
 |  |
Chapter 5. DOM
In the previous chapters, I've talked about Java and XML in the general sense, but I have described only SAX in depth. As you may be aware, SAX is just one of several APIs that allow XML work to be done within Java. This chapter and the next will widen your API knowledge as I introduce the Document Object Model, commonly called the DOM. This API is quite a bit different from SAX, and complements the Simple API for XML in many ways. You'll need both, as well as the other APIs and tools in the rest of this book, to be a competent XML developer.
Because DOM is fundamentally different from SAX, I'll spend a good bit of time discussing the concepts behind DOM, and why it might be used instead of SAX for certain applications. Selecting any XML API involves tradeoffs, and choosing between DOM and SAX is certainly no exception. I'll move on to possibly the most important topic: code. I'll introduce you to a utility class that serializes DOM trees, something that the DOM API itself doesn't currently supply. This will provide a pretty good look at the DOM structure and related classes, and get you ready for some more advanced DOM work. Finally, I'll show you some problem areas and important aspects of DOM in the "Gotcha!" section.
5.1. The Document Object Model
The Document Object Model, unlike SAX, has its origins in the World Wide Web Consortium (W3C). Whereas SAX is public-domain software, developed through long discussions on the XML-dev mailing list, DOM is a standard just like the actual XML specification. The DOM is not designed specifically for Java, but to represent the content and model of documents across all programming languages and tools. Bindings exist for JavaScript, Java, CORBA, and other languages, allowing the DOM to be a cross-platform and cross-language specification.
In addition to being different from SAX in regard to standardization and language bindings, the DOM is organized into "levels" instead of versions. DOM Level One is an accepted recommendation, and you can view the completed specification at http://www.w3.org/TR/REC-DOM-Level-1/. Level 1 details the functionality and navigation of content within a document. A document in the DOM is not just limited to XML, but can be HTML or other content models as well! Level Two, which was finalized in November of 2000, adds upon Level 1 by supplying modules and options aimed at specific content models, such as XML, HTML, and Cascading Style Sheets (CSS). These less-generic modules begin to "fill in the blanks" left by the more general tools provided in DOM Level 1. You can view the current Level 2 Recommendation at http://www.w3.org/TR/DOM-Level-2/. Level Three is already being worked on, and should add even more facilities for specific types of documents, such as validation handlers for XML, and other features that I'll discuss in Chapter 6, "Advanced DOM".
5.1.1. Language Bindings
Using the DOM for a specific programming language requires a set of interfaces and classes that define and implement the DOM itself. Because the methods involved are not outlined specifically in the DOM specification, and instead focus on the model of a document, language bindings must be developed to represent the conceptual structure of the DOM for its use in Java or any other language. These language bindings then serve as APIs for you to manipulate documents in the fashion outlined in the DOM specification.
I am obviously concerned with the Java language binding in this book. The latest Java bindings, the DOM Level 2 Java bindings, can be downloaded from http://www.w3.org/TR/DOM-Level-2/java-binding.html. The classes you should be able to add to your classpath are all in the org.w3c.dom package (and its subpackages). However, before downloading these yourself, you should check the XML parser and XSLT processor you purchased or downloaded; like the SAX packages, the DOM packages are often included with these products. This also ensures a correct match between your parser, processor, and the version of DOM that is supported.
Most XSLT processors do not handle the task of generating a DOM input themselves, but instead rely on an XML parser that is capable of generating a DOM tree. This maintains the loose coupling between parser and processor, letting one or the other be substituted with comparable products. As Apache Xalan, by default, uses Apache Xerces for XML parsing and DOM generation, it is the level of support for DOM that Xerces provides that is of interest. The same would be true if you were using Oracle's XSLT and XML processor and parser.[6]
[6]I don't want to imply that you cannot use one vendor's parser and another vendor's processor. In most of these cases, it's possible to specify a different parser for use. However, the default is always going to be the use of the vendor's software across the board.
5.1.2. The Basics
In addition to fundamentals about the DOM specification, I want to give you a bit of information about the DOM programming structure itself. At the core of DOM is a tree model. Remember that SAX gave you a piece-by-piece view of an XML document, reporting each event in the parsing lifecycle as it happened. DOM is in many ways the converse of this, supplying a complete in-memory representation of the document. The document is supplied to you in a tree format, and all of this is built upon the DOM org.w3c.dom.Node interface. Deriving from this interface, DOM provides several XML-specific interfaces, like Element, Document, Attr, and Text. So, in a typical XML document, you might get a structure that looks like Figure 5-1.
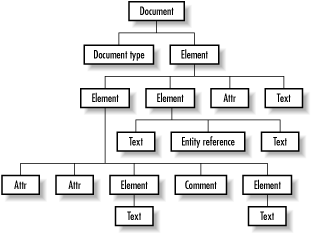
Figure 5-1. DOM structure representing XML
A tree model is followed in every sense. This is particularly notable in the case of the Element nodes that have textual values (as in the Title element). Instead of the textual value of the node being available through the Element node (through, for example, a getText( ) method), there is a child node of type Text. So you would get the child (or children) and the value of the element from the Text node itself. While this might seem a little odd, it does preserve a very strict tree model in DOM, and allows tasks like walking the tree to be very simple algorithms, without a lot of special cases. Because of this model, all DOM structures can be treated either as their generic type, Node, or as their specific type (Element, Attr, etc.). Many of the navigation methods, like getParent( ) and getChildren( ), are on that basic Node interface, so you can walk up and down the tree without worrying about the specific structure type.
Another facet of DOM to be aware of is that, like SAX, it defines its own list structures. You'll need to use the NodeList and NamedNodeMap classes when working with DOM, rather than Java collections. Depending on your point of view, this isn't a positive or negative, just a fact of life. Figure 5-2 shows a simple UML-style model of the DOM core interfaces and classes, which you can refer to throughout the rest of the chapter.
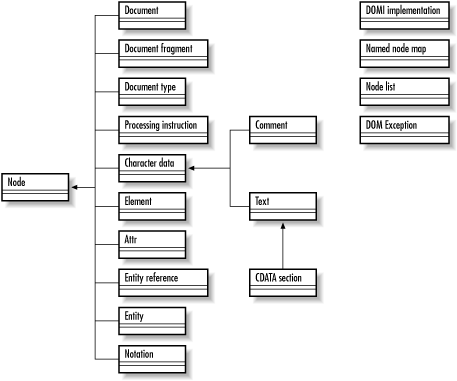
Figure 5-2. UML model of core DOM classes and interfaces
5.1.3. Why Not SAX?
As a final conceptual note before getting into the code, newbies to XML may be wondering why they can't just use SAX for dealing with XML. But sometimes using SAX is like taking a hammer to a scratch on a wall; it's just not the right tool for the job. I discuss a few issues with SAX that make it less than ideal in certain situations.
5.1.3.1. SAX is sequential
The sequential model that SAX provides does not allow for random access to an XML document. In other words, in SAX you get information about the XML document as the parser does, and lose that information when the parser does. When the second element in a document comes along, it cannot access information in the fourth element, because that fourth element hasn't been parsed yet. When the fourth element does comes along, it can't "look back" on that second element. Certainly, you have every right to save the information encountered as the process moves along; coding all these special cases can be very tricky, though. The other, more extreme option is to build an in-memory representation of the XML document. We will see in a moment that a DOM parser does exactly that, so performing the same task in SAX would be pointless, and probably slower and more difficult.
5.1.3.2. SAX siblings
Moving laterally between elements is also difficult with the SAX model. The access provided in SAX is largely hierarchical, as well as sequential. You are going to reach leaf nodes of the first element, then move back up the tree, then down again to leaf nodes of the second element, and so on. At no point is there any clear indication of what "level" of the hierarchy you are at. Although this can be implemented with some clever counters, it is not what SAX is designed for. There is no concept of a sibling element, or of the next element at the same level, or of which elements are nested within which other elements.
The problem with this lack of information is that an XSLT processor (refer to Chapter 2, "Nuts and Bolts") must be able to determine the siblings of an element, and more importantly, the children of an element. Consider the following code snippet in an XSL template:
<xsl:template match="parentElement"> <!-- Add content to the output tree --> <xsl:apply-templates select="childElementOne|childElementTwo" /> </xsl:template>
Here, templates are applied via the xsl:apply-templates construct, but they are being applied to a specific node set that matches the given XPath expression. In this example, the template should be applied only to the elements childElementOne or childElementTwo (separated by the XPath OR operator, the pipe). In addition, because a relative path is used, these must be direct children of the element parentElement. Determining and locating these nodes with a SAX representation of an XML document would be extremely difficult. With an in-memory, hierarchical representation of the XML document, locating these nodes is trivial, a primary reason why the DOM approach is heavily used for input into XSLT processors.
5.1.3.3. Why use SAX at all?
All these discussions about the "shortcomings" of SAX may have you wondering why one would ever choose to use SAX at all. But these shortcomings are all in regard to a specific application of XML data, in this case processing it through XSL, or using random access for any other purpose. In fact, all of these "problems" with using SAX are the exact reason you would choose to use SAX.
Imagine parsing a table of contents represented in XML for an issue of National Geographic. This document could easily be 500 lines in length, more if there is a lot of content within the issue. Imagine an XML index for an O'Reilly book: hundreds of words, with page numbers, cross-references, and more. And these are all fairly small, concise applications of XML. As an XML document grows in size, so does the in-memory representation when represented by a DOM tree. Imagine (yes, keep imagining) an XML document so large and with so many nestings that the representation of it using the DOM begins to affect the performance of your application. And now imagine that the same results could be obtained by parsing the input document sequentially using SAX, and would only require one-tenth, or one-hundredth, of your system's resources to accomplish the task.
Just as in Java there are many ways to do the same job, there are many ways to obtain the data in an XML document. In some scenarios, SAX is easily the better choice for quick, less-intensive parsing and processing. In others, the DOM provides an easy-to-use, clean interface to data in a desirable format. You, the developer, must always analyze your application and its purpose to make the correct decision as to which method to use, or how to use both in concert. As always, the power to make good or bad decisions lies in your knowledge of the alternatives. Keeping that in mind, it's time to look at the DOM in action.
|  | |
| 4.6. What's Next? |  | 5.2. Serialization |

Copyright © 2002 O'Reilly & Associates. All rights reserved.