
 |  |
Chapter 3. Document Type Definitions (DTDs)
Contents:
Validation
Element Declarations
Attribute Declarations
General Entity Declarations
External Parsed General Entities
External Unparsed Entities and Notations
Parameter Entities
Conditional Inclusion
Two DTD Examples
Locating Standard DTDs
While XML is extremely flexible, not all the programs that read particular XML documents are so flexible. Many programs can work with only some XML applications but not others. For example, Adobe Illustrator 10 can read and write Scalable Vector Graphics (SVG) files, but you wouldn't expect it to understand a Platform for Privacy Preferences (P3P) document. And within a particular XML application, it's often important to ensure that a given document indeed adheres to the rules of that XML application. For instance, in XHTML, li elements should only be children of ul or ol elements. Browsers may not know what to do with them, or may act inconsistently, if li elements appear in the middle of a blockquote or p element.
The solution to this dilemma is a document type definition (DTD). DTDs are written in a formal syntax that explains precisely which elements and entities may appear where in the document and what the elements' contents and attributes are. A DTD can make statements such as "A ul element only contains li elements" or "Every employee element must have a social_security_number attribute." Different XML applications can use different DTDs to specify what they do and do not allow.
A validating parser compares a document to its DTD and lists any places where the document differs from the constraints specified in the DTD.[3] The program can then decide what it wants to do about any violations. Some programs may reject the document. Others may try to fix the document or reject just the invalid element. Validation is an optional step in processing XML. A validity error is not necessarily a fatal error like a well-formedness error, though some applications may choose to treat it as one.
[3]The document type declaration and the document type definition are two different things. The abbreviation DTD is properly used only to refer to the document type definition.
3.1. Validation
A valid document includes a document type declaration that identifies the DTD the document satisfies. The DTD lists all the elements, attributes, and entities the document uses and the contexts in which it uses them. The DTD may list items the document does not use as well. Validity operates on the principle that everything not permitted is forbidden. Everything in the document must match a declaration in the DTD. If a document has a document type declaration and the document satisfies the DTD that the document type declaration indicates, then the document is said to be valid. If it does not, it is said to be invalid.
There are many things the DTD does not say. In particular, it does not say the following:
-
What the root element of the document is
-
How many of instances of each kind of element appear in the document
-
What the character data inside the elements looks like
-
The semantic meaning of an element; for instance, whether it contains a date or a person's name
DTDs allow you to place some constraints on the form an XML document takes, but there can be quite a bit of flexibility within those limits. A DTD never says anything about the length, structure, meaning, allowed values, or other aspects of the text content of an element.
Validity is optional. A parser reading an XML document may or may not check for validity. If it does check for validity, the program receiving data from the parser may or may not care about validity errors. In some cases, such as feeding records into a database, a validity error may be quite serious, indicating that a required field is missing, for example. In other cases, rendering a web page perhaps, a validity error may not be so important, and you can work around it. Well-formedness is required of all XML documents; validity is not. Your documents and your programs can use it or not as you find needful.
3.1.1. A Simple DTD Example
Recall Example 2-2 from the last chapter; this described a person. The person had a name and three professions. The name had a first name and a last name. The particular person described in that example was Alan Turing. However, that's not relevant for DTDs. A DTD only describes the general type, not the specific instance. A DTD for person documents would say that a person element contains one name child element and zero or more profession child elements. It would further say that each name element contains a first_name child element and a last_name child element. Finally it would state that the first_name, last_name, and profession elements all contain text. Example 3-1 is a DTD that describes such a person element.
Example 3-1. A DTD for the person
<!ELEMENT person (name, profession*)> <!ELEMENT name (first_name, last_name)> <!ELEMENT first_name (#PCDATA)> <!ELEMENT last_name (#PCDATA)> <!ELEMENT profession (#PCDATA)>
This DTD would probably be stored in a separate file from the documents it describes. This allows it to be easily referenced from multiple XML documents. However, it can be included inside the XML document if that's convenient, using the document type declaration we discuss later in this section. If it is stored in a separate file, then that file would most likely be named person.dtd, or something similar. The .dtd extension is fairly standard though not specifically required by the XML specification. If this file were served by a web server, it would be given the MIME media type application/xml-dtd.
Each line of Example 3-1 is an element declaration. The first line declares the person element; the second line declares the name element; the third line declares the first_name element; and so on. However, the line breaks aren't relevant except for legibility. Although it's customary to put only one declaration on each line, it's not required. Long declarations can even span multiple lines.
The first element declaration in Example 3-1 states that each person element must contain exactly one name child element followed by zero or more profession elements. The asterisk after profession stands for "zero or more." Thus, every person must have a name and may or may not have a profession or multiple professions. However, the name must come before all professions. For example, this person element is valid:
<person>
<name>
<first_name>Alan</first_name>
<last_name>Turing</last_name>
</name>
</person>However, this person element is not valid because it omits the name:
<person> <profession>computer scientist</profession> <profession>mathematician</profession> <profession>cryptographer</profession> </person>
This person element is not valid because a profession element comes before the name:
<person>
<profession>computer scientist</profession>
<name>
<first_name>Alan</first_name>
<last_name>Turing</last_name>
</name>
<profession>mathematician</profession>
<profession>cryptographer</profession>
</person>The person element may not contain any element except those listed in its declaration. The only extra character data it can contain is whitespace. For example, this is an invalid person element because it adds a publication element:
<person>
<name>
<first_name>Alan</first_name>
<last_name>Turing</last_name>
</name>
<profession>mathematician</profession>
<profession>cryptographer</profession>
<publication>On Computable Numbers...</publication>
</person>This is an invalid person element because it adds some text outside the allowed children:
<person>
<name>
<first_name>Alan</first_name>
<last_name>Turing</last_name>
</name>
was a <profession>computer scientist</profession>,
a <profession>mathematician</profession>, and a
<profession>cryptographer</profession>
</person>In all these examples of invalid elements, you could change the DTD to make these elements valid. All the examples are well-formed, after all. However, with the DTD in Example 3-1, they are not valid.
The name declaration says that each name element must contain exactly one first_name element followed by exactly one last_name element. All other variations are forbidden.
The remaining three declarations--first_name, last_name, and profession--all say that their elements must contain #PCDATA. This is a DTD keyword standing for parsed character data --that is, raw text possibly containing entity references such as & and <, but not containing any tags or child elements.
Example 3-1 placed the most complicated and highest-level declaration at the top. However, that's not required. For instance, Example 3-2 is an equivalent DTD that simply reorders the declarations. DTDs allow forward, backward, and circular references to other declarations.
Example 3-2. An alternate DTD for the person element
<!ELEMENT first_name (#PCDATA)> <!ELEMENT last_name (#PCDATA)> <!ELEMENT profession (#PCDATA)> <!ELEMENT name (first_name, last_name)> <!ELEMENT person (name, profession*)>
3.1.2. The Document Type Declaration
A valid document includes a reference to the DTD to which it should be compared. This is given in the document's single document type declaration. A document type declaration looks like this:
<!DOCTYPE person SYSTEM "http://www.cafeconleche.org/dtds/person.dtd">
This says that the root element of the document is person and that the DTD for this document can be found at the URI http://www.cafeconleche.org/dtds/person.dtd.
TIP: URI stands for Uniform Resource Identifier. URIs are a superset of URLs . They include not only URLs but also Uniform Resource Names (URNs). A URN allows you to identify a resource such as the DTD for SVGs irrespective of its location. Indeed, the resource might exist at multiple locations, all equally authoritative. In practice, the only URIs in wide use today are URLs.
The document type declaration is included in the prolog of the XML document after the XML declaration but before the root element. (The prolog is everything in the XML document before the root element start-tag.) Example 3-3 demonstrates.
Example 3-3. A valid person document
<?xml version="1.0" standalone="no"?>
<!DOCTYPE person SYSTEM "http://www.cafeconleche.org/dtds/person.dtd">
<person>
<name>
<first_name>Alan</first_name>
<last_name>Turing</last_name>
</name>
<profession>computer scientist</profession>
<profession>mathematician</profession>
<profession>cryptographer</profession>
</person>If the document resides at the same base site as the DTD, you can use a relative URL instead of the absolute form. For example:
<!DOCTYPE person SYSTEM "/dtds/person.dtd">
You can even use just the filename if the DTD is in the same directory as the document:
<!DOCTYPE person SYSTEM "person.dtd">
3.1.2.1. Public IDs
Standard DTDs may actually be stored at multiple URLs. For example, if you're drawing an SVG picture on your laptop at the beach, you probably want to validate your drawing without opening a network connection to the W3C's web site where the official SVG DTD resides. Such DTDs may be associated with public IDs. The name of the public ID uniquely identifies the XML application in use. At the same time, a backup URI is also included in case the validator does not recognize the public ID. To indicate that you're specifying a public ID, use the keyword PUBLIC in place of SYSTEM. For example, this document type declaration refers to the Rich Site Summary (RSS) DTD standardized by Netscape:
<!DOCTYPE rss PUBLIC "-//Netscape Communications//DTD RSS 0.91//EN"
"http://my.netscape.com/publish/formats/rss-0.91.dtd">A local catalog server can be used to convert the public IDs into the most appropriate URLs for the local environment. The catalogs themselves can be written in XML, specifically, the OASIS XML catalog format (http://www.oasis-open.org/committees/entity/spec.html). In practice, however, PUBLIC IDs aren't used very much. Almost all validators rely on the URI to actually validate the document.
3.1.3. Internal DTD Subsets
When you're first developing a DTD, it's often useful to keep the DTD and the canonical example document in the same file so you can modify and check them simultaneously. Therefore, the document type declaration may actually contain the DTD between square brackets rather than referencing it at an external URI. Example 3-4 demonstrates.
Example 3-4. A valid person document with an internal DTD
<?xml version="1.0"?>
<!DOCTYPE person [
<!ELEMENT first_name (#PCDATA)>
<!ELEMENT last_name (#PCDATA)>
<!ELEMENT profession (#PCDATA)>
<!ELEMENT name (first_name, last_name)>
<!ELEMENT person (name, profession*)>
]>
<person>
<name>
<first_name>Alan</first_name>
<last_name>Turing</last_name>
</name>
<profession>computer scientist</profession>
<profession>mathematician</profession>
<profession>cryptographer</profession>
</person>Some document type declarations contain some declarations directly but link in others using a SYSTEM or PUBLIC identifier. For example, this document type declaration declares the profession and person elements itself but relies on the file name.dtd to contain the declaration of the name element:
<!DOCTYPE person SYSTEM "name.dtd" [ <!ELEMENT profession (#PCDATA)> <!ELEMENT person (name, profession*)> ]>
The part of the DTD between the brackets is called the internal DTD subset. All the parts that come from outside this document are called the external DTD subset. Together they make up the complete DTD. As a general rule, the two different subsets must be compatible. Neither can override the element declarations the other makes. For example, if name.dtd also declared the person element, then there would be a problem. However, entity declarations can be overridden with some important consequences for DTD structure and design, which we'll see shortly when we discuss entities.
When you use an external DTD subset, you should give the standalone attribute of the XML declaration the value no. For example:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
TIP: Actually, the XML specification includes four very detailed rules about exactly when the presence of an external DTD subset does and does not require the standalone attribute to have the value no. However, the net effect of these rules is that almost all XML documents that use external DTD subsets require standalone to have the value no. Since setting standalone to no is always permitted even when it's not required, it's simply not worth worrying about the uncommon cases.
A validating processor is required to read the external DTD subset. A nonvalidating processor may do so, but is not required to, even if standalone has the value no. This means that if the external subset makes declarations that have consequences for the content of a document (for instance, providing default values for attributes) then the content of the document depends on which parser you're using and how it's configured. This has led to no end of confusion. Although some of the earliest XML parsers did not resolve external entities, most of the parsers still being used can do so and generally will do so. You should read the external DTD subset unless efficiency is a major concern or you're very familiar with the structure of the documents you're parsing.
3.1.4. Validating a Document
As a general rule, web browsers do not validate documents but only check them for well-formedness. If you're writing your own programs to process XML, you can use the parser's API to validate documents. If you're writing documents by hand and you want to validate them, you can either use one of the online validators or run a local program to validate the document.
The online validators are probably the easiest way to validate your documents. There are two of note:
-
The Brown University Scholarly Technology Group's XML Validation Form at http://www.stg.brown.edu/service/xmlvalid/
-
Richard Tobin's XML well-formedness checker and validator at http://www.cogsci.ed.ac.uk/%7Erichard/xml-check.html
First, you have to place the document and associated DTDs on a publicly accessible web server. Next, load one of the previous URLs in a browser, and type the URL of the document you're checking into the online form. The validating server will retrieve your document and tell you what, if any, errors it found. Figure 3-1 shows the results of using the Brown validator on a simple invalid but well-formed document.

Figure 3-1. Validity errors detected by the Brown University online validator
Most XML parser class libraries include a simple program to validate documents you can use if you're comfortable installing and using command-line programs. In Xerces 1.x, that program is sax.SAXCount. (Xerces 2.x uses sax.Counter instead.) Use the -v flag to turn on validation. (By default, SAXCount only checks for well-formedness.) Then pass the URLs or filenames of the documents you wish to validate to the SAXCount program on the command line like this:
C:\>java sax.SAXCount -v invalid_fibonacci.xml [Error] invalid_fibonacci.xml:8:10: Element type "title" must be declared. [Error] invalid_fibonacci.xml:110:22: The content of element type "Fibonacci_Numbers" must match "(fibonacci)*". fibonacci.xml: 541 ms (103 elems, 101 attrs, 307 spaces, 1089 chars)
You can see from this output that the document invalid_fibonacci.xml has two validity errors that need to be fixed: the first in line 8 and the second in line 110.
There are also some simple GUI programs for validating XML documents, including the Topologi Schematron Validator for Windows (http://www.topologi.com) shown in Figure 3-2. Despite the name, this product can actually validate documents against schemas written in multiple languages, including DTDs and the W3C XML Schema Language, as well as Schematron.
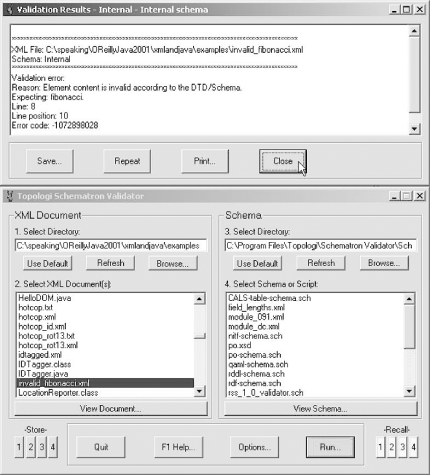
Figure 3-2. Validity errors detected by the Topologi Schematron Validator
|  | |
| 2.10. Checking Documents for Well-Formedness |  | 3.2. Element Declarations |

Copyright © 2002 O'Reilly & Associates. All rights reserved.