
 |  |
1.6. Document Object Model
When an HTML page loads into a scriptable browser, the browser creates a hidden, internal roadmap of all the elements it recognizes as scriptable objects. This roadmap is hierarchical in nature, with the most "global" object—the browser window or frame—containing a document, which, in turn, contains, say, a form, which, in turn, contains form elements. For a script to communicate with one of these objects, it must be able to reference the object in order to call one of the object's methods or set one of its property values. Document objects are the "things" that scripts work with.
Without question, the most difficult challenges facing scripters throughout the short history of scriptable browsers has been how each browser builds its internal roadmap of objects. This roadmap is called a document object model (DOM). When one browser implements an object as scriptable but the other doesn't, it drives scripters and page authors to distraction. Pioneering scripters felt the sting of this problem when they implemented image-swapping mouse rollovers in Navigator 3, only to discover that images were not scriptable objects in Internet Explorer 3. As a result, their IE 3 users were getting script errors when visiting the sites and moving their mice across the hot images. The situation only worsened when Microsoft developed its DOM for IE 4 in one direction, while Netscape took a different path for Navigator 4.
In an effort to standardize this area, a separate working group of the W3C is charged with setting recommendations for a Document Object Model (http://www.w3c.org/DOM/). The foundation for the W3C DOM is the Core DOM module, which defines fundamental building blocks (objects, properties, and methods) that apply to any document-oriented web content (whether pure XML or HTML and its descendants). The Core module includes definitions for basic objects, such as the document, an element, element text content, and an element's attributes. Beyond those generic building blocks of the Core, specialized modules define the objects that apply to particular kinds of documents or entities within documents. For example, the working group patterned an HTML module of the W3C DOM after the elements defined for the W3C HTML 4 specification. Every HTML 4 element is represented in the HTML DOM module as a DOM object. Thus, the HTML DOM includes objects for the p element, the form element, and so on down the line. HTML 4 element attributes, in turn, become properties of HTML DOM element objects. This is how a script can read the value assigned to an attribute in the source code and perhaps modify the value in response to user activity.
A primary goal of this effort is to create a recognized common denominator among browsers (or any document engine). By the time the first round of W3C DOM standards came into being, however, Netscape and Microsoft had already deployed two or more versions of their own rapidly diverging DOMs. With companies that held sometimes radically different philosophies participating in the W3C DOM process, finding a common ground was not easy.
The resulting recommendation, as best described in the modularized DOM Level 2, created a DOM that in many ways resembled none of the existing models. While the recommendation maintains backward compatibility with early object models (as implemented in Navigator 3 and IE 3), and it exposes all HTML elements as objects just as the IE 4 model does, the W3C DOM created an entirely new framework for pieces of a document. Perhaps the greatest impact on DOM coding practices at the time was in the way scripts reference elements.
1.6.1. DOM Level 0
The first object model, which the W3C specification calls DOM Level 0 (but in truth predates the W3C DOM), was restricted to only a handful of element objects. Inside a window, the document object is the master container of all content. After a document loaded into the browser, its content was largely static with the exception of forms and form controls (text fields, buttons, and select lists). References to element objects (plus a couple of abstract objects, such as location and history) entailed a hierarchical name, starting with the document object. To refer to a form control, the reference "walked" through an element hierarchy that matched the nested tag hierarchy in the document—at least to the extent that elements were recognized as objects. Thus, a reference to a form control included the document, the form, and the control itself:
document.formName.controlName
These models also treated multiple instances of elements as arrays of those elements. Using JavaScript array syntax, you could reference the element by way of numeric or named array indexes, as in:
document.forms[0].elements[0]
or:
document.forms["formName"].elements["controlName"]
or any combination of reference types:
document.forms[0].controlName
Given the initial purpose of scriptable browsers—primarily for client-side form validation and dynamic navigation—the limited object model was sufficient. Despite its limitations, DOM Level 0 from Navigator 2, Navigator 3, and IE 3 was intriguing enough to attract a wide audience hungry for more flexibility.
1.6.2. Microsoft IE 4 DOM
In advance of the W3C's DOM activity, Microsoft boosted the powers of IE 4 to allow scripts to modify any piece of a document's content after the page had loaded. The key to this feature was automatic reflow of the page to accommodate changes in an element's dimensions due to the scripted change.
With the luxury of being able to render any modified content, it was meaningful to expose all HTML elements as scriptable objects for the IE 4 DOM. What scripters needed, however, was a quick way to reference those elements without having to take the structure of the document into account. A property of the document object (or any other container object for that matter) flattened the hierarchy of nested elements so that as long as the script had the id of the desired element, the document.all array (collection) offered instant access to the element in multiple syntax approaches, such as:
document.all.elementID
document.all("elementID")
document.all["elementID"]In addition to this referencing syntax, the IE 4 DOM empowered all elements with properties and methods that facilitated the reading and writing of plain text and HTML content on the fly. You could, for example, insert some HTML inside an element by first assembling a string of HTML tags, attributes, and content, and then assigning that string to the innerHTML property of an existing element. The inserted content got rendered instantly, as the page reflowed to adjust for the inserted HTML. If the content contained no tags, you could assign the string to the element's innerText property.
The nested structure of HTML elements also played a role in the IE4 DOM. The notion of parent and child elements followed traditional paths. An element's container was its parent element; an element nested inside another was a child of the outer element. The element was king, and an element contained either just plain text or additional HTML elements.
1.6.3. W3C DOM Architecture
The W3C DOM working group based its architecture on an object type that is more granular than the element: the node. The concept behind this is that a document and its contents can be diagrammed, in a sense, as a hierarchy of items—nodes—of different types. Some nodes are containers (branches from which other nodes hang), while others are self-contained (leaves at the ends of branches).
The root node of a document is the document node—the master container of all content. In an HTML document, an item denoted in the source code by a tag is an element node. Text content between a matched start and end tag pair is a text node. Other types of nodes also occur in a document, such as attribute nodes, comment nodes, and document-type nodes. To visualize the basic node arrangement, consider the following HTML for a simple document:
<!DOCTYPE ... > <html> <head> </head> <body> <p>A simple paragraph.</p> </body> </html>
Figure 1-1 shows a diagrammed version of the node hierarchy of this document.
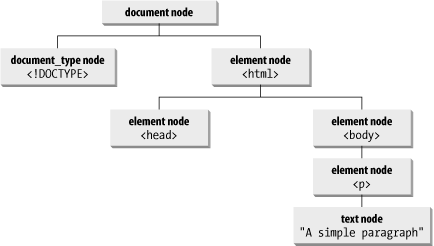
Figure 1-1. A simple document's node structure
The tree structure shown in Figure 1-1 lends itself to describing relationships among elements in parent-child terms. For example, the document node in the illustration has two child nodes, the DOCTYPE and html elements. These two child nodes are siblings to each other. The html element node is, itself, also a parent to the head and body nodes. (Note that some W3C DOM clients, such as Netscape 6, also treat line breaks in HTML source code as separate text nodes. Examples later in this book take this behavior into account.)
As you can see, the parent-child relationships are not conceptually different from the containment hierarchy that well-formed HTML documents exhibit. In fact, the IE 4 DOM, at least at the element level, treats relationships the same way. But when it comes to using the W3C DOM to reference elements and what you see in the source code as text content, the approach is different from any DOM that came before it.
In place of the IE 4 document.all collection, the W3C DOM implements a root document object method, document.getElementById( ), that dives through the entire document in search of an id attribute value matching the parameter of the method. For example, if a paragraph element's id attribute is myP, a script can reference the paragraph as follows:
document.getElementById("myP")The method returns a reference to the element, whose properties and methods may be invoked as needed. Unlike the IE 4 DOM, however, a W3C DOM element object has no direct knowledge of its child nodes, other than the fact that they exist. For example, the text content of a W3C DOM p element is not a property of the p element object. In other words, W3C DOM Level 2 provides no analog to the innerText or innerHTML properties of the IE 4 DOM. To read or modify the content of an element's content, your scripts must work with the child nodes of the element.
An element object has numerous properties and methods that provide scriptable access to information about its parent, child, and sibling nodes. These properties and methods become the primary gateways to reaching an element's nested nodes. In turn, every node has properties that reveal its type (via a constant value for each type) and value. If a child node is of the text node type, you can read or write the string value of that text node as a property of that text node. If the content consists of a mixture of text and other HTML elements, you must use other W3C DOM facilities to create and accumulate element and text nodes before inserting them into an existing element. In this model, element tags are not represented as string content of a document.
The rationale behind this seemingly complicated approach to accessing content is partly attributable to the need for the Core W3C DOM to work with both XML and HTML documents. Although the modularization of the W3C DOM offers an opportunity to add the IE DOM's innerText or innerHTML convenience properties to HTML element objects, this has not occurred in the HTML module for Level 2 (which remains unfinished as of this writing). Recognizing the significant scripting convenience of reading and writing an element's content as a string, however, the Mozilla engine (in Netscape 6 and later) implements the innerHTML property for all element objects. You can, of course, use the innerHTML property to put plain text into an element as well, so this one property handles all situations nicely.
An Object-Oriented Model
The parent-child relationship between nodes in a document depends solely on the nesting and source code order of the tags and related content. This kind of containment hierarchy, however, does not necessarily imply inheritance of properties from parent to child. If you assign a value to the id attribute or property of a table element, nested rows do not inherit the parent element's ID. The closest that inheritance touches HTML elements is in the style sheet area, where most style attributes are inherited by an element's child elements (but CSS inheritance is governed by rules that have nothing to do with object orientation).
The W3C DOM, however, is built upon an abstract model that looks very object oriented. The abstract model defines what constitutes a node, an element, and so on. All content-related objects are derived from the Node object, defined in the Core module. This fundamental building block comes with nearly three dozen constants, properties, and methods that define what a Node is and what it can do. More specific kinds of nodes, such as the Document, Element, Attr[ibute], and Text nodes, inherit all of the Node object's constants, properties, and methods, adding properties or methods that are appropriate for whatever kind of node it is. Carrying this inheritance further to the DOM's HTML module, the HTMLElement inherits from the generic Element object, and each tag-specific element (such as HTMLBodyElement or HTMLInputElement) inherits from the HTMLElement object.
You can also find places in the W3C DOM abstract model where object "classes" act as interfaces to other objects. For example, in the Events module, an important object is called the EventTarget. As you'll see in more detail in Chapter 6, any node can be a target of an event. Thus, the DOM specification implies that all node objects should implement the EventTarget interface.
None of this abstract model construction impacts the way your scripts reference objects within a document. But it does help explain why all HTML element objects share such a large number of properties and methods, as shown in the beginning of Chapter 9.
Netscape 6 implements a substantial portion of the W3C DOM Level 2 specification. Support in IE was sketchy in IE 5, but IE has gradually embraced more—but certainly not all—of the specification through Version 6. In other words, IE 5 and later support both the Microsoft proprietary DOM (from IE 4) and significant portions of the W3C DOM. As of IE 6, however, Microsoft has not implemented the W3C DOM modules governing events and text ranges. Chapter 5 and Chapter 6 cover the current W3C and IE DOM implementations, while Chapter 9 provides a complete cross-DOM reference.
|  | |
| 1.5. Style Sheets |  | 1.7. Web Accessibility Initiative |

Copyright © 2003 O'Reilly & Associates. All rights reserved.