
 |  |
Chapter 1. Database Applications and the Web
With the growth of the Web over the past decade, there has been a similar growth in services that are accessible over the Web. Many new services are web sites that are driven from data stored in databases. Examples of web database applications include news services that provide access to large data repositories, e-commerce applications such as online stores, and business-to-business (B2B) support products.
Database applications have been around for over 30 years, and many have been deployed using network technology long before the Web existed. The point-of-service systems used by bank tellers are obvious examples of early networked database applications. Terminals are installed in bank branches, and access to the bank's central database application is provided through a wide area network. These early applications were limited to organizations that could afford the specialized terminal equipment and, in some cases, to build and own the network infrastructure.
The Web provides cheap, ubiquitous networking. It has an existing user base with standardized web browser software that runs on a variety of ordinary computers. For developers, web server software is freely available that can respond to requests for both documents and programs. Several scripting languages have been adapted or designed to develop programs to use with web servers and web protocols.
This book is about bringing together the Web and databases. Most web database applications do this through three layers of application logic. At the base is a database management system (DBMS) and a database. At the top is the client web browser used as an interface to the application. Between the two lies most of the application logic, usually developed with a web server-side scripting language that can interact with the DBMS, and can decode and produce HTML used for presentation in the client web browser.
We begin by discussing the three-tier architecture model used in many web database applications. We then introduce the nature of the Web and its underlying protocols and then discuss each of the three tiers and their components in detail. Hugh and Dave's Online Wines, our case study application, is introduced at the end of this chapter. We refer to it frequently throughout the course of the book and use it as a model to illustrate the construction of a web database application.
1.1. Three-Tier Architectures
This book describes web database applications built around a three-tier architecture model, shown in Figure 1-1. At the base of an application is the database tier, consisting of the database management system that manages the database containing the data users create, delete, modify, and query. Built on top of the database tier is the complex middle tier, which contains most of the application logic and communicates data between the other tiers. On top is the client tier, usually web browser software that interacts with the application.
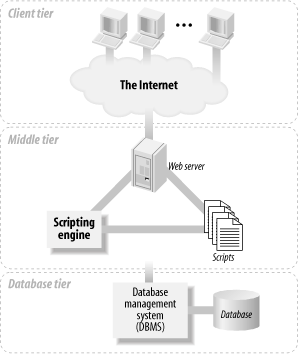
Figure 1-1. The three-tier architecture model of a web database application
The formality of describing most web database applications as three-tier architectures hides the reality that the applications must bring together different protocols and software. The majority of the material in this book discusses the middle tier and the application logic that brings together the fundamentally different client and database tiers.
When we use the term "the Web," we mean three major, distinct standards and the tools based on these standards: the Hypertext Markup Language (HTML), the Hypertext Transfer Protocol (HTTP), and the TCP/IP networking protocol suite. HTML works well for structuring and presenting information using a web browser application. TCP/IP is an effective networking protocol that transfers data between applications over the Internet and has little impact on web database application developers. The problem in building web database applications is interfacing traditional database applications to the Web using HTTP. This is where the complex application logic is needed.
1.1.1. Hypertext Transfer Protocol
The three-tier architecture provides a conceptual framework for web database applications. The Web itself provides the protocols and network that connect the client and middle tiers of the application; that is, it provides the connection between the web browser and the web server. HTTP is one component that binds together the three-tier architecture. A detailed knowledge of HTTP isn't necessary to understand the material in this book, but it's important to understand the problems HTTP presents for web database applications. The HTTP protocol is used by web browsers to request resources from web servers, and for web servers to return responses. (A longer introduction to the underlying web protocols—including more examples of HTTP requests and responses—can be found in Appendix B.)
HTTP allows resources to be communicated and shared over the Web. From a network perspective, HTTP is an applications-layer protocol that is built on top of the TCP/IP networking protocol suite. Most web servers and web browsers communicate using the current version, HTTP/1.1. Some browsers and servers use the previous version, HTTP/1.0, but most HTTP/1.1 software is backward-compatible with HTTP/1.0.
HTTP communications dominate Internet network traffic. In 1997, HTTP accounted for about 75% of all traffic.[1] We speculate that this percentage is now even higher due to the growth in the number and popularity of HTTP-based applications such as free email services.
[1]From K. Thompson, G. J. Miller, and R. Wilder. "Wide-area internet traffic patterns and characteristics," IEEE Network, 11(6):10-23, November/December 1997.
1.1.1.1. HTTP example
HTTP is conceptually simple: a client web browser sends a request for a resource to a web server, and the web server sends back a response. The HTTP response carries the resource—the HTML document, image, or output of a program—back to the web browser as its payload. This simple request-response model is shown in Figure 1-2.

Figure 1-2. A web browser makes a request and the web server responds with the resource
An HTTP request is a textual description of a resource and additional header information. Consider the following example request:
GET /index.html HTTP/1.0 From: hugh@computer.org (Hugh Williams) User-agent: Hugh-fake-browser/version-1.0 Accept: text/plain, text/html
This example uses a GET method to request an HTML page index.html with HTTP/1.0. In this example, three additional header lines identify the user and the web browser and define what data types can be accepted by the browser. A request is normally made by a web browser and may include other headers; the previous example was created manually by typing the request into Telnet software.
An HTTP response has a response code and message, additional headers, and usually the resource that has been requested. An example response to the request for index.html is as follows:
HTTP/1.0 200 OK Date: Sat, 21 Jul 2002 03:44:25 GMT Server: Apache/1.3.20 Content-type: text/html Content-length: 88 Last-modified: Fri, 1 Feb 2002 03:40:03 GMT <html><head> <title>Test Page</title></head> <body> <h1>It Worked!</h1> </body></html>
The first line of the response agrees to use HTTP/1.0 and confirms that the request succeeded by reporting the response code 200 and the message OK; another common response is 404 Not Found. In this example, five lines of additional headers identify the current date and time, the web server software, the data type, the length of the response, and when the resource was last modified. After a blank line, the resource itself follows. In this example the resource is the requested HTML document, index.html.
1.1.1.2. State
Traditional database applications are stateful. In traditional database applications, users log in, run related transactions, and then log out when they are finished. For example, in a bank application, a bank teller might log in, use the application through a series of menus as he serves customer requests, and log out when he's finished for the day. The bank application has state: once the teller is logged in, he can interact with the application in a structured way using menus. When the teller has logged out, he can no longer use the application.
HTTP is stateless. Statelessness means that any interaction between a web browser and a web server is independent of any other interaction. Each HTTP request from a web browser includes the same header information, such as the security credentials of the user, the types of pages the browser can accept, and instructions on how to format the response. Statelessness has benefits: the most significant are the resource savings from not having to maintain information at the web server to track a user, and the flexibility to allow users to move between unrelated pages or resources.
Because HTTP is stateless, it is difficult to develop stateful web database applications. What is needed is a method to maintain state in HTTP so that information flows and structure can be imposed. A common solution is to exchange a token between a web browser and a web server that uniquely identifies the user and her session. Each time a browser requests a resource, it presents the token, and each time the web server responds, it returns the token to the web browser. The token is used by the middle-tier software to restore information about a user from her previous request, such as which menu in the application she last accessed. Exchanging tokens allows stateful structure such as menus, steps, and workflow processes to be added to the application.
1.1.2. Thin Clients
Given that a web database application built with a three-tier architecture doesn't fit naturally with HTTP, why use that model at all? The answer mostly lies in the benefits of the thin client. Web browsers are very thin clients: little application logic is included in the client tier. The browser simply sends HTTP requests for resources and then displays the responses, which contain mostly HTML documents.
A three-tier model means you don't have to build, install, or configure the client tier. Any user who has a web browser can use the web database application, usually without needing to install additional software, be using a specific operating system, or own a particular hardware platform. This means an application can be delivered to any number of diverse, geographically dispersed users. The advantage is so significant that our focus in this book is entirely on three-tier solutions with this thin-client web browser architecture.
But what are the alternatives to a thin client? A custom-built Java applet is an example of a thicker client that can still fit the three-tier model: the user downloads an applet and runs more of the overall application logic on her platform. The applet still interacts with a middle tier that, in turn, provides an interface to the database tier. The advantage is customization: rather than using the generic browser solution, a custom solution can eliminate many problems inherent in the statelessness, security, and inflexibility of the Web. The applet might not even use HTTP to communicate with the middle-tier application logic.
A thick client is also part of a traditional two-tier solution, also known as a client/server architecture. Most traditional database applications—such as those in the bank—have only two tiers. The client tier has most of the overall application logic, and the server tier is the DBMS itself. The advantage is that a customized solution can be designed to meet the exact application requirements without any compromises. Disadvantages are the lack of hardware and operating system flexibility and the requirement to provide software to each user.
|  | |
| 0.8. Acknowledgments |  | 1.2. The Client Tier |

Copyright © 2003 O'Reilly & Associates. All rights reserved.