
Chapter 8. SQL Reference
Contents:
Relational Databases
Data Types
Schema Manipulation Commands
Data Manipulation Commands
Functions
Return Codes
There are dozens of different database management systems on the market today, from nearly as many vendors. Developing applications that are more or less database independent requires a standardized interface to the underlying data. Since the early 1980s, this interface has been SQL, a sophisticated database manipulation language.[1]
[1] The acronym expands out to either Structured Query Language (based on the original IBM acronym from the 1970s) or Standard Query Language (which has been more popular in recent years). Perhaps because of this confusion, most people just say SQL, pronounced either see-quell or ess-cue-ell.
Unlike Java, SQL is a declarative language. It allows users to specify particular actions on the database and retrieve the results of those actions. It specifies a set of standardized data types and standard error messages, but it lacks procedural constructs. There are no conditionals or loops standard in SQL.
There are several versions of the SQL standard. SQL-86 and SQL-89 have been superceded by SQL-92, which is supported by most database vendors, although there are a number of platform-specific variations. Many databases also include additional data types, operators, and functions beyond those specified in the SQL-92 standard. In addition, there are three levels of SQL-92 conformance: entry-level, intermediate, and full. Many products support only the entry-level SQL-92 standard, leaving out some advanced features. JDBC drivers are supposed to provide entry-level functionality and, for the most part, they do.
This chapter presents a brief introduction to the structure of a relational database system and a quick reference to the most commonly used SQL commands. The complete set of SQL commands is simply too large to cover here: even a concise SQL reference can run to several hundred pages. I have endeavored to provide the information that most client-side programmers need. For a complete introduction to most aspects of SQL, I highly recommend SQL Clearly Explained by Jan Harrington (AP Professional).
8.1. Relational Databases
Data storage and retrieval are two of the biggest tasks facing most enterprise applications. There are lots of ways to store data on a disk, but for large-scale applications a relational database management system (RDBMS) is far and away the most popular choice.
Data in an RDBMS is organized into tables, where these tables contain rows and columns. You can think of an individual table as a spreadsheet with a little more organization: column data types are fixed and there may be rules governing the formatting of each column. This alone is enough for a database system (plain DBMS). A relational database system has one other key attribute: individual tables can be related based on some common data. Figure 8-1 shows three tables in a relational structure. The CUSTOMERS table is related to the ORDERS table based on the CUSTOMER_ID field, and the ORDERS table is related to the ITEMS table based on the ORDER_ID field. SQL provides a standardized means of accessing the data in tables and working with the relationships between tables.
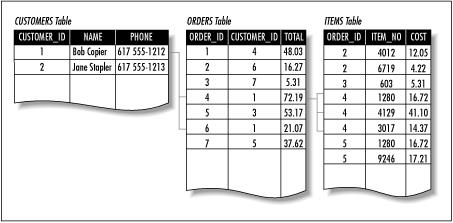
Figure 8-1. Three related tables
The highest-level organizational concept in an RDBMS system is a cluster.[2] A cluster contains one or more catalogs, which are usually the highest-level object a programmer ever has to deal with. A catalog contains a group of schemas. A schema contains a group of tables and other objects and is generally assigned to a particular application or user account. Generally, the database administrator is responsible for dealing with clusters and catalogs. Most users work within a particular schema.
[2] The naming comes from the older SQL standards, where a cluster represented physical storage space. This is no longer the case, but the name persists.
To reference a table within a particular schema, separate the schema name and the table name with a dot:
schema_name.table_name
To reference a particular column within a particular schema:
schema_name.table_name.column_name
To set a particular schema as the default, use the SET SCHEMA SQL statement:
SET SCHEMA schema_name
When you log into a database, you are generally assigned a default schema. When accessing tables within the default schema, you may omit the schema name.
When creating new objects, the names you assign to them must be unique within the schema. SQL-92 allows names up to 128 characters, including letters, numbers, and the underscore ( _ ) character.
 |  |  |
| Part 2. Enterprise Reference |  | 8.2. Data Types |

Copyright © 2001 O'Reilly & Associates. All rights reserved.