|
» |
|
|
|
A two data center and third location have the following configuration requirements: If Arbitrator nodes are used
there must be an equal number of nodes (1-7) in each Primary data
center, and the third location can contain 1 or 2 Arbitrator nodes.
The Arbitrator nodes are standard Serviceguard nodes configured
in the cluster, however, they are not allowed to be connected to
the shared disks in either of the Primary data centers. Arbitrator
nodes are used as tie breakers to maintain cluster quorum when all
communication between the two Primary data centers is lost. The
data center containing the Arbitrator Nodes must be located separately
from the nodes in the Primary data centers. If the Primary data
centers each contain a single node, then only one Arbitrator node
is allowed. Cluster lock disks are not supported in this configuration.
Arbitrator nodes are not supported if CVM or CFS is used in the
cluster. The third location can contain
a single Serviceguard Quorum Server node (running HP-UX or Red Hat
Linux), in place of an Arbitrator node(s), however that node must
still be located in a third location separate from the Primary data
centers, with a separate power circuit. The Quorum Server does not
have to be on the same subnet as the cluster nodes, but network
routing must be configured such that all nodes in the cluster can
contact the Quorum Server via separate physical routes. Since only
one IP address can be configured for a Quorum Server, it is suggested
to make the Quorum Server more highly available. This is done by
running it in it's own Serviceguard cluster, or to configure the
LAN used for the Quorum Server IP address with at least two LAN
interface cards using APA (Automatic Port Aggregation) LAN_MONITOR mode to improve the availability if a LAN failure occurs.
Prior to Quorum Server revision A.02.00, it was not supported
to run the Quorum Server in a Serviceguard cluster.
For
more information about quorum server, refer to the Managing Serviceguard user’s
guide and the Serviceguard Quorum Server Release Notes No routing is allowed for
the networks between the data centers. Routing is allowed to the
third location if a Quorum Server is used in that data center site.
MirrorDisk/UX mirroring for LVM and VxVM mirroring is supported for
clusters of up to 16 nodes.
CVM 3.5 or CVM 4.1 mirroring is supported for Serviceguard and Extended
Clusters for RAC clusters containing 2, 4, 6, or 8 nodes*. In CVM
and CFS configurations Arbitrator nodes are not supported, and a
Quorum Server node must be used instead.
MirrorDisk/UX mirroring for Shared LVM volume groups is supported
for EC RAC clusters containing 2 nodes. If Serviceguard OPS Edition
or Serviceguard Extension for RAC is used, then there can only be
two or four nodes configured to share OPS/RAC data, as MirrorDisk/UX
only supports concurrent volume group activation for up to two nodes.
CVM and CFS allows for clusters containing 2, 4, 6 or 8 nodes*. There can be separate networking
and Fibre Channel links between the data centers, or both networking
and Fibre Channel can go over DWDM links between the data centers. Fibre Channel Direct Fabric
Attach (DFA) is recommended over Fibre Channel Arbitrated loop configurations,
due to the superior performance of DFA, especially as the distance
increases. Therefore Fibre Channel switches are preferred over Fibre
Channel hubs. Any combination of the following
Fibre Channel capable disk arrays may be used: HP StorageWorks FC10,
HP StorageWorks FC60, HP StorageWorks Virtual Arrays, HP StorageWorks
Disk Array XP or EMC Symmetrix Disk Arrays. Application data must be
mirrored between the primary data centers. If MirrorDisk/UX is used,
Mirror Write Cache (MWC) must be the Consistency Recovery policy
defined for all mirrored logical volumes. This will allow for resynchronization
of stale extents after a node crash, rather than requiring a full
resynchronization. For SLVM (concurrently activated) volume groups,
Mirror Write Cache must not be defined as the Consistency Recovery
policy for mirrored logical volumes (that is, NOMWC must
be used). This means that a full resynchronization may
be required for shared volume group mirrors after a node crash,
which can have a significant impact on recovery time. To ensure
that the mirror copies reside in different data centers, it is recommended
to configure physical volume groups for the disk devices in each
data center, and to use Group Allocation Policy for all mirrored
logical volumes. Due to the maximum of 3 images
(1 original image plus two mirror copies) allowed in MirrorDisk/UX,
if JBODs are used for application data, only one data center can
contain JBODs while the other data center must contain disk arrays
with hardware mirroring. Note that having three mirror copies will
affect performance on disk writes. VxVM and CVM mirroring does not
have a limit on the number of mirror copies, so it is possible to
have JBODS in both data centers, however increasing the number of
mirror copies may adversely affect performance on disk writes. No routing is allowed for
the networks between data centers. Routing is allowed to the third
data center if a Quorum Server is used in that data center. Veritas Volume Manager (VxVM)
mirroring is supported for distances of up to 100 kilometers for
clusters of 16 nodes*. However, VxVM supports up to 10 kilometers
for clusters of 16 nodes depending on your HP-UX version*. Ensure
that the mirror copies reside in different data centers and the
DRL (Dirty Region Logging) feature are used. Raid 5 mirrors are
not supported. It is important to note that the data replication
links between the data centers VxVM can only perform a full resynchronization
(that is, it cannot perform an incremental synchronization) when
recovering from the failure of a mirror copy or loss of connectivity
to a data center. This can have a significant impact on performance
and availability of the cluster if the disk groups are large. Veritas CVM mirroring is
supported for Serviceguard, Serviceguard OPS Edition, or Serviceguard
Extension for RAC clusters for distances up to 10 kilometers for
2, 4, 6, or 8 node clusters, and up to 100 kilometers for 2 node
clusters*. Since CVM 3.5 does not support multiple heartbeats
and allows only one heartbeat network to be defined for the cluster,
you must make the heartbeat network highly available, using a standby
LAN to provide redundancy for the heartbeat network.
The heartbeat subnet should be a dedicated network, to ensure that
other network traffic will not saturate the heartbeat network. The
CVM Mirror Detachment Policy must be set to “Global”. For clusters using Veritas
CVM 3.5, only a single heartbeat subnet is supported, so it is required
to have both Primary and Standby LANs configured for the heartbeat
subnet on all nodes. For SGeRAC clusters, it is recommended to have
an additional network for Oracle RAC cache fusion traffic. It is
acceptable to use a single Standby network to provide backup for
both the heartbeat network and the RAC cache fusion network, however
it can only provide failover capability for one of these networks
at a time. If Serviceguard Extension
for Faster Failover (SGeFF) is used in a two data center and third
location architecture, a two node cluster with multiple heartbeats
and a quorum server in the third location are required. For more
detailed information on Serviceguard Extension for Faster Failover,
refer to the Serviceguard Extension for Faster Failover
Release Notes and the “Optimizing
Failover Time in a Serviceguard Environment” white
paper.
The following table shows the possible configurations using
a three data center architecture. Table 2-2 Supported System and Data Center Combinations | Data Center A | Data Center B | Data Center C | Serviceguard Version |
|---|
| 1 | 1 | 1 Arbitrator Node | A.11.13 or later | 1 | 1 | Quorum Server System | A.11.13 or later | 1 | 1 | Quorum Server System | A.11.16 or later (including SGeFF) | 2 | 1 | 2 Arbitrator Nodes | A.11.13 or later | | 1 | 2 | 2 Arbitrator Nodes | A.11.13 or later | | 2 | 2 | 1 Arbitrator Node | A.11.13 or later | | 2 | 2 | 2* Arbitrator Nodes | A. 11.13 or later | 2 | 2 | Quorum Server System | A. 11.13 or later | | 3 | 3 | 1 Arbitrator Node | A. 11.13 or later | | 3 | 3 | 2* Arbitrator Nodes | A. 11.13 or later | 3 | 3 | Quorum Server System | A.11.13 or later | | 4 | 4 | 1 Arbitrator Node | A.11.13 or later | | 4 | 4 | 2* Arbitrator Nodes | A.11.13 or later | 4 | 4 | Quorum Server System | A.11.13 or later | | 5 | 5 | 1 Arbitrator Node | A.11.13 or later | | 5 | 5 | 2* Arbitrator Nodes | A.11.13 or later | 5 | 5 | Quorum Server System | A.11.13 or later | | 6 | 6 | 1 Arbitrator Node | A.11.13 or later | | 6 | 6 | 2* Arbitrator Nodes | A.11.13 or later | 6 | 6 | Quorum Server System | A.11.13 or later | | 7 | 7 | 1 Arbitrator Node | A.11.13 or later | | 7 | 7 | 2* Arbitrator Nodes | A.11.13 or later | 7 | 7 | Quorum Server System | A.11.13 or later | 8 | 8 | Quorum Server System | A.11.13 or later |
* Configurations with two arbitrators are preferred because
they provide a greater degree of availability, especially in cases
when a node is down due to a failure or planned maintenance. It
is highly recommended that two arbitrators be configured in Data
Center C to allow for planned downtime in Data Centers A and B. | | | |  | NOTE: Serviceguard Extension for RAC clusters are limited
to 2, 4, 6, or 8 nodes. | | | | |
The following is a list of recommended arbitration methods
for Metrocluster solutions in order of preference: 2 arbitrator
nodes, where supported 1 arbitrator node, where
supported Quorum Server running in
a Serviceguard cluster
For more information on Quorum Server, refer to the Serviceguard Quorum
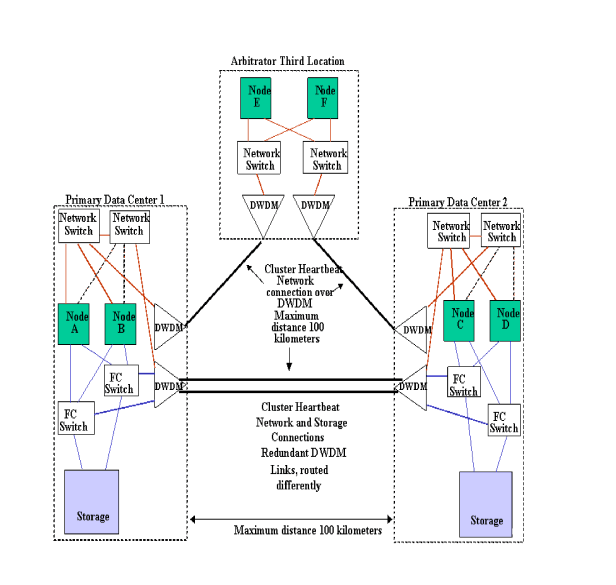
Server Version A.01.00 Release Notes for HP-UX. Figure 2-4 “Two
Data Centers and Third Location with DWDM and Arbitrators” is an example
of a two data center and third location configuration using DWDM,
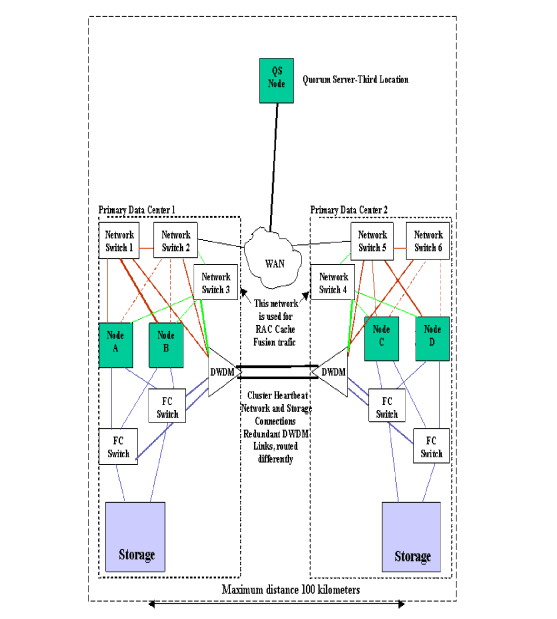
with arbitrator nodes in the third location. Figure 2-5 “Two
Data Centers and Third Location with DWDM and Quorum Server” is an example
of a two data center and third location configuration using DWDM,
with a quorum server node on the third site and is specifically
for a SGeRAC cluster. The DWDM boxes connected between the two Primary
Data Centers are configured with redundant dark fibre links and
the standby fibre feature has been enabled. Note that there is a separate network (indicated by the lines
to switches #3 and #4) being used for the RAC Cache Fusion traffic
to ensure good RAC performance. Switches #2 and #5 are used for
the Standby network, which can provide local LAN failover for both
the Primary Heartbeat network and the Primary RAC Cache Fusion network.
However it must be noted that the Standby network can only provide
local failover capability for one of the Primary networks at a time.
For that reason, it is preferable to have a separate Standby network
for the Heartbeat network and for the RAC Cache Fusion network. There are no requirements for the distance between the Quorum
Server Data center and the Primary Data Centers, however it is necessary
to ensure that the Quorum Server can be contacted within a reasonable amount
of time (should be within the NODE_TIMEOUT period). Cluster lock
disks are not allowed in this configuration. There can be 2, 4,
6, or 8 nodes in this cluster if CVM 3.5 is used and the distance
is 10 kilometers or less. However, there can be only 2 nodes in
this cluster if CVM is used, the distance is 100 kilometers and
if shared LVM is used. Since there are 4 nodes shown in this example cluster, this
means that this cluster can only use CVM as the volume manager,
and the distance between the Primary data centers cannot exceed
10 kilometers. |