
 |  |
3.3. Content Handlers
In order to let an application do something useful with XML data as it is being parsed, you must register handlers with the SAX parser. A handler is nothing more than a set of callbacks that SAX defines to let programmers insert application code at important events within a document's parsing. These events take place as the document is parsed, not after the parsing has occurred. This is one of the reasons that SAX is such a powerful interface: it allows a document to be handled sequentially, without having to first read the entire document into memory. Later, we will look at the Document Object Model (DOM), which has this limitation.[3]
[3]Of course, this limitation is also an advantage; having the entire document in memory allows for random access. In other words, it's a double-edged sword, which I'll look at more in Chapter 5, "DOM".
There are four core handler interfaces defined by SAX 2.0: org.xml.sax.ContentHandler , org.xml.sax.ErrorHandler, org.xml.sax.DTDHandler, and org.xml.sax.EntityResolver. In this chapter, I will discuss ContentHandler and ErrorHandler. I'll leave discussion of DTDHandler and EntityResolver for the next chapter; it is enough for now to understand that EntityResolver works just like the other handlers, and is built specifically for resolving external entities specified within an XML document. Custom application classes that perform specific actions within the parsing process can implement each of these interfaces. These implementation classes can be registered with the reader using the methods setContentHandler( ) , setErrorHandler( ), setDTDHandler( ), and setEntityResolver( ). Then the reader invokes the callback methods on the appropriate handlers during parsing.
For the SAXTreeViewer example, a good start is to implement the ContentHandler interface. This interface defines several important methods within the parsing lifecycle that our application can react to. Since all the necessary import statements are in place (I cheated and put them in already), all that is needed is to code an implementation of the ContentHandler interface. For simplicity, I'll do this as a nonpublic class, still within the SAXTreeViewer.java source file. Add in the JTreeContentHandler class, as shown here:
class JTreeContentHandler implements ContentHandler {
/** Tree Model to add nodes to */
private DefaultTreeModel treeModel;
/** Current node to add sub-nodes to */
private DefaultMutableTreeNode current;
public JTreeContentHandler(DefaultTreeModel treeModel,
DefaultMutableTreeNode base) {
this.treeModel = treeModel;
this.current = base;
}
// ContentHandler method implementations
}Don't bother trying to compile the source file at this point; you'll get a ton of errors about methods defined in ContentHandler not being implemented. The rest of this section walks through each of these methods, adding as we go. In this basic class, it's enough to pass in the TreeModel implementation, which is used to add new nodes to the JTree, and the base node (created in the buildTree( ) method, earlier). The base node is set to a member variable called current; this variable always points to the node being worked with, and the code needs to move that node down the tree hierarchy (when nested elements are found), as well as back up the tree (when elements end and the parent becomes current again). With that in place, it's time to look at the various ContentHandler callbacks and implement each. First take a quick glance at the ContentHandler interface, which shows the callbacks that need to be implemented:
public interface ContentHandler {
public void setDocumentLocator(Locator locator);
public void startDocument( ) throws SAXException;
public void endDocument( ) throws SAXException;
public void startPrefixMapping(String prefix, String uri)
throws SAXException;
public void endPrefixMapping(String prefix)
throws SAXException;
public void startElement(String namespaceURI, String localName,
String qName, Attributes atts)
throws SAXException;
public void endElement(String namespaceURI, String localName,
String qName)
throws SAXException;
public void characters(char ch[], int start, int length)
throws SAXException;
public void ignorableWhitespace(char ch[], int start, int length)
throws SAXException;
public void processingInstruction(String target, String data)
throws SAXException;
public void skippedEntity(String name)
throws SAXException;
}3.3.1. The Document Locator
The first method you need to define is one that sets an org.xml.sax.Locator for use within any other SAX events. When a callback event occurs, the class implementing a handler often needs access to the location of the SAX parser within an XML file. This is used to help the application make decisions about the event and its location within the XML document, such as determining the line on which an error occurred. The Locator class has several useful methods such as getLineNumber( ) and getColumnNumber( ) that return the current location of the parsing process within an XML file when invoked. Because this location is only valid for the current parsing lifecycle, the Locator should be used only within the scope of the ContentHandler implementation. Since this might be handy to use later, the code shown here saves the provided Locator instance to a member variable:
class JTreeContentHandler implements ContentHandler {
/** Hold onto the locator for location information */
private Locator locator;
// Constructor
public void setDocumentLocator(Locator locator) {
// Save this for later use
this.locator = locator;
}
}3.3.2. The Beginning and the End of a Document
In any lifecycle process, there must always be a beginning and an end. These important events should each occur once, the former before all other events, and the latter after all other events. This rather obvious fact is critical to applications, as it allows them to know exactly when parsing begins and ends. SAX provides callback methods for each of these events, startDocument( ) and endDocument( ).
The first method, startDocument( ), is called before any other callbacks, including the callback methods within other SAX handlers, such as DTDHandler. In other words, startDocument( ) is not only the first method called within ContentHandler, but also within the entire parsing process, aside from the setDocument-Locator( ) method just discussed. This ensures a finite beginning to parsing, and lets the application perform any tasks it needs to before parsing takes place.
The second method, endDocument( ), is always the last method called, again across all handlers. This includes situations in which errors occur that cause parsing to halt. I will discuss errors later, but there are both recoverable errors and unrecoverable errors. If an unrecoverable error occurs, the ErrorHandler's callback method is invoked, and then a final call to endDocument( ) completes the attempted parsing.
In the example code, no visual event should occur with these methods; however, as with implementing any interface, the methods must still be present:
public void startDocument( ) throws SAXException {
// No visual events occur here
}
public void endDocument( ) throws SAXException {
// No visual events occur here
}Both of these callback methods can throw SAXExceptions. The only types of exceptions that SAX events ever throw, they provide another standard interface to the parsing behavior. However, these exceptions often wrap other exceptions that indicate what problems have occurred. For example, if an XML file was parsed over the network via a URL, and the connection suddenly became invalid, a java.net.SocketException might occur. However, an application using the SAX classes should not have to catch this exception, because it should not have to know where the XML resource is located (it might be a local file, as opposed to a network resource). Instead, the application can catch the single SAXException. Within the SAX reader, the original exception is caught and rethrown as a SAXException, with the originating exception stuffed inside the new one. This allows applications to have one standard exception to trap for, while allowing specific details of what errors occurred within the parsing process to be wrapped and made available to the calling program through this standard exception. The SAXException class provides a method, getException( ), which returns the underlying Exception (if one exists).
3.3.3. Processing Instructions
I talked about processing instructions (PIs) within XML as a bit of a special case. They were not considered XML elements, and were handled differently by being made available to the calling application. Because of these special characteristics, SAX defines a specific callback for handling processing instructions. This method receives the target of the processing instruction and any data sent to the PI. For this chapter's example, the PI can be converted to a new node and displayed in the tree viewer:
public void processingInstruction(String target, String data)
throws SAXException {
DefaultMutableTreeNode pi =
new DefaultMutableTreeNode("PI (target = '" + target +
"', data = '" + data + "')");
current.add(pi);
}In a real application using XML data, this is where an application could receive instructions and set variable values or execute methods to perform application-specific processing. For example, the Apache Cocoon publishing framework might set flags to perform transformations on the data once it is parsed, or to display the XML as a specific content type. This method, like the other SAX callbacks, throws a SAXException when errors occur.
NOTE: It's worth pointing out that this method will not receive notification of the XML declaration:<?xml version="1.0" standalone="yes"?>In fact, SAX provides no means of getting at this information (and you'll find out that it's not currently part of DOM or JDOM, either!). The general underlying principle is that this information is for the XML parser or reader, not the consumer of the document's data. For that reason, it's not exposed to the developer.
3.3.4. Namespace Callbacks
From the discussion of namespaces in Chapter 2, "Nuts and Bolts", you should be starting to realize their importance and impact on parsing and handling XML. Alongside XML Schema, XML Namespaces is easily the most significant concept added to XML since the original XML 1.0 Recommendation. With SAX 2.0, support for namespaces was introduced at the element level. This allows a distinction to be made between the namespace of an element, signified by an element prefix and an associated namespace URI, and the local name of an element. In this case, the term local name refers to the unprefixed name of an element. For example, the local name of the ora:copyright element is simply copyright. The namespace prefix is ora, and the namespace URI is declared as http://www.oreilly.com.
There are two SAX callbacks specifically dealing with namespaces. These callbacks are invoked when the parser reaches the beginning and end of a prefix mapping. Although this is a new term, it is not a new concept; a prefix mapping is simply an element that uses the xmlns attribute to declare a namespace. This is often the root element (which may have multiple mappings), but can be any element within an XML document that declares an explicit namespace. For example:
<catalog>
<books>
<book title="XML in a Nutshell"
xmlns:xlink="http://www.w3.org/1999/xlink">
<cover xlink:type="simple" xlink:show="onLoad"
xlink:href="xmlnutCover.jpg" ALT="XML in a Nutshell"
width="125" height="350" />
</book>
</books>
</catalog>In this case, an explicit namespace is declared several element nestings deep within the document. That prefix and URI mapping (in this case, xlink and http://www.w3.org/1999/xlink, respectively) are then available to elements and attributes within the declaring element.
The startPrefixMapping( ) callback is given the namespace prefix as well as the URI associated with that prefix. The mapping is considered "closed" or "ended" when the element that declared the mapping is closed, which triggers the endPrefixMapping( ) callback. The only twist to these callbacks is that they don't quite behave in the sequential manner in which SAX usually is structured; the prefix mapping callback occurs directly before the callback for the element that declares the namespace, and the ending of the mapping results in an event just after the close of the declaring element. However, it actually makes a lot of sense: for the declaring element to be able to use the declared namespace mapping, the mapping must be available before the element's callback. It works in just the opposite way for ending a mapping: the element must close (as it may use the namespace), and then the namespace mapping can be removed from the list of available mappings.
In the JTreeContentHandler, there aren't any visual events that should occur within these two callbacks. However, a common practice is to store the prefix and URI mappings in a data structure. You will see in a moment that the element callbacks report the namespace URI, but not the namespace prefix. If you don't store these prefixes (reported through startPrefixMapping( )), they won't be available in your element callback code. The easiest way to do this is to use a Map, add the reported prefix and URI to this Map in startPrefixMapping( ), and then remove them in endPrefixMapping( ). This can be accomplished with the following code additions:
class JTreeContentHandler implements ContentHandler {
/** Hold onto the locator for location information */
private Locator locator;
/** Store URI to prefix mappings */
private Map namespaceMappings;
/** Tree Model to add nodes to */
private DefaultTreeModel treeModel;
/** Current node to add sub-nodes to */
private DefaultMutableTreeNode current;
public JTreeContentHandler(DefaultTreeModel treeModel,
DefaultMutableTreeNode base) {
this.treeModel = treeModel;
this.current = base;
this.namespaceMappings = new HashMap( );
}
// Existing methods
public void startPrefixMapping(String prefix, String uri) {
// No visual events occur here.
namespaceMappings.put(uri, prefix);
}
public void endPrefixMapping(String prefix) {
// No visual events occur here.
for (Iterator i = namespaceMappings.keySet().iterator( );
i.hasNext( ); ) {
String uri = (String)i.next( );
String thisPrefix = (String)namespaceMappings.get(uri);
if (prefix.equals(thisPrefix)) {
namespaceMappings.remove(uri);
break;
}
}
}
}One thing of note: I used the URI as a key to the mappings, rather than the prefix. As I mentioned a moment ago, the startElement( ) callback reports the namespace URI for the element, not the prefix. So keying on URIs makes those lookups faster. However, as you see in endPrefixMapping( ), it does add a little bit of work to removing the mapping when it is no longer available. In any case, storing namespace mappings in this fashion is a fairly typical SAX trick, so store it away in your toolkit for XML programming.
WARNING: The solution shown here is far from a complete one in terms of dealing with more complex namespace issues. It's perfectly legal to reassign prefixes to new URIs for an element's scope, or to assign multiple prefixes to the same URI. In the example, this would result in widely scoped namespace mappings being overwritten by narrowly scoped ones in the case where identical URIs were mapped to different prefixes. In a more robust application, you would want to store prefixes and URIs separately, and have a method of relating the two without causing overwriting. However, you get the idea in the example of how to handle namespaces in the general sense.
3.3.5. Element Callbacks
By now you are probably ready to get to the data in the XML document. It is true that over half of the SAX callbacks have nothing to do with XML elements, attributes, and data. This is because the process of parsing XML is intended to do more than simply provide your application with the XML data; it should give the application instructions from XML PIs so your application knows what actions to take, let the application know when parsing begins and when it ends, and even tell it when there is whitespace that can be ignored! If some of these callbacks don't make much sense yet, keep reading.
Of course, there certainly are SAX callbacks intended to give you access to the XML data within your documents. The three primary events involved in getting that data are the start and end of elements and the characters( ) callback. These tell you when an element is parsed, the data within that element, and when the closing tag for that element is reached. The first of these, startElement( ), gives an application information about an XML element and any attributes it may have. The parameters to this callback are the name of the element (in various forms) and an org.xml.sax.Attributes instance. This helper class holds references to all of the attributes within an element. It allows easy iteration through the element's attributes in a form similar to a Vector. In addition to being able to reference an attribute by its index (used when iterating through all attributes), it is possible to reference an attribute by its name. Of course, by now you should be a bit cautious when you see the word "name" referring to an XML element or attribute, as it can mean various things. In this case, either the complete name of the attribute (with a namespace prefix, if any), called its Q name, can be used, or the combination of its local name and namespace URI if a namespace is used. There are also helper methods such as getURI(int index) and getLocal-Name(int index) that help give additional namespace information about an attribute. Used as a whole, the Attributes interface provides a comprehensive set of information about an element's attributes.
In addition to the element attributes, you get several forms of the element's name. This again is in deference to XML namespaces. The namespace URI of the element is supplied first. This places the element in its correct context across the document's complete set of namespaces. Then the local name of the element is supplied, which is the unprefixed element name. In addition (and for backwards compatibility), the Q name of the element is supplied. This is the unmodified, unchanged name of the element, which includes a namespace prefix if present; in other words, exactly what was in the XML document: ora:copyright for the copyright element. With these three types of names supplied, you should be able to describe an element with or without respect to its namespace.
In the example, several things occur that illustrate this capability. First, a new node is created and added to the tree with the local name of the element. Then, that node becomes the current node, so all nested elements and attributes are added as leaves. Next, the namespace is determined, using the supplied namespace URI and the namespaceMappings object (to get the prefix) that you just added to the code from the last section. This is added as a node, as well. Finally, the code iterates through the Attributes interface, adding each (with local name and namespace information) as a child node. The code to accomplish all this is shown here:
public void startElement(String namespaceURI, String localName,
String qName, Attributes atts)
throws SAXException {
DefaultMutableTreeNode element =
new DefaultMutableTreeNode("Element: " + localName);
current.add(element);
current = element;
// Determine namespace
if (namespaceURI.length( ) > 0) {
String prefix =
(String)namespaceMappings.get(namespaceURI);
if (prefix.equals("")) {
prefix = "[None]";
}
DefaultMutableTreeNode namespace =
new DefaultMutableTreeNode("Namespace: prefix = '" +
prefix + "', URI = '" + namespaceURI + "'");
current.add(namespace);
}
// Process attributes
for (int i=0; i<atts.getLength( ); i++) {
DefaultMutableTreeNode attribute =
new DefaultMutableTreeNode("Attribute (name = '" +
atts.getLocalName(i) +
"', value = '" +
atts.getValue(i) + "')");
String attURI = atts.getURI(i);
if (attURI.length( ) > 0) {
String attPrefix =
(String)namespaceMappings.get(namespaceURI);
if (attPrefix.equals("")) {
attPrefix = "[None]";
}
DefaultMutableTreeNode attNamespace =
new DefaultMutableTreeNode("Namespace: prefix = '" +
attPrefix + "', URI = '" + attURI + "'");
attribute.add(attNamespace);
}
current.add(attribute);
}
}The end of an element is much easier to code. Since there is no need to give any visual information, all that must be done is to walk back up the tree one node, leaving the element's parent as the new current node:
public void endElement(String namespaceURI, String localName,
String qName)
throws SAXException {
// Walk back up the tree
current = (DefaultMutableTreeNode)current.getParent( );
}One final note before moving on to element data: you may have noticed that with a namespace URI and an element's Q name, it would be possible to figure out the prefix as well as the URI from the information supplied to the startElement( ) callback, without having to use a map of namespace associations. That's absolutely true, and would serve the example code well. However, most applications have hundreds and even thousands of lines of code in these callbacks (or, better yet, in methods invoked from code within these callbacks). In those cases, relying on parsing of the element's Q name is not nearly as robust a solution as storing the data in a custom structure. In other words, splitting the Q name on a colon is great for simple applications, but isn't so wonderful for complex (and therefore more realistic) ones.
3.3.6. Element Data
Once the beginning and end of an element block are identified and the element's attributes are enumerated for an application, the next piece of important information is the actual data contained within the element itself. This generally consists of additional elements, textual data, or a combination of the two. When other elements appear, the callbacks for those elements are initiated, and a type of pseudo-recursion happens: elements nested within elements result in callbacks "nested" within callbacks. At some point, though, textual data will be encountered. Typically the most important information to an XML client, this data is usually either what is shown to the client or what is processed to generate a client response.
In XML, textual data within elements is sent to a wrapping application via the characters( ) callback. This method provides the wrapping application with an array of characters as well as a starting index and the length of the characters to read. Generating a String from this array and applying the data is a piece of cake:
public void characters(char[] ch, int start, int length)
throws SAXException {
String s = new String(ch, start, length);
DefaultMutableTreeNode data =
new DefaultMutableTreeNode("Character Data: '" + s + "'");
current.add(data);
}Seemingly a simple callback, this method often results in a significant amount of confusion because the SAX interface and standards do not strictly define how this callback must be used for lengthy pieces of character data. In other words, a parser may choose to return all contiguous character data in one invocation, or split this data up into multiple method invocations. For any given element, this method will be called not at all (if no character data is present within the element) or one or more times. Parsers implement this behavior differently, often using algorithms designed to increase parsing speed. Never count on having all the textual data for an element within one callback method; conversely, never assume that multiple callbacks would result from one element's contiguous character data.
As you write SAX event handlers, be sure to keep your mind in a hierarchical mode. In other words, you should not get in the habit of thinking that an element owns its data and child elements, but only that it serves as a parent. Also keep in mind that the parser is moving along, handling elements, attributes, and data as it comes across them. This can make for some surprising results. Consider the following XML document fragment:
<parent>This element has <child>embedded text</child> within it.</parent>
Forgetting that SAX parses sequentially, making callbacks as it sees elements and data, and forgetting that the XML is viewed as hierarchical, you might make the assumption that the output here would be something like Figure 3-2.
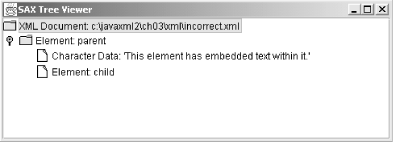
Figure 3-2. Expected, and incorrect, graphical tree
This seems logical, as the parent element completely "owns" the child element. But what actually occurs is that a callback is made at each SAX event-point, resulting in the tree shown in Figure 3-3.
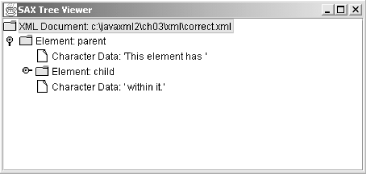
Figure 3-3. Actual generated tree
SAX does not read ahead, so the result is exactly what you would expect if you viewed the XML document as sequential data, without all the human assumptions that we tend to make. This is an important point to remember.
WARNING: Currently, neither Apache Xerces nor just about any other parser available performs validation by default. In the example program, since nothing has been done to turn it on, no validation occurs. However, that does not mean that a DTD or schema is not processed, again in almost all cases. Note that even without validation, an exception resulted when no system ID could be found, and the DTD reference could not be resolved (in the section on InputSources). So be sure to realize the difference between validation occurring, and DTD or schema processing occurring. Triggering of ignorableWhitespace( ) only requires that DTD or schema processing occurs, not that validation occurs.
Finally, whitespace is often reported by the characters( ) method. This introduces additional confusion, as another SAX callback, ignorableWhitespace( ), also reports whitespace. Unfortunately, a lot of books (including, I'm embarrassed to admit, my first edition of Java and XML) got the details of whitespace either partially or completely wrong. So, let me take this opportunity to set the record straight. First, if no DTD or XML Schema is referenced, the ignorable-Whitespace( ) method should never be invoked. Period.
The reason is that a DTD (or schema) details the content model for an element. In other words, in the JavaXML.dtd file, the contents element can only have chapter elements within it. Any whitespace between the start of the contents element and the start of a chapter element is (by logic) ignorable. It doesn't mean anything, because the DTD says not to expect any character data (whitespace or otherwise). The same thing applies for whitespace between the end of a chapter element and the start of another chapter element, or between it and the end of the contents element. Because the constraints (in DTD or schema form) specify that no character data is allowed, this whitespace cannot be meaningful. However, without a constraint specifying that information to a parser, that whitespace cannot be interpreted as meaningless. So by removing the reference to a DTD, these various whitespaces would trigger the characters( ) callback, where previously they triggered the ignorableWhitespace( ) callback. Thus whitespace is never simply ignorable, or nonignorable; it all depends on what (if any) constraints are referenced. Change the constraints, and you might change the meaning of the whitespace.
Let's dive even deeper. In the case where an element can only have other elements within it, things are reasonably clear. Whitespace in between elements is ignorable. However, consider a mixed content model:
<!ELEMENT p (b* | i* | a* | #PCDATA)>
If this looks like gibberish, think of HTML; it represents (in part) the constraints for the p element, or paragraph tag. Of course, text within this tag can exist, and also bold (b), italics (i), and links (a) elements as well. In this model, there is no whitespace between the starting and ending p tags that will ever be reported as ignorable (with or without a DTD or schema reference). That's because it's impossible to distinguish between whitespace used for readability and whitespace that is supposed to be in the document. For example:
<p>
<i>Java and XML</i>, 2nd edition, is now available at bookstores, as
well as through O'Reilly at
<a outsideurl=">http://www.oreilly.com</a>.
</p>In this XHTML fragment, the whitespace between the opening p element and the opening i element is not ignorable, and therefore reported through the characters( ) callback. If you aren't completely confused (and I don't think you are), be prepared to closely monitor both of the character-related callbacks. That will make explaining the last SAX callback related to this issue a snap.
3.3.7. Ignorable Whitespace
With all that whitespace discussion done, adding an implementation for the ignorableWhitespace( ) method is a piece of cake. Since the whitespace reported is ignorable, the code does just that -- ignore it:
public void ignorableWhitespace(char[] ch, int start, int length)
throws SAXException {
// This is ignorable, so don't display it
}Whitespace is reported in the same manner as character data; it can be reported with one callback, or a SAX parser may break up the whitespace and report it over several method invocations. In either case, adhere closely to the precautions about not making assumptions or counting on whitespace as textual data in order to avoid troublesome bugs in your applications.
3.3.8. Entities
As you recall, there is only one entity reference in the contents.xml document, OReillyCopyright. When parsed and resolved, this results in another file being loaded, either from the local filesystem or some other URI. However, validation is not turned on in the reader implementation being used.[4] An often overlooked facet of nonvalidating parsers is that they are not required to resolve entity references, and instead may skip them. This has caused some headaches before, as parser results may simply not include entity references that were expected to be included. SAX 2.0 nicely accounts for this with a callback that is issued when an entity is skipped by a nonvalidating parser. The callback gives the name of the entity, which can be included in the viewer's output:
[4]I'm assuming that even if you aren't using Apache Xerces, your parser does not leave validation on by default. If you get different results than shown in this chapter, consult your documentation and see if validation is on. If it is, sneak a peek at Chapter 4, "Advanced SAX " and see how to turn it off.
public void skippedEntity(String name) throws SAXException {
DefaultMutableTreeNode skipped =
new DefaultMutableTreeNode("Skipped Entity: '" + name + "'");
current.add(skipped);
}Before you go looking for the OReillyCopyright node, though, you should be aware that most established parsers will not skip entities, even if they are not validating. Apache Xerces, for example, never invokes this callback; instead, the entity reference is expanded and the result included in the data available after parsing. In other words, it's there for parsers to use, but you will be hard-pressed to find a case where it crops up! If you do have a parser that exhibits this behavior, note that the parameter passed to the callback does not include the leading ampersand and trailing semicolon in the entity reference. For &OReillyCopyright;, only the name of the entity reference, OReillyCopyright, is passed to skippedEntity( ).
3.3.9. The Results
Finally, you need to register the content handler implementation with the XMLReader you've instantiated. This is done with setContentHandler( ). Add the following lines to the buildTree( ) method:
public void buildTree(DefaultTreeModel treeModel,
DefaultMutableTreeNode base, String xmlURI)
throws IOException, SAXException {
// Create instances needed for parsing
XMLReader reader =
XMLReaderFactory.createXMLReader(vendorParserClass);
ContentHandler jTreeContentHandler =
new JTreeContentHandler(treeModel, base);
// Register content handler
reader.setContentHandler(jTreeContentHandler);
// Register error handler
// Parse
InputSource inputSource =
new InputSource(xmlURI);
reader.parse(inputSource);
}If you have entered all of these document callbacks, you should be able to compile the SAXTreeViewer source file. Once done, you may run the SAX viewer demonstration on the XML sample file created earlier. Also, make sure that you have added your working directory to the classpath. The complete Java command should read:
C:\javaxml2\build>java javaxml2.SAXTreeViewer ..\ch03\xml\contents.xml
This should result in a Swing window firing up, loaded with the XML document's content. If you experience a slight pause in startup, you are probably waiting on your machine to connect to the Internet and resolve the OReillyCopyright entity reference. If you aren't online, refer to Chapter 2, "Nuts and Bolts" for instructions on replacing the reference in the DTD with a local copyright file. In any case, your output should look similar to Figure 3-4, depending on what nodes you have expanded.
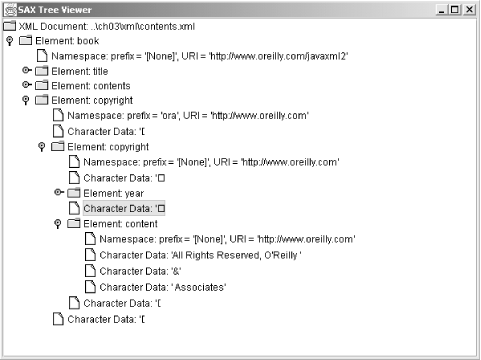
Figure 3-4. SAXTreeViewer in action
A couple of things to notice: first, the surrounding whitespace of elements is not present, since the presence of a DTD and strict content model forces that whitespace to be ignored (as it is reported to the ignorableWhitespace( ) callback). Second, the entity reference is resolved, and you see the contents of the copyright.xml file nested within the larger tree structure. Also, because this file has no DTD, whitespace that might be considered ignorable is reported as character data through the characters( ) callback. That results in the odd little control characters in the tree's text value (these are most often carriage returns in the underlying document). Finally, notice how the text "O'Reilly & Associates" within copyright.xml is actually reported through three invocations of the characters( ) callback. This is a perfect illustration of textual data not being reported as one block of text. In this case, the parser split the text on the entity reference (&), which is a common behavior. In any case, you should try running the viewer on different XML documents and see how the output changes.
You have now seen how a SAX-compliant parser handles a well-formed XML document. You should also be getting an understanding of the document callbacks that occur within the parsing process and of how an application can use these callbacks to get information about an XML document as it is parsed. In the next chapter, I will look at validating an XML document by using additional SAX classes designed for handling DTDs. Before moving on, though, I want to address the issue of what happens when your XML document is not valid, and the errors that can result from this condition.
|  | |
| 3.2. SAX Readers |  | 3.4. Error Handlers |

Copyright © 2002 O'Reilly & Associates. All rights reserved.