

|
Chapter 28 Rules |

|
28.6 The RHS
The purpose of the RHS in a rule is to rewrite the workspace. To make this rewriting more versatile, sendmail offers several special RHS operators. The complete list is shown in Table 28.2 .
| RHS | Description or Use | |
|---|---|---|
$
digit
|
Section 28.6.1, "Copy by Position: $digit" | Copy by position |
$:
|
Section 28.6.2, "Rewrite Once Prefix: $:" | Rewrite once (prefix) |
$@
|
Section 28.6.3, "Rewrite-and-Return Prefix: $@" | Rewrite and return (prefix) |
$>
set
|
Section 28.6.4, "Rewrite Through Another Rule Set: $>set" | Rewrite through another rule set |
$#
|
Section 28.6.5, "Specify a Delivery Agent: $#" | Specify a delivery agent |
$[ $]
|
Section 28.6.6, "Canonicalize Hostname: $[ and $]" | Canonicalize hostname |
$( $)
|
Section 33.4, "Use Maps with $( and $) in Rules" | Database lookup |
28.6.1 Copy by Position: $digit
The
$
digit
operator in the
RHS
is used to copy tokens
from the
LHS
into the workspace. The
digit
refers to
positions of
LHS
wildcard operators in the
LHS
:
R$+@$* $2!$1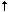
Here, the
$1
in the
RHS
indicates tokens matched by the first
wildcard operator in the
LHS
(in this case the
$+
),
and the
$2
in the
RHS
indicates tokens matched by
the second wildcard operator in the
LHS
(the
$*
).
In this example, if the workspace contains
A@B.C
, it
will be rewritten by the
RHS
as follows:
$*
matches
B.C
so
$2
copies it to workspace
!
explicitly placed into workspace
$+
matches
A
so
$1
copies it to workspace
The
$
digit
copies all the tokens matched by its corresponding
wildcard operator.
For the
$+
wildcard operator, only a single token (
A
)
is matched and copied with
$1
.
The
!
is copied as is.
For the
$*
wildcard operator,
three tokens are matched (
B.C
), so
$2
copies all three.
Thus the above rule rewrites
A@B.C
into
B.C!A
.
Not all
LHS
operators
need
to be referenced with a
$
digit
in the
RHS
.
Consider the following:
R$*<$*>$* <$2>
Here, only the middle
LHS
operator (the second one) is required to
rewrite the workspace. So only the
$2
is needed in the
RHS
(
$1
and
$3
are not needed and are not present
in the
RHS
).
Although macros appear to be operators in the
LHS
, they are
not. Recall that macros are expanded when the configuration
file is read (see
Section 28.1.1, "Macros in Rules"
). As a consequence, although they appear as
$
letter
in the configuration file, they are converted
to tokens when that configuration file is read. For example,
DAxxx R$A @ $* $1
Here, the macro
A
is defined to have the value
xxx
.
To the unwary, the
$1
appears
to indicate the
$A
.
But when the configuration file is read, the above rule is expanded
into
Rxxx @ $* $1
Clearly, the
$1
refers to the
$*
(because
$
digit
references only operators and
$A
is a macro, not an operator).
The
sendmail
program is unable to detect errors of this sort. If the
$1
were instead
$2
(in a mistaken attempt to reference the
$*
),
sendmail
prints the following error and skips
that rule:
ruleset replacementnum out of bounds
V8 sendmail catches these errors when the configuration file is read. Earlier versions caught this error only when mail was actually sent.
The
digit
of the
$
digit
must be in the range
one through nine. A
$0
is meaningless and causes
sendmail
to print the above error message and to skip that rule.
Extra digits are considered tokens,
rather than extensions of the
$
digit
. That is,
$11
is the
RHS
operator
$1
and the token
1
,
not a reference to the eleventh
LHS
operator.
28.6.2 Rewrite Once Prefix: $:
Ordinarily, the RHS rewrites the workspace as long as the workspace continues to match the LHS . This looping behavior can be useful. Consider the need to strip extra trailing dots off an address in the workspace:
R$*.. $1.
Here, the
$*
matches any address that has two or more
trailing dots. The
$1.
in the
RHS
then strips one
of those two trailing dots when rewriting the workspace. For
example,
xxx . . . . . becomesxxx . . . . xxx . . . . becomes
match fails
Although this looping behavior of rules can be handy, for most rules it can be dangerous. Consider the following example:
R$* <$1>
The intention of this rule is to cause whatever is in the workspace
to become surrounded with angle brackets.
But after the workspace is rewritten, the
LHS
again checks for a match; and since the
$*
matches anything,
the match succeeds, the
RHS
rewrites the workspace again,
and again the
LHS
checks for a match:
xxx becomesand so on, until ...
In this case, sendmail catches the problem, because the workspace has become too large. It prints the above error message and skips that and all further rules in the rule set. If you are running sendmail in test mode, this fatal error would also be printed:
== Ruleset 0 (0) status 65
Unfortunately, not all such endless looping produces a visible error message. Consider the following example:
R$* $1
Here is an LHS that matches anything and an RHS that rewrites the workspace in such a way that the workspace never changes. For older versions this causes sendmail to appear to hang (as it processes the same rule over and over and over). Newer versions of sendmail will catch such endless looping and print ( syslog ) the following error:
Infinite loop in rulesetruleset_name, rule rule_number
In this instance the original workspace is returned.
It is not always desirable (or even possible) to write "loop-proof"
rules. To prevent looping,
sendmail
offers the
$:
RHS
prefix. By starting the
RHS
of a rule with the
$:
operator, you are telling
sendmail
to rewrite the workspace
exactly once.
R$* $: <$1>
Again the rule causes the contents of the workspace
to be surrounded by a pair of
angle brackets. But here the
$:
prefix prevents the
LHS
from checking
for another match after the rewrite.
Note that the
$:
prefix must begin the
RHS
to
have any effect. If it instead appears inside the
RHS
, its
special meaning is lost:
foo rewritten by $:$1 becomes
28.6.3 Rewrite-and-Return Prefix: $@
The flow of rules is such that each and every rule in a series of rules (a rule set) is given a chance to match the workspace:
Rxxx yyy Ryyy zzz
The first rule matches
xxx
in the workspace and
rewrites the workspace to contain
yyy
. The first
rule then tries to match the workspace again but, of
course, fails.
The second rule then tries to match the workspace.
Since the workspace
contains
yyy
, a match is found, and the
RHS
rewrites the workspace
to be
zzz
.
There will often be times when one rule in a series performs
the appropriate rewrite and no subsequent rules need to be
called. In the above example, suppose
xxx
should
only become
yyy
and that the second rule
should not be called. To solve problems like this,
sendmail
offers the
$@
prefix for use in the
RHS
.
The
$@
prefix tells
sendmail
that the current rule
is the last one that should be used in the current rule set.
If the
LHS
of the current
rule matches, any rules that follow (in the current rule set) are ignored:
Rxxx $@yyy Ryyy zzz
If the workspace contains anything other than
xxx
, the
first rule does not match, and the second rule is called.
But if the workspace contains
xxx
, the first rule
matches and rewrites the workspace. The
$@
prefix
for the
RHS
of that rule prevents the second rule (and any
subsequent rules) from being called.
Note that the
$@
also prevents looping. The
$@
tells
sendmail
to skip further rules
and
to
rewrite only once. The difference between
$@
and
$:
is
that both rewrite only once, but
$@
doesn't
proceed to the next rule, whereas
$:
does
.
The
$@
operator must be used as a prefix because it has special
meaning only when it
begins the
RHS
of a rule. If it appears anywhere
else inside the
RHS
it loses its special meaning:
foo rewritten by $@$1 becomes
28.6.4 Rewrite Through Another Rule Set: $>set
Rules are organized in sets that can be thought of as subroutines. Occasionally, a rule or series of rules can be common to two or more rule sets. To make the configuration file more compact and somewhat clearer, such common series of rules can be made into separate subroutines.
The
RHS
$>
set
operator tells
sendmail
to perform
additional rewriting using a secondary set of rules.
The
set
is the rule-set name or number of that secondary
set. If
set
is the name or number of a nonexistent rule set,
the effect is the same as if the subroutine rules were
never called (the workspace is unchanged).
If the
set
is numeric and is greater than the maximum number of allowable
rule sets,
sendmail
prints the following error and skips that rule:
bad rulesetbad_number (maximum max)
If the
set
is a name and the rule-set name is unknown,
sendmail
prints the following error and skips that rule:
Unknown rulesetbad_name
Neither of these errors is caught when the configuration file is read. They are caught only when mail is sent, because a rule set name may be a macro:
$> $&{SET}
The
$&
prefix prevents the macro named
{SET}
from being expanded
when the configuration file is read. Therefore the name or number of the rule
set cannot be known until mail is sent.
The process of calling another set of rules proceeds in five stages:
First
As usual, if the
LHS
matches the workspace, the
RHS
gets to rewrite
the workspace.
Second
The
RHS
ignores the
$>
set
part and rewrites the rest as usual.
Third
The rewritten workspace is then given to the set of rules specified
by
set
. They either rewrite the workspace or do not.
Fourth
The original
RHS
(the one with the
$>
set
) leaves
the possibly rewritten workspace as is, as though it had performed
the subroutine's rewriting itself.
Fifth
The
LHS
gets a crack at the new workspace as usual unless it is prevented
by a
$:
or
$@
prefix in the
RHS
.
For example, consider the following two sets of rules:
# first set S21 R$*.. $:$>22 $1. strip extra trailing dots ...etc. # second set S22 R$*.. $1. strip trailing dots
Here, the first set of rules contains, among other things, a single rule that removes extra dots from the end of an address. But because other rule sets may also need extra dots stripped, a subroutine (the second set of rules) is created to perform that task.
Note that the first rule strips one trailing dot
from the workspace and then calls
rule set 22 (the
$>22
), which then strips
any additional dots.
The workspace as rewritten by rule set 22 becomes
the workspace yielded by the
RHS
in the first rule.
The
$:
prevents the
LHS
of the first rule from
looking for a match a second time.
Prior to V8.8
sendmail
the subroutine call must begin the
RHS
(immediately follow any
$@
or
$:
prefix, if any) and
only a single subroutine may be called. That is, the following
causes rule set 22 to be called but does not call 23:
$>22 xxx $>23 yyy
Instead of calling rule set 23, the
$>
operator and
the
23
are copied as is into the workspace, and
that workspace is passed to rule set 22:
xxx $> 23 yyy
Beginning with V8.8 [5] sendmail , subroutine calls may appear anywhere inside the RHS , and there may be multiple subroutine calls. Consider the same RHS as above:
[5] Using code derived from IDA sendmail.
$>22 xxx $>23 yyy
Beginning with V8.8
sendmail
, rule set 23 is called first and is
given the workspace
yyy
to rewrite. The workspace,
as rewritten by rule set 23, is added to the end of the
xxx
,
and the combined result is passed to rule set 22.
Under V8.8 sendmail , subroutine rule-set calls are performed from right to left. The result (rewritten workspace) of each call is appended to the RHS text to the left.
You should beware of one problem with all versions of
sendmail
.
When ordinary text immediately follows the number of the rule
set, that text is likely to be ignored. This can be witnessed
by using the
-d21.3
debugging switch.
Consider the following RHS :
$>3uucp.$1
Because
sendmail
parses the
3
and the
uucp
as a single token, the subroutine call succeeds, but the
uucp
is lost. The
-d21.3
switch illustrates this
problem:
-----callsubr 3uucp (3)
The
3uucp
is interpreted as the number 3,
so it is accepted as a valid number despite the fact
that
uucp
was attached.
Since the
uucp
is a part of the number, it
is not available for comparison
to the workspace and so is lost.
The correct way to write the above
RHS
is
$>3 uucp.$1
Note that the space between the
3
and the
uucp
causes
them to be viewed as two separate tokens.
This problem can also arise with macros. Consider the following:
$>3$M
Here, the
$M
is expanded when the configuration file is
parsed. If the expanded value
lacks a leading space, that value (or the first token in it) is lost.
Note that operators that follow a rule-set number are correctly recognized:
$>3$[$1$]
Here, the
3
is immediately followed by the
$[
operator.
Because operators are token separators, the call to rule set 3
will be correctly interpreted as
-----callsubr 3 (3)
But as a general rule, and just to be safe, the number of a subroutine call should always be followed by a space. [6]
[6] As a stylistic point, it is easier to read rules that have spaces between all patterns that are expected to match separate tokens. For example, use
$+ @ $* $=minstead of$+@$*$=m. This style handles subroutine calls automatically.
28.6.5 Specify a Delivery Agent: $#
The
$#
operator in the
RHS
is copied as is into the workspace
and functions as a flag advising
sendmail
that
a delivery agent has been selected. The
$#
must be the first
token copied into the rewritten workspace for it to have this special
meaning:
If it occupies any other position in the workspace, it loses its
special meaning.
$# local
When it occurs first in the rewritten workspace, the
$#
operator tells
sendmail
that the second token in the workspace is the name of a delivery
agent.
The
$#
operator is useful only in rule
sets 0 and 5.
Note that the
$#
operator may be prefixed with a
$@
or
a
$:
without losing its special meaning, because those prefix
operators are not copied to the workspace:
$@ $# local rewritten as
However, those prefix operators are not necessary, because
the
$#
acts just like a
$@
prefix. It
prevents the
LHS
from attempting to match again after the
RHS
rewrite, and it causes any following rules to be skipped.
When used in nonprefix roles in rule sets 0 and 5,
$@
and
$:
also act like flags, conveying host and user information
to
sendmail
(see
Section 29.6, "Rule Set 0"
).
28.6.6 Canonicalize Hostname: $[ and $]
Tokens that appear between
a
$[
and
$]
pair of operators in the
RHS
are
considered to be the name of a host.
That hostname is looked up by using
DNS
[7]
and replaced with the full canonical form of that name.
If found, it is then copied to the workspace, and the
$[
and
$]
are discarded.
[7] Or other means, depending on the setting of service switch file, if you have one, or the state of the
ServiceSwitchFileoption (see Section 34.8.61, ServiceSwitchFile ).
For example, consider a rule that looks for a hostname in angle brackets and (if found) rewrites it in canonical form:
R<$*> $@ <$[ $1 $]> canonicalize host name
Such canonicalization is useful at sites where users frequently send mail
to machines using the short version of a machine's name.
The
$[
tells
sendmail
to view all the tokens
that follow (up to the
$]
) as a single hostname.
If the name cannot be canonicalized (perhaps because there is no such host), the name is copied as is into the workspace. For configuration files lower than 2, no indication is given that it could not be canonicalized (more about this soon).
Note that if the
$[
is omitted and the
$]
is included,
the
$]
loses its special meaning and is copied as is
into the workspace.
The hostname between the
$[
and
$]
can also
be an
IP
address. By surrounding the hostname with
square brackets (
[
and
]
), you are telling
sendmail
that it is really an
IP
address:
wash.dc.gov
When the IP address between the square brackets corresponds to a known host, the address and the square brackets are replaced with that host's canonical name.
If the version of the configuration
file is
2
or greater (as set with the
V
configuration command;
see
Section 27.5, "The V Configuration Command"
),
a successful canonicalization has a dot appended to the
result:
myhost becomes
Note that a trailing dot is not legal [8] in an address specification, so subsequent rules (such as rule set 4) must remove these added trailing dots.
[8] Under DNS the trailing dot signifies the root (topmost) domain. Therefore under DNS a trailing dot is legal. For mail, however, RFC1123 specifically states that no address is to be propagated that contains a trailing dot.
Also, the
K
configuration command
(see
Section 33.3, "The K Configuration Command"
)
can be used
to redefine (or eliminate) the dot as the added character. For example,
Khost host -a.found
This causes
sendmail
to
add the text
.found
to a successfully
canonicalized hostname instead of the dot.
One difference between V8
sendmail
and other versions
is in the way it looks up names from between the
$[
and
$]
operators. The rules for V8
sendmail
are as follows:
First
If the name contains at least one dot (
.
) anywhere within it, it is
looked up as is; for example,
host.CS
.
Second
If that fails, it appends the default domain to the name (as defined
in
/etc/resolv.conf
) and tries to look up the result;
for example,
host.CS.our.Sub.Domain
.
Third
If that fails, the leftmost part of the subdomain (if any) is discarded
and the result is appended to the original host;
for example,
host.our.Sub.Domain
.
Fourth
If the original name did not have a dot in it, it is looked up as is;
for example,
host
.
This approach allows names such as
host.CS
to first match
a site in the Czech Republic, such as
vscht.CS
(if that was intended), rather than to wrongly
match a host in your local Computer Science (
CS
) department.
This is particularly important if you have wildcard
MX
records
for your site.
28.6.6.1 An example of canonicalization
The following two-line configuration file can be used to observe how sendmail canonicalizes hostnames:
V2 R$* $@ $[ $1 $]
If this file were called x.cf , sendmail could be run in rule-testing mode with a command like the following:
%/usr/lib/sendmail -oQ. -Cx.cf -bt
Thereafter, hostname canonicalization can be observed by specifying rule set 0 and a hostname. One such run of tests is as follows:
ADDRESS TEST MODE (ruleset 3 NOT automatically invoked) Enter <ruleset> <address> >0 washrewrite: ruleset 0 input: wash rewrite: ruleset 0 returns: wash . dc . gov . >0 nohostrewrite: ruleset 0 input: nohost rewrite: ruleset 0 returns: nohost >
Note that the known host named
wash
is rewritten in
canonicalized form (with a dot appended because of the
V2
).
The unknown host named
nohost
is unchanged and has no dot appended.
28.6.6.2 Default in canonicalization: $:
IDA and V8
sendmail
both offer an alternative to
leaving the hostname unchanged when canonicalization fails
with
$[
and
$]
. A default can be used instead
of the failed hostname by prefixing that default with a
$:
:
$[host $: default $]
The
$:
default
must follow the
host
and
precede the
$]
. To illustrate its use, consider the
following rule:
R$* $:$[ $1 $: $1.notfound $]
If the hostname
$1
can be canonicalized, the workspace
becomes that canonicalized name. If it cannot, the workspace
becomes the original hostname with a
.notfound
appended
to it.
If the
default
part of the
$:
default
is omitted,
a failed canonicalization is rewritten as zero tokens.
28.6.7 Other Operators
Many other operators (depending on your version of sendmail ) may also be used in rules. Because of their individual complexity, all of the following are detailed in other chapters. We outline them here, however, for completeness.
- Class macros
-
Class macros are described in Section 32.2.1, "Matching Any in a Class: $=" and Section 32.2.2, "Matching Any Not in a Class: $~" of Chapter 32, Class Macros . Class macros may appear only in the LHS . They begin with the prefix
$=to match a token in the workspace to one of many items in a class. The alternative prefix$~causes a token in the workspace to match if it does not appear in the list of items that are the class. - Conditionals
-
The conditional macro operator
$?is rarely used in rules (see Section 31.6, "Macro Conditionals: $?, $|, and $." ). When it is used in rules, the result is often not what was intended. Its else part, the$|conditional operator is used by thecheck_compatrule set (see Section 29.10.4, "The check_compat Rule Set" ) to separate the sender from the recipient address. - Database Operators
-
The database operators,
$(and$), are used to look up tokens in various types of database files and network database services. They also provide access to internal services, such as dequoting and looking up MX records (see Chapter 33, Database Macros ).
|
|

|
|
| 28.5 The LHS |
|
28.7 Pitfalls |