|
» |
|
|
|
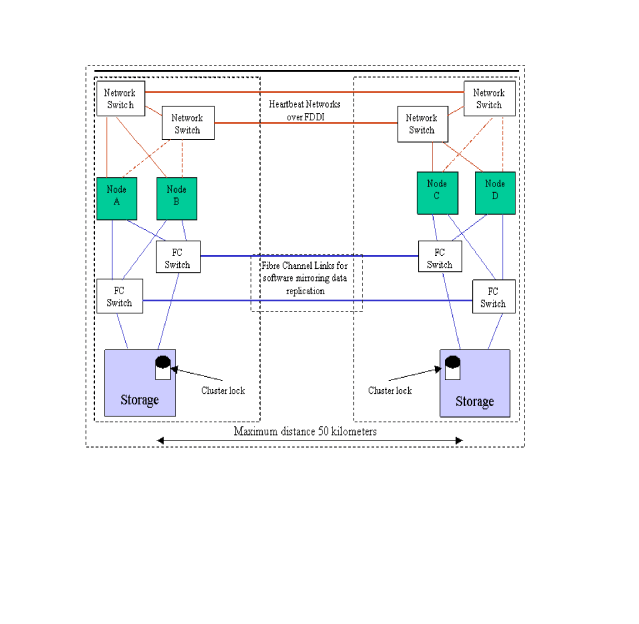
The two data center architecture is based on a standard Serviceguard configuration
with half of the nodes in one data center, and the other half in
another data center. Nodes can be located in separate data centers
in the same building, or even separate buildings within the limits
of FibreChannel technology. Configurations with two data centers
have the following requirements: There must
be an equal number of nodes (1 or 2) in each data center. In order to maintain cluster
quorum after the loss of an entire data center, you must configure
dual cluster lock disks (one in each data center). Since cluster
lock disks are only supported for up to 4 nodes, the cluster can
contain only 2 or 4 nodes. The Serviceguard Quorum Server cannot
be used in place of dual cluster disks, as the Quorum Server must
reside in a third data center. Therefore, a three data center cluster
is a preferable solution, if dual cluster lock disks cannot be used,
or if the cluster must have more than 4 nodes. When using dual cluster
lock disks, there exists a chance of Split Brain Syndrome (where
the nodes in each data center form two separate clusters, each with
exactly one half of the cluster nodes) if all communication between
the two data centers is lost and all nodes remain running.
The
Serviceguard Quorum Server prevents the possibility of split brain,
however the Quorum Server must reside in a third site. Therefore
a three data center cluster is a preferable solution, to prevent
split brain, and the only solution if dual cluster lock disks cannot
be used, or if the cluster must have more than 4 nodes. Two data center configurations
are not supported if SONET is used for the cluster interconnects
between the Primary data centers. To protect against the possibility
of a split cluster inherent when using dual cluster locks, at least
two (three preferred) independent paths between the two data centers
must be used for heartbeat and cluster lock I/O. Specifically, the
path from the first data center to the cluster lock at the second
data center must be different than the path from the second data
center to the cluster lock at the first data center. Preferably,
at least one of the paths for heartbeat traffic should be different
from each of the paths for cluster lock I/O. No routing is allowed for
the networks between data centers. MirrorDisk/UX mirroring for
LVM and VxVM mirroring are supported for clusters of 2 or 4 nodes.
However, the dual cluster lock devices can only be configured in
LVM Volume Groups. There can be separate networking
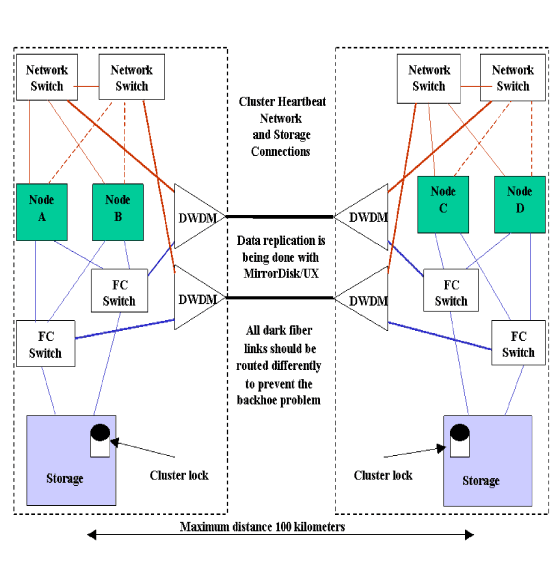
and FibreChannel links between the two data centers, or both networking
and Fibre Channel can go over DWDM links between the two data centers.
See the section below “Network and Data Replication Links
Between the Data Centers” for more details. CVM 3.5 and CVM 4.1 mirroring
is supported for Serviceguard and Extended Cluster for RAC clusters.
However, the dual cluster lock devices must still be configured
in LVM Volume Groups. Since cluster lock disks are only supported
for up to 4 nodes, the cluster can contain only 2 or 4 nodes. MirrorDisk/UX mirroring for
Shared LVM volume groups is supported for Extended Cluster for RAC
clusters containing 2 nodes. FibreChannel Direct Fabric
Attach (DFA) is recommended over FibreChannel Arbitrated loop configurations,
due to the superior performance of DFA, especially as the distance
increases. Therefore Fibre Channel switches are preferred over Fibre
Channel hubs. Any combination of the following
FibreChannel capable disk arrays may be used: HP StorageWorks Virtual
Arrays, HP StorageWorks Disk Array XP, Enterprise Virtual Arrays
(EVA) or EMC Symmetrix Disk Arrays. Refer to the HP Configuration
Guide (available through your HP representative) for
a list of supported FibreChannel hardware. Application data must be
mirrored between the primary data centers. If MirrorDisk/UX is used,
Mirror Write Cache (MWC) must be the Consistency Recovery policy
defined for all mirrored logical volumes. This will allow for resynchronization
of stale extents after a node crash, rather than requiring a full
resynchronization. For SLVM (concurrently activated) volume groups,
Mirror Write Cache must not be defined as the Consistency Recovery
policy for mirrored logical volumes (that is, NOMWC must
be used). This means that a full resynchronization may
be required for shared volume group mirrors after a node crash,
which can have a significant impact on recovery time. To ensure
that the mirror copies reside in different data centers, it is recommended
to configure physical volume groups for the disk devices in each
data center, and to use Group Allocation Policy for all mirrored
logical volumes. Due to the maximum of 3 images
(1 original image plus two mirror copies) allowed in MirrorDisk/UX,
if JBODs are used for application data, only one data center can
contain JBODs while the other data center must contain disk arrays
with hardware mirroring. Note that having three mirror copies will
affect performance on disk writes. VxVM and CVM 3.5 mirroring does
not have a limit on the number of mirror copies, so it is possible
to have JBODS in both data centers, however increasing the number
of mirror copies may adversely affect performance on disk writes. Veritas Volume Manager (VxVM)
from mirroring is supported for distances of up to 100 kilometers
for clusters of 16 nodes. However, VxVM supports up to 10 kilometers
for clusters of 16 nodes on supported versions of HP-UX. Ensure
that the mirror copies reside in different data centers and the
DRL (Dirty Region Logging) feature is used. Raid 5 mirrors are not
supported. It is important to note that the data replication links
between the data centers VxVM can only perform a full resynchronization
(that is, it cannot perform an incremental synchronization) when
recovering from the failure of a mirror copy or loss of connectivity
to a data center. This can have a significant impact on performance
and availability of the cluster if the disk groups are large. Veritas CVM version 3.5 mirroring
is supported for Serviceguard, Serviceguard OPS Edition, or Serviceguard
Extension for RAC clusters (SGeRAC) for distances up to 10 kilometers
for 2, 4, 6, or 8 node clusters, and up to 100 kilometers for 2
node clusters. Since CVM 3.5 does not support multiple heartbeats
and allows only one heartbeat network to be defined for the cluster,
you must make the heartbeat network highly available, using a standby
LAN to provide redundancy for the heartbeat network.
The heartbeat subnet should be a dedicated network, to ensure that
other network traffic will not saturate the heartbeat network. The
CVM Mirror Detachment Policy must be set to “Global”.
CVM 4.1 supports multiple heartbeat subnets. For clusters using Veritas
CVM 3.5, only a single heartbeat subnet is supported, so it is required
to have both Primary and Standby LANs configured for the heartbeat
subnet on all nodes. For SGeRAC clusters, it is recommended to have
an additional network for Oracle RAC cache fusion traffic. It is
acceptable to use a single Standby network to provide backup for
both the heartbeat network and the RAC cache fusion network, however
it can only provide failover capability for one of these networks
at a time. Serviceguard Extension for
Faster Failover (SGeFF) is not supported in a two data center architecture,
which requires a two-node cluster and the use of a quorum server.
For more detailed information on SGeFF, refer to the Serviceguard
Extension for Faster Failover Release Notes and the “
Optimizing Failover Time in a Serviceguard Environment” white
paper.
Two
Data Center FibreChannel Implementations | |
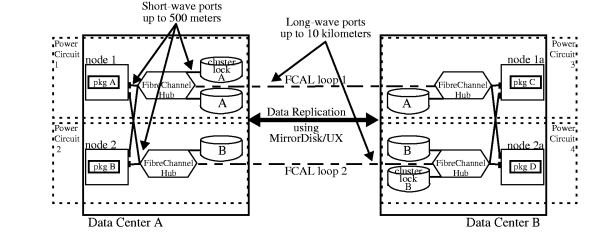
In a two data center configuration, shown in Figure 2-1 “Two
Data Centers with FibreChannel Hubs”, it is required to use a cluster lock
disk, which is only supported for up to 4 nodes. This configuration
can be implemented using any HP-supported FibreChannel devices.
Disks must be available from all nodes using redundant links. Not
all links are shown in Figure 2-1 “Two
Data Centers with FibreChannel Hubs”. The two cluster lock disks should be located on separate FibreChannel loops
to guard against single point of failure. The lock
disks can also be used as data disks. They must be connected to
all nodes using redundant links (not all links are shown in Figure 2-1 “Two
Data Centers with FibreChannel Hubs”). Nodes can connect to disks in the same data center using short
wave ports, and hubs can connect between data centers using long-wave
ports. This gives you a maximum distance of 10 kilometers between
data centers, making it possible to locate data centers in different
buildings. Advantages
and Disadvantages of a Two Data Center Architecture | |
The advantages of a two data center architecture are: Only two data centers are needed, meaning less space
and less coordination between operations staff. No arbitrator nodes are needed. All systems are connected to both copies of data,
so that if a primary disk fails but the primary system stays up,
there is a greater availability because there is no package failover.
The disadvantages of a two data center architecture are: There is a slight chance of
split brain syndrome. Since there are two cluster lock disks, a
split brain syndrome would occur if the following happened simultaneously: The chances are slight, however these events happening at
the same time would result in split brain syndrome and probable
data inconsistency. Planning different physical routes for both
network and data connections or adequately protecting the physical
routes greatly reduces the possibility of split brain syndrome. Software mirroring increases CPU overhead. The cluster must be either two or four nodes with
cluster lock disks. Larger clusters are not supported due to cluster
lock requirements. Although it is a low cost solution, it does require
some additional cost: FibreChannel links are required for
both local and remote connectivity. All systems must be connected to multiple copies
of the data and to both cluster lock disks.
|