network. Material presented in this chapter to support that objective address the following topics:
Internet Service Providers (ISPs) and Content Providers (or portals) typically provide dial-up Internet access as part of their service package. However, many of these providers do not want to invest the time in building out dial-up access infrastructure, or cannot build out infrastructure fast enough—particularly when expanding into new regions. Other retail companies want to offer private label Internet access as part of their brand, but do not want to build out their own service.
Wholesale dial is a service that offers these providers with cost and efficiency savings by allowing a separate wholesale service provider to manage the dial-up needs of the ISPs or portals.
Cisco's wholesale dial outsourcing solution, also referred to as the Cisco SS7 interconnect (IC) for access servers, delivers virtual port capability across any number of Cisco remote access servers. Coupled with sophisticated port policy management that guarantees port availability to wholesale customers, Cisco enables carriers and ISPs to offer unique service offerings that can drive incremental revenue while holding down operational costs. Figure 2-1 illustrates an example wholesale dial environment.
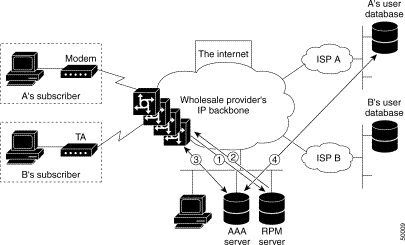
Out-sourced corporate dial-up is directly applicable to both ISPs and carriers, including incumbent local exchange carriers (ILECs), competitive LECs (CLECs), inter-exchange carriers (IXCs), and Post, Telegraph, and Telephone services (PTTs).
Wholesale dial service is typically purchased for one or more of the following reasons (how each fits into the wholesale dial scheme is illustrated in Figure 2-1):
1. To outsource an activity that is not part of the core business or value proposition of the service provider. This applies to small ISPs, vertical market ISPs, content providers/portals, and value-added network providers.
2. To provide dial-up access points outside the current geographical reach of the service provider. This applies to ILECs, regional CLECs, and regional ISPs.
3. To grow dial capacity very quickly. This applies to all service providers.
4. To offer private label Internet access as a form of affinity marketing. An example of affinity marketing might be a PC retailer distributor that offers private label Internet access for one year free with its PCs.
Some service providers now focus on providing content-based services, or various vertical-market products. For example, a service provider might focus on providing legal case law access to attorneys via a web site. As part of the attorneys' service package, dial-up access must be provided. The core competency of the service provider is the provision of content and customer care—not in deploying and managing dial access servers. Purchasing wholesale dial ports from a service provider offers a way for the content provider to deliver the complete service package to its customers while outsourcing operation of the dial-up service.
Many ISPs are regional, offering service over a defined geographical area. But a significant subset of an ISP's customers commonly require access across a broader area. In particular, a business might require that dial-up access be provided in the locations where it has offices before signing a contract for service. For a regional ISP, growing outside of its region can be expensive and time consuming. Buying wholesale dial ports in the regions where it does not have coverage allows the ISP to meet customer needs while limiting the capital and time consumed with building out a new point-of-presence (POP). The ISP may decide to expand into that region anyway, but by using a dial wholesale approach, expansion can be planned and run to the ISP's schedule.
ISPs also face skyrocketing demand for Internet access that might be difficult to meet for a number of reasons. In North America, demand for T1 voice circuits is so great in some areas that the ILECs cannot meet demand. Their response is to quote extremely long install intervals. The ILECs, in turn, are facing equipment shortages from the major switch vendors that cannot provide the line and control cards for their Class 5 switches. These cards are used to provision voice T1s. Often T1 PRIs are the most difficult to obtain, because they require additional ISDN controller cards within the switch. Unfortunately, ISDN PRI is exactly the service ISPs require as it provides top connect speeds for V.90 callers.
The result is that ISPs often cannot build out their POPs, even if they overcome the significant logistical challenges of purchasing, deploying, and configuring a large number of new dial access servers. They are limited by the ability of the carriers to provide circuits. In this case, purchasing wholesale ports allows ISPs to expand ahead of their POP build-out capability.
This section introduces several topics used in this document to help build a conceptual framework for managing wholesale dial networks. Descriptions here address:
Network management is the practice of managing a communication network by monitoring, controlling, configuring, and securing the devices of the network. The principal goals of network management are:
Probably the single most commonly cited description of network management functions is based on the Open Systems Interconnect (OSI) Network Management Systems (NMS) model. This model is divided into five groups known collectively as FCAPS, representing fault, configuration, accounting, performance, and security management areas. The following brief descriptions summarize the general scope of coverage of each FCAPS network management component. This understanding of FCAPS is used as a foundation for the descriptions that follow later in this document. Throughout this document, each recommended product and component described is defined by how it fits into the FCAPS model.
Depending on the information you require regarding specific types of events, some of components of the FCAPS model are easier to implement. For example, fault management is one the easiest FCAPS components to implement successfully if you are looking for a general fault (which represent approximately 90 percent of all faults). Furthermore, fault management is the best understood of the FCAPS components. However, finding more subtle faults (that are not simply service outages)—such as high levels of errors or high levels of discarded packets—requires much more intricate analysis of a network's operational data.
The section that follows summarizes the fundamental management components around which an FCAPS-based network management approach is built.
The FCAPS model consists of the following components (each is summarized in a brief statement that follows):
Fault management is concerned with detecting, diagnosing, and correcting network and system faults (outages and degradations). Fault management products typically provide for alert handling and event management functions, and can include the diagnostic tools needed to isolate faults to facilitate corrective or alternative actions. See "Wholesale Dial Management Overview" later in this chapter for implementation details.
Configuration management is concerned with the installation, identification, inventory removal, and configuration of hardware (including components such a cards, modules, memory, and software), software, firmware, and services. Configuration management also provides for monitoring and managing the deployment status of a device. The configuration management functional area includes software management, change control, and inventory management. See "Configuration Management Implementation" later in this chapter for implementation details.
Accounting management is concerned with tracking the use of resources in a network An example would be the allocation of billing costs for both time and services rendered by a service provider. Accounting management also addresses billing for utilization of communications and computing facilities, as well as tracking user access to networks and the resources accessed by those users. Accounting management systems typically include knowledge of tariff structures. See "Accounting Management Implementation" later in this chapter for implementation details.
Performance management is concerned with the measurement and analysis of both short-term and long-term network and system statistics related to:
Performance management is also used to determine whether there are any outages on a network.
Ideally, performance data can be used to prevent future failures by helping network planners identify trends that suggest capacity utilization or other problems before such problems affect users or services. Performance management tools are also used to assist in planning, design, and performance-tuning for improved network and systems efficiency. See "Performance Management Implementation Recommendations" later in this chapter for implementation details.
Security management is concerned with the management of security for the communications network and the network management infrastructure. Security management tools can address user access rights, data privacy, alarms and audit trails of security attacks/breaches, the management of security mechanisms, and password distribution. See "Security Management Implementation" later in this chapter for implementation details.
The Simple Network Management Protocol (SNMP) is an application-layer protocol that facilitates the exchange of management information between a NMS, agents, and managed devices. SNMP uses the Transmission Control Protocol/Internet Protocol (TCP/IP) protocol suite. There are three versions of SNMP:
Today, SNMP is the single, most-widely implemented network management standard. SNMP has achieved widespread implementation and acceptance largely due its inherently limited scope. SNMP's success stems from wide-support of a well-defined set of commands and responses. SNMP has evolved to permit vendor flexibility in terms of management information base (MIB) extensions. Two essential SNMP components are summarized briefly here:
SNMP is a simple request-response protocol. The network-management system issues a request, and managed devices return responses. This behavior is implemented by using one of four protocol operations: Get, GetNext, Set, and Trap. The Get operation is used by the NMS to retrieve the value of one or more object instances from an agent (within the managed device). If the agent responding to the Get operation cannot provide values for all the object instances in a list, it does not provide any values. The GetNext operation is used by the NMS to retrieve the value of the next object instance in a table or list within an agent. The Set operation is used by the NMS to set the values of object instances within an agent. The Trap operation is used by agents to asynchronously inform the NMS of a significant event.
Figure 2-2 illustrates two SNMP polling negotiations, the sending of a set command, and a Trap communication.
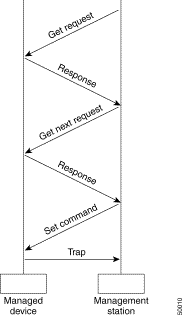
SNMP polls are requests for information sent from the NMS to SNMP agents usually in a set intervals. In a basic polling operation, an NMS polls the managed device with an SNMP Get request. The managed device's SNMP agent responds to the request and provides the information needed. Fault polling is generally performed every 5 to 15 minutes.
If a SNMP Trap (for example, a message indicating a port failure) was not received by the management station or if the device was unable to send a trap because the managed device suffered some sort of catastrophic outage, the NMS can detect the outage in a reasonable timeframe via polling. Performance and configuration management functions can also use polling.
For more information on SNMP Polling refer to "Wholesale Dial SNMP MIBs."
An SNMP trap is an unsolicited message sent by an SNMP agent to an SNMP manager when certain events occur on the network.
SYSLOG messages are system messages that can either be configured to be collected and retained on a managed device or that can be configured to be collected and sent to a network server that maintains a file of SYSLOG messages. A wide array of information types are captured in SYSLOG messages—from login records to configuration changes to memory errors.
SYSLOG messages play an important role in managing a wholesale dial network. For example, SYSLOG messages can be configured to be sent at the end of every connection. Such SYSLOG messages are invaluable for troubleshooting individual connections. Information can be combined to provide statistical characterizations and to then determine whether an asynchronous port is experiencing unusual problems such as premature disconnects or speed negotiation problems.
While SYSLOG messages generate critical diagnostic information, they can also pose storage challenges if not properly managed. Consider the modem call terse SYSLOG message. This message provides information about a user, the type of connection made, the speed of a connection, and the disconnect cause. A server must have sufficient storage space to accumulate this data for a large-scale dial-based network. The server must also have an reasonable log rotation scheme so that messages older than a certain date are purged. If messages are not periodically purged, the volume of messages sent from devices can overwhelm a SYSLOG server.
Remote Monitoring (RMON) is a standard monitoring specification. It is a subset of SNMP that enables various network probes and devices to exchange network-monitoring data with an NMS. The RMON specification defines a set of statistics and functions that can be exchanged between RMON-compliant console managers and network probes.
RMON became a draft standard in 1995 as IETF RFC 1757. RMON is in effect a set of MIBs primarily used to performance monitor network entities. RMON functionality can reside within the SNMP agent of a managed device or within an RMON probe. RMON probes exist on a network in passive mode monitoring and collecting network statistical information.
RMON functions that reside within managed agents usually lack some of the Object Identifiers (OIDs) found in an RMON probe. However, agents that include RMON can send alerts when a specific threshold is surpassed.
This section describes how each of the components of the FCAPS model pertain to a wholesale dial network. It consist of the following six topics:
Each network technology has unique characteristics and unique diagnostic events that typify trouble conditions for components on a network or for the entire network. Dial networks, including wholesale dial networks, are not exceptions.
Dial service providers can face an environment featuring thousands of interfaces in a dispersed topology of multiple remote Network Access Servers (NASs). The NAS interfaces are typically toggling from active to inactive connection states.
For most network topologies, it is a bad thing when multiple interfaces flap continuously from active to inactive states. Flapping typically requires immediate attention, because angry users cannot access network services. Dial service is unique in that state flapping is the norm and usually can be ignored for asynchronous dial ports.
However, the following interfaces and functions must be operational at all times to ensure continuous connectivity in a dial environment:
Since all the components in a wholesale dial environment must work together to ensure completed/connected calls, any single component failure for any length of time can block or abruptly terminate thousands of connections.
Because of the limited number on interfaces to monitor in a wholesale dial network, a few basic MIBs can be used to monitor all wholesale dial components for faults. Table 2-1 summarizes a specific MIB II object that can provide relevant status information.
| SNMP MIB II Object Name | Object Description | Object ID | Poll Interval |
|---|---|---|---|
ifAdminStatus | The desired state of the interface. The testing(3) state indicates that no operational packets can be passed. | .1.3.6.1.2.1.2.2.1.7 | 5 minutes |
ifOperStatus | The current operational state of the interface. The testing(3) state indicates that no operational packets can be passed. | .1.3.6.1.2.1.2.2.8 | 5 minutes1 |
ifInDiscards | The number of inbound packets which were chosen to be discarded even though no errors had been detected to prevent their being deliverable to a higher-layer protocol. One possible reason for discarding such a packet could be to free up buffer space. | .1.3.6.1.2.1.2.2.1.13 | 15 minutes |
ifInErrors | The number of inbound packets that contained errors preventing them from being deliverable to a higher-layer protocol. | .1.3.6.1.2.1.2.2.1.14 | 15 minutes |
ifOutDiscards | The number of outbound packets which were chosen to be discarded even though no errors had been detected to prevent their being transmitted. One possible reason for discarding such a packet could be to free up buffer space. | .1.3.6.1.2.1.2.2.1.19 | 15 minutes |
ifOutErrors | The number of outbound packets that could not be transmitted because of errors. | .1.3.6.1.2.1.2.2.1.20 | 15 minutes |
| 1Value not equal to 1. |
To achieve effective fault management of a wholesale dial network, be sure to assess network elements on a component-by-component basis to determine how to best monitor each. The following network elements require careful consideration when planning for wholesale dial fault management.
For fault monitoring on a NAS, focus on the availability of the NAS itself. The principal fault monitoring mechanism is SNMP polling, as summarized in "SNMP Polling" earlier in this chapter. Additional points for failure include: NAS DS3 interface; NAS network interface to the accessed network; and, the network interface to the SS7.
If any of these interfaces are inactive, the NAS cannot support any connections.
 |
Note See "Performance Management Implementation Recommendations" for additional NAS-related components requiring monitoring. |
As stated in earlier in this chapter each of the interfaces should be monitored with the ifOperStatus MIB.
This is done automatically if you purchase a node manager product (such as HP OpenView). Using the OID directly only occurs if you manually set up polling. Manual configuration of polling might be required if you need more detailed polling, or if you are creating your own application.
The SC2200 connects directly to the telephone network. The NAS receives signalling for its DS3 through the SC2200. For the SC2200, monitor:
The SLT is a card that is installed in a Cisco 3600 chassis. For the SLT, only the up/down (active/inactive) status of the interface can be monitored. No statistical information can be obtained from the SLT. Statistical information must be gathered from the SC2200.
The Resource Pool Management Server (RPMS) is a software package running on a Sun Microsystems server. For RPMS, monitor:
|
Note The RPMS server is an excellent source of accounting data, because every call must be authorized by the RPMS in a wholesale dial network. See "Accounting Management Implementation" for more information. |
There are supporting components on a wholesale dial network that interconnect all of the components of the network (such as high-end routers and switches within the Telco's core network fabric). For the most part these devices can be monitored as if they were LAN/WAN components. It is extremely critical to the wholesale dial network that these components work properly, but the specifics of ensuring proper functioning are beyond the scope of this document.
Configuration management for a wholesale dial network is similar to any other type of network. The principals are the same. Configuration management deals with the configuration of devices (how the devices are setup to run), software management, and inventory management. Inventory management can be broken down into two components: what devices reside in the network; and, what components reside in the devices.
CiscoWorks 2000 Cisco Resource Manager Essentials (CRME) provides tools supporting configuration management of a wholesale dial network for both the network devices and embedded components. CRME is an element manager for Cisco switches, routers, and NASs.
|
Note An element manager is a software package that manages a specific category of devices in a network. Element managers usually are created by each vendor for its specific products. Element manager can manage an entire vendor product line; however, an element manager might also manage specific types of devices such as switches, routers, or access servers. |
CRME is comprised of a set of tools presented collectively in a single web-based user interface. Some capabilities of CRME include the following:
To configure the SC2000, use the Cisco Media Gateway Controller Manager (CMM) tool. The CMM has a graphical user interface (GUI) that uses SNMP to configure and provision your Cisco SC2200. CMM provides all the necessary tools for configuration management of the SC2200.
Additional information about CMM can be found at the following Cisco Connection Online web pages:
Accounting management is the most complex component of the FCAPS model to effectively implement. Accounting in a wholesale dial network usually concerns tracking end user connections. For example, network managers might want to know which users have called in, how long they remain connected, and to which ISP they belong.
The information needed to build accounting records are available in several locations. The modem call terse record is a SYSLOG message that is generated at the termination of every dial connection. The modem call terse record provides useful information that can help create trending analysis, and can help in troubleshooting specific connection problems. However, the modem call terse record is generated at the time of a call termination and cannot provide any information on active calls.
Another good source for collecting call information are the Remote Authentication Dial-in User Service (RADIUS) call records. These are generated at call generation. They are more difficult to capture, but provide information on active calls.
For generalized call accounting data, the RPMS server is an effective repository for these records. RPMS gives retail providers various statistics, such as:
RPMS also provides information indicating that a retailer has reached its resource limit and has started to reject calls by providing a call reject counter.
The application of RPMS statistics in this instance illustrates how the lines between FCAPS functions can be blurred, given that these same RPMS-derived statistics can be categorized with performance statistics.
For the purposes of this document, these statistics are included with accounting statistics because of the way that the statistics can be used. Consider a situation in which every retailer connected to a wholesale dial environment reaches its allocated capacity, although the wholesale dial network itself is easily within its total capacity constraint. In this instance, the RPMS call statistics are in effect accounting data—not performance data.
The subject of accounting in a dial network can easily generate several documents. Detailed information on dial accounting is beyond the scope of this document.
As stated earlier in this chapter, performance management is concerned with the measurement and analysis of both short-term and long-term network and system statistics related to:
Performance management in a wholesale dial network is relatively uncomplicated, with the exception of modem performance management. It can be split into two categories:
The performance management descriptions that follow are divided into the following sections:
The performance management discussion here focuses on the performance management capabilities of individual NASs, not the network in aggregate. Three NAS interfaces require performance monitoring:
For network performance monitoring, use a tool such as Concord's Network Health. Network Health is specifically designed to monitor network performance. Network Health allows operators to view network, device, and segment statistics in a web-based format. Concord's Network Health can also send a trap to a fault management application if a specific event is detected (such as a threshold being exceeded).
Because of the intermittent nature of a dial-based connectivity, DS3 or T1 interface throughput is rarely an issue. The reason is that each call is limited to 64Kb per channel. As a result, there is never a large amount of data saturating a DS3 or T1 link.
The statistics graphed in Figure 2-3 and Figure 2-4 illustrate the total number of calls connected during a single day (Figure 2-3) and over a one week interval (Figure 2-4). To determine the capacity of a NAS, first determine the number of channels available for accepting calls, then determine the number of modems in the chassis. The lesser of these two is the total number of calls that can be accepted by this NAS.
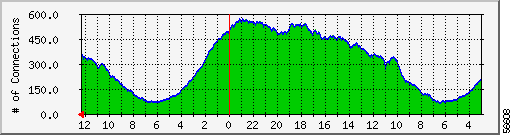
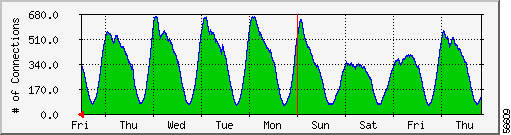
Determining the utilization of a point-of-presence (POP) is a little more difficult, because there are usually multiple NASs per POP. To create a single graph for a POP, first determine the capacity of each NAS, sum those, and then assemble a cumulative graph of all NASs.
With dial traffic, you can typically expect approximately 80 percent idle time on a dial port. This results in relatively low total throughput from a NAS to the supporting network. Figure 2-5 illustrates how statistical graphing can help characterize the traffic behavior of a dial network.
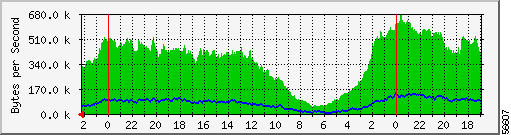
Figure 2-5 depicts a dial network featuring a 5:1 ratio of bytes received (downstream) in comparison to bytes sent (upstream). This suggests that the modem users receive five times as much data as they send on a dial network.
Some background on the graphic in Figure 2-5—The NAS graphed in Figure 2-5 has a DS3 link—for a total of 672 available channels. The all time peak for this NAS is five percent utilization of the Ethernet port that connects this NAS to the supporting network. The average is less than three percent.
|
Note Twelve T1/E1 lines can be used on the AS5800 instead of a DS3 link. However, T1/E1 lines are rarely implemented in a wholesale dial network. DS3 lines are more commonly used due to their ability to efficiently handle large numbers of simultaneous connections. |
The interface that connects the NAS to the network also experiences a low utilization rate. If high utilization rates are registered, the likely causes are problems that are not related to the number of dial users or connections. However it is a good practice to monitor this interface for general performance statistics (such as utilization, collisions, and CRC errors).
Table 2-2 lists MIB objects that can be used to monitor overall connection activity.
| MIB Object Name | Object Description | Object ID | Poll Interval |
|---|---|---|---|
cpuActive | Displays the number of current dial connections | .1.3.6.1.4.1.9.10.19.1.1.4.0 | 5 minutes |
cpmPPPCalls | Displays the number of current PPP connections | .1.3.6.1.4.1.9.10.19.1.1.5.0 | 5 minutes |
Look for utilization rates of 10 percent or less on a 100Mb Ethernet interface, with an occasional spike. This interface also should be connected to a switch, so you should see 0 collisions, 0 CRC errors, and 0 retransmissions. If any of these metrics are being exceeded, a problem in the network exists that warrants additional diagnostic assessment.
The SLT cannot be managed directly. The only information you can get from the SLT is standard MIB II information. All statistical information must be polled through the SC2200.
Monitoring modem performance is difficult in a dial network because it is impractical to poll performance statistics for every group of modems used for general network access. The performance of a set of modems largely depends on how often they are called, the type of modem calling, how long the call lasts, and how much data is sent through the connection.
For true modem performance statistics, a modem with a known protocol such as V.90 calling through the PSTN connecting to the NAS for a specific amount of time, transmitting a specific amount of traffic is the only way to obtain accurate and meaningful performance statistics.
Currently, no commercial tool exists to do this; however, one can easily be built using a UNIX box and a PPP daemon such as pppd. To set up a generic dialer tool on a UNIX workstation, example steps are as follows:
Step 1 Connect a modem to the serial port.
Step 2 Write a script that initiates the call to a DNIS for a specific amount of time (such as 15 minutes). During that time the script specifies that the workstation transmits a specific amount of data. An example would be for the script to specify that the workstation send a file via the file transfer protocol (FTP) to another workstation attached to the same network.
Step 3 The modem call terse records can then be examined to determine which ports the modem tool connected to and if any problems were encountered during the call process.
Look for these problems:
For the purposes of this document, monitoring call performance focuses on the total number of calls a wholesale dial infrastructure can handle and how efficiently the wholesale dial provider connects calls for the retailer. This includes how calls are rerouted if a POP becomes saturated.
RPMS tracks call resources. The RPMS server is used to allocate a pre-determined number of ports to a specific customer (ISP/retailer) in order to complete calls. RPMS tracks associated statistics both on a per ISP basis and in aggregate.
|
Note Remote monitoring using RPMS is facilitated by its web-based interface. |
SC2200 performance can be monitored through its element management tool—the Cisco CMM. It can also be monitored by a third party tool such as Concord Network Health.
The useful statistics to monitor on an SC2200 are as follows:
|
Note The MIBs associated with these statistics are SNMP manageable. |
In addition, important system data points to monitor include:
Refer to the following site for related MIB information:
Availability management can be split into three subtopics:
|
Note Because of the limited number on interfaces to monitor in a wholesale dial network, a few basic SNMP MIBs can be used to monitor all the wholesale dial components for faults. For related information, see Table 2-1 in "Fault Management for Wholesale Dial Components." |
Monitoring device availability involves determining whether a device responding to ICMP echos and SNMP requests. Many applications can measure device availability, including Concord Network Health, Cisco Resource Manager Essentials (CRME), and Veritas' NerveCenter. Depending on the SNMP request or ICMP echo intervals, it is possible for a device to reload (reboot). If the ColdStart SNMP trap is not received by the SNMP Manager, an operations center may never know that a device has reloaded. One way determine whether a reboot has occurred is to generate an SNMP request of the sysUpTime object. Table 2-3 illustrates example attributes for sysUpTime.
| MIBII Object Name | Object Description | Object ID | Poll Interval | Threshold |
|---|---|---|---|---|
sysUpTime | System uptime in 1/100ths of seconds | .1.3.6.1.2.1.1.3 | 5 minutes | Less than 30000 |
The example illustrated in Table 2-3 specifies a 5-minute polling cycle. With a threshold of less than 30000 timeticks (where, 30000 * 1/100 = 300 seconds = 5 minutes), if a device ever responds with a value less than 30000, you can conclude that the device has reloaded. However, if a network device sees little change or an upgrade occurs, it is possible for this counter to wrap (232 1/100 seconds, or approximately 497 days), which would lead to a false alarm.
Monitoring path availability focuses on determining whether a packet can reach its intended destination. This can be measured simply using Internet Control Message Protocol (ICMP) echo, but the information provided by this measurement is limited. Cisco's Service Assurance Agent (SA Agent) provides greater monitoring flexibility to measure path availability.
SA Agent is an enhancement of (and a new name for) the Response Time Reporter (RTR) introduced in Cisco IOS release 11.2. RTR allows you to monitor network performance by measuring key Service Level Agreement (SLA) metrics such as response time, network resources, availability, jitter, connect time, packet loss, and application performance.
With Cisco IOS release 12.0(5)T, the SA Agent allows you to:
The SA Agent also extends IP support and enhances the management and measurement of enterprise and service provider networks. With the growing importance of mission-critical network applications and the emergence of globally-networked enterprises, SLAs are increasingly required that provide for minimum acceptable levels of service. The SA Agent provides a reliable mechanism to accurately monitor and measure the key metrics in SLAs.
The SA Agent allows you to measure and monitor the following:
Specifically, the SA Agent allows you to define the following operations:
SA Agent can be configured via the Cisco IOS command line interface (CLI), SNMP (via the RTTMON MIB), or through applications such as Cisco's Internetwork Performance Monitor (IPM) or Cisco's Service Management Solution (SMS), consisting of Cisco Service Level Manager and the ME1100 Management Engines. Cisco IPM and Cisco SMS also can act as data collectors as well as provide data archiving and reporting.
Regardless of how you deploy SA Agent in the network environment, you can configure SA Agent to send a SNMP trap to your SNMP manager when a configured threshold is exceeded. This presents the possibility of alerting your Network Operations Center (NOC) to specific path failures and performance degradation issues.
For more information, please refer to the following documents:
Selecting a tool for monitoring service availability depends on the service being measured. Cisco SA Agent provides metrics for key network services such as DHCP, DNS, and HTTP requests. To measure application availability and response, Concord provides various add-on modules to the Network Health core application. Other vendors provide applications for measuring specific application availability and performance.
Security management in this document focuses on authentication, authorization, and accounting (AAA) management for dial access to ports and access to devices. To fully address the issue of security management, you must consider the complete range of network access security issues—including firewall, server security, and device security. These topics are beyond the scope of this document.
A wholesale dial provider cannot realistically keep up with access requests from customers/retailers (ISPs and other dial retailers). The best way to deal with this issue is to require each ISP to maintain its own AAA server. For dial access, that usually involves a RADIUS-based AAA server solution.
In addition to the basic dial connectivity security provided by a AAA server environment, it is also good practice to control and monitor access to network devices themselves (such as NASs and routers). To control and monitor access to the network devices, implement a AAA server using Access Registrar software. This Access Registrar-based AAA server should be a separate entity (not an integral function of any other dial access servers). Access Registrar software is based on the AAA model of network security and it incorporates both Terminal Access Controller Access Control System Plus (TACACS+) and RADIUS protocols. By using AAA you can monitor and track individuals accessing network devices.
For more information about AAA implementation, refer to following document:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Posted: Thu Sep 26 10:35:51 PDT 2002
All contents are Copyright © 1992--2002 Cisco Systems, Inc. All rights reserved.
Important Notices and Privacy Statement.