|
» |
|
|
|
To protect against
multiple points of failure, cluster components must be geographically
dispersed: nodes can be put in different rooms, on different floors
of a building, or even in separate buildings or separate cities.
The distance between the nodes is dependent on the types of disaster
from which you need protection, and on the technology used to replicate
data. Three types of disaster-tolerant clusters are described in this
guide: These types differ from a simple local cluster in many ways.
Extended distance clusters and metropolitan clusters often require
right-of-way from local governments or utilities to lay network
and data replication cable. This can complicate the design and implementation.
They also require a different kind of control mechanism for ensuring
that data integrity issues do not arise, such as a quorum server.
Typically, metropolitan clusters use an arbitrator site containing
additional cluster nodes instead of the cluster lock disk. Continental
clusters span great distances and operate by replicating data between
two completely separate local clusters. Extended
Distance Clusters | |
The two types of Extended
Distance Cluster configurations are Extended Distance Cluster and Extended
Distance Cluster for RAC. Both types use Serviceguard to create
disaster tolerant High Availability clusters. The following describes
in more detail the key differences between the two types: An Extended Distance Cluster (also
known as extended campus cluster) is a normal
Serviceguard cluster that has alternate nodes located in different
data centers separated by some distance. Extended distance clusters
are connected using a high speed cable that guarantees network access
between the nodes as long as all guidelines for disaster tolerant
architecture are followed. Extended distance clusters were formerly
known as campus clusters, but that term is
not always appropriate because the supported distances have increased
beyond the typical size of a single corporate campus. The maximum
distance between nodes in an Extended Distance Cluster is set by
the limits of the data replication technology and networking limits.
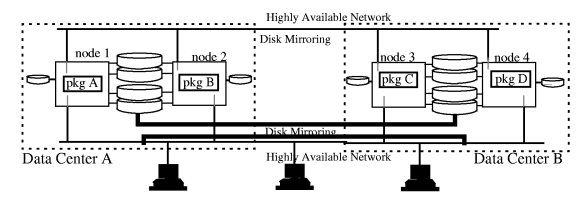
An Extended Distance Cluster is shown in Figure 1-3 “Extended
Distance Cluster ”. Extended
distance clusters can be configured over shorter distances using
FibreChannel mass storage, or over distances as great as 100 km using
storage and networking routed over links extended via DWDM. In extended distance architecture, each clustered server is
directly connected to all storage in both data centers. With direct
access to remote storage devices from a local server, an Extended
Distance Cluster with up to four nodes can be designed with two
data centers using dual cluster lock disks for cluster quorum. If
the cluster size is greater than four nodes, an Extended Distance
Cluster can be designed with two data centers and a third location
housing arbitrator nodes or quorum server. Architecture and configuration
requirements for several types of extended distance clusters are
described more fully in Chapter 2 “Building
an Extended Distance Cluster Using Serviceguard” Benefits
of Extended Distance ClusterThis configuration
implements a single Serviceguard cluster across two data centers,
and uses either MirrorDisk/UX or Veritas VxVM mirroring from Symantec
for data replication. No (cluster) license beyond Serviceguard is
required for this solution, making it the least expensive to implement. You may choose any storage
supported by Serviceguard, and the storage can be a mix of any Serviceguard-supported
storage. This configuration may be
the easiest to understand and manage, as it is similar in many ways
to Serviceguard. Application failover is minimized.
All disks are available to all nodes, so that if a primary disk
fails but the node stays up and the replica is available, there
is no failover (that is, the application continues to run on the
same node while accessing the replica). Data copies are peers, so
there is no issue with reconfiguring a replica to function as a
primary disk after failover. Writes are synchronous, unless
the link or disk is down, so data remains current between the primary
disk and its replica.
Extended
Distance Cluster for RAC | |
An Extended
Distance Cluster for RAC merges Extended Distance Cluster
with Serviceguard Extension for RAC (SGeRAC). SGeRAC is a specialized
configuration that enables Oracle Real Application Clusters (RAC)
to run in an HP-UX environment on high availability clusters. RAC
in a Serviceguard environment lets you maintain a single (Oracle) database
image that is accessed by the servers in parallel in an active/active
configuration, thereby providing greater processing power without
the overhead of administering separate databases. Metropolitan
Cluster | |
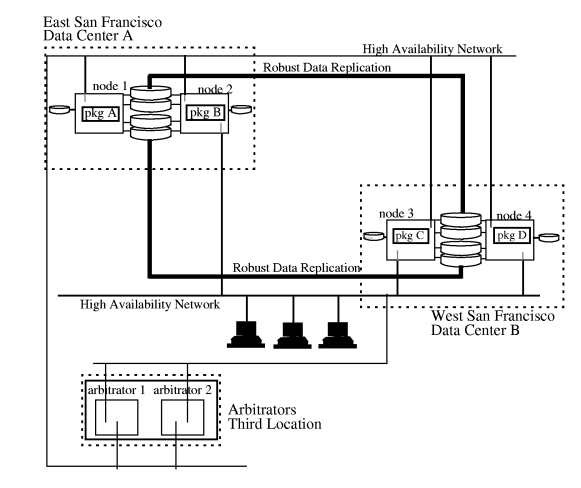
A metropolitan
cluster is a cluster that has alternate nodes located
in different parts of a city or in adjacent cities. Putting nodes
further apart increases the likelihood that alternate nodes will
be available for failover in the event of a disaster. The architectural
requirements are the same as for an Extended Distance Cluster, with
the additional constraint of a third location for arbitrator node(s)
or quorum server. And as with an Extended Distance Cluster, the
distance separating the nodes in a metropolitan cluster is limited
by the data replication and network technology available. | | | |  | NOTE: While it is possible to configure physical data
replication through products such as HP’s XP Series disk
arrays with Continuous Access XP or Symmetrix EMC SRDF, it is still
necessary to provide for high availability at the local level through
RAID or mirroring. | | | | |
In addition, there is no hard requirement
on how far the third location has to be from the two main data centers.
The third location can be as close as the room next door with its
own power source or can be as far as in a site across town. The
distance between all three locations dictates the level of disaster
tolerance a metropolitan cluster can provide. Metropolitan cluster architecture is implemented through the
following HP products: Metrocluster
with Continuous Access XP Metrocluster with Continuous
Access EVA Metrocluster with EMC SRDF
The above products are described fully in Chapters 3, 4, and
5 of the Designing Disaster Tolerant HA Clusters Using
Metrocluster and Continentalclusters user’s
guide. On-line versions of the above document and other HA documentation are available at http://docs.hp.com -> High Availability. Metropolitan cluster architecture is shown in Figure 1-4 “Metropolitan
Cluster ”. A key difference between extended distance clusters and metropolitan clusters
is the data replication technology used. The Extended Distance Cluster
uses FibreChannel and HP-UX supported software mirroring for data
replication. Metropolitan clusters provide extremely robust hardware-based
data replication available with specific disk arrays based on the
capabilities of the HP StorageWorks Disk Array XP series, StorageWorks
EVA, or the EMC Symmetrix array. Metrocluster
offers a more resilient solution than Extended Distance Cluster,
as it provides full integration between Serviceguard’s application
package and the data replication subsystem. The storage subsystem
is queried to determine the state of the data on the arrays.
Metrocluster
knows that application package data is replicated between two data
centers. It takes advantage of this knowledge to evaluate the status
of the local and remote copies of the data, including whether the
local site holds the primary copy or the secondary copy of data,
whether the local data is consistent or not and whether the local
data is current or not. Depending on the result of this evaluation,
Metrocluster decides if it is safe to start the application package,
whether a resynchronization of data is needed before the package
can start, or whether manual intervention is required to determine
the state of the data before the application package is started.
Metrocluster
allows for customization of the startup behavior for application
packages depending on your requirements, such as data currency or
application availability. This means that by default, Metrocluster
will always prioritize data consistency and data currency over application
availability. If, however, you choose to prioritize availability
over currency, you can configure Metrocluster to start up even when
the state of the data cannot be determined to be fully current (but
the data is consistent). Metrocluster Continuous Access
XP and Metrocluster EMC SRDF support synchronous and asynchronous
replication modes, allowing you to prioritize performance over data
currency between the data centers. Because data replication
and resynchronization are performed by the storage subsystem, Metrocluster
may provide significantly better performance than Extended Distance
Cluster during recovery. Unlike Extended Distance Cluster, Metrocluster
does not require any additional CPU time, which minimizes the impact
on the host. There is little or no lag
time writing to the replica, so the data remains current.
Data can be copied in both directions, so that if the primary site
fails and the replica takes over, data can be copied back to the
primary site when it comes back up.
Disk resynchronization is independent of CPU failure (that is, if
the hosts at the primary site fail but the disk remains up, the
disk knows it does not have to be resynchronized). Metrocluster Continuous
Access XP is supported in a Three Data Center solution, providing
the data consistency of synchronous replication and the capability
of CA journaling replication to protect against local and wide-area
disasters.
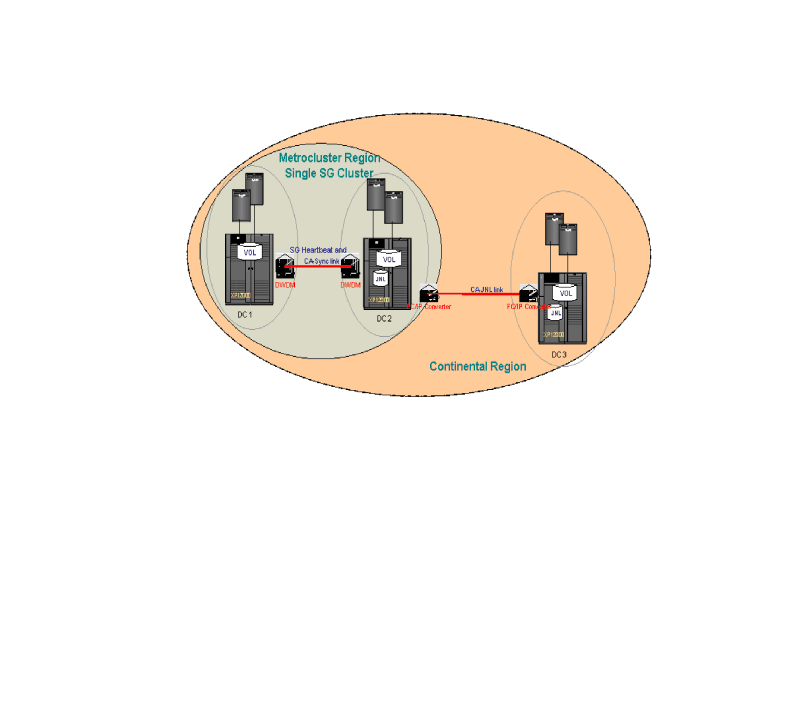
The Three Data Center solution integrates
Serviceguard, Metrocluster Continuous Access XP, Continentalclusters
and HP StorageWorks XP 3DC Data Replication Architecture. This configuration
consists of two Serviceguard clusters. The first cluster, which
is basically a Metrocluster, has two data centers namely Primary
data center (DC1) and Secondary data center (DC2). The second cluster,
a normal Serviceguard cluster, has only one data center namely Third
data center (DC3). Continuous Access synchronous replication is
used within the Metrocluster region and Continuous Access long-distance
journal replication is used between the Metrocluster and recovery
cluster regions. Metrocluster supports Data Replication Storage Failover Preview;
allows you to preview the preparation for the storage of the data
replication environment in a Metrocluster failover or Continentalclusters
recovery. See “Data
Replication Storage Failover Preview”.
Differences
Between Extended Distance Cluster and MetroclusterThe major differences between an Extended
Distance Cluster and a Metrocluster are: The methods used to replicate data between
the storage devices in the two data centers. The two basic methods
available for replicating data between the data centers for HP-UX
clusters are either host-based or storage array-based. Extended
Distance Cluster always uses host-based replication (either MirrorDisk/UX
or Veritas VxVM mirroring). Any (mix of) Serviceguard supported
storage can be implemented in an Extended Distance Cluster. Metrocluster always
uses array-based replication/mirroring, and requires storage from
the same vendor in both data centers (that is, a pair of XPs with Continuous
Access, a pair of Symmetrix arrays with SRDF, or a pair of EVAs
with Continuous Access). Data centers in an Extended
Distance Cluster can span up to 100km, whereas the distance between
data centers in a Metrocluster is defined by the shortest of
the following distances: the
maximum distance that guarantees a network latency of no more than
200ms the maximum distance supported
by the data replication link the maximum supported distance
for DWDM as stated by the provider
In an Extended Distance Cluster,
there is no built-in mechanism for determining the state of the
data being replicated. When an application fails over from one data
center to another, the package is allowed to start up if the volume
group(s) can be activated. A Metrocluster implementation provides
a higher degree of data integrity; that is, the application is only
allowed to start up based on the state of the data and the disk
arrays. Extended Distance Cluster
supports active/active access by implementing SGeRAC, whereas Metrocluster
supports active/standby access. Extended Distance Cluster
disk reads may outperform Metrocluster in normal operations. On
the other hand, Metrocluster data resynchronization and recovery
performance are better than Extended Distance Cluster.
Continental
Cluster | |
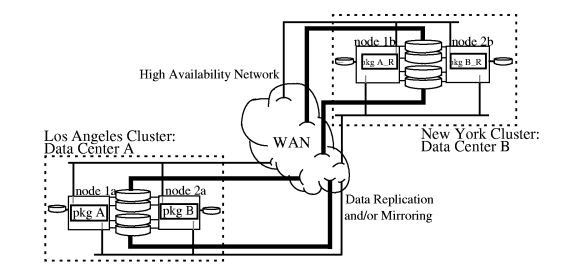
A continental
cluster provides an alternative disaster tolerant solution
in which distinct clusters can be separated
by large distances, with wide area networking used between them.
Continental cluster architecture is implemented via the Continentalclusters
product, described fully in Chapter 2 of the Designing
Disaster Tolerant HA Clusters Using Metrocluster and Continentalclusters user’s
guide. The design is implemented with distinct Serviceguard clusters
that can be located in different geographic areas with the same
or different subnet configuration. In this architecture, each cluster
maintains its own quorum, so an arbitrator data center is not used
for a continental cluster. A continental cluster can use any WAN
connection via a TCP/IP protocol; however, due to data replication
needs, high speed connections such as T1 or T3/E3 leased lines or
switched lines may be required. See Figure 1-5 “Continental
Cluster ”.
| | | | | NOTE: A continental cluster can also be built using clusters
that communicate over shorter distances using a conventional LAN. | | | | |
Continentalclusters provides the flexibility to work with
any data replication mechanism. It provides pre-integrated solutions
that use HP StorageWorks Continuous Access XP, HP StorageWorks Continuous Access
EVA, or EMC Symmetrix Remote Data Facility for data replication
via the Metrocluster products. The points to consider when configuring a continental cluster
over a WAN are: Inter-cluster connections are TCP/IP
based. The physical connection is one or more leased lines
managed by a common carrier. Common carriers cannot guarantee the
same reliability that a dedicated physical cable can. The distance
can introduce a time lag for data replication, which creates an
issue with data currency. This could increase the cost by requiring
higher speed WAN connections to improve data replication performance
and reduce latency. Operational issues, such as working with different
personnel trained on different processes, and conducting failover
rehearsals, are made more difficult the further apart the nodes
are in the cluster.
Benefits
of Continentalclusters Continentalclusters
provides the ability to monitor a high availability cluster and
fail over mission critical applications to another cluster if the
monitored cluster should become unavailable. Continentalclusters supports
mutual recovery, which allows for different critical applications
to be run on each cluster, with each cluster configured to recover
the mission critical applications of the other. You can virtually build data
centers anywhere and still have the data centers provide disaster
tolerance for each other. Since Continentalclusters uses multiple
clusters, theoretically there is no limit to the distance between
the clusters. The distance between the clusters is dictated by the
required rate of data replication to the remote site, level of data
currency, and the quality of networking links between the two data
centers. In addition, inter-cluster
communication can be implemented with either a WAN or LAN topology.
LAN support is advantageous when you have data centers in close
proximity to each other, but do not want the data centers configured
into a single cluster. One example may be when you already have
two Serviceguard clusters close to each other and, for business
reasons, you cannot merge these two clusters into a single cluster.
If you are concerned with one of the centers becoming unavailable,
Continentalclusters can be added to provide disaster tolerance.
Furthermore, Continentalclusters can be implemented with an existing
Serviceguard cluster architecture while keeping both clusters running,
and provide flexibility by supporting disaster recovery failover
between two clusters that are on the same subnet or on different
subnets. You can integrate Continentalclusters
with any storage component of choice that is supported by Serviceguard.
Continentalclusters provides a structure to work with any type of
data replication mechanism. A set of guidelines for integrating
other data replication schemes with Continentalclusters is included
in the Designing Disaster Tolerant HA Clusters Using
Metrocluster and Continentalclusters user’s
guide. Besides selecting your own
storage and data replication solution, you can
also take advantage of the following HP pre-integrated solutions: Storage
subsystems implemented by Metrocluster are also pre-integrated with
Continentalclusters. Continentalclusters uses the same data replication
integration module that Metrocluster implements to check for data
status of the application package before package start up. If Oracle DBMS is used and
logical data replication is the preferred method, depending on the
version, either Oracle 8i Standby or Oracle 9i Data Guard with log
shipping is used to replicate the data between two data centers.
HP provides a supported integration toolkit for Oracle 8i Standby
DB in the Enterprise Cluster Management Toolkit (ECMT).
RAC is supported by Continentalclusters
by integrating it with SGeRAC. In this configuration, multiple nodes
in a single cluster can simultaneously access the database (that
is, nodes in one data center can access the database). If the site
fails, the RAC instances can be recovered at the second site. RAC using Veritas Cluster
Volume Manager (CVM) or Veritas Cluster File
System (CFS) are supported by Continentalclusters by integrating
it with SGeRAC. In this configuration, Oracle RAC instances are
supported in the Continentalclusters environment for physical replication
using HP StorageWorks Continuous Access XP, or EMC Symmetrix Remote
Data Facility (SRDF) using HP SLVM or Veritas Cluster Volume Manager
(CVM) or Cluster File Systems (CFS) from Symantec for volume management. For more information on configuring applications in
CFS/CVM environments in Continentalclusters, refer to the “Configuring Single
Instance Applications in CFS/CVM Environments in Continentalclusters” white
paper on the high availability documentation web site at http://docs.hp.com -> High Availability -> Continentalcluster. Single instance applications
using Veritas Cluster Volume Manager (CVM) or Veritas Cluster File
System (CFS) are supported by Continentalclusters. Configuration of multiple
recovery pairs is allowed. A recovery pair in a continental cluster
consists of two Serviceguard clusters. One functions as a primary
cluster and the other functions as recovery cluster for a specific
application. In the multiple recovery pair configuration, more than
one primary cluster (where the primary packages are running) can
be configured to share the same recovery cluster (where the recovery
package is running). Continentalclusters maximum
node support for Serviceguard/Serviceguard Extension for RAC depends
upon storage management type (that is, LVM, SLVM, CVM, CFS). Failover for Continentalclusters
is semi-automatic. If a data center fails, the administrator is
advised, and is required to take action to bring the application
up on the surviving cluster. Continentalclusters supports
Maintenance
mode; allows a recovery group in maintenance mode to be exempt from
a recovery. Continentalclusters
supports Disaster Recovery (DR) Rehearsal; detects configuration
discrepancies at the recovery cluster and hence improves the “DR
preparedness” of the recovery cluster. Continentalclusters supports Data
Replication Storage Failover Preview; previews the preparation of
the data replication environment for the storage, in a Metrocluster
failover or in Continentalclusters recovery.
Support
for Maintenance Mode in a Continentalclusters Environment | |
On the recovery cluster, recovery groups can be individually
moved into maintenance mode. Continentalclusters does not allow
recovery of those recovery groups that are in maintenance mode,
such as cmrecovercl, or cmrunpkg/cmmodpkg, thus preventing the recovery package startup. At initial configuration, by default, all recovery groups
will be out of maintenance mode. However, when a recovery group
is in maintenance mode the availability of the primary packages
are not impacted that is, the primary package can be started up
or can failover locally at the primary cluster. | | | | | NOTE: Maintenance mode is an optional feature. To enable maintenance
mode, configure a shared disk (non-replicated) with a file system
on all recovery clusters and the Continentalclusters configuration
file should be specified with the CONTINENTAL_CLUSTER_STATE_DIR. | | | | |
A recovery group is moved into maintenance mode, by default,
only if its primary package is running. However, if the site is
unreachable or primary package is shutdown down, you can move a
recovery group into maintenance mode by using the force option. | | | |  | CAUTION: Do not move a recovery group into maintenance mode,
as in the case of the force option, if it is already recovered.
This will prevent subsequent startups of the recovery package. Also,
when used in DR Rehearsals, this will not prevent DR Rehearsal startups
on the production data. | | | | |
For more information on how to setup or use the maintenance
mode feature, see the Designing Disaster Tolerant HA
Clusters Using Metrocluster and Continentalclusters user’s
guide. Support
for Disaster Recovery RehearsalFor a successful recovery in a Continentalclusters environment,
it is critical that the configurations on all the systems, both
primary and recovery cluster, are in sync. The configuration, that is subject to change, after the initial
setup may not be updated on all systems. Hence, this configuration
inconsistency would prevent a recovery attempt on a specific node.
For example, a recovery attempt could fail if the Metrocluster environment
file changed on the primary cluster hosts and was not updated to
the hosts at the recovery cluster. The DR (Disaster Recovery) rehearsal feature “rehearses” the
recovery without impacting the availability of the primary package.
The DR rehearsal detects configuration discrepancies at the recovery
cluster and hence improves the “DR preparedness” of
the recovery cluster. Continentalclusters, for DR Rehearsals, allows recovery groups
to be configured with a special rehearsal package, which is specified
as part of the recovery group definition. The DR Rehearsal starts
the rehearsal package which has a package configuration that is
similar to that of the recovery package and thereby verifying the
recovery environment and procedure. The cmrecovercl option {-r -g <recovery group>} is used to start rehearsal for a recovery group on the
recovery cluster. | | | | | NOTE: DR Rehearsal startup is allowed only if the recovery
group is in maintenance mode. This is a protection which ensures
that while rehearsal is in progress, recovery is prevented. Since
the recovery and rehearsal package have similar package configuration
(that is, share resources), allowing both of them to start will
result in resource collision and impact data integrity. | | | | |
For more information on how to setup and run DR Rehearsal,
see the Designing Disaster Tolerant HA Clusters Using
Metrocluster and Continentalclusters user's guide. Data
Replication Storage Failover PreviewData Replication Storage Failover Preview allows you to preview
the preparation for the storage of the data replication environment
in a Metrocluster failover or Continentalclusters recovery. This
is done with the cmdrprev command, which also verifies the data replication environment
that may cause a Metrocluster failover or Continentalclusters recovery
to fail. For more information on the use of cmdrprev, see the Designing Disaster Tolerant HA Clusters
Using Metrocluster and Continentalclusters user's guide. Continental
Cluster With Cascading Failover | |
A continental cluster with cascading failover uses three main
data centers distributed between a metropolitan cluster, which serves
as a primary cluster, and a standard cluster, which serves as a
recovery cluster. Cascading failover means that applications are configured
to fail over from one data center to another in the primary cluster
and then to a third (recovery) cluster if the entire primary cluster
fails. Data replication also follows the cascading model. Data is
replicated from the primary disk array to the secondary disk array
in the Metrocluster, then replicated to the third disk array in
the Serviceguard recovery cluster. For more information on Cascading Failover configuration,
maintenance, and recovery procedures, refer to the “Cascading
Failover in a Continental Cluster” white paper
on the high availability documentation web site at http://docs.hp.com -> High Availability -> Continentalclusters. Cascading
Failover Using MetroclusterThis configuration uses three data replication groups, two
of which are part of the metropolitan cluster and the other attached
to the recovery cluster. The data centers are distributed as follows: Primary—on the site that
holds the primary copy of the data, located in the primary cluster. Secondary—on the site that holds a remote
mirror copy of the data, located in the primary cluster. Arbitrator or Quorum Server—a third location
that contains the arbitrator nodes, or quorum server located in
the primary cluster. Recovery—on a site that holds a remote
mirror copy of the data, located in the recovery cluster.
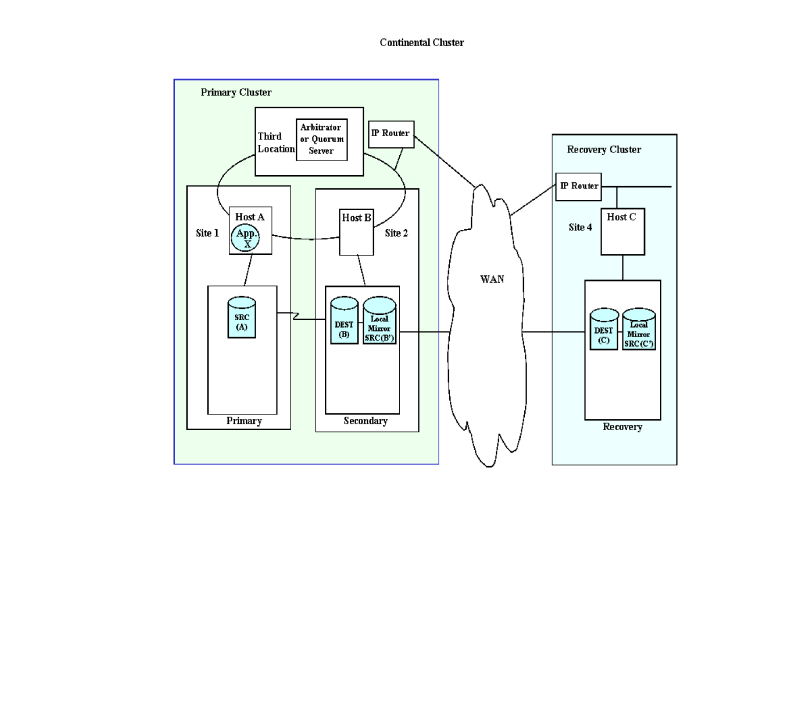
Figure 1-6 “Cascading
Failover Data Center Distribution Using Metrocluster” illustrates data
centers, clusters, and nodes in a cascading failover configuration,
and shows at a high level how the data replication is connected.
The primary cluster consists of two storage devices: a source device
(connected to the primary site and labeled as device A) and a destination
device (connected to the secondary site and labeled as device B).
Data is replicated via storage data replication facilities (for example,
Continuous Access) continuously from source to destination. On site 2, a local mirror is associated with the destination
devices (labeled as device B’). The mirror technology is
storage specific (for example, Business Copy). This local mirror
also acts as a source device for recovery during rolling disasters. A rolling disaster is defined as a
disaster that occurs before the cluster is able to recover from
a non-disastrous failure. An example is a data replication link
that fails, then, as it is being restored and data is being resynchronized,
a disaster causes an entire data center to fail. In the recovery cluster, on site 4, the destination device
(labeled as device C) is connected to the node in the cluster. Data
is periodically replicated to the destination devices via storage
data replication technology. A local mirror of the destination device
is required on site 4 for cases of rolling disasters (labeled as
device C’). Currently, HP StorageWorks XP Continuous Access
and EMC Symmetrix SRDF technologies are supported for the multi-site
disaster tolerant solution. Refer to the Designing Disaster Tolerant HA Clusters
Using Metrocluster and Continentalclusters user’s
guide for details on setting up data replication for this type of
cluster. The next section provides an overview of a three data center
solution, which utilizes both Metrocluster Continuous Access XP
and Continentalclusters environments. Three
Data Center Architecture | |
A Three Data
Center solution integrates Serviceguard, Metrocluster Continuous
Access XP, Continentalclusters and HP StorageWorks XP 3DC Data Replication
Architecture. This configuration protects against local and wide-area
disasters by using both synchronous replication (for data consistency)
and Continuous Access journaling (for long-distance replication). A Three Data Center configuration consists of two Serviceguard
clusters. The first cluster, which is a Metrocluster, has two data
centers that make up the Primary data center (DC1) and Secondary
data center (DC2). The second cluster, typically located at a long
distance from the Metrocluster sites, is the Third Data Center (DC3);
it is configured as a recovery cluster. These two clusters are configured
as a Continental cluster, as shown in Figure 1-7 “Three
Data Center Solution Overview”. HP
XP StorageWorks in a Three Data Center Architecture HP XP StorageWorks Three Data Center architecture enables
data to be replicated over three data centers concurrently using
a combination of Continuous Access Synchronous and Continuous Access
Journaling data replication. In a XP 3DC design there are two available configurations; Multi-Target and Multi-Hop.
The XP 3DC configuration can switch between the Multi-Target and
Multi-Hop configurations at any time during a normal operation.
These configurations may be implemented with either two or three
Continuous Access links between the data centers. When there are two Continuous Access links, one link is a
Continuous Access Sync and the other is a Continuous Access Journal
data replication link. As both supported configurations use two
Continuous Access links, they are also referred to as Multi-Hop-Bi-Link and Multi-Target-Bi-Link. Whether the configuration is multi-hop or multi-target is
determined by two factors: where data enters the system (that is,
where the application is running) and in what direction the data
flows between the XP arrays. In an XP 3DC Multi-Target Bi-Link configuration
the data enters the system on a specific XP array and is replicated
into multiple directions. In an XP 3DC Multi-Hop Bi-Link configuration
the data enters the system on one XP array, is replicated synchronously
to the next XP array, and from there is replicated to the last XP
array. A Three Data Center configuration uses HP StorageWorks 3DC
Data Replication Architecture in order to replicate data over three
data centers, which provides complete data currency and protects
against both local and wide-area disasters. Also, a Three Data Center configuration
concurrently supports short-distance Continuous Access synchronous
replication within the Metrocluster, and long-distance Continuous
Access journal replication between the Metrocluster and recovery
cluster. The Three Data Center Architecture is described fully in Chapter
6, Designing a Disaster Tolerant Solution Using the Three
Data Center Architecture of the Designing
Disaster Tolerant HA Clusters Using Metrocluster and Continentalclusters user’s
guide on the high availability documentation web site at http://docs.hp.com -> High Availability -> Metrocluster
or Continentalcluster. Comparison
of Disaster Tolerant Solutions | |
Table 1-1 “Comparison of Disaster Tolerant Cluster Solutions” summarizes and
compares the disaster tolerant solutions that are currently available: Table 1-1 Comparison of Disaster Tolerant Cluster Solutions | Attributes | Extended Distance Cluster | Extended Distance Cluster for RAC | Metrocluster | Continentalclusters |
|---|
| Key Benefit | Excellent in “normal” operations, and
partial failure. Since all hosts have access to both disks, in a failure
where the node is running and the application is up, but the disk
becomes unavailable, no failover occurs. The node will access the remote
disk to continue processing. | Excellent in “normal” operations,
and partial failure. Active/active configuration provides maximum
data through put and reduces the need for failover (since both data
centers are active, the application is already up on the 2nd site). | Two significant benefits: Provides maximum data protection. State of the data
is determined before application is started.If necessary, data resynchroniza-tion
is performed before application is brought up. Better performance than Extended Distance Cluster
for resync, as replication is done by storage subsystem (no impact
to host).
| Increased data protection by supporting unlimited distance
between data centers (protects against such disasters as those caused
by earthquakes or violent attacks, where an entire area can be disrupted). | | Key Limitation | No ability to check the state of the data before
starting up the application. If the volume group (vg) can be activated, the
application will be started. If mirrors are split or PV links are
down, as long as the vg can be activated, the application will be
started.
Data resynchroniza-tion can have a big impact
on system performance, as this is a host-based solution. | SLVM configuration is limited to 2 nodes
for distances of up to 100km*. CVM or CFS, which are available with Serviceguard Storage Management Suite
Bundles, configuration supports up to 8 nodes. However, 8-node configuration
is limited to a distance of 10km*. Data resynchronization can
have a big impact on system performance as this is a host-based solution. | Specialized storage required. Currently,
XP with continuous access, EVA with continuous access, and EMC’s Symmetrix
with SRDF are supported. | No automatic failover between clusters. | Maximum Distance | * 100 Kilometers | * 100km (maximum is 2 nodes, with either SLVM
or CVM) * 10km (maximum is 2 nodes with SLVM and 8 nodes
with CVM and CFS) | Shortest of the distances between: Cluster network latency (not to exceed 200ms). Data Replication Max Distance. DWDM provider max distance.
| No distance restrictions. | | Data Replication mechanism | Host-based, via MirrorDisk/UX or (Veritas) VxVM. Replication can
affect performance (writes are synchronous). Re-syncs can impact performance (full
re-sync is required in many scenarios that have multiple failures.) | Host-based, via MirrorDisk/UX or (Veritas)
CVM and CFS Replication can impact performance (writes
are synchronous). Re-syncs can impact performance (full re-sync
is required in many scenarios that have multiple failures). | Array-based, via CAXP or CAEVA or EMC
SRDF. Replication and resynchronization performed by
the storage subsystem, so the host does not experience a performance
hit. Incremental re-syncs are done, based on bitmap, minimizing
the need for full re-syncs. | You have a choice of either selecting your own
SG-supported storage and data replication mechanism, or implementing
one of HP’s pre-integrated solutions (including CA XP,
CA EVA, and EMC SRDF for array-based, or Oracle 8i Standby for host
based.) Also, you may choose Oracle 9i Data Guard as a host-based
solution. Contributed (that is, unsupported) integration templates for
Oracle 9i. | | Application Failover | Automatic (no manual intervention required). | Instance is already running at the 2nd
site. | Automatic (no manual intervention required). | Semi-automatic (user must “push
the button” to initiate recovery). Disaster
Recovery (DR) Rehearsal provides a method to identify
and fix configuration inconsistency at the recovery cluster. See “Support
for Maintenance Mode in a Continentalclusters Environment”. “Data
Replication Storage Failover Preview” | | Access Mode | Active/Standby | Active/Active | Active/Standby | Active/Standby | Client Transpar-
ency | Client detects the lost connection. You
must reconnect once the application is recovered at 2nd site. | Client may already have a standby connection
to remote site. | Client detects the lost connection. You
must reconnect once the application is recovered at 2nd site. | You must reconnect once the application
is recovered at 2nd site. | Maximum Cluster Size Allowed | 2 to 16 nodes (up to 4 when using dual
lock disks). | * 2, 4, 6, or 8 nodes with SLVM or CVM with
a maximum distance of 100km. * 2, 4, 6, or 8 nodes to 8 nodes with
CVM with a maximum distance of 10km. | 3 to 16 nodes | Depends storage management type (that
is, LVM, SLVM, CVM, CFS) based on what is being used for Serviceguard/SGeRAC. | Storage | Identical storage is not required (replication
is host-based with either MirrorDisk/UX or VxVM mirroring). | Identical storage is not required (replication
is host-based with either *MirrorDisk/UX or CVM Mirroring). | Identical Storage is required. | Identical storage is required if storage-based mirroring
is used. Identical storage is not required for other
data replication implementations. | Data Replication Link | Dark Fiber | Dark Fiber | Dark Fiber Continuous Access
over IP Continuous Access over ATM | WAN LAN Dark
Fiber (pre-integrated solution) Continuous Access over
IP (pre-integrated solution) Continuous Access over ATM
(pre-integrated solution) | Cluster Network | Single IP subnet | Single IP subnet | Single IP subnet | Two configurations: Single
IP subnet for both clusters (LAN connection between clusters) Two
IP subnets - one per cluster (WAN connection between clusters) | DTS Software/
Licenses Required | SG (no other clustering SW is required). | SG + SGeRAC | SG + Metrocluster Continuous Access
XP or Metrocluster Continuous Access EVA or Metrocluster
EMC SRDF | SG + Continentalclusters
+ (Metrocluster Continuous Access XP or Metrocluster
Continuous Access EVA or Metrocluster
EMC SRDF or Enterprise Cluster Master Toolkit) or Customer-selected
data replication subsystem CC with RAC: SG + SGeRAC
+ CVM/CFS + Continentalclusters |
Table 1-2 Supported Distances Extended Distance Cluster Configurations Cluster type/Volume Manager | Distances up to 10 kilometers | Distances up to 100 kilometers |
|---|
Serviceguard with LVM and MirrorDisk/UX | Supported for clusters with up to 16
nodes with Serviceguard A.11.16 or greater on HP-UX 11i v1, 11i
v2 or 11i v3 | Supported for clusters with up to 16
nodes with Serviceguard A.11.16 or greater on HP-UX 11i v1, 11i
v2 or 11i v3 | Serviceguard with VxVM mirroring | Supported for clusters with up to 16
nodes with Serviceguard A.11.16 or greater on HP-UX 11i v1 or 11i
v2 | Supported for clusters with up to 16
nodes with Serviceguard A.11.16 or greater on HP-UX 11i v1 or 11i
v2 | SGeRAC with SLVM and MirrorDisk/UX | Supported for clusters with 2 nodes with
SGeRAC A.11.16 or greater on HP-UX 11i v1, 11i v2 or 11i v3 | Supported for clusters with 2 nodes with SGeRAC
A.11.16 or greater on HP-UX 11i v1, 11i v2 and 11i v3 | SGeRAC with CVM 3.5 mirroring | Supported for clusters with 2, 4, 6, or
8 nodes with SGeRAC A.11.16 or greater on HP-UX 11i v1 or 11i v2. | Supported for clusters with 2 nodes with SGeRAC
A.11.16 or greater on HP-UX 11i v1 or 11i v2. | Serviceguard A.11.17 with CVM 4.1 or
CFS 4.1 mirroring | Supported for clusters with 2, 4, 6, or
8 nodes with Serviceguard A.11.17 on 11i v2 | Supported for clusters with 2, 4, 6 or
8 nodes with Serviceguard A.11.17 on HP-UX 11i v2 | SGeRAC A.11.17 with CVM 4.1 or CFS 4.1
mirroring | Supported for clusters with 2, 4, 6, or 8 nodes
with Serviceguard A.11.17 on 11i v2. Supported with Oracle RAC 9.2 or
10gR2 | Supported for clusters with 2 nodes with Serviceguard
A.11.17 on HP-UX 11i v2. Supported with Oracle RAC 9.2 or 10gR2 |
|