
 |  |
2.2. Elements, Tags, and Character Data
The document in Example 2-1 is composed of a single element named person. The element is delimited by the start-tag <person> and the end-tag </person>. Everything between the start-tag and the end-tag of the element (exclusive) is called the element's content. The content of this element is the text string:
Alan Turing
The whitespace is part of the content, though many applications will choose to ignore it. <person> and </person> are markup. The string "Alan Turing" and its surrounding whitespace are character data. The tag is the most common form of markup in an XML document, but there are other kinds we'll discuss later.
2.2.1. Tag Syntax
XML tags look superficially like HTML tags. Start-tags begin with < and end-tags begin with </. Both of these are followed by the name of the element and are closed by >. However, unlike HTML tags, you are allowed to make up new XML tags as you go along. To describe a person, use <person> and </person> tags. To describe a calendar, use <calendar> and </calendar> tags. The names of the tags generally reflect the type of content inside the element, not how that content will be formatted.
2.2.1.1. Empty elements
There's also a special syntax for empty elements, i.e., elements that have no content. Such an element can be represented by a single empty-element tag that begins with < but ends with />. For instance, in XHTML, an XMLized reformulation of standard HTML, the line-break and horizontal-rule elements are written as <br /> and <hr /> instead of <br> and <hr>. These are exactly equivalent to <br></br> and <hr></hr>, however. Which form you use for empty elements is completely up to you. However, what you cannot do in XML and XHTML (unlike HTML) is use only the start-tag--for instance <br> or <hr>--without using the matching the end-tag. That would be a well-formedness error.
2.2.1.2. Case sensitivity
XML, unlike HTML, is case sensitive. <Person> is not the same as <PERSON> is not the same as <person>. If you open an element with a <person> tag, you can't close it with a </PERSON> tag. You're free to use upper- or lowercase or both as you choose. You just have to be consistent within any one element.
2.2.2. XML Trees
Let's look at a slightly more complicated XML document. Example 2-2 is a person element that contains more information suitably marked up to show its meaning.
Example 2-2. A more complex XML document describing a person
<person>
<name>
<first_name>Alan</first_name>
<last_name>Turing</last_name>
</name>
<profession>computer scientist</profession>
<profession>mathematician</profession>
<profession>cryptographer</profession>
</person>2.2.2.1. Parents and children
This XML document is still composed of one person element. However, now this element doesn't merely contain undifferentiated character data. It contains four child elements: a name element and three profession elements. The name element contains two child elements of its own, first_name and last_name.
The person element is called the parent of the name element and the three profession elements. The name element is the parent of the first_name and last_name elements. The name element and the three profession elements are sometimes called each other's siblings. The first_name and last_name elements are also siblings.
As in human society, any one parent may have multiple children. However, unlike human society, XML gives each child exactly one parent, not two or more. Each element (with one exception I'll note shortly) has exactly one parent element. That is, it is completely enclosed by another element. If an element's start-tag is inside some element, then its end-tag must also be inside that element. Overlapping tags, as in <strong><em>this common example from HTML</strong></em>, are prohibited in XML. Since the em element begins inside the strong element, it must also finish inside the strong element.
2.2.2.2. The root element
Every XML document has one element that does not have a parent. This is the first element in the document and the element that contains all other elements. In Example 2-1 and Example 2-2, the person element filled this role. It is called the root element of the document . It is also sometimes called the document element. Every well-formed XML document has exactly one root element. Since elements may not overlap, and since all elements except the root have exactly one parent, XML documents form a data structure programmers call a tree. Figure 2-1 diagrams this relationship for Example 2-2. Each gray box represents an element. Each black box represents character data. Each arrow represents a containment relationship.
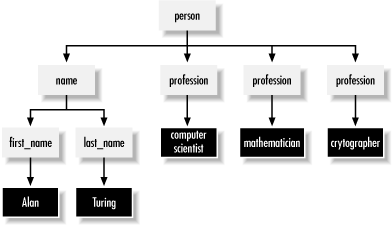
Figure 2-1. A tree diagram for Example 2-2
2.2.3. Mixed Content
In Example 2-2, the contents of the first_name, last_name, and profession elements were character data, that is, text that does not contain any tags. The contents of the person and name elements were child elements and some whitespace that most applications will ignore. This dichotomy between elements that contain only character data and elements that contain only child elements (and possibly a little whitespace) is common in documents that are data oriented. However, XML can also be used for more free-form, narrative documents such as business reports, magazine articles, student essays, short stories, web pages, and so forth, as shown by Example 2-3.
Example 2-3. A narrative-organized XML document
<biography> <name><first_name>Alan</first_name> <last_name>Turing</last_name> </name> was one of the first people to truly deserve the name <emphasize>computer scientist</emphasize>. Although his contributions to the field are too numerous to list, his best-known are the eponymous <emphasize>Turing Test</emphasize> and <emphasize>Turing Machine</emphasize>. <definition>The <term>Turing Test</term> is to this day the standard test for determining whether a computer is truly intelligent. This test has yet to be passed. </definition> <definition>The <term>Turing Machine</term> is an abstract finite state automaton with infinite memory that can be proven equivalent to any any other finite state automaton with arbitrarily large memory. Thus what is true for a Turing machine is true for all equivalent machines no matter how implemented. </definition> <name><last_name>Turing</last_name></name> was also an accomplished <profession>mathematician</profession> and <profession>cryptographer</profession>. His assistance was crucial in helping the Allies decode the German Enigma machine. He committed suicide on <date><month>June</month> <day>7</day>, <year>1954</year></date> after being convicted of homosexuality and forced to take female hormone injections. </biography>
The root element of this document is biography. The biography contains name, definition, profession, and emphasize child elements. It also contains a lot of raw character data. Some of these elements such as last_name and profession only contain character data. Others such as name contain only child elements. Still others such as definition contain both character data and child elements. These elements are said to contain mixed content. Mixed content is common in XML documents containing articles, essays, stories, books, novels, reports, web pages, and anything else that's organized as a written narrative. Mixed content is less common and harder to work with in computer-generated and processed XML documents used for purposes such as database exchange, object serialization, persistent file formats, and so on. One of the strengths of XML is the ease with which it can be adapted to the very different requirements of human-authored and computer-generated documents.
|  | |
| 2. XML Fundamentals |  | 2.3. Attributes |

Copyright © 2002 O'Reilly & Associates. All rights reserved.