
 |  |
B.2. Hypertext Transfer Protocol
As discussed in Chapter 1, HTTP is the standard that allows documents to be communicated and shared over the Web. From a network perspective, HTTP is an application-layer protocol that is built on top of TCP/IP. Using our courier analogy from the previous section, HTTP is a kind of cover letter—like a fax cover sheet—that is stored in the envelope and tells the receiver what language the document is in, instructions on how to read the letter, and how to reply.
Since the original version, HTTP/0.9, there have only been two revisions of the HTTP standard. HTTP/1.0 was released as RFC-1945[13] in May 1996 and HTTP/1.1 as RFC-2616 in June 1999.
[13]Request for Comments, or RFCs, are submitted to the RFC editor (http://www.rfc-editor.org) usually by authors attached to organizations such as the Internet Engineering Task Force (IETF at http://www.ietf.org). RFCs date back to the early ARPAnet days and are used to present networking protocols, procedures, programs, and concepts. They also include meeting notes, opinions, bad poems, and other humor: RFC-2324 describes the Hypertext Coffee Pot Control Protocol.
B.2.1. Request and Response Model
HTTP is simple: a client—most conspicuously a web browser—sends a request for some resource to a HTTP server, and the server sends back a response. The HTTP response carries the resource—the HTML document or image or whatever—as its payload back to the client. This simple request-response model is shown in Figure B-2.
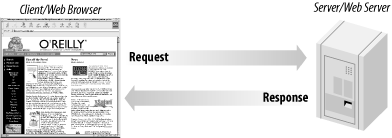
Figure B-2. Browser makes a request and the HTTP server responds
The term HTTP server is the correct description for what is more commonly called a web server. Technically, a web browser is an example of a user agent. Other user agents include proxy servers, applications that can provide services such as caching of responses, and access control.
B.2.1.1. Simulating an HTTP request
A good way to understand the mechanics of HTTP is to simulate a request and observe the response using the program telnet. From a command prompt, the telnet program is run with the domain name component of the URL and the port number 80. This instructs the telnet program to connect to the host machine on port 80, the port that the web server usually listens on. Then an HTTP request is sent by typing in a request line followed by a blank line (pressing the Enter key twice).
Example B-1 shows the request line:
HEAD / HTTP/1.0
followed by the server response. The HEAD keyword asks the server to respond with only the HTTP response header fields and not the whole requested document, which is useful if the requested page is large, or the request is for an image. The HEAD keyword is followed by the resource component of the URL and the version of HTTP that the client supports. To see a full response, the request line:
GET / HTTP/1.1
is entered followed by a blank line.
Example B-1. A simulated HTTP request using telnet
% telnet www.w3.org 80 Trying 18.29.1.35... Connected to www.w3.org. Escape character is '^]'. HEAD / HTTP/1.1 HTTP/1.1 200 OK Date: Wed, 26 Sep 2001 03:42:32 GMT Server: Apache/1.3.6 (Unix) PHP/3.0.11 P3P: policyref="http://www.w3.org/2001/05/P3P/p3p.xml" Cache-Control: max-age=600 Expires: Wed, 26 Sep 2001 03:52:32 GMT Last-Modified: Tue, 25 Sep 2001 21:08:00 GMT ETag: "5b42a7-4b06-3bb0f230" Accept-Ranges: bytes Content-Length: 19206 Connection: close Content-Type: text/html; charset=us-ascii Connection closed by foreign host. %
B.2.2. Uniform Resource Locators
Uniform resource locators—more commonly known as URLs—are used as the primary naming and addressing method of the Web. URLs belong to the larger class of uniform resource identifiers; both identify resources, but URLs include specific host details that allow connection to a server that holds the resource.
A URL can be broken into three basic parts: the protocol identifier; the host and service identifier; and a resource identifier, a path with optional parameters and an optional query that identifies the resource. The following example shows a URL that identifies an HTTP resource:
http://host_domain_name:8080/absolute_path?query
The HTTP standard doesn't place any limit on the length of a URL, however, some older browsers and proxy servers do. The structure of a URL is formally described by RFC-2396: Uniform Resource Identifiers (URI): Generic Syntax.
B.2.2.1. Protocol
The first part of the URL identifies the application protocol. HTTP URLs start with the familiar http://. Other applications that use URLs to locate resources identify different protocols; for example, URLs used with the File Transfer Protocol (FTP) begin with ftp://. URLs that identify HTTP resources served over connections that are encrypted using the Secure Sockets Layer start with https://. We discussed the use of the Secure Sockets Layer to protect data transmitted over the Internet in Chapter 9.
B.2.2.2. Host and service identification
The next part of the HTTP URL identifies the host on which the web server is running, and the port on which the server listens for HTTP requests. The domain name or the IP address can identify the host component. Using the domain name allows user-friendly web addresses such as:
http://www.w3.org/Protocols/
The equivalent URL using the IP address is more difficult to remember:
http://18.29.1.35/Protocols/
B.2.2.3. Nonstandard TCP ports
By convention, servers running well-known Internet applications use standard, well-known TCP port numbers. By default, a HTTP server listens for requests on port 80, an FTP server listens on port 21, and so on. The port number can be omitted from a URL if the well-known port is used. Clients—such as web browsers—determine which well-known port to connect to by the protocol indicated in the URL. For example, requests for the URL http://www.ora.com are made to the host machine www.ora.com on port 80. When a nonstandard port is used, the URL must include the port number so the browser can successfully connect to the service. For example, the URL http://www.example.com:8080 connects to the web server running on port 8080 on the host www.example.com.
B.2.2.4. Resource identification
The remaining URL components help locate a specific resource. The path, with optional parameters, and an optional query are processed by the web server to locate or compute a response. The path often corresponds to an actual file path on the host's filesystem. For example, an Apache web server running on www.example.com may store all the web content under the directory /usr/local/apache/htdocs and be configured to use the path component of the URL relative to that directory. The HTTP response to the URL http://www.example.com/marketing/home.php contains the file /usr/local/apache/htdocs/marketing/home.php.
B.2.2.5. Parameters and queries
The path component of a URL can include parameters and queries that are used by the web server. A common example is to include a query as part of the URL that runs a search script. The following example shows the string q=red as a query that the script search.php can use:
http://example.com/search.php?q=red
Multiple query terms can be encoded using the & character as a separator:
http://example.com/search.php?q=red&r=victoria
Parameters allow other information not related to a query to be encoded. For example, consider the parameter lines=10 in the URL:
http://example.com/search.php;lines=10?q=red
This can be used by the search.php script to modify the number of lines to display in a result screen.
While HTTP provides the distinction between parameters and queries, parameters are more complex than what we have described here and are not commonly used in practice. We discussed how PHP can use query variables encoded into URLs in Chapter 5.
B.2.2.6. Fragment identifiers
A URL can include a fragment identifier that is interpreted by the client once a requested resource has been received. A fragment identifier is included at the end of a URL separated from the path by the # character. The meaning of the fragment identifier depends on the type of the resource. For example, the following URL includes the fragment identifier tannin for a HTML document:
http://example.com/documents/glossary.html#tannin
When a web browser receives the HTML resource, it then positions the rendered document in the display to start at the anchor element <a name="tannin"> if the named anchor exists.
B.2.2.7. Absolute and relative URLs
The URI general syntax allows a resource to be specified as an absoluteor a relative URL. Absolute URLs identify the protocol http://, the host, and the path of the resource, and can be used alone to locate a resource. Here's an example absolute URL:
http://example.com/documents/glossary.html
Relative URLs don't contain all the components and are always considered with respect to a base URL. A relative URL is resolved to an absolute URL, with respect to the base URL. Typically, a relative URL contains the path components of a resource and allows related sets of resources to reference each other in a relative way. This allows path hierarchies to be readily changed without the need to change every URL embedded in a set of documents.
A web browser has two ways to set base URLs when resolving relative URLs. The first method allows a base URL to be encoded into the HTML using the <base> element. The second method sets the base URL to that of the current document; this is the default. For example, the following HTML document contains three relative URLs embedded into <a> elements:
<html>
<body>
<h2>My Home Page</h2>
<p>Read my <a href="cv.html">Curriculum Vitae</a>
<p>Read my
<a href="work/emp.html">employment history</a>
<p>Visit
<a href="/admin/fred.html">Fred's home page</a>
</body>
</html>Consider what happens if the example is requested with the following URL:
http://example.com/development/dave/home.html
The three relative URLs are resolved to the following absolute URLs by the browser:
http://example.com/development/dave/cv.html http://example.com/development/dave/work/emp.html http://example.com/admin/fred.html
Table B-1 shows several relative URLs and how they are resolved to the corresponding absolute URLs given the base URL http://example.com/a/b/c.html?foo=bar.
Table B-1. Example relative URLs resolved to absolute URLs
|
Relative URL |
Absolute URL with respect to http://example.com/a/b/c.html?foo=bar |
|---|---|
|
d.html |
http://example.com/a/b/d.html |
|
e/d.html |
http://example.com/a/b/e/d.html |
|
/d.html |
http://example.com/d.html |
|
../d.html |
http://example.com/a/d.html |
|
#xyz |
http://example.com/a/b/c.html?foo=bar#xyz |
|
./ |
http://example.com/a/b/ |
|
../ |
http://example.com/a/ |
B.2.2.8. URL encoding
The characters used in resource names, query strings, and parameters must not conflict with the characters that have special meanings or can't allowed in a URL. For example, a question mark character identifies the beginning of a query, and an ampersand (&) character separates multiple terms in a query. The meanings of these characters can be escaped using a hexadecimal encoding consisting of the percent character (%) followed by the two hexadecimal digits representing the ASCII encoded of the character. For example, an ampersand (&) character is encoded as %26.
The characters that need to be escape-encoded are the control, space, and reserved characters:
; / ? : @ & = + $ ,
Delimiter characters must also be encoded:
< > # % "
The following characters can cause problems with gateways and network agents, and should also be encoded:
{} | \ ^ [ ] `PHP provides the rawurlencode( ) function to protect them. For example, rawurlencode( ) can build the href attribute of an embedded link:
echo '<a href="search.php?q=' .
rawurlencode("100% + more") .
'">';The result is an <a> element with an embedded URL correctly encoded:
<a href="search.php?q=100%25%20%2B%20more">
PHP also provides the urlencode( ) function that differs from the rawurlencode( ) function in that the former encodes spaces as a + sign whereas the latter encodes spaces as %20. The use of the + character to encode a space was an early HTTP way to encode spaces.
B.2.3. HTTP Requests
The model used for HTTP requests is to apply methods to identified resources. A HTTP request message contains a method name, a URL to which the method is to be applied, and header fields. Some requests can include a body -- for example, the data collected in a <form>—that is referred to in the HTTP standard as the entity-body.
Example B-2 shows the request message sent from a Netscape browser applying the GET method to the grapes.gif resource. The action is to retrieve the image stored in the file grapes.gif.
Example B-2. An example HTTP request message
GET /grapes.gif HTTP/1.0 Accept: image/gif, image/jpeg, image/png, */*; Accept-Charset: iso-8859-1,*,utf-8; Accept-Encoding: gzip; Accept-Language: en; Connection: Keep-Alive; Host: www.webdatabasebook.com; User-Agent = Mozilla/4.51 [en] (WinNT; I);
The first line of the message is the request-line and contains the method name GET, the request URL /grapes.gif, and the HTTP version HTTP/1.0, each separated by a space character. The request-line is followed by a list of header fields. Each field is represented as a name and value pair separated with a colon character, and lines are separated with semicolons.
The header fields are followed by a blank line and then by the optional body of the message. The POST method request usually contains a body of text, as we discuss in the next section.
B.2.3.1. Request methods
There are six request methods, but only three are used in practice:
- GET
- Retrieves a resource. A query can be used to add extra information to the GET request and, as we discussed in our introduction to URLs, these are appended to the URL itself. A database search is a good example of an application of the GET request: the resource is likely to be a web script, and the query component of the URL is the search conditions.
- POST
- Sends data to a server. Rather than appending data to the URL, the data is sent in the body of the HTTP request.
- HEAD
- Returns only the header fields in a response, not the resource itself. This can be used for lightweight retrieval, so that the modification date of a resource can be checked before the full resource is retrieved with GET.
- DELETE
- Allows a resource identified by the URL to be deleted from a server. This is the counterpart to the PUT method and allows an author to remove a resource from the specified URL. Usually not implemented.
- PUT
- Similar to the POST method, this method is designed to put a resource onto a server that can be later retrieved with the URL in the PUT request. Some HTML editors and web servers support the PUT methods allowing authors to put resources onto a web site at the specified URL. Usually not implemented.
- TRACE
- Produces diagnostic information.
The HTTP standard divides these methods into those that are safe and those that aren't. The safe methods—GET and HEAD—don't have any persistent side effects on the server. The unsafe methods—POST, PUT, and DELETE—by their nature are designed to have persistent effects on the server. The standard allows for clients to warn users that a request may be unsafe, and a browser should not resend a request with the POST method without user confirmation.
The HTTP standard further classifies methods as idempotent when a request can be repeated many times and have the same effect as if the method was called once. The GET, HEAD, PUT, and DELETE methods are classified as idempotent; the POST method isn't.
B.2.3.2. GET versus POST
Both the GET and POST methods send data to the server, but which method should you use?
The HTTP standard includes the two methods to achieve different goals. The POST method was intended to create a resource. The contents of the resource would be encoded into the body of the HTTP request. For example, an order <form> might be processed and a new row in a database created.
The GET method is used when a request has no side effects such as performing a search, and the POST method is used when a request has side effects such as adding a new row to a database. A more practical issue is that the GET method may result in long URLs, and may even exceed some browser and server limits on URL length.
Use the POST method if any of the following are true:
-
The result of the request has persistent side effects such as adding a new database row.
-
If the data collected on the form is likely to result in a large URL if implemented using the GET method.
-
The data to be sent is in any encoding other than seven-bit ASCII.
Use the GET method if all the following are true:
B.2.4. HTTP Responses
When a web server processes a request from a browser, it attempts to apply the method to the identified resource and create a response. The action of the request may succeed, or it may fail for a variety of reasons, but the web server always sends a response message back to the browser.
A HTTP response message contains a status line, header fields, and the requested entity as the body of the message. The body of the response is usually the resource requested in the request message. Example B-3 shows the result of a GET method on a small HTML file.
Example B-3. An example HTTP response message
HTTP/1.1 200 OK Date: Tue, 24 Oct 2001 02:54:37 GMT Server: Apache/1.3.19 Last-Modified: Tue, 24 Oct 2001 02:53:08 GMT ETag: "4445f-bf-39f4f994" Content-Length: 321 Accept-Ranges: bytes Connection: close Content-Type: text/html <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd" > <html> <head><title>Grapes and Glass</title></head> <body> <img src="http://example.com/grapes.gif"> <p>Welcome to my simple page <p><img src="http://example.com/glass.gif"> </body> </html>
The status line—the first line of the message—starts with the protocol version of the message, followed by a status code and a reason phrase, each separated by a space character. The status line is followed by the header fields. As with the request, each field is represented as a name and value pair separated with a colon character. A blank line separates the header fields and the body of the response.
B.2.4.1. Status codes
HTTP status codes are used to classify responses to requests. The HTTP status code system is extensible, with a set of codes described in the standard that are "generally recognized in current practice." HTTP defines a status code as a three-digit number; the first digit is the class of response. The following list shows the five classes of codes defined by HTTP:
- 1xx
- Informational. HTTP 1.0 reserves this class of code for future use. HTTP 1.1 uses codes in this class to indicate the request has been received by the server and that processing is continuing.
- 2xx
- Success. The request was successfully received, and the action successfully performed.
- 3xx
- Redirection. When a response has a redirection code, the client needs to make a further request to actually get the specified resource. The URL of the actual resource is included in the response header field Location. When the status code is set to 301, the browser automatically makes the request for the URL specified in the Location header field. The use of the Location header field is discussed further in Chapter 5, and used in many examples throughout this book.
- 4xx
- Client error. The request can't be processed due to bad syntax of the message, the sender is unauthorized or forbidden to access the resource, or the resource can't be found.
- 5xx
- Server error. The server failed to fulfill an apparently valid request.
The actual code used for a particular response is largely determined by the configuration of the web server, and not by a scripting environment that might create a web application. Some scripting environments allow the web developer to explicitly set these codes. For example, a script associated with a URL might simply set the response code to 501 to indicate the requested function hasn't been implemented.
B.2.5. Caching
Most user agents, such as web browsers, allow HTTP responses to be cached, which can significantly reduce the number of requests sent to a web server and thus improve the performance of a web application. HTTP responses are cached by saving a response to a request in memory. When a browser considers a request, it first looks to its local cache to see if it has an up-to-date copy of the response before sending the request to the web server. Consider a web site that includes a company logo on the top of each page in an image element such as:
<img src="/images/logo.gif">
When the browser requests a page that contains the image, a separate request is sent to retrieve the image /images/logo.gif. If the image resource is cacheable, and browser caching is enabled, the browser saves the response in a cache. A subsequent request for the image is recognized, and the local copy from the cache is used rather than sending the request for the resource to a web server.
A browser uses a cached response until the response becomes stale, or the cache becomes full and the response is displaced by the resources from other requests. The primary mechanism for determining if a response is stale is comparing the date and time set in the Expires header field with the date and time of the host running the user agent. If the date and time are incorrectly set on the user agent's host, a cached response may expire immediately or be cached longer than expected. HTTP/1.1 is more sophisticated than HTTP/1.0 in controlling the life of a cached response using other parameters not discussed here.
Not all responses are cacheable. HTTP describes the conditions that allow a user agent to cache a response in some detail; essentially most responses are cacheable unless a cache-control header directs otherwise. There are many situations in which an application may wish to prevent a page from being cached, particularly when the content of a response is dynamically generated, such as in a web database application.
B.2.5.1. HTTP/1.0 cache control
HTTP/1.0 uses the Pragma header set to the value no-cache to prevent caching. Some old user agents don't support the use of the Pragma header to control the caching of a response. The only way to prevent caching of a page with these older user agents is to set the Expires header field to 0, which instructs many user agents to immediately expire the response or change it to a past date and time. This practice is recognized, but not formally supported by the HTTP standard.
B.2.5.2. HTTP/1.1 cache control
HTTP/1.1 uses the Cache-Control header field as its basic caching control mechanism. The Cache-Control header can be used in both HTTP requests and responses, however, we consider only HTTP responses here. Setting the Cache-Control header field to no-cache in a HTTP response prevents the response from being cached by a HTTP/1.1 user agent.
Some HTTP/1.1 Cache-Control settings are directed to user agents that maintain caches for more that one user, such as a proxy server. Proxy servers are used to achieve several goals; one is to provide caching of responses for a group of users. A local network, such as that found in a university department, can be configured to send all HTTP requests to a proxy server. The proxy server forwards requests to the destination web server and passes back the responses to the originating client. Proxy servers can cache responses and thus reduce requests sent outside the local network. Setting the Cache-Control header field to public allows a user agent to make the cached response available to any request. Setting the Cache-Control header field to private allows a user agent to make the cached response available only to the client who made the initial request.
Setting the Cache-Control header to no-store prevents a user agent from storing the response in nonvolatile storage, such as a hard disk. This prevents sensitive information from being inadvertently saved beyond the life of a browser session. HTTP/1.1 defines several other Cache-Control header fields not described here.
The HTTP/1.1 standard is relatively new, and there are several user agents that aren't HTTP/1.1-aware or -compliant. While HTTP/1.1 provides better cache control directives, it is wise to include header fields that are understood by HTTP/1.0 browsers, proxy servers, and other user agents.
B.2.6. HTTP and TCP/IP
Each time a HTTP request is sent, a TCP/IP connection is made. When a browser makes a request, the following network activity results:
-
The browser initiates a TCP/IP connection to the web server on the host and port identified in the URL of the request.
-
The host sends back a TCP acknowledgment to indicate a virtual circuit has successfully been established.
-
The browser sends the HTTP request in full to the server using the established connection.
-
The server acknowledges the receipt of the request and starts to generate a response. The browser waits for the response and times out if the response doesn't arrive within a preset time limit.
-
The server sends the HTTP response message to the browser.
-
The browser acknowledges the receipt of the complete HTTP response.
-
The server disconnects the virtual circuit.
Each HTTP request-response sequence is a completely separate network connection: each request message sent by a web browser—or any other HTTP user agent—is totally independent of any other request. Every request message a web server receives has its own separate response. This independence of requests is what makes the HTTP protocol stateless.
B.2.6.1. Simultaneous request model
The stateless nature of the HTTP protocol allows applications that use HTTP to scale well and also allows for some performance optimizations. Because the protocol is stateless, one such optimization is that a web browser can make multiple HTTP requests in parallel. Consider the HTML document shown in Example B-4 that encodes references to two images.
Example B-4. The HTML document http://example.com/wine.html
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd" > <html> <head><title>Grapes and Glass</title></head> <body> <img src="http://example.com/grapes.gif"> <p>Welcome to my simple page <p><img src="http://example.com/glass.gif"> </body> </html>
After requesting the HTML document and processing it, the browser makes two additional requests for the resources grapes.gif and glass.gif. In all, three separate HTTP requests must be made to display the page. However, the browser can make the two requests for the images simultaneously. The browser isn't concerned about the order in which the images are retrieved and, because each request is independent, TCP/IP can't guarantee that the requests are responded to in any particular order.
Sending requests in parallel allows a browser to maximize the use of available network bandwidth. However, a browser can make only a limited number of parallel requests with improvements to performance and, typically, a limit of four simultaneous requests provides the best results. The ability to send requests simultaneously allows a web browser to use more network capacity relative to other applications. An application such as FTP communicates through one TCP connection and therefore has access to less bandwidth when a web browser makes four TCP connections in parallel.
At the server end, simultaneous requests can be treated independently and may not even be processed by the same web server. A common way to handle high volumes of requests is to use specialized network hardware to balance connections across multiple web servers running on different machines. The stateless nature of HTTP allows for such configurations. We discussed the issues of session management and the stateless nature of HTTP in Chapter 8.
B.2.6.2. Persistent connections
Web pages that consist of text alone are retrieved from a web server with one HTTP request. However, many web pages contain images and other objects that require additional HTTP requests; some corporate home pages contain more that 60 images, each requiring a separate HTTP request. The page shown in Example B-4 requires three requests: the first to get the page and then two more to get the images. While the browser is usually configured to make up to four parallel requests, with HTTP/1.0, each request must open a separate TCP connection to the server. This is expensive as each request adds to the cost of the TCP dialog required to open the virtual connection.
As a result, browsers and web servers often support a keep-alive capability to reduce the time taken to load web pages that contain images. This feature allows multiple requests to be made in succession using the one TCP connection. After a specified idle period, the connection is assumed to be no longer required and is closed by the server. HTTP/1.1 uses persistent TCP connections as the default behavior. Persistent connections not only improve the performance of the browser but reduce the load on a HTTP server and on the network, because fewer TCP connections need to be established.
In the same way as the simultaneous request model, a browser can send multiple requests on a persistent connection without waiting for each response. This behavior is called pipelining.
B.2.7. MIME
Originally, web pages were solely HTML documents encoding text and hypertext links to other pages. The first version of HTTP, HTTP/0.9, was not much more than a way to wrap HTML documents. However, web pages today are made up of a variety of resources including images, Java applets, sounds, movies, and the HTML that glues them all together.
To allow the transfer of other resources, HTTP/1.0 has borrowed the concepts of Multipurpose Internet Mail Extensions (MIME) as a way to encode objects. As the name suggests, MIME attaches content with encoding other that plain text to electronic mail. HTTP's use of MIME is almost identical to its use in electronic mail.
MIME includes several header fields that describe the enclosed data and are included in the HTTP messages that contain a body. If the response message is carrying a HTML file, the Content-Type field is set to text/html. Web browsers examine the media type in the Content-Type field to help decide how to render the body of a response. They can also be configured to use particular helper applications for those media types that can't be directly displayed. The Content-Length field is also set to the number of bytes that make up the original content.
MIME uses media types to describe content. Media types are divided into a content-type and subtype pairs. The MIME standard defines seven content-types and several basic subtypes. The subtypes can be extended to specifically define different media. A list of well-known subtypes for each content-type is maintained by the Internet Assigned Number Authority (IANA) and can be found at http://www.isi.edu/in-notes/iana/assignments/media-types/.
Media types are also used to describe browser and server capabilities, and preferences. The Accept request header field informs the web server of browser capabilities and preferences. This field carries a list of types in preference order and can include weighting factors.
|  | |
| B. Internet and Web Protocols |  | C. Modeling and Designing Relational Databases |

Copyright © 2003 O'Reilly & Associates. All rights reserved.