| United States-English |
|
|
|
Managing Serviceguard Fifteenth Edition > Chapter 3 Understanding
Serviceguard Software ComponentsHow the Cluster Manager Works |
|
The cluster manager is used to initialize a cluster, to monitor the health of the cluster, to recognize node failure if it should occur, and to regulate the re-formation of the cluster when a node joins or leaves the cluster. The cluster manager operates as a daemon process that runs on each node. During cluster startup and re-formation activities, one node is selected to act as the cluster coordinator. Although all nodes perform some cluster management functions, the cluster coordinator is the central point for inter-node communication. The system administrator sets up cluster configuration parameters and does an initial cluster startup; thereafter, the cluster regulates itself without manual intervention in normal operation. Configuration parameters for the cluster include the cluster name and nodes, networking parameters for the cluster heartbeat, cluster lock information, and timing parameters (discussed in the chapter Chapter 4 “Planning and Documenting an HA Cluster ”). You can set cluster parameters using Serviceguard Manager or by editing the cluster configuration file (see Chapter 5 “Building an HA Cluster Configuration”). The parameters you enter are used to build a binary configuration file which is propagated to all nodes in the cluster. This binary cluster configuration file must be the same on all the nodes in the cluster. Central to the operation of the cluster manager is the sending and receiving of heartbeat messages among the nodes in the cluster. Each node in the cluster exchanges heartbeat messages with the cluster coordinator over each monitored TCP/IP network configured as a heartbeat device. (LAN monitoring is further discussed later in the section “Monitoring LAN Interfaces and Detecting Failure ”) If a cluster node does not receive heartbeat messages from all other cluster nodes within the prescribed time, a cluster re-formation is initiated. At the end of the re-formation, if a new set of nodes form a cluster, that information is passed to the package coordinator (described further in this chapter, in “How the Package Manager Works”). Failover packages that were running on nodes that are no longer in the new cluster are transferred to their adoptive nodes. Note that if there is a transitory loss of heartbeat, the cluster may re-form with the same nodes as before. In such cases, packages do not halt or switch, though the application may experience a slight performance impact during the re-formation. If heartbeat and data are sent over the same LAN subnet, data congestion may cause Serviceguard to miss heartbeats and initiate a cluster re-formation that would not otherwise have been needed. For this reason, HP recommends that you dedicate a LAN for the heartbeat as well as configuring heartbeat over the data network.
Each node sends its heartbeat message at a rate specified by the cluster heartbeat interval. The cluster heartbeat interval is set in the cluster configuration file, which you create as a part of cluster configuration, described fully in Chapter 5 “Building an HA Cluster Configuration”. A manual startup forms a cluster out of all the nodes in the cluster configuration. Manual startup is normally done the first time you bring up the cluster, after cluster-wide maintenance or upgrade, or after reconfiguration. Before startup, the same binary cluster configuration file must exist on all nodes in the cluster. The system administrator starts the cluster in Serviceguard Manager or with the cmruncl command issued from one node. The cmruncl command can only be used when the cluster is not running, that is, when none of the nodes is running the cmcld daemon. During startup, the cluster manager software checks to see if all nodes specified in the startup command are valid members of the cluster, are up and running, are attempting to form a cluster, and can communicate with each other. If they can, then the cluster manager forms the cluster. An automatic cluster startup occurs any time a node reboots and joins the cluster. This can follow the reboot of an individual node, or it may be when all nodes in a cluster have failed, as when there has been an extended power failure and all SPUs went down. Automatic cluster startup will take place if the flag AUTOSTART_CMCLD is set to 1 in the /etc/rc.config.d/cmcluster file. When any node reboots with this parameter set to 1, it will rejoin an existing cluster, or if none exists it will attempt to form a new cluster. A dynamic re-formation is a temporary change in cluster membership that takes place as nodes join or leave a running cluster. Re-formation differs from reconfiguration, which is a permanent modification of the configuration files. Re-formation of the cluster occurs under the following conditions (not a complete list):
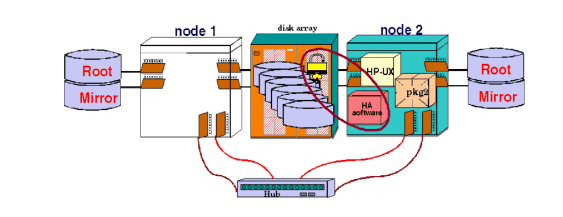
Typically, re-formation results in a cluster with a different composition. The new cluster may contain fewer or more nodes than in the previous incarnation of the cluster. In general, the algorithm for cluster re-formation requires a cluster quorum of a strict majority (that is, more than 50%) of the nodes previously running. If both halves (exactly 50%) of a previously running cluster were allowed to re-form, there would be a split-brain situation in which two instances of the same cluster were running. In a split-brain scenario, different incarnations of an application could end up simultaneously accessing the same disks. One incarnation might well be initiating recovery activity while the other is modifying the state of the disks. Serviceguard’s quorum requirement is designed to prevent a split-brain situation. Although a cluster quorum of more than 50% is generally required, exactly 50% of the previously running nodes may re-form as a new cluster provided that the other 50% of the previously running nodes do not also re-form. This is guaranteed by the use of a tie-breaker to choose between the two equal-sized node groups, allowing one group to form the cluster and forcing the other group to shut down. This tie-breaker is known as a cluster lock. The cluster lock is implemented either by means of a lock disk, lock LUN, or a quorum server. The cluster lock is used as a tie-breaker only for situations in which a running cluster fails and, as Serviceguard attempts to form a new cluster, the cluster is split into two sub-clusters of equal size. Each sub-cluster will attempt to acquire the cluster lock. The sub-cluster which gets the cluster lock will form the new cluster, preventing the possibility of two sub-clusters running at the same time. If the two sub-clusters are of unequal size, the sub-cluster with greater than 50% of the nodes will form the new cluster, and the cluster lock is not used. If you have a two-node cluster, you are required to configure a cluster lock. If communications are lost between these two nodes, the node that obtains the cluster lock will take over the cluster and the other node will halt (system reset). Without a cluster lock, a failure of either node in the cluster will cause the other node, and therefore the cluster, to halt. Note also that if the cluster lock fails during an attempt to acquire it, the cluster will halt. A one-node cluster does not require a cluster lock. A two-node cluster requires a cluster lock. In clusters larger than three nodes, a cluster lock is strongly recommended. If you have a cluster with more than four nodes, use a quorum server; a cluster lock disk is not allowed for clusters of that size. A lock disk or lock LUN can be used for clusters up to and including four nodes in size. A cluster lock disk is a special area on an LVM disk located in a volume group that is shareable by all nodes in the cluster. Similarly, a cluster lock LUN is a small dedicated LUN, connected to all nodes in the cluster, that contains the lock information. In an LVM configuration, a disk used as a lock disk is not dedicated for use as the cluster lock; the disk can be employed as part of a normal volume group with user data on it. A lock LUN, on the other hand, is dedicated to the cluster lock; you cannot store any other data on it. You specify the cluster lock volume group and physical volume, or the cluster lock LUN, in the cluster configuration file. When a node obtains the cluster lock, this area is marked so that other nodes will recognize the lock as “taken.” The operation of the lock disk or lock LUN is shown in Figure 3-2 “Lock Disk or Lock LUN Operation”. Serviceguard periodically checks the health of the lock disk or LUN and writes messages to the syslog file if the device fails the health check. This file should be monitored for early detection of lock disk problems. If you are using a lock disk, you can choose between two lock disk options—a single or dual lock disk—based on the kind of high availability configuration you are building. A single lock disk is recommended where possible. With both single and dual locks, however, it is important that the cluster lock be available even if the power circuit to one node fails; thus, the choice of a lock configuration depends partly on the number of power circuits available. Regardless of your choice, all nodes in the cluster must have access to the cluster lock to maintain high availability.
A single lock disk or lock LUN should be configured on a power circuit separate from that of any node in the cluster. For example, using three power circuits for a two-node cluster is highly recommended, with a separately powered disk or LUN for the cluster lock. In two-node clusters, this single lock device must not share a power circuit with either node, and a lock disk must be an external disk. For three or four node clusters, the disk should not share a power circuit with 50% or more of the nodes. If you are using disks that are internally mounted in the same cabinet as the cluster nodes, then a single lock disk would be a single point of failure, since the loss of power to the node that has the lock disk in its cabinet would also render the cluster lock unavailable. Similarly, in a campus cluster, where the cluster contains nodes running in two separate data centers, a single lock disk would be a single point of failure should the data center it resides in suffer a catastrophic failure. In these two cases only, a dual cluster lock, with two separately powered cluster disks, should be used to eliminate the lock disk as a single point of failure.
For a dual cluster lock, the disks must not share either a power circuit or a node chassis with one another. In this case, if there is a power failure affecting one node and disk, the other node and disk remain available, so cluster re-formation can take place on the remaining node. For a campus cluster, there should be one lock disk in each of the data centers, and all nodes must have access to both lock disks. In the event of a failure of one of the data centers, the nodes in the remaining data center will be able to acquire their local lock disk, allowing them to successfully reform a new cluster.
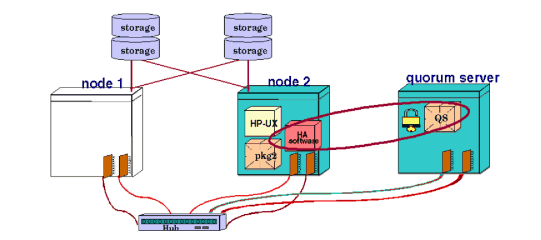
A quorum server can be used in clusters of any size. The quorum server process runs on a machine outside of the cluster for which it is providing quorum services. The quorum server listens to connection requests from the Serviceguard nodes on a known port. The server maintains a special area in memory for each cluster, and when a node obtains the cluster lock, this area is marked so that other nodes will recognize the lock as “taken.” If communications are lost between two equal-sized groups of nodes, the group that obtains the lock from the Quorum Server will take over the cluster and the other nodes will perform a system reset. Without a cluster lock, a failure of either group of nodes will cause the other group, and therefore the cluster, to halt. Note also that if the quorum server is not available when its arbitration services are needed, the cluster will halt. The operation of the quorum server is shown in Figure 3-3 “Quorum Server Operation”. When there is a loss of communication between node 1 and node 2, the quorum server chooses one node (in this example, node 2) to continue running in the cluster. The other node halts. The quorum server runs on a separate system, and can provide quorum services for multiple clusters. Normally, you should not configure a cluster of three or fewer nodes without a cluster lock. In two-node clusters, a cluster lock is required. You may consider using no cluster lock with configurations of three or more nodes, although the decision should be affected by the fact that any cluster may require tie-breaking. For example, if one node in a three-node cluster is removed for maintenance, the cluster reforms as a two-node cluster. If a tie-breaking scenario later occurs due to a node or communication failure, the entire cluster will become unavailable. In a cluster with four or more nodes, you may not need a cluster lock since the chance of the cluster being split into two halves of equal size is very small. However, be sure to configure your cluster to prevent the failure of exactly half the nodes at one time. For example, make sure there is no potential single point of failure such as a single LAN between equal numbers of nodes, or that you don’t have exactly half of the nodes on a single power circuit. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||