|
|

This chapter describes LocalDirector failover and contains the following sections:
Two LocalDirectors can be configured to provide automatic backup capabilities for each other. This configuration is called LocalDirector failover.
In a LocalDirector failover configuration, one LocalDirector is the primary unit (default active) and the other LocalDirector is the backup unit (default standby). The primary unit performs normal network functions. The backup unit monitors the primary unit operation and is ready to take control if the primary unit fails.
When a failure occurs, the backup unit becomes the active unit and assumes control by exchanging Media Access Control (MAC) addresses with the primary unit. The units do not give up their primary/backup designations, however.
The active unit (whether primary or backup) uses the system IP and MAC addresses of the primary unit. The standby unit (whether primary or backup) uses the failover IP address and MAC address of the backup unit. Because the active unit always uses the same IP and MAC addresses, Address Resolution Protocol (ARP) entries do not need to change or time out anywhere on the network.
The standby unit monitors failover communications, active unit power status, interface line status, and received hello packets. A failure of any of these parameters on the active unit causes the standby unit to take control. A failure or switch generates SYSLOG messages regarding the cause of the failover.
To take a unit out of the "failed" state, cycle the power or use the failover reset command. The failover reset command also clears failover timers and counters for the LocalDirector unit. When a failed primary unit is brought back online, the primary unit does not automatically resume as the active unit (because the primary unit could immediately enter in the failed state). However, if a failure is due to a lost signal on a network interface card, failover "autorecovers" when the network is available.
Use the failover active command to initiate a failover change from the standby unit. Use the no failover active command at the active unit to initiate a failover change. You can also use this feature to force an active unit offline for maintenance.
By default, the standby unit does not keep state information on each connection; all active connections are dropped and must be reestablished by the clients. However, if you configure stateful failover on LocalDirectors, the standby LocalDirector not only has copies of the active LocalDirector configuration, but also has copies of the tables that show the active connections and their state. If the active unit fails, these connections are still valid, and users continue an active session with the server. Use the replicate command to configure stateful failover per virtual server.
The configuration of the active unit is copied to the standby unit under the following conditions:
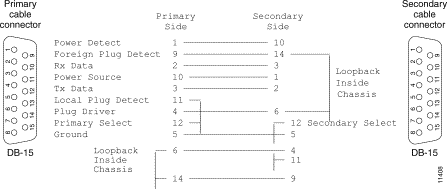
Follow this procedure to set up a failover configuration. Figure 5-1 shows the physical connections for the primary and secondary units.
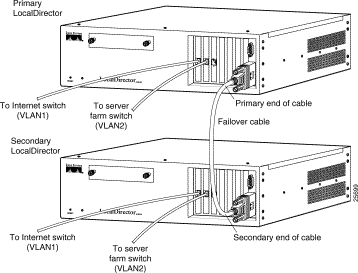
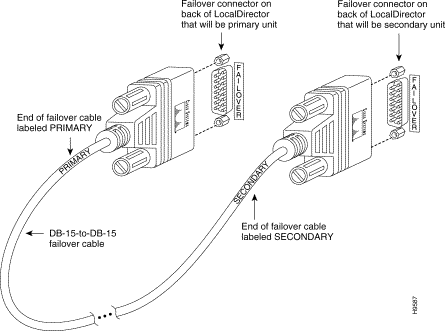
Step 1 Attach the end of the LocalDirector failover cable labeled PRIMARY to the LocalDirector that is to be the primary unit (the failover cable is shown in Figure 5-2).
Step 2 Attach the other end of the cable to the LocalDirector that is to be the secondary unit.
Step 3 Connect the interface cables to the appropriate hardware:
Step 4 Power up the primary unit.
Step 5 Use the failover ip address command to set the IP address for the standby unit.
To take advantage of multiple IP addresses or dispatched mode, or allow the failover unit to be on a different network from that of the real servers, use the failover alias ip address command to set up an alias on the standby failover unit. A maximum of 256 aliases is allowed.
Step 6 If you want to configure stateful failover, use the replicate command. See the replicate command descriptions in Chapter 6, "Command Reference," for more information.
Step 7 Write the primary configuration to a floppy disk or a TFTP server.
Step 8 Power up the standby unit.
Step 9 Reboot the primary unit to start the configuration replication to the secondary unit and start failover monitoring.
Step 10 Check your configuration:
Table 5-1 lists the commands that are used for failover configurations. For complete descriptions of these commands, see "Command Reference."
| Command | Description |
|---|---|
failover | Sets up failover configuration. |
failover active | Forces LocalDirector to active state. |
failover alias ip address | Sets failover alias IP address. |
failover hellotime | Sets failover hellotime |
failover ip address | Sets failover IP address. |
failover reset | Resets a failed LocalDirector. |
replicate | Sets up stateful connections. |
show failover | Shows status. |
show ip address | Displays IP address. For the active unit, the system IP address is displayed; for the standby unit, the failover IP address displayed. |
This section describes the following examples of failover configurations:
Figure 5-1 shows a basic failover implementation. Note that the third interface on LocalDirector 416 is not being used. In this example, the shutdown command must be used to disable the interface; otherwise the unit is seen as failed.
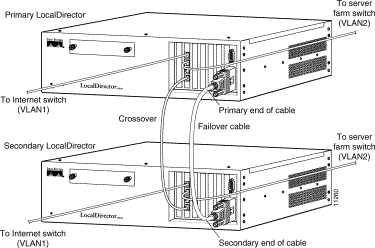
Figure 5-3 shows stateful failover with a dedicated interface, provided by the crossover cable.
Use the replicate interface command to identify the dedicated interface, as follows:
ld(config)# replicate interface 3
The ports on the 4-port interface are numbered 0 to 3. This command dedicates the bottom port on the card to stateful failover.
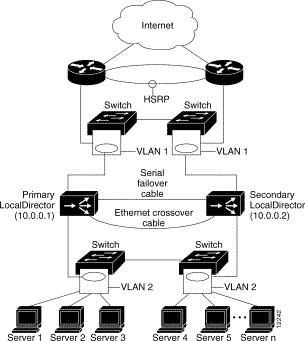
Many sites employ LocalDirectors in situations of heavy traffic loads, where redundant switches are used to route incoming traffic to multiple locations, including LocalDirectors. Figure 5-4 shows a LocalDirector configuration that is fault-tolerant.
The configuration in Figure 5-4 produces the following results, given any component failure:
Note that in the Figure 5-4 configuration, failure of a server-side switch removes access to the servers attached to it. This situation can be minimized by utilizing servers with dual LAN ports, such as exist on some LAN cards designed for redundant links.
In planning for redundant Web sites, it is wise to plan for power failures, so that equipment affected is backed up by other equipment that is not on the same power circuit.
It also makes sense to not provide power in such a way that multiple failovers occur at the same time; for example, having a gateway router and a switch served by the same power circuit or supply. This situation would mean that a switch and router would both try to converge their routes at the same time, which would cause problems in a heavily loaded network.
If there is a loss of network communication over an interface, failover begins a series of tests to determine which unit failed. These tests begin when hello messages are not heard for a number of consecutive 5-second intervals (the number is set by the failover hellotime command). Hello messages are sent over both network interfaces and the serial cable every 5 seconds.
The tests generate network traffic to determine which (if either) unit is failed. At the start of each test, each unit clears its received packet count for its interfaces. At the conclusion of each test, each unit checks whether it has received any traffic. If it has, the interface is considered operational. If one unit receives traffic for a test and the other unit does not, the unit that received no traffic is considered failed. If neither unit has received traffic, they go to the next test.
The following lists the failover interface tests:
Failover messages always have a SYSLOG priority level of 2, which indicates a critical condition. All failover SYSLOG messages are also sent as Simple Network Management Protocol (SNMP) SYSLOG traps.
To receive SNMP SYSLOG traps (SNMP failover traps), the SNMP agent must be configured to send SNMP traps to SNMP management stations, define a SYSLOG host, and also compile the Cisco SYSLOG MIB into your SNMP management station. See the snmp-server and syslog command descriptions in Chapter 6, "Command Reference," for more information.
The SYSLOG messages sent to record failover events are listed in the "SYSLOG and SNMP Messages" section of Appendix A, "Troubleshooting."
The following is the normal output for the show failover command. Note that the IP address used by each unit is displayed.
ld-prim(config)# show failover
Failover On
Cable status: Normal
This host: Primary - Active
Active time: 6885 (sec)
Interface 0 (192.168.89.1): Normal
Interface 1 (192.168.89.1): Normal
Other host: Secondary - Standby
Active time: 0 (sec)
Interface 0 (192.168.89.2): Normal
Interface 1 (192.168.89.2): Normal
Failover does not start monitoring the network interfaces until it hears six hello packets on that interface. This happens in 30 to 60 seconds, in most cases.
If the failover pair is connected to a switch running spanning tree, the start of failover monitoring takes twice the forward delay time configured in the switch (typically 15 seconds) plus an additional 30 seconds. This delay occurs because the switch detects a temporary bridge loop at bootup (and immediately following a failover event). When this bridge loop is detected, the switch stops forwarding packets (including failover hello packets) until the forward delay times out. The switch then enters "listen" mode for a second forward delay time to listen for more bridge loops.
After twice the forward delay time, traffic should resume. LocalDirector remains in "waiting" mode until it hears six hello packets (one every 5 seconds for a total of 30 seconds). During this time, the LocalDirector passes traffic while suspending failover monitoring for hello packets. All other failover monitoring continues (power, interface, and failover cable hello).
The following example shows the output if failover has not started monitoring the network interfaces.
ld-prim(config)# show failover
Failover On
Cable status: Normal
This host: Primary - Active
Active time: 6930 (sec)
Interface 0 (192.168.89.1): Normal (Waiting)
Interface 1 (192.168.89.1): Normal (Waiting)
Other host: Secondary - Standby
Active time: 15 (sec)
Interface 0 (192.168.89.2): Normal (Waiting)
Interface 1 (192.168.89.2): Normal (Waiting)
The following example shows that a failure has been detected. Note that interface 1 on the primary unit is the source of the failure. The units are back in waiting mode because of the failure. The failed unit has removed itself from the network (interfaces are down) and it is no longer sending hello packets on the network. The active unit remains in the waiting state until the failed unit is replaced and failover communications start again.
ld-prim(config)# show failover
Failover On
Cable status: Normal
This host: Primary - Standby (Failed)
Active time: 7140 (sec)
Interface 0 (192.168.89.2): Normal (Waiting)
Interface 1 (192.168.89.2): Failed (Waiting)
Other host: Secondary - Active
Active time: 30 (sec)
Interface 0 (192.168.89.1): Normal (Waiting)
Interface 1 (192.168.89.1): Normal (Waiting)
This section contains some frequently asked questions about the failover feature.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Posted: Thu Mar 2 15:40:01 PST 2000
Copyright 1989 - 2000©Cisco Systems Inc.