
7.2. Using the DBI Framework
Here are the basic steps for using DBI. For more information on DBI, see Programming the Perl DBI by Alligator Descartes and Tim Bunce (O'Reilly).
- Step 1: Load the necessary Perl module
-
Nothing special here, you need to just:
use DBI;
- Step 2: Connect to the database and receive a connection handle
-
The Perl code to establish a DBI connection to a MySQL database and return a database handle looks like this:
# connect using to the database named $database using given # username and password, return a database handle $database = "sysadm"; $dbh = DBI->connect("DBI:mysql:$database",$username,$pw); die "Unable to connect: $DBI::errstr\n" unless (defined $dbh);DBI will load the low-level DBD driver for us (DBD::mysql) prior to actually connecting to the server. We then test if the connect( ) succeeded before continuing. DBI provides RaiseError and PrintError options for connect( ), should we want DBI to perform this test or automatically complain about errors when they happen. For example, if we used:
$dbh = DBI->connect("DBI:mysql:$database", $username,$pw,{RaiseError => 1});then DBI would call die for us if the connect( ) failed.
- Step 3: Send SQL commands to the server
-
With our Perl module loaded and a connection to the database server in place, it's showtime! Let's send some SQL commands to the server. We'll use some of the SQL tutorial queries from Appendix D, "The Fifteen-Minute SQL Tutorial" for examples. These queries will use the Perl q convention for quoting (i.e., something is written as q{something}), just so we don't have to worry about single or double quotes in the actual queries themselves. Here's the first of the two DBI methods for sending commands:
$results=$dbh->do(q{UPDATE hosts SET bldg = 'Main' WHERE name = 'bendir'}); die "Unable to perform update:$DBI::errstr\n" unless (defined $results);$results will receive either the number of rows updated or undef if an error occurs. Though it is useful to know how many rows were affected, that's not going to cut it for statements like SELECT where we need to see the actual data. This is where the second method comes in.
To use the second method you first prepare a SQL statement for use and then you ask the server to execute it. Here's an example:
$sth = $dbh->prepare(q{SELECT * from hosts}) or die "Unable to prep our query:".$dbh->errstr."\n"; $rc = $sth->execute or die "Unable to execute our query:".$dbh->errstr."\n";prepare( ) returns a new creature we haven't seen before: the statement handle. Just like a database handle refers to an open database connection, a statement handle refers to a particular SQL statement we've prepare( )d. Once we have this statement handle, we use execute to actually send the query to our server. Later on, we'll be using the same statement handle to retrieve the results of our query.
You might wonder why we bother to prepare( ) a statement instead of just executing it directly. prepare( )ing a statement gives the DBD driver (or more likely the database client library it calls) a chance to parse the SQL query. Once a statement has prepare( )d, we can execute it repeatedly via our statement handle without parsing it over and over. Often this is a major efficiency win. In fact, the default do( ) DBI method does a prepare( ) and then execute( ) behind the scenes for each statement it is asked to execute.
Like the do call we saw earlier, execute( ) returns the number of rows affected. If the query affects zero rows, the string 0E0 is returned to allow a Boolean test to succeed. -1 is returned if the number of rows affected is unknown by the driver.
Before we move on to ODBC, it is worth mentioning one more twist supported by most DBD modules on the prepare( ) theme: placeholders. Placeholders, also called positional markers, allow you to prepare( ) an SQL statement that has holes in it to be filled at execute( ) time. This allows you to construct queries on the fly without paying most of the parse time penalty. The question mark character is used as the placeholder for a single scalar value. Here's some Perl code to demonstrate the use of placeholders:
@machines = qw(bendir shimmer sander); $sth = $dbh->prepare(q{SELECT name, ipaddr FROM hosts WHERE name = ?}); foreach $name (@machines){ $sth->execute($name); do-something-with-the-results }Each time we go through the foreach loop, the SELECT query is executed with a different WHERE clause. Multiple placeholders are straightforward:
$sth->prepare( q{SELECT name, ipaddr FROM hosts WHERE (name = ? AND bldg = ? AND dept = ?)}); $sth->execute($name,$bldg,$dept);Now that we know how to retrieve the number of rows affected by non-SELECT SQL queries, let's look into retrieving the results of our SELECT requests.
- Step 4: Retrieve SELECT results
-
The mechanism here is similar to our brief discussion of cursors during the SQL tutorial in Appendix D, "The Fifteen-Minute SQL Tutorial". When we send a SELECT statement to the server using execute( ), we're using a mechanism that allows us to retrieve the results one line at a time.
In DBI, we call one of the methods in Table 7-1 to return data from the result set.
Table 7.1. DBI Methods for Returning Data
Name
Returns
Returns If No More Rows
fetchrow_arrayref( )
An array reference to an anonymous array with values that are the columns of the next row in a result set
undef
fetchrow_array( )
An array with values that are the columns of the next row in a result set
An empty list
fetchrow_hashref( )
A hash reference to an anonymous hash with keys that are the column names and values that are the values of the columns of the next row in a result set
undef
fetchall_arrayref( )
A reference to an array of arrays data structure
A reference to an empty array
Let's see these methods in context. For each of these examples, assume the following was executed just prior:
$sth = $dbh->prepare(q{SELECT name,ipaddr,dept from hosts}) or die "Unable to prepare our query: ".$dbh->errstr."\n"; $sth->execute or die "Unable to execute our query: ".$dbh->errstr."\n";Here's fetchrow_arrayref( ) in action:
while ($aref = $sth->fetchrow_arrayref){ print "name: " . $aref->[0] . "\n"; print "ipaddr: " . $aref->[1] . "\n"; print "dept: " . $aref->[2] . "\n"; }The DBI documentation mentions that fetchrow_hashref( ) is less efficient than fetchrow_arrayref( ) because of the extra processing it entails, but it can yield more readable code. Here's an example:
while ($href = $sth->fetchrow_hashref){ print "name: " . $href->{name} . "\n"; print "ipaddr: " . $href->{ipaddr}. "\n"; print "dept: " . $href->{dept} . "\n"; }Finally, let's take a look at the "convenience" method, fetchall_arrayref( ). This method sucks the entire result set into one data structure, returning a reference to an array of references. Be careful to limit the size of your queries when using this method because it does pull the entire result set into memory. If you have a 100GB result set, this may prove to be a bit problematic.
Each reference returned looks exactly like something we would receive from fetchrow_arrayref( ). See Figure 7-2.
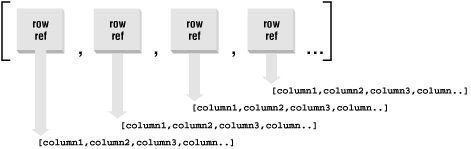
Figure 7.2. The data structure returned by fetchrow_arrayref
Here's some code that will print out the entire query result set:
$aref_aref = $sth->fetchall_arrayref; foreach $rowref (@$aref_aref){ print "name: " . $rowref->[0] . "\n"; print "ipaddr: " . $rowref->[1] . "\n"; print "dept: " . $rowref->[2] . "\n"; print '-'x30,"\n"; }This code sample is specific to our particular data set because it assumes a certain number of columns in a certain order. For instance, we assume the machine name is returned as the first column in the query ($rowref->[0]).
We can use some magic attributes (often called metadata) of statement handles to rewrite our result retrieval code to make it more generic. Specifically, if we look at $sth->{NUM_OF_FIELDS} after a query, it will tell us the number of fields (columns) in our result set. $sth->{NAME} contains a reference to an array with the names of each column. Here's a more generic way to write the last example:
$aref_aref = $sth->fetchall_arrayref; foreach $rowref (@$aref_aref){ for ($i=0; $i < $sth->{NUM_OF_FIELDS};i++;){ print $sth->{NAME}->[$i].": ".$rowref->[$i]."\n"; } print '-'x30,"\n"; }Be sure to see the DBI documentation for more metadata attributes.
- Step 5: Close the connection to the server
-
In DBI this is simply:
# tells server you will not need more data from statement handle # (optional, since we're just about to disconnect) $sth->finish; # disconnects handle from database $dbh->disconnect;
7.2.1. DBI Leftovers
There are two remaining DBI topics worth mentioning before we move on to ODBC. The first is a set of methods I call "shortcut" methods. The methods in Table 7-2 combine steps 3 and 4 from above.
Table 7.2. DBI Shortcut Methods
|
Name |
Combines These Methods into a Single Method |
|---|---|
|
selectrow_arrayref($stmnt) |
prepare($stmnt), execute(), fetchrow_arrayref( ) |
|
selectcol_arrayref($stmnt) |
prepare($stmnt), execute(), (@{fetchrow_arrayref( )})[0] (i.e., returns first column for each row) |
|
selectrow_array($stmnt) |
prepare($stmnt), execute(), fetchrow_array( ) |
The second topic worth mentioning is DBI's ability to bind variables to query results. The methods bind_col( ) and bind_columns( ) are used to tell DBI to automatically place the results of a query into a specific variable or list of variables. This usually saves a step or two when coding. Here's an example using bind_columns( ) that makes its use clear:
$sth = $dbh->prepare(q{SELECT name,ipaddr,dept from hosts}) or
die "Unable to prep our query:".$dbh->errstr".\n";
$rc = $sth->execute or
die "Unable to execute our query:".$dbh->errstr".\n";
# these variables will receive the 1st, 2nd, and 3rd columns
# from our SELECT
$rc = $sth->bind_columns(\$name,\$ipaddr,\$dept);
while ($sth->fetchrow_arrayref){
# $name, $ipaddr, and $dept are automagically filled in from
# the fetched query results row
do-something-with-the-results
}
 |  |  |
| 7.1. Interacting with an SQL Server from Perl |  | 7.3. Using the ODBC Framework |

Copyright © 2001 O'Reilly & Associates. All rights reserved.