|
|

For purposes of this chapter, it is assumed that you have read Chapter 1, "Analyzer Overview," which describes the concepts and principles essential to understanding and using the Analyzer.
This chapter tells you how to use the Analyzer by means of the graphical user interface (GUI) of the Display module. The Display modules, which can be installed on one or more host workstations or PCs in your network, incorporates an extensive menu system for invoking Analyzer functionality.
This chapter contains the following sections:
Take the following into account when you use the FlowCollector and the Analyzer:
For instructions on starting all the Analyzer modules, including the Display module, see the "Installing and Setting Up the Analyzer" section in Chapter 2.
As noted in Chapter 1, the Analyzer displays two types of traffic information:
The traffic information for these two data types is processed and arranged into a spreadsheet-like matrix of columns and rows in the display pane of the Display module.
The following sections describe the NetFlow and TMS data aggregation schemes available for use with the FlowCollector and the Analyzer.
NetFlow data aggregation schemes consist of key columns and value columns.
Table 3-1 summarizes the NetFlow data aggregation schemes available in the current releases of the FlowCollector and the Analyzer by listing: a) the name of the NetFlow data aggregation scheme; b) the name(s) of the key columns incorporated into the Analyzer display output for each aggregation scheme; and c) a description of the contents of each key column in the aggregation scheme output.
| Aggregation Scheme Name | Key Column Name in Data Array | Column Contents |
|---|---|---|
Source | IP address of the device that originated the traffic flow. | |
Destination | IP address of the device that received the traffic flow. | |
Source | IP address of the source device that originated the traffic flow. | |
IP transport protocol used in transmitting the monitored traffic. | ||
Destination | IP address of the destination device. | |
Source | IP address of the source device. | |
Source | IP address of the source device. | |
Source | IP address of the source device. | |
SrcPort | Application port number of the source device. | |
DestPort | Application port number of the destination device. | |
Source AS (autonomous system) number. | ||
Source | IP address of the source device. | |
Source | IP address of the source device. | |
Source | IP address of the source device.
| |
Source AS | Autonomous system (AS) from which the monitored traffic originated. | |
Source Port | On source host, the application port from which the monitored traffic was sent. This may be a port number or (if the FlowCollector is so configured) a text string. | |
Source (Subnet) | IP address of the network from which the monitored traffic originated. | |
Destination (Subnet) | IP address of the network to which the monitored traffic was delivered. | |
Source (Subnet) | IP address of the network from which the monitored traffic originated. |
The key columns of a NetFlow data aggregation scheme represent the traffic information that the FlowCollector looks for in sorting and processing UDP datagrams received from NetFlow exporting devices in your network. Once the FlowCollector processes the data according to the aggregation scheme currently in effect, it stores the data in its local NetFlow directory.
The value columns of a NetFlow data aggregation scheme contain the statistical information extracted from the UDP datagrams for a given traffic flow. The value columns, which are common to all of the NetFlow data aggregation schemes (except for the CallRecord aggregation scheme, as noted in Table 3-1), are listed and described in Table 3-2.
For more detailed information about the FlowCollector and the associated NetFlow data aggregation schemes, consult the NetFlow FlowCollector Installation and User Guide.
| Value Column Name | Value Column Contents |
|---|---|
Total number of packets in the monitored traffic flow. | |
Pkts/Sec | Packet rate per second of the monitored traffic flow. |
Total number of bytes in the monitored traffic flow. | |
Kbits/Sec | Total bit rate in kilobits per second. |
Flows | Total number of monitored traffic flows. |
Flows/Min | Number of flows monitored per minute. |
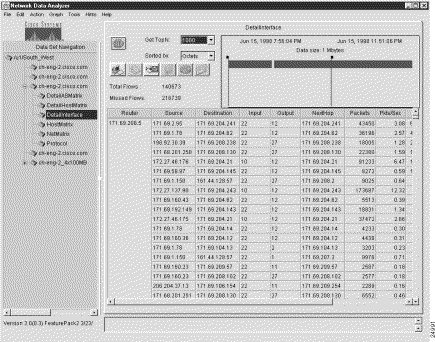
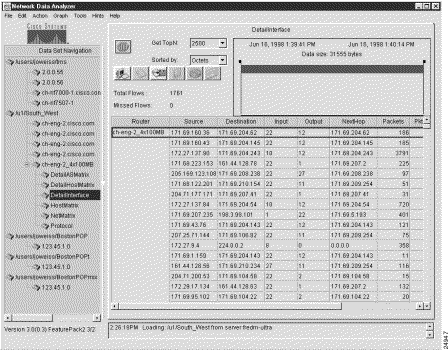
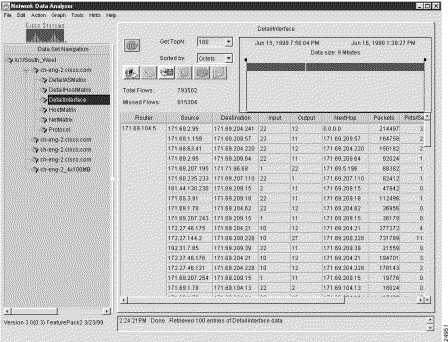
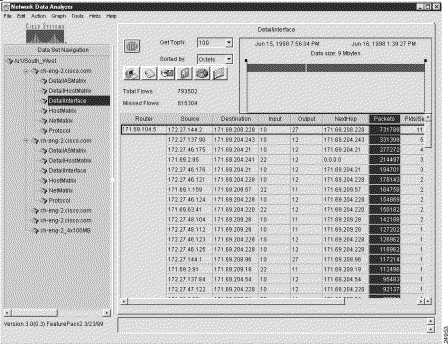
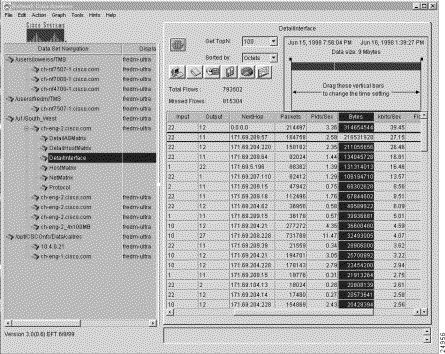
Figure 3-1 shows a sample display of a typical NetFlow data aggregation scheme, in this case, the DetailInterface aggregation scheme.
Due to space limitations in the display pane, not all of the columns in an aggregation scheme can be displayed in the pane at one time. Hence, aggregation scheme data typically overflows the available space in the display pane. Therefore, vertical and horizontal scroll bars are incorporated into the pane to enable you to traverse to any area of interest in the overall data array.
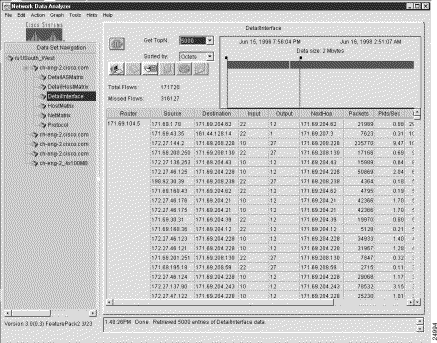
The Router column shown in Figure 3-1 is common to all of the NetFlow data aggregation schemes. This column identifies the source device from which the displayed NetFlow data was collected.
The key columns of a displayed NetFlow data aggregation scheme contain information peculiar to the particular scheme being displayed.
In Figure 3-1, for example, the key columns of the DetailInterface aggregation scheme include the following:
These columns identify the specific subset of sort keys used by the FlowCollector in post-processing the UDP export datagrams received from the router identified (by the IP address) in the first column of the display.
Using these sort keys, the FlowCollector filters and aggregates the appropriate data from the exported UDP datagrams and stores the results as a specific collection of data in its local NetFlow repository.
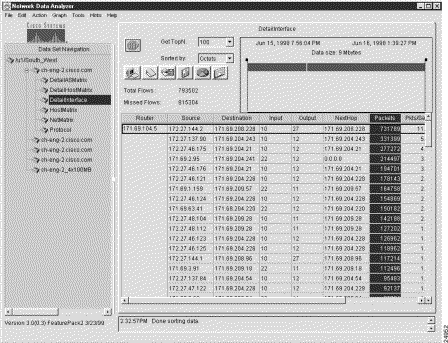
Figure 3-2 is a representation of the same sample output for the DetailInterface aggregation scheme shown in Figure 3-1, except that the display pane is scrolled to the right to make all of the value columns in the data array visible.
The value columns of a displayed NetFlow data aggregation scheme always comprise the six rightmost columns of the data array, as identified below:
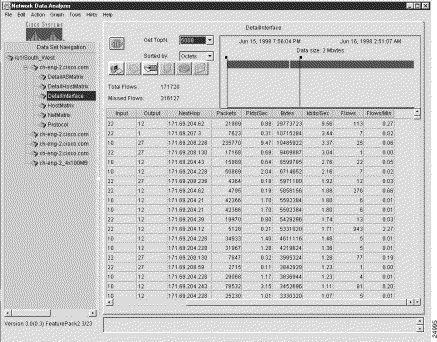
Table 3-3 describes the two key columns of the TMS TrafficMatrix data aggregation scheme, while Table 3-4 describes the value columns of the TMS TrafficMatrix data aggregation scheme.
Note that the value columns in Table 3-4 pertain to two different types of traffic: E (external) packets, and I (internal) packets.
| Key Field Name | Description |
|---|---|
Destination | The destination IP address and destination IP address mask for type "p" records. Type "p" records are indexed by destination prefix and describe dynamic tag switching traffic data or traffic engineered (TE) tunnel head traffic data. |
The tunnel head IP address and tunnel serial ID for type "t" records. Type "t" records are indexed by tunnel head for tunnel midpoint records and describe traffic engineered (TE) tunnel midpoint data. |
| Name of Value Field | Description |
|---|---|
E.pkts | External packet count within the specified start/stop interval for the flow. |
E.Pkts/Sec | External packet rate, in packets per second. |
E.Bytes | External byte count within the specified start/stop interval for the flow. |
E.kbits/Sec | External byte rate, in kilobits per second. |
I.Pkts | Internal packet count within the specified start/stop interval for the flow. |
I.Pkts/Sec | Internal packet rate, in packets per second. |
I.Bytes | Internal byte count within the specified start/stop interval for the flow. |
I.kbits/Sec | Internal byte rate, in kilobits per second. |
Pkts | Total packet count within the specified start/stop interval for the flow. |
Pkts/Sec | Total packet rate, in packets per second. |
Bytes | Total byte count within the specified start/stop interval for the flow. |
kbits/Sec | Total bit rate, in kilobits per second. |
Route Flaps | Number of route flaps detected within the specified start/stop interval for the flow. The term route flap refers to an instance of the route going down and being restored. |
Flaps/Min | Measured rate of route flaps per minute within the specified start/stop interval for the flow. |
Figure 3-3 shows sample output for the TMS TrafficMatrix data aggregation scheme, which is designed specifically for use in collecting and displaying TMS data.
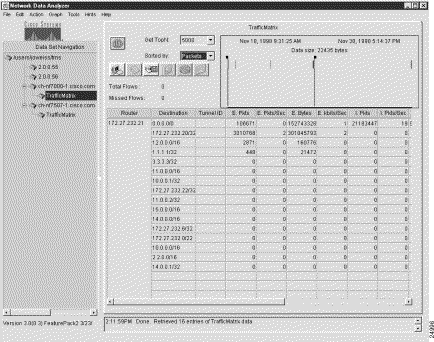
The Router column of the TMS data array (see Figure 3-3) always identifies the source device from which the displayed TMS data was collected.
The key columns of a TMS data array include the following:
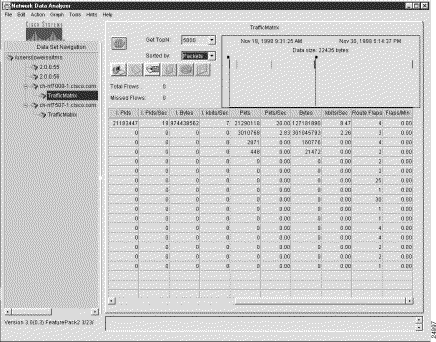
Figure 3-4 shows the same sample output pertaining to the TrafficMatrix aggregation scheme as that shown in Figure 3-3, except that the data in the display pane is shifted to the left by means of the horizontal scroll bar, bringing most of the value columns comprising the overall data array into view.
The E.Pkts column marks the beginning of the 14 values columns displayed in a TMS aggregation scheme. Table 3-4 describes the 14 different values columns that appear in a TMS TrafficMatrix aggregation scheme.
The Display module File menu provides the following selectable options:
The menu system provided by the Analyzer is structured to help you accomplish specific tasks in a logical fashion, generally proceeding from simple to more complex tasks.
Some menu options are grayed out (not selectable) until other requisite conditions are satisfied.
The following sections describe how you use the File menu options.
You can export (save) the contents of any displayed aggregation scheme to a named file at any time. Figure 3-5 shows a typical "DetailInterface" aggregation scheme that you could use as the basis for the Export function of the File menu.
To export the contents of a displayed aggregation scheme to a named file, perform the following procedure:
Step 1 If the data aggregation scheme that you want to export is currently displayed (as in Figure 3-5), select the Export option of the File menu or click the Export Data button in the display pane.
Either action causes the following pop-up window to appear.
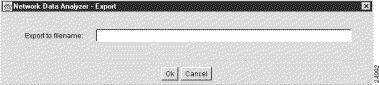
Step 2 Choose a name by which you want the displayed aggregation scheme data to be saved, such as "detail_interface_output."
Step 3 Enter the name of the file in the space provided in the export pop-up window, as shown below.
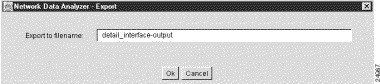
Step 4 Click OK.
The following message box appears, identifying the saved file by name and indicating the location in which it is stored.

The export file is stored in comma separated vector (.CSV) format in a specific directory on the device presently serving as the DisplayServer host (fredm-ultra, for purposes of this procedure). The .CSV file format can be interpreted by Microsoft Excel and other popular spreadsheet programs.
You can save aggregation scheme data as a .CSV file and import the file into any program that can handle this file format.
Operational conveniences and efficiencies can be realized by creating and saving named tree files. After you create a tree file, you can load it into the Data Set Navigation pane at any time and use it as the basis for a current Display module session.
In using the Analyzer to meet day-to-day needs, it is to your advantage to create a library of tree files that you can draw upon. For example, you can compose a working data tree structure that encompasses exporting devices in a certain network segment or geographical area of interest.
With a library of tree files available when you start up the Display module, you can load any desired working data tree structure into the Data Set Navigation pane as a single entity, thus avoiding having to populate the Data Set Navigation pane individually with data set paths in preparation for a given Display module session.
After you populate the Data Set Navigation pane with the desired data set paths, save the contents of the pane as a named file by invoking the Save option of the File menu.
To create and save a tree file, perform the following steps:
Step 1 Add a desired number of data set paths one at a time into the Data Set Navigation pane.
The procedure for populating the Data Set Navigation pane with desired data set paths is described in the "Adding Data Set Paths to the Data Set Navigation Pane" section.
For purposes of creating and saving a named tree file, assume that you have added the data set paths shown in Figure 3-6 into the Data Set Navigation pane.
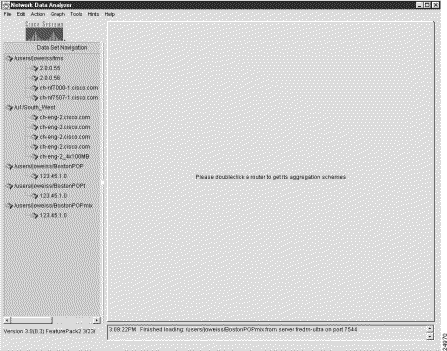
Step 2 After populating the Data Set Navigation pane with the desired data set paths, save the data sets paths as a tree file by invoking the Save option of the File menu.
This action causes the following Configurations pop-up window to appear.
Step 3 In the data field at the top of the Configurations pop-up window, enter a file name of your choosing, such as "Boston_Pops," by which the tree file is to be identified.

Step 4 Click OK to save the file by the designated name in a directory on the DisplayServer module host.
You can select the Load option from the File menu at any time to select any one of several pre-defined tree files for loading into the Data Set Navigation pane.
The "Creating and Saving a Tree File" section describes how to create a library of pre-defined tree files that you can load into the Data Set Navigation pane to serve as the selection mechanism for Display module functions.
To load a tree file into the Data Set Navigation pane, perform the following procedure:
Step 1 Select the Load option from the File menu. The following pop-up window appears:
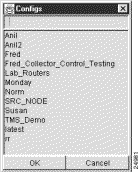
As evident from the contents of this pop-up window, several tree files have been created and saved previously for use in performing current or intended Display module tasks.
Step 2 From those tree files listed in the Configurations pop-up window, determine which file you want to load into the Data Set Navigation pane.
For this purpose, assume that you want to load the tree file named "Norm."
Step 3 To load the selected tree file, do either of the following:
Either action above causes the selected tree file to be loaded into the Data Set Navigation pane (see Figure 3-7).
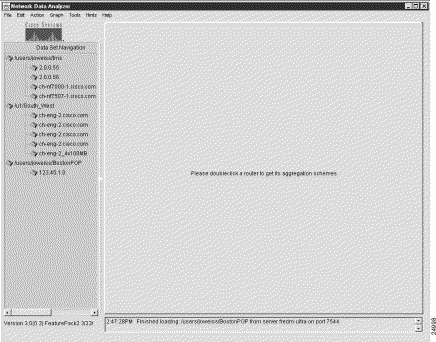
With the data tree structure shown in Figure 3-7 loaded into the Data Set Navigation pane, you can invoke any Display module function, provided that the selected option is not grayed out (unavailable in the current operating context of the Analyzer).
The following loading options become available to you once you have created and saved one or more tree files:
The default data tree structure loaded into the Data Set Navigation pane on Display module startup remains in effect until you deliberately change it, delete it, or replace it.
When you want to work with a data tree structure other than the one currently being displayed in the Data Set Navigation pane, you can use the Load option of the File menu, as described above, to load any other desired tree file.
To exit from the Analyzer, select the Quit option of the File menu.
This section describes how to use the following options on the Edit menu:
This section describes how to manually add individual data set paths to the Data Set Navigation pane.
To group individual data set paths into named router groups that appear automatically in the Data Set Navigation pane, refer to the "Creating and Saving a Named Router Group" section.
To retrieve and analyze either NetFlow data or TMS traffic data on initial startup of the Display module, you must know beforehand the location of specific directories in a FlowCollector host or an NFS-mounted storage volume in which desired traffic information is known to be stored. Hence, you must add to the Data Set Navigation pane those data set paths that point to NetFlow or TMS traffic data of interest.
To add individual data set paths manually to the Data Set Navigation pane, perform the following steps:
Step 1 From the Display module pull-down menu, select the Add Data Path option of the Edit menu. The New Data Location dialog box appears.
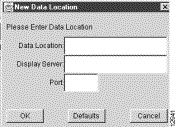
Step 2 Enter the appropriate information to define the desired data set path:
(a) Data Location---This field identifies the directory in a storage repository (/u1/South_West, for example) that you know contains the NetFlow desired data.
You must uniquely define this directory so that it can be accessed directly by the DisplayServer module specified in (b) below.
(b) Display Server---This field identifies the DisplayServer host (fredm-ultra, for example) that has been configured to service user requests for traffic data. The DisplayServer retrieves the requested data from the directory specified in (a) above.
You can identify the DisplayServer host by either its logical name (fredm-ultra, for example) or its IP address.
(c) Port---This field identifies the application port number used by the DisplayServer specified in (b) above in servicing user data requests.
Typically, application port number 7544 is used by the DisplayServer in listening for user commands.
Step 3 When you complete the fields of the New Data Location dialog box, as shown below, click OK.
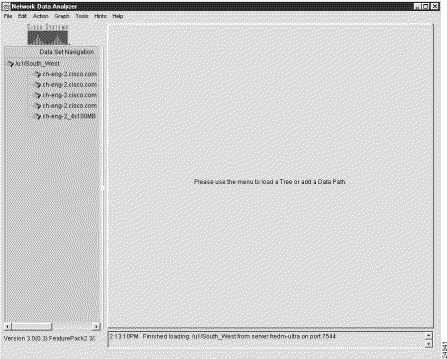
This step adds the specified new data set path into the Data Set Navigation pane, as shown in Figure 3-8.
By repeating this procedure, you can add multiple data set paths to the Data Set Navigation pane.
To conserve available space in the Data Set Navigation pane, add only those data set paths relevant to your current Display module session.
It can be useful to combine several individual data set paths into a named router group that relates to a particular set of routers or switches in your network.
A named router group constitutes a working data tree structure that you can load into the Data Set Navigation pane at any time as a single entity, obviating the need to populate the Data Set Navigation pane manually with data set paths at each startup of the Display module. Defining a named router group for each of your operating needs enables you to load, change, and delete named router groups at will to serve a variety of Analyzer operating needs.
For more information on cloning, see the "Cloning Function of the Properties Window" section.
To group multiple data set paths into a named router group, perform the following steps:
Step 1 Populate the Data Set Navigation pane with any number of data set paths of relevance for defining a named router group.
If the Data Set Navigation pane is not already populated with appropriate data set paths (such as those shown in Figure 3-9) add any number of data set paths individually to the Data Set Navigation pane through successive uses of the Add Data Path option of the Edit menu.
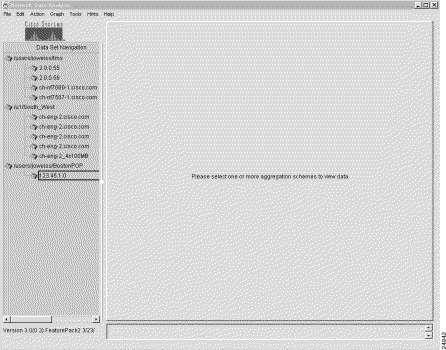
The procedure for this function is described in the "Adding Data Set Paths to the Data Set Navigation Pane" section.
Step 2 Add the Add Router Group name to the Data Set Navigation pane by doing the following:
(a) Select the Add Group option from the Edit menu. The following pop-up window appears.
(b) In this Set Group Name window, enter a router group name of your choice, such as "North_American_Region," for example.

(c) Click OK.
The router group name "North_American_Region" then appears at the bottom of the Data Set Navigation pane (see Figure 3-10).
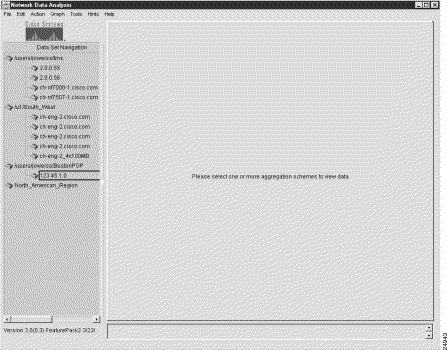
Step 3 Populate the named router group with data set paths.
Using the data set paths already present in the Data Set Navigation pane, drag the desired data set paths one at a time into the router group named "North_American_Region."
Click the desired data set path to highlight it. Hold down the left mouse button and drag the data set path into the named router group.
Repeat this step as many times as necessary to compose the named router group. For this example, assume that you want to drag the data set paths "/users/joweiss/tms," "/u1/South_West," and "/users/joweiss/BostonPOP" into the named router group.
Step 4 After composing the named router group, you can:
If you choose the second option, delete any non-essential data set paths by successively invoking the Remove Router Or Group option of the Edit menu, as described in the next section.
Step 5 Save the existing data tree structure to a file. To do so:
(a) Select the Save option from the File menu. The following pop-up window appears:
(b) Enter a file name of your choice in the blank field at the top of the window to identify the saved file. Assume that you want to name the file "North_American_Region." The pop-up window appears as follows:
(c) Click OK to save the file.
On completion of this procedure, the Data Set Navigation pane contains the named router group shown in Figure 3-11.
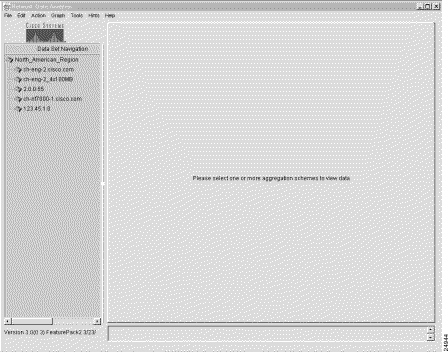
With this working data tree structure in place in the Data Set Navigation pane, you can select any available aggregation scheme in the pane as the basis for Display module tasks.
This section describes how to "clean up" the existing data tree structure in the Data Set Navigation pane by means of the Remove Router Or Group option of the Edit menu.
Your existing data tree structure might become outdated due to changes in your networking or data exporting environment. Such changes may include:
Any fundamental configuration changes to FlowCollectors or the directory pointers for stored traffic information can potentially invalidate an existing data set path or an existing element of a named router group.
For this reason, the Display module incorporates capabilities that enable you to tailor the contents of the Data Set Navigation pane.
The sample tree structure shown in Figure 3-12 shows a context for removing selected elements of a data tree structure from the Data Set Navigation pane.
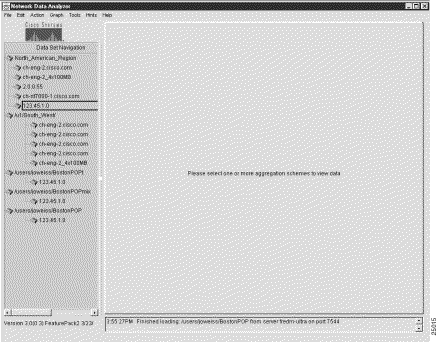
To remove any element of the tree structure currently being displayed in the Data Set Navigation pane, perform the following procedure:
Step 1 Determine which element of an existing data tree structure that you want to remove.
For purposes of this step, assume that you want to delete the entire router group named "u1/South_West."
Step 2 Click the router group name "u1/South_West" to highlight it.
This action changes the appearance of the Display module window (see Figure 3-13.
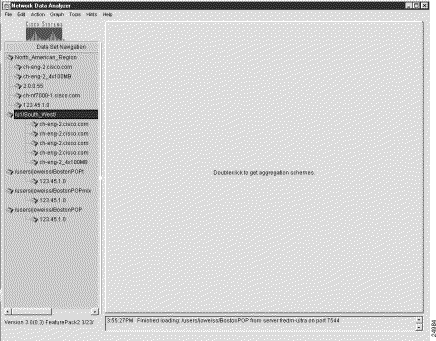
Step 3 Select the Remover Router Or Group option of the Edit menu.
The following pop-up window prompts you for confirmation of your intent to delete the selected router group.
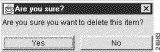
Step 4 Click "Yes." The Data Set Navigation pane then takes on the appearance shown in Figure 3-14.
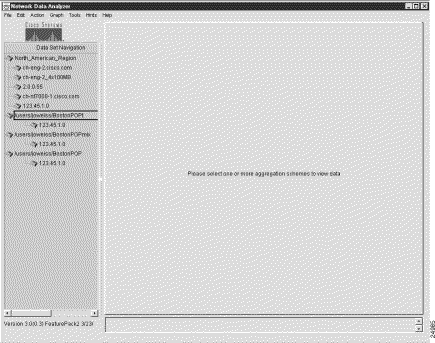
Using the procedure outlined above, you can remove any logical element of an existing data tree structure.
If you select any part of an existing data tree structure for deletion other than one at "root" level (left-justified in the pane), the Remove Router Or Group option remains grayed out. In other words, the Remove Router Or Group option of the Edit menu is effective only with respect to an entire selected router group or selected data set path.
By selecting the Properties option of the Edit menu, you can display the properties of any router that you select in the Data Set Navigation pane.
For example, assume that you clicked the router ch-eng-2_4x100MB shown in Figure 3-15 to select it. To display the properties of the selected router, you need only select the Properties option of the Edit menu.

When you select the Properties option of the Edit menu, the following Properties window appears, displaying the properties of the selected router.
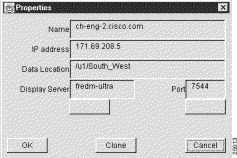
This window displays the following information about the selected router:
The buttons at the bottom of the Properties window perform the following functions:
The properties window enables you to clone the name and the properties of a selected router into another selected router group.
For example, the cloning process includes the following generalized steps:
1. Select the router "ch-eng-2_4x100MB," as shown in Figure 3-16, with the intent to clone it into another named router group.
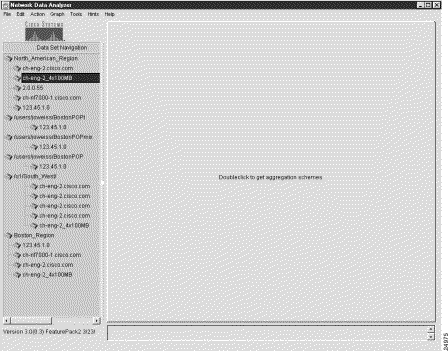
2. With this router selected, select the Properties option of the Edit menu.
This action pops up a Properties window on the main Display module window (see Figure 3-17.
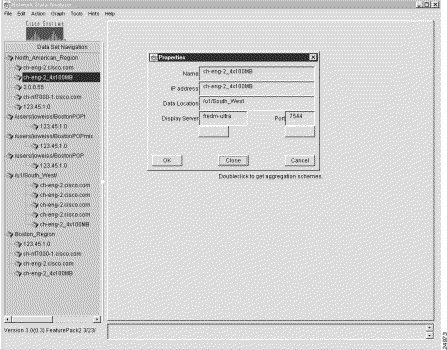
3. Click the Clone button in the Properties window.
This action pops up a Pick a Target Group window on the Properties window (see Figure 3-18).
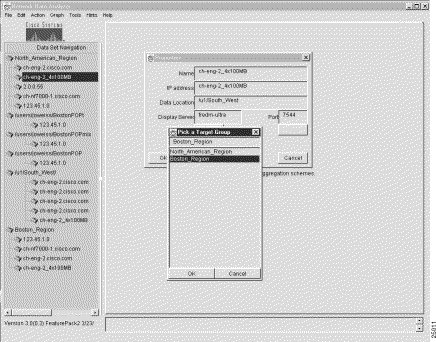
4. In the Pick a Target Group window, select the name of the named router group into which the selected router is to be cloned, such as "Boston_Region."
5. To execute the cloning function, click Boston_Region (to replicate its name in the field at the top of the window).
6. Click OK.
These steps cause the router named ch-eng-2_4x100MB to be cloned into the router group named Boston_Region, as demonstrated by the new entry at the bottom of the Data Set Navigation pane shown in Figure 3-19.
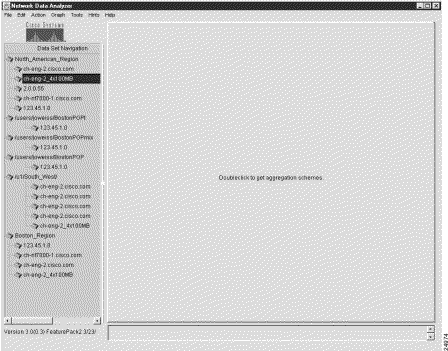
The Action menu provides the following selectable options:
The following sections describe how to use these menu options.
This section presents procedures for retrieving and displaying traffic information for:
A common Analyzer task is to display traffic information for a selected device and aggregation scheme.
For purposes of this section, assume that you have added the data tree structure shown in Figure 3-20 to the Data Set Navigation pane.
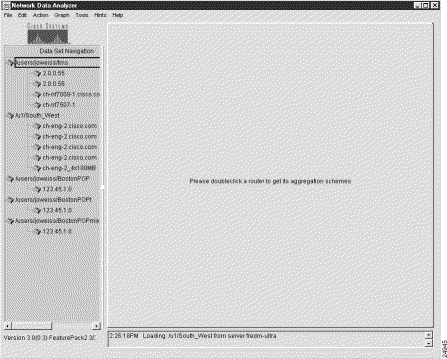
To display traffic data for a selected device and aggregation scheme, perform the following steps:
Step 1 Select the desired device.
Double-click the name of the router of interest in the Data Set Navigation pane (see Figure 3-20).
Assuming that "ch-eng-2_4x100MB" is the device of interest, double-click the device name to list its applicable aggregation schemes in the Data Set Navigation pane.
Step 2 Select the aggregation scheme that you want to apply for display purposes.
For example, assume that you want to display traffic information for the DetailInterface aggregation scheme. Click this aggregation scheme.
This action causes a "clean" display pane labeled DetailInterface to appear in the Display module window (see Figure 3-21).
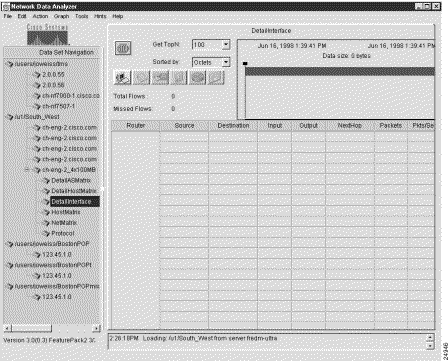
Note that the time line area in the top right portion of the window indicates the range of dates and times for which data is available for the selected router and aggregation scheme.
Step 3 To establish the desired time horizon for data retrieval purposes, position the time slider marks, as appropriate.
You can move either time slider mark in either horizontal direction to establish the desired time period.
Step 4 Click the Get TopN: pull-down menu to select the number of traffic flows that you want taken into account in data retrieval operations.
The selectable values of "N" range from 10 to 10,000. The value 100 is the default.
In effect, the value that you select determines the relative volume of traffic data to be retrieved and processed for the selected aggregation scheme.
For example, if you select "10" as the TopN value, you limit the volume of traffic data to be processed to the first ten traffic flows.
Selecting a lower value for N tends to improve Analyzer performance, because less information is processed in satisfying the data display request.
Step 5 Click the Sorted by: pull-down menu to select the desired sort key for displaying the traffic data.
For this purpose, assume that the data is to be sorted by "Octets."
Step 6 Click the Get Data from Server button in the display pane (the leftmost button).
Alternatively, you can select the Get Data option from the Action menu to initiate the retrieval and display of traffic data for the selected aggregation scheme.
The result of this procedure is shown in Figure 3-22.
A common Analyzer task is to display traffic information for a selected aggregation scheme that is common across devices in a named router group.
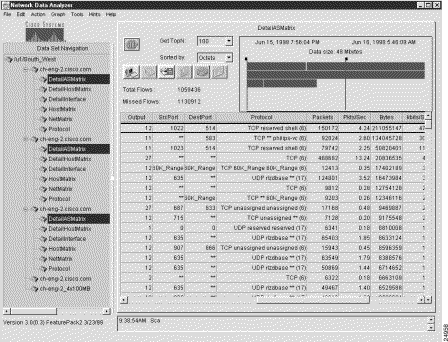
Figure 3-23 shows the tree structure for the named router group, "/u1/South_West," that serves as the basis for the procedures described in this section. Figure 3-23 indicates that you want to display NetFlow data for the DetailASMatrix aggregation scheme for three exporting devices that are common to the named router group.
For details about how to create a named router group, refer to the "Creating and Saving a Named Router Group" section.
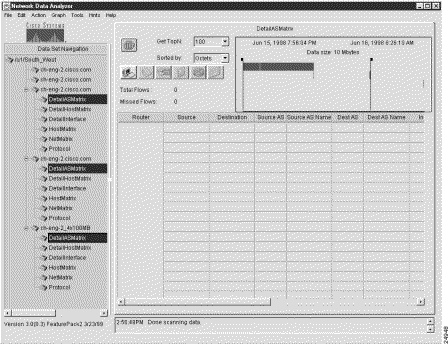
To display NetFlow data for an aggregation scheme that is common to selected devices in a named router group, perform the following steps:
Step 1 Select a desired aggregation scheme that is common to two or more devices in the overall tree structure for the named router group. The selected aggregation scheme must be the same for all devices.
To select a common aggregation scheme among two or more devices, hold down the Ctrl key and click the name of each scheme.
Step 2 Position the time slider marks in the display pane, as desired, to establish the applicable time horizon for display operations.
Step 3 Click the Get TopN: pull-down menu in the display pane to select the number of traffic flows ("N") that you want taken into account for display purposes. The default value for Get TopN: is 100.
Step 4 Click the Sorted by: pull-down menu in the display pane to select the desired sort key for display purposes. The default value for the Sorted by: parameter is "Octets."
Step 5 Click the Get Data from Server button in the display pane (the leftmost button).
Alternatively, you can select the Get Data option from the Action menu to initiate the display operation for the selected aggregation scheme.
On completion of the above procedure, traffic data for the selected aggregation scheme appears (see Figure 3-24).
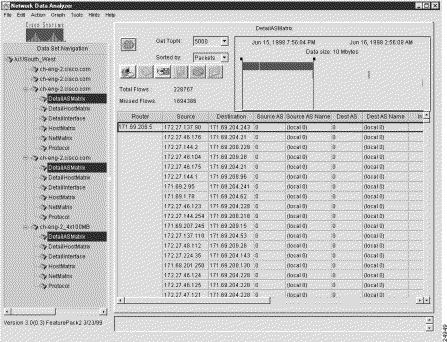
The applicable aggregation scheme data for each selected device is "stacked" in the display pane one below another, beginning with the first selected device and continuing to the last selected device.
As with all display functions, when the overall data array exceeds the observable "at-a-glance" space in the display pane, you can use the horizontal and vertical scroll bars in the display pane to traverse to any area of the display.
By using similar data tree structures in this manner for multiple devices in a named router group, you can select any aggregation scheme common among any combination of devices in the group and initiate display functions for the selected devices. This capability enables you to compare traffic patterns and statistics of interest between exporting devices in the group.
For purposes of this section, the working data tree structure shown in Figure 3-25 is assumed to be basis for sort operations.
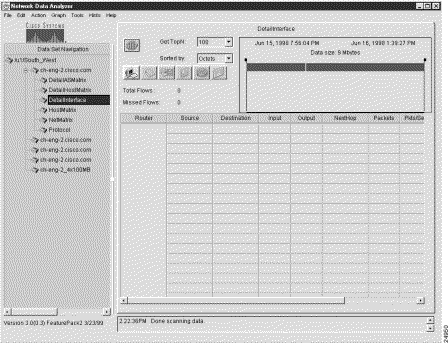
You can select any aggregation scheme in an existing data tree structure, retrieve the applicable traffic data for that aggregation scheme, select any column of the data array, and sort the data in that column.
To initiate a sort operation relative to a selected aggregation scheme, perform the following steps:
Step 1 Select an aggregation scheme for display purposes.
For this step, assume that you want to display traffic information for the DetailInterface aggregation scheme.
Step 2 Click the DetailInterface aggregation scheme to access a "clean" display pane.
Step 3 Prepare for sort operations, as follows:
(a) Position the time slider marks in the display pane as desired to establish the applicable time horizon for governing the extent of data retrieval.
(b) Click the Get TopN: pull-down menu in the display pane to select the number of traffic flows ("N") that you want taken into account for data retrieval purposes. The default value for Get TopN: is 100.
(c) Click the Sorted by: pull-down menu to select the desired sort key for display purposes. The default value for the Sorted by: parameter is "Octets."
Step 4 Click the Get Data from Server button in the display pane.
Alternatively, you can select the Get Data option from the Action menu to initiate data retrieval and display for the selected aggregation scheme.
Step 5 When the data for the selected aggregation scheme appears in the display pane (Figure 3-26), you can sort the data in either of two ways:
Using this option, you can double-click a succession of column headings (in any desired order) to initiate sort operations for a series of selected columns.
For purposes of this step, assume that you want to sort the data in the Packets column of the data array.
This procedure results in the data array shown in Figure 3-27.
Note that the data in the Packets column of the aggregation scheme is sorted in descending numerical order.
The Translate Host Addresses option of the Action menu enables you to translate IP addresses appearing in the Source or Destination columns of a displayed NetFlow data aggregation scheme into equivalent host names.
Table 3-1 lists the NetFlow data aggregation schemes and the key columns applicable to each scheme. For purposes of translating host IP addresses, the applicable key columns of a NetFlow data aggregation scheme include only the following:
The Translate Host Addresses option is applicable only to NetFlow data aggregation schemes that incorporate Source or Destination columns in the displayed aggregation scheme. If the Translate Host Addresses option is not available, it is grayed out.
When you invoke the Translate Host Addresses option, the NetFlow data array in the display pane changes, as follows:
Note that the following Display module functions incorporate an IP address translation function:
Figure 3-28 shows a typical NetFlow data aggregation scheme containing Source and Destination columns.
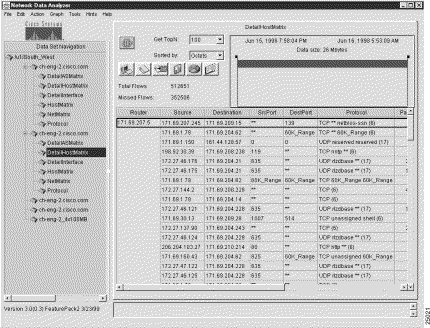
If you invoke the Translate Host Addresses option while this aggregation scheme is in effect, the data array is altered as follows:
The result of this IP translation function is shown in Figure 3-29.
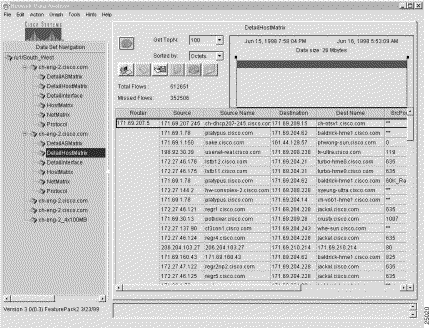
You may find it useful to sort the host names appearing in the Source Name and Dest Name columns of a NetFlow data array.
For example, if several exporting devices appear in your network that are identified with host names that vary slightly from each other (such as fredm-ultra, fredm-sun, fredm-pc), you can perform a sort on the Source Name or the Dest Name column in the data array. In this example, the sort operation causes the "fredm" host devices to sort the data alphabetically and rearrange it in the resulting data array.
The Display module Graph menu provides the following selectable options:
The following sections describe how you use these menu options.
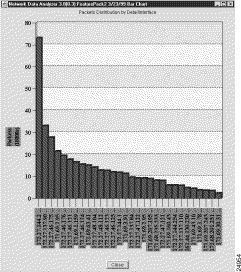
The data in the DetailInterface aggregation scheme shown in Figure 3-30 is used as the basis for illustrating the Analyzer's bar chart function.
The Packets column of the aggregation scheme is highlighted, indicating that you can use the data in this column for bar chart creation. You can select any of the six value columns of a NetFlow data aggregation scheme, or any of the 14 value columns of a TMS data aggregation scheme as the basis for creating a bar chart.
You can use either of two methods to create a bar chart representation of the traffic information in the Packets column (or any other value column of a NetFlow or TMS data aggregation scheme):
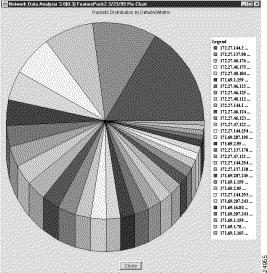
For this section, the aggregation scheme data shown in Figure 3-32 serves as the basis for illustrating pie chart creation.
The Packets column of the aggregation scheme is highlighted, indicating that you can use the data in this column for pie chart creation. As with bar charts, you can select any of the six value columns of a NetFlow data aggregation scheme, or any of the 14 value columns of a TMS data aggregation scheme as the basis for creating a pie chart.
You can use either of two methods to create a pie chart representation of the traffic information in the Packets column (or any other value column of a NetFlow or TMS data aggregation scheme):
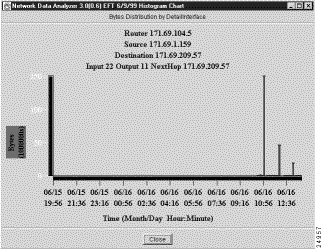
For the purpose of creating a histogram, use the data in the DetailInterface aggregation scheme shown in Figure 3-34. Note that the Bytes column in the data array is highlighted, indicating that the data in this column is to be used as the basis for creating the histogram. Note also that you must select a row in the overall NetFlow data array for which you want a histogram representation of traffic data.
You can use either of two methods in creating a histogram representation of the traffic information in the Bytes column (or any other value column of a NetFlow data aggregation scheme):
This section describes the following Tools menu facilities for data exploration:
The AS Drill Down Window option enables you to take a closer look at traffic data pertaining to multiple devices involved in traffic flows between source AS and destination AS systems in your network. An AS (autonomous system) is a network, or a collection of networks, operating under a common network administration and routing strategy.
In AS networks, it is often useful to examine traffic data closely for several devices in the network to determine the best way to administer the network and use its resources. The AS Drill Down Window of the Display module provides this capability.
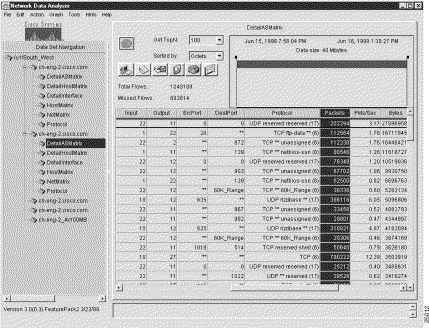
The AS Drill Down Window option of the Tools menu is used in connection with the DetailASMatrix aggregation scheme. Figure 3-36 shows a typical data array for DetailASMatrix aggregation schemes for three selected devices.
To drill down on NetFlow data pertaining to source and destination AS systems in your network, perform the following steps:
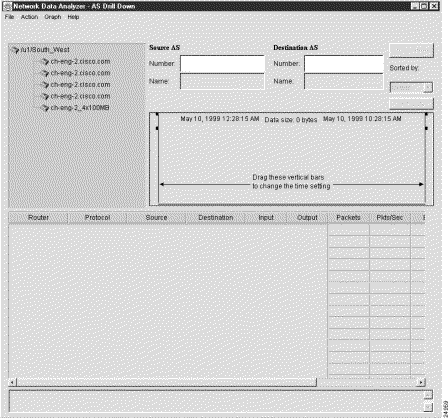
Step 1 Select the AS Drill Down Window option from the Tools menu of the Display module. The AS Drill Down Window appears (Figure 3-37).
The data tree structure shown in the Data Set Navigation pane of Figure 3-36 is propagated into the equivalent area of the AS Drill Down window for device selection purposes in initiating AS drill down functions. In addition, the time line area in the top right portion of the window indicates the ranges of dates and times for which data is available for the selected routers and aggregation schemes.
Step 2 Select those devices that you want to use for AS drill down operations.
Assume, for example, that you want to include the first three devices in the router group named "/u1/South_West," as follows:
While holding down the Ctrl key, click each device name to highlight it.
Step 3 Establish the desired parameters for performing the AS drill down operations, as follows:
(a) Enter the Source AS number and the Destination AS number in the appropriate fields of the AS Drill Down window. For this example, assume that "0" is entered in each field as the source and destination AS numbers.
(b) Select the Show Times option under the Action menu of the AS Drill Down window or click the Show Times button.
This action shows the time spans for which aggregation scheme data has been collected for the selected devices.
(c) Position the time slider marks to establish the desired time setting for retrieving traffic data for the three selected devices.
(d) Choose a value for the Sorted by: field. Choices include the following:
For this example, choose Octets as the sort key.
(e) Click the Get Data button in the ASDrill Down window to initiate data retrieval.
Alternatively, you can select the Get Data option from the Action menu to initiate data retrieval.
Either action results in the display of appropriate AS data for the selected devices, as shown in Figure 3-38. The display output shows which protocols were used by each selected router interface.
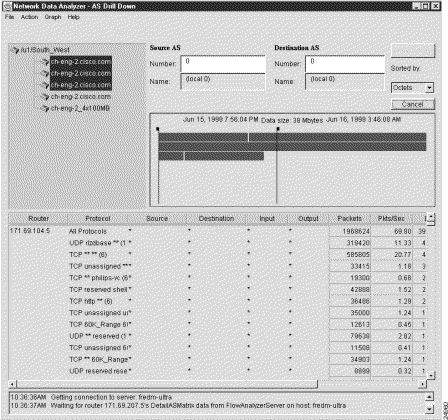
Step 4 To drill down on (get more detail for) the protocols used by a selected device, do the following:
(a) If necessary, use the vertical scroll bar in the right margin of the AS Drill Down window to bring into view the desired data for the device of interest.
(b) If necessary, click and drag the sizing bar in the right margin of the Protocol column header to expand the column enough to bring all information in the column into view.
(c) Select the desired row in the Protocol column for the selected device.
For this step, assume that you want to drill down on the protocol data for the third selected data set path for the device named "ch-eng-2.cisco.com." The resulting data for this device will be identified in the resulting data array by its IP address 171.69.207.5.
To bring the data for this interface into view, it may be necessary to use the vertical scroll bar in the window to traverse to the appropriate area of the data array.
Assume further that you want to get more detail on the third row in the Protocol column for this device, that is, the row containing the protocol "UDP rtzdbase**(17)," and that you want to use this row as the basis for drill down operations (Figure 3-39).
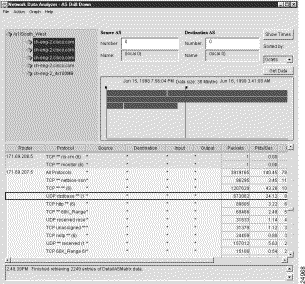
Double-click this row to initiate the display of AS drill down data. As shown in Figure 3-40), detailed traffic flow information is displayed for each individual source destination pair seen on the interface with IP address 171.69.207.5.
Alternatively, you can select the Drill Down on Protocol option of the Action menu in this window to initiate the display of AS data.
Step 5 To collapse (hide) the AS data currently being displayed for the selected row, select the Hide Drill Down Data option from the Action menu in the window.
This action causes the NetFlow data array to revert to its previous form (as shown in Figure 3-39), at which point, you can select any other Protocol row for any other selected device and use that row as the basis for AS drill down operations.
You can perform a series of AS drill down operations for any number of Protocol rows in the data array for a selected device.
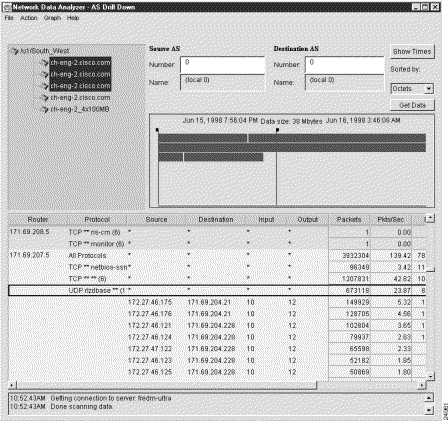
In the AS Drill Down window, an asterisk appearing in any Protocol row of the traffic data array indicates that additional information relating to the DetailASMatrix aggregation scheme is available for display purposes.
For any such row, you can do either of the following:
By successively double-clicking a series of rows containing an asterisk, you can open each row and view more detail about the specific end-to-end flows with the specific protocol seen on that selected interface.
The effect of drilling down on any row in the Protocol column of an AS Drill Down window that contains asterisks is to expand the following columns of the displayed data aggregation scheme:
The Search option of the Tool menu enables you to search for traffic flows in the following ways:
Procedures for initiating searches for the above types of traffic flows appear in the following sections.
Use the Search Window option of the Tools menu only in connection with the DetailASMatrix aggregation scheme. Before you can perform search operations involving this aggregation scheme, the following conditions must exist:
Figure 3-41 shows a sample data tree structure that meets these requirements.
When you select the Search Window option of the Tools menu, a separate Search window appears on the Display module screen (see Figure 3-42). Note that the current contents of the Data Set Navigation pane are propagated into the pane labelled "Using these Routers" for device selection purposes.
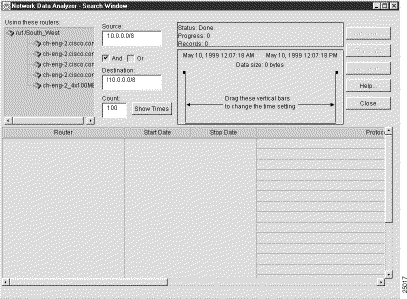
When you access the Search Window by invoking the Search Window option of the Tools menu, you can initiate search operations by performing the following steps:
Step 1 Select the device (or devices) of interest in the data tree structure of the Search Window.
In choosing devices that you want to apply for search purposes, you have the following options:
Step 2 Enter the appropriate IP address information for search operations in the Source and Destination fields of the Search Window.
When you enter IP addresses or subnet addresses in either the Source field or the Destination field of the Search Window, use the format shown in the following example in specify the range of IP addresses:
192.69.0.0/16
Step 3 Click the AND box or the OR box, as appropriate, to define the desired boolean operator for the intended search operation.
Step 4 Click the Show Times button.
Step 5 Position the time slider marks, as appropriate, to define the time horizon for which DetailASMatrix aggregation scheme data is to be retrieved and processed during search operations.
Step 6 Click the Start Search button.
The different searches that you can perform using this generalized procedure are described in the following sections.
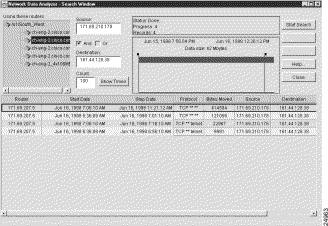
This search operation looks for traffic flows that have occurred between a specified source device and a specified destination device.
To search for traffic flows between one IP address and another IP address, perform the following steps:
Step 1 In the Source field, enter the IP address of the source device that originated the flows (171.69.210.178, for example).
Step 2 In the Destination field, enter the IP address of the destination device that received the flows (161.44.128.38, for example).
Step 3 Check the AND box.
Step 4 Click the Show Times button, adjust the time slider marks, as desired, and click the Start Search button.
This procedure finds the traffic flows that originated from the source device (171.69.210.178) and that were received by the destination device (161.44.128.38).
Sample output from an IP-to-IP search operation is shown in Figure 3-43.
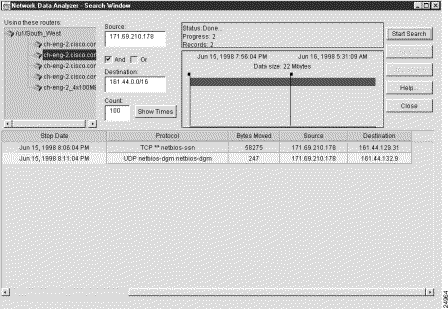
This search operation looks for traffic flows that have occurred between a specified source device and destination devices that have IP addresses within a specified range on a subnet.
To search for flows between a specified source device and a range of subnet addresses, perform the following steps:
Step 1 In the Source field, enter the IP address of the source device that originated the flows (171.69.210.178, for example).
Step 2 In the Destination field, enter the subnet address of the destination devices that received the flows (161.44.0.0/16, for example).
Step 3 Check the AND box.
Step 4 Click the Show Times button, adjust the time slider marks, as desired, and click the Start Search button.
This procedure finds the flows that originated from the source device with the IP address 171.69.210.178 and that terminated at destination devices having IP addresses in the range 161.44.0.0 to 164.44.255.255.
Figure 3-44 shows sample output from the IP-to-subnet search operation above.
Note that you can swap the contents of the Source and Destination fields to accomplish the reverse of the search operation described above. This procedure is described in the following section.
To search for flows between a range of subnet addresses and a specified IP address, perform the following steps:
Step 1 In the Source field, enter the subnet address of the source devices that originated the flows (161.44.0.0/16, for example).
Step 2 In the Destination field, enter the IP address of the destination device that received the flows (171.69.210.178, for example).
Step 3 Check the AND box.
Step 4 Click the Show Times button, adjust the time slider marks, as desired, and click the Start Search button.
This procedure finds the flows that originated from the source devices having IP addresses in the range from 161.44.0.0 to 161.44.255.255 and that were received by the destination device at IP address 171.69.210.178.
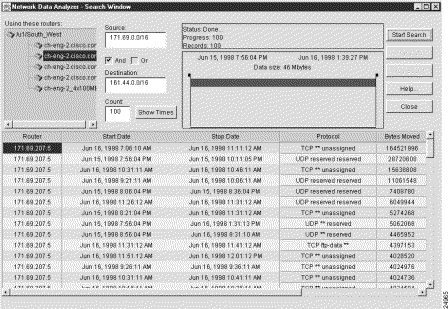
This search operation looks for traffic flows that have occurred between source devices having IP addresses within a specified range and destination devices having IP addresses within a specified range.
To search for flows between one subnet address and another subnet address, perform the following steps:
Step 1 In the Source field, enter the subnet address of the source devices that originated the flows (171.69.0.0/16, for example).
Step 2 In the Destination field, enter the subnet address of the destination devices that received the flows (161.44.0.0/16, for example).
Step 3 Check the AND box.
Step 4 Click the Show Times button, adjust the time slider marks, as desired, and click the Start Search button.
This procedure finds the flows that originated from the source devices having an IP address in the range from 171.69.0.0 to 171.69.255.255 and that were received by the destination devices having an IP address in the range from 161.44.0.0 to 161.44.255.255.
Figure 3-45 shows sample output from the subnet-to-subnet search procedure outlined above.
This search operation looks for traffic flows that have occurred between a specified source device and destination devices other than those having IP addresses within a specified subnet's range.
To search for flows that a specified device directs to other devices in the network, except to certain specified devices, perform the following steps:
Step 1 In the Source field, enter the IP address of the source device that originated the flows (171.69.210.178, for example).
Step 2 In the Destination field, enter the ! character, followed by a subnet address range (161.44.0.0/16, for example).
The exclamation point (!) is a "not" operator that means "any but those" addresses specified in the subnet address. The effect of this operator is to limit the scope of the search operation.
Step 3 Check the AND box.
Step 4 Click the Show Times button, adjust the time slider marks, as desired, and click the Start Search button.
This procedure finds the flows that originated from the specified device (171.69.210.178) and terminated at devices other than those having an IP address in the specified range (161.44.0.0 to 161.44.255.255).
Figure 3-46 shows sample output from the search procedure outlined above.
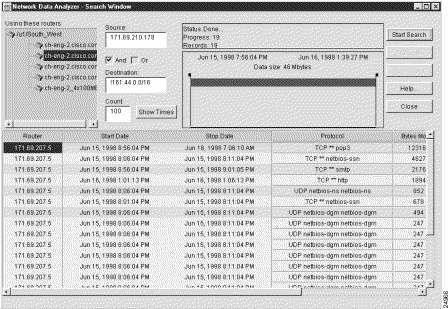
Note that you can swap the contents of the Source and Destination fields to accomplish the reverse of the search operation described above. This reverse procedure is described in the following section.
To search for flows that originate anywhere in the network (except from devices having an IP address in a specified range) and that terminate with a specified device, perform the following steps:
Step 1 In the Source field, enter the ! operator, followed by a subnet address (161.44.0.0/16, for example).
The exclamation point (!) is a "not" operator that means "any but those" addresses specified in the subnet address. The effect of this operator is to limit the scope of the search operation.
Step 2 In the Destination field, enter the IP address of the destination device that received the flows (171.69.210.178, for example).
Step 3 Check the AND box.
Step 4 Click the Show Times button, adjust the time slider marks, as desired, and click the Start Search button.
This procedure finds all the traffic flows that originated from anywhere in the network (except for those devices having an IP address in the range from 161.44.0.0 to 161.44.255.255) and that were received by the destination device at IP address 171.69.210.178.
This section describes the following Tools menu facilities for data collection:
This section describes the facilities provided by the Analyzer for controlling traffic matrix statistics (TMS) data collections.
Depending on whether or not TMS collections have already been defined, either of two versions of the Traffic Matrix Statistics Control window appears when you select the TMS Collection Control option of the Tools menu:
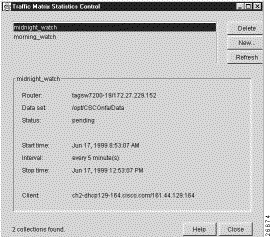
For purposes of this section, it is assumed that no TMS collections have been defined. Thus, when you click the New button in the Traffic Matrix Statistics Control window, the Configuration Files Directory window shown in Figure 3-49 appears, prompting you to enter the name of a directory on a host UtilityServer that contains configuration files for the routers and switches in your network.
Typically, the directory path name that you enter into the Configuration Files Directory window points to the directory "/tftpboot/configs/" created previously on a host UtilityServer for storing router configuration files.
There must be a configuration file in this directory for each TMS export-capable device that you intend to control by means of the Traffic Matrix Statistics Control window. You create router configuration files at installation time when you configure devices to operate in your network. Thus, for each new device so configured, you log on to the device and copy its running configuration file into the /tftpboot/configs/ directory.
The configuration file directory provides the names, interfaces, and passwords of network devices, enabling you to log on to any TMS export-capable device in the network and to configure that device for TMS collections by means of the Traffic Matrix Statistics Control window.
Typically, you store the router configuration files on a designated UtilityServer host in the network. However, you can store such files on any NFS-mounted volume in the network that is accessible to the UtilityServer. In other words, the directory path name that you enter in the Configuration Files Directory window can point to a directory on any UNIX platform in the network that is reachable by the UtilityServer.
After you enter a directory path name in the Configuration Files Directory window, click OK. If the directory path name that you enter is valid, the Traffic Matrix Statistics Control window shown in Figure 3-47 appears. Select any named collection listed in the rectangular TMS collection name area at the top of this window as the target for configuring the new TMS collection parameters. See the next section for a description of how you define the parameters for a new TMS collection.
If you decide to abandon the directory specification task, click Cancel in the Configuration Files Directory window to return to the Traffic Matrix Statistics Control window.
If the directory path name that you enter in the Configuration Files Directory window contains no configuration files, or if you specify the directory path name incorrectly, the following Router Config Files window appears to so indicate.
You define a new TMS collection by setting specific parameters in the Traffic Matrix Statistics Control window.
When you click the New button in the Traffic Matrix Statistics Control window and a valid router configuration files directory exists on a designated UtilityServer host in the network, the Traffic Matrix Statistics Control window shown in Figure 3-50 appears. This window incorporates a New Collection panel that enables you to define a new TMS collection process.
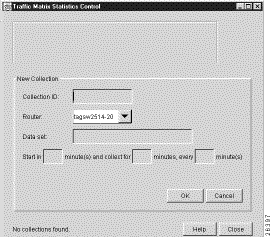
The New Collection panel provides facilities for defining the following TMS collection parameters:
Click Cancel if you wish to abandon the TMS collection definition task. Doing so clears the fields of the New Collection panel and returns you to the Traffic Matrix Statistics Control window.
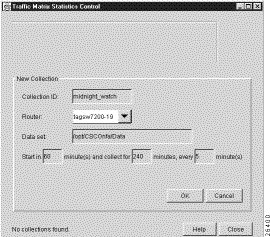
The sample data entered as described above is reflected in the completed New Collection panel shown in Figure 3-51.
When you click OK in the New Collection panel after specifying the TMS collection control parameters as described in the preceding section, the Traffic Matrix Statistics Control window takes the form shown in Figure 3-52. Note that the new collection name "midnight_watch" now appears at the top left corner of the window.
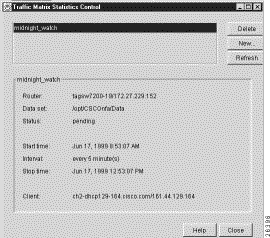
You can define any number of TMS collections in the manner described in the preceding section, but you can specify only one TMS collection for a given device.
Once TMS collections are defined and listed in the Traffic Matrix Statistics Control window, you can:
This section describes the configuration and control facilities provided by the NetFlow Collection Control window, which is accessed when you select the NetFlow Collection Control option of the Tools menu.
To collect NetFlow data successfully:
Therefore, if no FlowCollectors have been defined previously in the UtilityServer's NFCCC.txt file when you select the NetFlow Collection Control option, you must satisfy the requirements outlined in the following sections before you can gain access to the collection control facilities of the NetFlow Collection Control window.
This section describes a series of screens that the Display module presents to you in the event that no FlowCollectors have been defined previously in the UtilityServer's NFCCC.txt file. If such is the case, the following Network Data Analyzer Start Up dialog box appears.
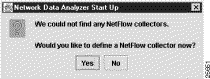
If you click Yes in response to the above message, the following New Collector Dialog box appears, enabling you to enter the name of a FlowCollector to which you want to connect.
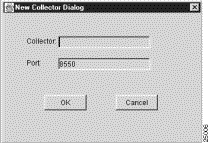
After you enter the FlowCollector name and click OK, the NetFlow Collection Control window appears, displaying the name of the desired FlowCollector in the Collector list of the window.
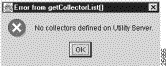
If you click Cancel in the New Collector Dialog window, the NetFlow Collection Control window appears without displaying the name of a FlowCollector in the Collector list of the window. In this case, if you close the NetFlow Collection Control window and again select the NetFlow Collection Control option of the Tools menu in another attempt to connect to a FlowCollector, the following error message appears to remind you that no FlowCollectors have been defined in the UtilityServer's NFCCC.txt file.
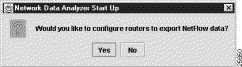
If you click No in the Network Data Analyzer Start Up window shown at the beginning of this section, the window again appears with a new query: "Would you like to configure routers to export NetFlow Data?"
The "Configuring Routers for Data Export" section describes how you configure routers for the export of NetFlow or TMS data.
If you click Yes in response to the above configuration query, the following Configuration Files Directory pop-up appears, enabling you to enter the path name of the directory containing the router configuration files on the UtilityServer host.
After entering the path name, click OK.
If you click Cancel in the Configuration Files Directory window above, you will be returned to the main Display module window.
If you click No in response to the "Would you like to configure routers to export Netflow data?" query, the Network Data Analyzer Start Up window shown below appears, querying you: "Would you like to view NetFlow Data?"
If you answer Yes to the query "Would you like to view NetFlow data?," the following New Data Location pop-up window appears, enabling you to enter the directory path name (/u1/South_West, for example) that contains the desired NetFlow data.
After you enter the directory path name in the Data Location field, click OK to proceed.
If you click Defaults, the default DisplayServer and port number are set. Also, the current contents of the Data Location field are cleared so that you can enter a desired directory path name.
If you Click Cancel, the directory path name operation is abandoned.
If you answer No to the query "Would you like to view NetFlow data?," you are returned to the main Display module window without satisfying any of the prerequisites for viewing NetFlow data.
This section describes the FlowCollector files and Analyzer facilities that come into play during the user name and password authentication process for a FlowCollector. A successful authentication process enables you to gain access to desired NetFlow data stored on a FlowCollector.
The following two files in the FlowCollector's /opt/CSCOnfc/config directory are of consequence during FlowCollector startup and pertain to the user name and password authentication process:
You can configure a FlowCollector either to enforce or to ignore the user name and password authentication requirement on startup, as described below.
If the FlowCollector has been configured to enforce user name and password authentication on startup, as described in the preceding section, the Display module prompts you to enter a user name and password in the User Name and Password Dialog box shown below.

A list of FlowCollectors is maintained by the UtilityServer in the NFCCC.txt file stored in its /opt/CSCOnfa/NFAUtility/config/ directory.
You establish the initial contents of this file when you install the UtilityServer. In so doing, you should take into account all of the FlowCollectors that you intend to control by means of the NetFlow Collection Control window.
The UtilityServer maintains the following parameters in the NFCCC.txt file for each FlowCollector:
If the user name and password that you enter for a FlowCollector passes the authentication check during an Analyzer connection request, you can store the user name in the UtilityServer's NFCCC.txt file by means of the User Validation window shown below.
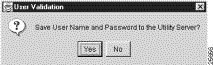
The capability to store the user name is provided as a user convenience in updating the NFCCC.txt file. If you forget the user name for the FlowCollector, you can view the contents of the NFCCC.txt file to refresh your memory.
For reasons of security, the host FlowCollector system password is not stored in the NFCCC.txt file. Nevertheless, the password that you enter to satisfy the FlowCollector authentication process remains in effect for the duration of the current Display module session. Thus, the FlowCollector "remembers" the user password until you exit from the current Display module session.
In the event that you exit the Display module and start again later, you must re-enter the appropriate password for any FlowCollector that is configured to enforce user authentication.
If user authentication is enabled (the default state) on the FlowCollector to which you intend to connect, you will be prompted to specify a user name and password before being granted access to the FlowCollector.
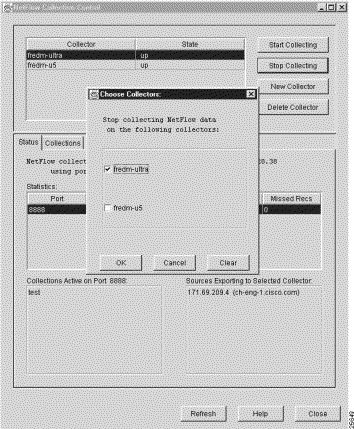
When you complete the user authentication process, as described in the "User Name and Password Authentication Process" section, you are granted access to the NetFlow Collection Control window shown in Figure 3-53.

The rectangular area at the top of the NetFlow Collection Control window incorporates facilities that enable you to:

The rectangular area at the bottom of the NetFlow Collection Control window contains several tabs, any one of which you can select at any time to perform desired NetFlow collection control tasks for a selected FlowCollector. The panels associated with these tabs are described in the sections referenced below:
In addition, the bottom of the NetFlow Collection Control window contains the following selectable push-buttons:
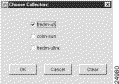
You can replicate the configuration and control parameters that you define for one FlowCollector into other FlowCollectors by means of the Choose Collectors window shown in Figure 3-55.
The Choose Collectors window appears automatically each time you attempt to perform an operation that can be logically applied to other FlowCollectors, such as when you:
From Figure 3-55, note that:
A typical Status panel in the NetFlow Collection Control window is shown in Figure 3-56.

The Status panel presents information about active collections on the selected FlowCollector. The panel includes the following facilities:
The Collections panel lists the collections currently defined for the selected FlowCollector. As shown in Figure 3-57, this panel enables you to accomplish the following tasks:
Each time you change the configuration parameters for a selected FlowCollector, a command is sent to that FlowCollector to update its nfconfig.file, thus causing it to operate according to the new or changed configuration parameters.
One of the key parameters that you can set in this window is the collection filter. A filter can incorporate multiple permit and deny attributes (such as source addresses, interfaces, and so on), but all such attributes must be related to one filter name. You can apply a filter with multiple permit and deny attributes to multiple collections, but any given collection can have at most just one filter associated with it at any time.
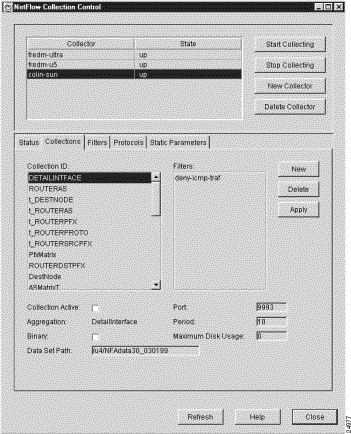
The Collections panel provides the following FlowCollector configuration facilities:
You can select only one collection name at a time in this pane.
When you click the New button in the Collections panel, a New Collection panel (see Figure 3-58) appears in place of the Collections panel.
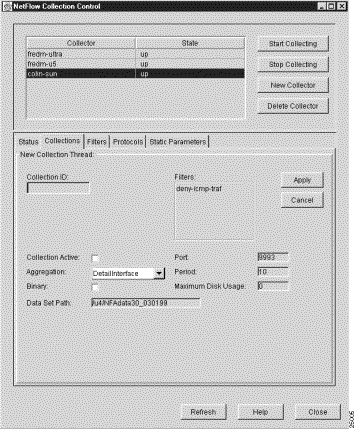
When you click New in the Collections panel, all of the parameters of the most recently selected Collections panel are propagated into the New Collections panel, giving you a basis for:
In either case, the New Collections panel:
When you specify a new collection for the selected FlowCollector, click OK to put the new collection into effect. Doing so sends configuration commands to the selected FlowCollector, updating its nfconfig.file and causing it to recognize the new collection process in aggregating NetFlow data.
If you decide to abandon the new collection definition process, click Cancel to return to the Collections panel.
The New Collection panel provides the following configuration facilities for defining new collections:
The New Collection panel also includes the following collection control facilities:
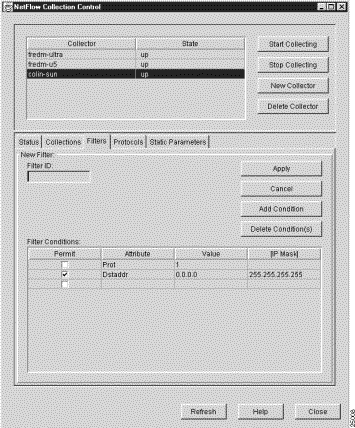
When you click the Filters tab of the NetFlow Collection Control window, the Filters panel appears (see Figure 3-59).
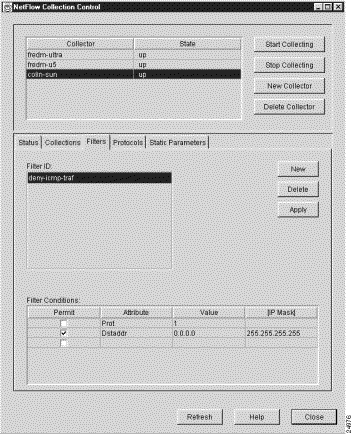
The Filters panel lists the filters currently defined for the selected FlowCollector and incorporates facilities that enable you to:
When you create a new filter, modify an existing filter, or delete an existing filter, a command is sent to the selected FlowCollector, causing it to update its nfconfig.file and to operate accordingly.
The Filters panel provides the following filter display and definition facilities:
| Filter Attribute | Filter Value |
|---|---|
Srcaddr | The IP addresses, respectively, of the traffic source, the traffic destination, and the next hop device routing the traffic to the destination. Each IP address requires a network mask. |
Srcport | The assigned port number for the transport layer protocol (RFC 1700) at the traffic source and destination, respectively. The port number can range from 1 to 65535. |
Srcinterface | The numeric identifier of the physical interface at the source and destination, respectively. |
Prot | The protocol number in the flow record, as specified in the /etc/protocols file. The protocol number can range from 1 to 255. |
Protocol | The protocol name, as displayed in the Protocol pane of the Protocol panel (see Figure 3-62) and defined in the nfknown.protocols file. |
TOS | The type-of-service (ToS) byte (which includes IP precedence and Type of Service fields) provides a way to prioritize traffic. The value of the ToS byte can range from 0 to 255. |
SrcAS | The source and destination autonomous system (AS) number, respectively. |
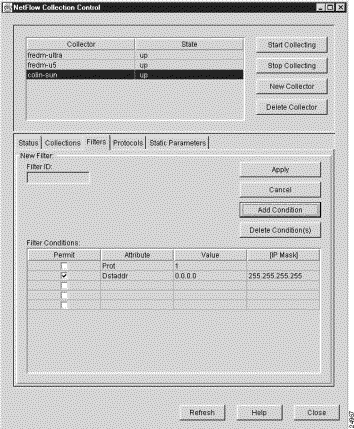
When you click the New Filter button in the Filters panel, a New Filter panel (see Figure 3-60) appears in place of the existing Filters panel.
All of the parameters of the most recently selected Filters panel are propagated into the New Filter panel, giving you a basis for:
In either case, the New Filter panel incorporates all of the filter definition facilities available to you through the Filters panel. In addition, the New Filter panel incorporates a Filter ID pane that enables you to define a unique name for the new filter.
When you create a new filter for the selected FlowCollector, a command is sent to the FlowCollector to update its nfconfig.file accordingly.
The New Filter panel provides the following new filter definition facilities:
When you click the Protocols tab of the NetFlow Collection Control window, the Protocols panel appears (see Figure 3-62).
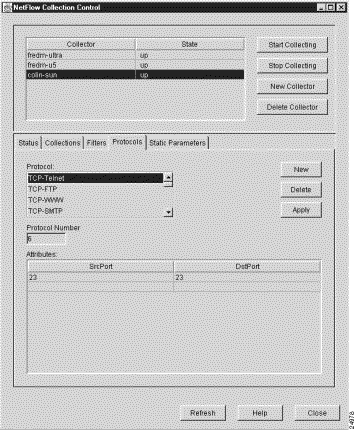
The Protocols panel lists the protocols currently defined for the selected FlowCollector, enabling you to:
When you create a new protocol, modify an existing protocol, or delete an existing protocol, a command is sent to the selected FlowCollector to update its nfknown.protocols file with the current protocol definitions and port numbers.
The Protocol panel provides the following protocol display and definition facilities:
When you click the New button in the Protocols panel, a New Protocol panel (see Figure 3-63) appears in place of the existing Protocols panel.
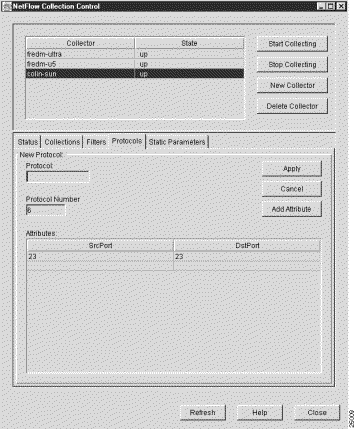
All of the parameters of the most recently selected Protocol panel are propagated into the New Protocols panel, giving you a basis for:
In either case, the New Protocol panel incorporates all of the configuration facilities available to you by means of the Protocols panel. In addition, the New Protocol panel incorporates a Protocol pane through which you can define a unique name for the new protocol.
When you create a new protocol for the selected FlowCollector, a command is sent to the FlowCollector, causing it to update its nfknown.protocols file and to aggregate NetFlow data according to the new protocol.
The New Protocol panel provides the following new protocol definition facilities:
When you click the Static Parameters tab of the NetFlow Collection Control window, the Static Parameters panel appears (see Figure 3-64).
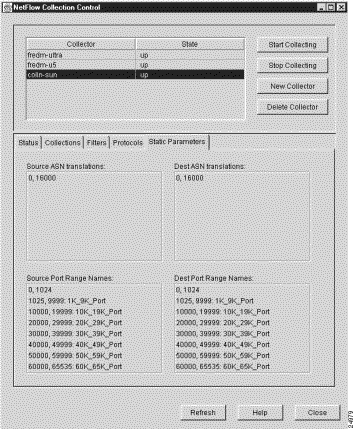
You cannot interact with the Static Parameters panel. It only displays static configuration information for the selected FlowCollector.
The Static Parameters panel has four panes, each of which shows the default text strings that are written into NetFlow data files in place of numeric information. These default settings are provided for your use in translating less readable numeric data into equivalent more readable text strings when NetFlow data files are stored by the selected FlowCollector.
A set of default static parameters and associated text strings are provided in the configuration files that are shipped with the FlowCollector, enabling you to take immediate advantage of this built-in translation capability.
Each of the four panes in the Static Parameters panel contains the following information:
The panes in the Static Parameters panel are described briefly below. If you wish to change any default setting, you must edit the appropriate FlowCollector configuration file, as identified below.
When you select the Router Configuration option of the Tools menu, the Configuration Files Directory window (see Figure 3-65) prompts you to specify the name of a directory on a network device that contains configuration files for the routers and switches in your network.
You create router configuration files at installation time when you configure devices to operate in the network. Typically, you log on to a newly-installed device and copy its running configuration file into a directory that you create on a UtilityServer host for storing router configuration files.
There must be a configuration file in this directory for each NetFlow or TMS export-capable device that you intend to configure by means of the Router Configuration window (see Figure 3-66).
The configuration file directory provides the names, interfaces, and passwords of network devices, enabling you to log on to any NetFlow or TMS export-capable device in the network and configure it by means of the Router Configuration window.
Although you typically store router configuration files on a UtilityServer host, you can store them on any NFS-mounted volume in the network that is accessible to the UtilityServer. Thus, the directory path name that you enter in the Configuration Files Directory window can point to any UNIX directory on any host in the network that is reachable by the UtilityServer.
For example, assume that you have created a configuration file directory named "/tftpboot/configs/" on a UtilityServer operating on a UNIX platform. After you enter this directory path name (or any other directory path name that points to router configuration files), click OK.
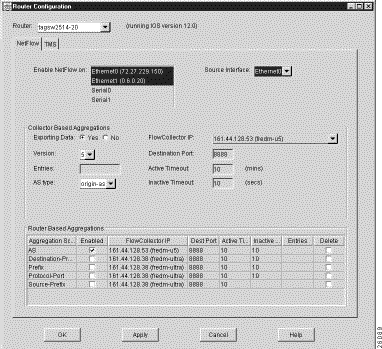
If the directory path name that you enter is valid, the Router Configuration window appears (see Figure 3-66) with the NetFlow panel selected by default. The Router pull-down selection box incorporated into this window enables you to select any NetFlow or TMS export-capable device of interest and to configure that device for data export.
The following facilities are common to the NetFlow configuration panel and the TMS configuration panel of the Router Configuration window:
The Router Configuration window appears with the NetFlow tab selected by default, displaying the NetFlow configuration panel shown in Figure 3-66. This panel enables you to configure network devices to export NetFlow data.
The NetFlow configuration panel is partitioned into three functional areas, as described below:
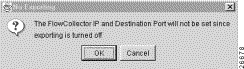
The Collector Based Aggregations area and the Router Based Aggregations area of the Router Configuration window are functionally equivalent, the only difference being that each area enables you to control a specific type of NetFlow data collection and aggregation process.
You can use either area of the Router Configuration window at any time to configure selected routers to export or process NetFlow data as desired, including configuring the same router to perform the following tasks simultaneously:
The selection lists for configuring the interfaces on the selected router are described below:
The configuration parameters for the router interfaces apply to both FlowCollector-based data aggregations and router-based data aggregations.
The data fields and push-buttons for controlling FlowCollector-based aggregations (Version 1 or Version 5 export records) for a selected router are described below:
In general, the column headings in the table for router-based aggregations (Version 8 export records) parallel the functions of the five similarly-named data fields described in the preceding section for FlowCollector-based aggregations.
Beyond the first column (which lists the five router based aggregation schemes), all columns of the table are editable. For example, you can click any cell in the table at any time, change the data contained therein to a desired value, and click Apply to effect the change.
The functions of the columns in the table are described below in their order of appearance from left to right:
When you select the TMS tab in the Router Configuration window, the TMS router configuration panel shown in Figure 3-67 is displayed. This panel enables you to configure network devices to export TMS data.
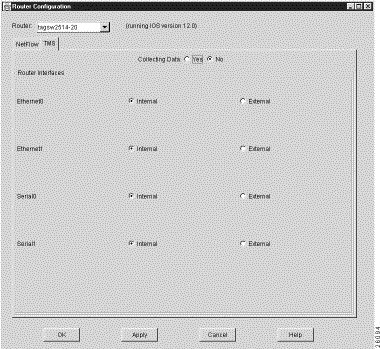
The following facilities displayed in conjunction with the TMS router configuration panel perform the same functions as those described in the "Elements Common to NetFlow and TMS Configuration Panels" section:
The functional elements unique to the TMS router configuration panel include the following:
In the event that the directory path name that you specify in the Configuration Files Directory window (see Figure 3-65) is invalid or does not exist, the following Router Config Files window is displayed by the Analyzer to so indicate.
In this case, click OK to return to the main Display module window.
You can then start over by selecting the Router Configuration option of the Tools menu. When the Configuration Files Directory dialog window again appears, you can correctly specify the path name of the desired configuration files directory, or you can specify the name of a different directory that you have reason to believe contains requisite router configuration files.
Alternatively, you can open a UNIX window and, by means of CLI commands, copy the router configuration files from their known current directory into the directory that you defined by means of the Configuration Files Directory dialog window.
In any case, you must have access to a directory that contains valid router configuration files before you can open and use the Router Configuration window. This window can only display information pertaining to network devices for which valid configuration files exist.
When the Router Configuration window appears, you can select any NetFlow or TMS data exporting device listed in the window's Router pull-down list and view and/or change any of its associated configuration parameters.
The UtilityServer checks all the configuration files stored in the router configuration file directory, ignoring any invalid files. After the UtilityServer validates the router name, the user's login password, and the enable password for each router, it passes the router name and its associated configuration parameters to the Display module. The name of the router is then added to the Router pull-down list, and, if selected, the data fields of the Router Configuration window are updated accordingly.
If for some reason a connection cannot be made to a device that you select in the Router pull-down list, the following No Connection message window appears to so indicate.
In this case, click OK to close the window. You can then attempt to connect to any other router listed in the Router pull-down list of the Router Configuration window.
The Display module Hints menu provides a Get Hints option. When you select this option, the pop-up window shown in Figure 3-68 appears. You can access this window at any time for assistance in performing the common Analyzer tasks listed in the window.

The Analyzer Display module Help menu provides the selectable options described in the following sections.
Select the About Network Data Analyzer option of the Tools menu to invoke Netscape Navigator. The resulting window, see Figure 3-69, lists the platforms on which the Analyzer is supported and tells you how to obtain assistance.
Select the How to Use the Network Data Analyzer option of the Help menu to invoke Netscape Navigator. The resulting window, see Figure 3-70, lists typical and optional Analyzer tasks that you can select at random for information about how to perform the selected task.
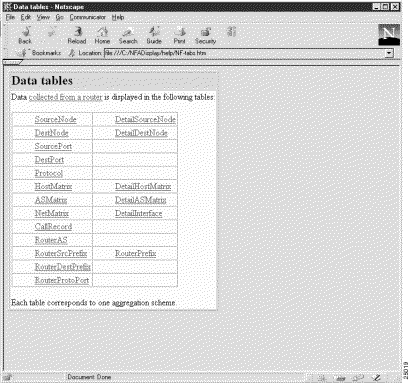
Select the Tables and Aggregation Schemes option of the Help menu to invoke Netscape Navigator, which displays the window shown in Figure 3-71. The table in this window lists the aggregation schemes available for use with the Analyzer.
You can select any entry in this table at random for additional information about the characteristics, uses, and parameters of the selected aggregation scheme.
Select the Getting Support option of the Help menu to invoke Netscape Navigator, which displays the window shown in Figure 3-72. This window lists the platforms on which the Analyzer runs and the resources that you can call upon for assistance in using the Analyzer.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Posted: Mon Jul 12 12:14:54 PDT 1999
Copyright 1989-1999©Cisco Systems Inc.