
 |  |
Chapter 7. JDOM
JDOM provides a means of accessing an XML document within Java through a tree structure, and in that respect is somewhat similar to the DOM. However, it was built specifically for Java (remember the discussion on language bindings for the DOM?), so is in many ways more intuitive to a Java developer than DOM. I'll describe these aspects of JDOM throughout the chapter, as well as talk about specific cases to use SAX, DOM, or JDOM. And for the complete set of details on JDOM, you should check out the web site at http://www.jdom.org.
Additionally, and importantly, JDOM is an open source API. And because the API is still finalizing on a 1.0 version, it also remains flexible.[7] You have the ability to suggest and implement changes yourself. If you find that you like JDOM, except for one little annoying thing, you can help us investigate solutions to your problem. In this chapter, I'll cover JDOM's current status, particularly with regard to standardization, and the basics on using the API, and I'll give you some working examples.
[7]Because JDOM 1.0 is not final, some things may change between the publication of this book and your download. I'll try and keep a running list of changes on the JDOM web site (http://www.jdom.org) and work with O'Reilly to get these changes and updates available as quickly as possible.
Full Disclosure
In the interests of full disclosure, I should say that I am one of the co-creators of JDOM; my partner in crime on this particular endeavor is Jason Hunter, the noted author of Java Servlet Programming (O'Reilly). Jason and I had some issues with DOM, and during a long discussion at the 2000 O'Reilly Enterprise Java Conference, came up with JDOM. I also owe a great deal of credit to James Davidson (Sun Microsystems, servlet 2.2 specification lead, Ant author, etc.) and Pier Fumagalli (Apache/Jakarta/Cocoon superhero). Plus, the hundreds of good friends on the JDOM mailing lists.
All that to say that I'm partial to JDOM. So, if you sense some favoritism creeping through this chapter, I apologize; I use SAX, DOM, and JDOM often, but I happen to like one more than the others, because in my personal development, it has helped me out. Anyway, consider yourself forewarned!
7.1. The Basics
Chapter 5, "DOM" and Chapter 6, "Advanced DOM" should have given you a pretty good understanding of dealing with XML tree representations. So when I say that JDOM also provides a tree-based representation of an XML document, that gives you a starting point for understanding how JDOM behaves. To help you see how the classes in JDOM match up to XML structures, take a look at Figure 7-1, which shows a UML model of JDOM's core classes.
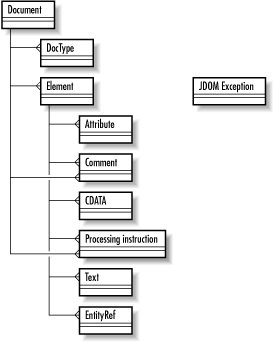
Figure 7-1. UML model of core JDOM classes
As you can see, the names of the classes tell the story. At the core of the JDOM structure is the Document object; it is both the representation of an XML document, and a container for all the other JDOM structures. Element represents an XML element, Attribute an attribute, and so on down the line. If you've immersed yourself in DOM, though, you might think there are some things missing from JDOM. For example, where's the Text class? As you recall, DOM follows a very strict tree model, and element content is actually considered a child node (or nodes) of an element node itself. In JDOM, this was seen as inconvenient in many cases, and the API provides getText( ) methods on the Element class. This allows the content of an element to be obtained from the element itself, and therefore there is no Text class. This was felt to provide a more intuitive approach for Java developers unfamiliar with XML, DOM, or some of the vagaries of trees.
7.1.1. Java Collections Support
Another important item to take note of is that you don't see any list classes like SAX's Attributes class or DOM's NodeList and NamedNodeMap classes. This is a nod to Java developers; it was felt that using Java Collections (java.util.List, java.util.Map, etc.) would provide a familiar and simple API for XML usage. DOM must serve across languages (remember Java language bindings in Chapter 5, "DOM"?), and can't take advantage of language-specific things like Java Collections. For example, when invoking the getAttributes( ) method on the Element class, you get back a List; you can of course operate upon this List just as you would any other Java List, without looking up new methods or syntax.
7.1.2. Concrete Classes and Factories
Another basic tenet of JDOM that is different from DOM, and not so visible, is that JDOM is an API of concrete classes. In other words, Element, Attribute, ProcessingInstruction, Comment, and the rest are all classes that can be directly instantiated using the new keyword. The advantage here is that factories are not needed, as factories can oftentimes be intrusive into code. Creating a new JDOM document would be done like this:
Element rootElement = new Element("root");
Document document = new Document(rootElement);That simple. On the other hand, not using factories can also be seen as a disadvantage. While you can subclass JDOM classes, you would have to explicitly use those subclasses in your code:
element.addContent(new FooterElement("Copyright 2001"));Here, FooterElement is a subclass of org.jdom.Element, and does some custom processing (it could, for example, build up several elements that display a page footer). Because it subclasses Element, it can be added to the element variable through the normal means, the addContent( ) method. However, there is no means to define an element subclass and specify that it should always be used for element instantiation, like this:
// This code does not work!!
JDOMFactory factory = new JDOMFactory( );
factory.setDocumentClass("javaxml2.BrettsDocumentClass");
factory.setElementClass("javaxml2.BrettsElementClass");
Element rootElement = JDOMFactory.createElement("root");
Document document = JDOMFactory.createDocument(rootElement);The idea is that once the factory has been created, specific subclasses of JDOM structures can be specified as the class to use for those structures. Then, every time (for example) an Element is created through the factory, the javaxml2.BrettsElementClass is used instead of the default org.jdom.Element class.
Support for this as an option is growing, if not as a standard means of working with JDOM. That means that in the open source world, it's possible this functionality might be in place by the time you read this, or by the time JDOM is finalized in a 1.0 form. Stay tuned to http://www.jdom.org for the latest on these developments.
7.1.3. Input and Output
A final important aspect of JDOM is its input and output model. First, you should realize that JDOM is not a parser; it is an XML document representation in Java. In other words, like DOM and SAX, it is simply a set of classes that can be used to manipulate the data that a parser provides. As a result, JDOM must rely on a parser for reading raw XML.[8] It can also accept SAX events or a DOM tree as input, as well as JDBC ResultSet instances and more. To facilitate this, JDOM provides a package specifically for input, org.jdom.input. This package provides builder classes; the two you'll use most often are SAXBuilder and DOMBuilder . These build the core JDOM structure, a JDOM Document, from a set of SAX events or a DOM tree. As JDOM standardizes (see Section 7.4, "Is JDOM a Standard?" at the end of this chapter), it's also expected that direct support for JDOM will materialize in parser efforts like Apache Xerces and Sun's Crimson.
[8]By default, this parser is Xerces, which is included with JDOM. However, you can use any other XML parser with JDOM.
For dealing with input streams, files or documents on disk, or building from existing XML not in a DOM tree, SAXBuilder is the best solution. It's fast and efficient, just like SAX. Using the builder is a piece of cake:
SAXBuilder builder = new SAXBuilder( );
Document doc = builder.build(new FileInputStream("contents.xml"));I'll detail this further in the code in the chapter, but you can see that it doesn't take much to get access to XML. If you already have your document in a DOM structure, you'll want to use DOMBuilder, which performs a fast conversion from one API to the other:
DOMBuilder builder = new DOMBuilder( ); Document doc = builder.build(myDomDocumentObject);
It's fairly self-explanatory. This essentially converts from an org.w3c.dom.Document to an org.jdom.Document. The process of converting from a JDOM document back to one of these structures is essentially the same, in reverse; the org.jdom.output package is used for these tasks. To move from JDOM structures to DOM ones, DOMOutputter is used:
DOMOutputter outputter = new DOMOutputter( ); org.w3c.dom.Document domDoc = outputter.output(myJDOMDocumentObject);
Taking a JDOM Document and firing off SAX events works in the same way:
SAXOutputter outputter = new SAXOutputter( ); outputter.setContentHandler(myContentHandler); outputter.setErrorHandler(myErrorHandler); outputter.output(myJDOMDocumentObject);
This works just like dealing with normal SAX events, where you register content handlers, error handlers, and the rest, and then fire events to those handlers from the JDOM Document object supplied to the output( ) method.
The final outputter, and the one you'll probably work with more than any other, is org.jdom.output.XMLOutputter. This outputs XML to a stream or writer, which wraps a network connection, a file, or any other structure you want to push XML to. This also is effectively a production-ready version of the DOMSerializer class from Chapter 5, "DOM", except of course it works with JDOM, not DOM. Using the XMLOutputter works like this:
XMLOutputter outputter = new XMLOutputter( );
outputter.output(jdomDocumentObject, new FileOutputStream("results.xml"));So there you have it; the input and output of JDOM all in a few paragraphs. One last thing to note, as illustrated in Figure 7-2: it is very easy to "loop" things because all the input and output of JDOM is actually part of the API. In other words, you can use a file as input, work with it in JDOM, output it to SAX, DOM, or a file, and then consume that as input, restarting the loop. This is particularly helpful in messaging-based applications, or in cases where JDOM is used as a component between other XML supplying and consuming components.
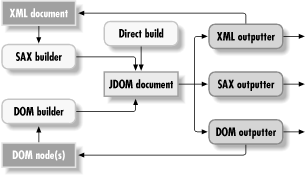
Figure 7-2. Input and output loops in JDOM
This isn't a comprehensive look at JDOM, but it gives you enough information to get started, and I'd rather show you things within the context of working code anyway! So, let's take a look at a utility program that can convert Java properties files to XML.
|  | |
| 6.6. What's Next? |  | 7.2. PropsToXML |

Copyright © 2002 O'Reilly & Associates. All rights reserved.