| United States-English |
|
|
|
Managing Serviceguard Fifteenth Edition > Chapter 3 Understanding
Serviceguard Software ComponentsServiceguard Architecture |
|
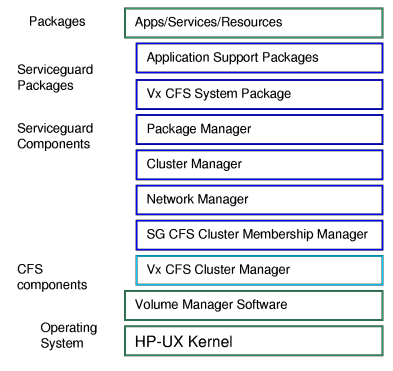
The following figure shows the main software components used by Serviceguard. This chapter discusses these components in some detail.
Serviceguard uses the following daemons:
Each of these daemons logs to the /var/adm/syslog/syslog.log file except for /opt/cmom/lbin/cmomd, which logs to /var/opt/cmom/cmomd.log. The quorum server runs outside the cluster. By default, it logs to the standard output, and it is suggested you redirect output to a file named /var/adm/qs/qs.log. This daemon is used by the Serviceguard commands to gather information from all the nodes within the cluster. It gathers configuration information such as information on networks and volume groups. It also distributes the cluster binary configuration file to all nodes in the cluster. This daemon is started by inetd(1M). There are entries in the /etc/inetd.conf file. This daemon determines cluster membership by sending heartbeat messages to cmcld daemons on other nodes in the Serviceguard cluster. It runs at a real time priority and is locked in memory. The cmcld daemon sets a safety timer in the kernel which is used to detect kernel hangs. If this timer is not reset periodically by cmcld, the kernel will cause a system TOC (Transfer of Control) or INIT, which is an immediate system reset without a graceful shutdown. (This manual normally refers to this event simply as a system reset.) This could occur because cmcld could not communicate with the majority of the cluster’s members, or because cmcld exited unexpectedly, aborted, or was unable to run for a significant amount of time and was unable to update the kernel timer, indicating a kernel hang. Before a system reset resulting from the expiration of the safety timer, messages will be written to /var/adm/syslog/syslog.log and the kernel’s message buffer, and a system dump is performed. The duration of the safety timer depends on the cluster configuration parameters HEARTBEAT_INTERVAL and NODE_TIMEOUT, and also on the characteristics of the cluster configuration, such as whether it uses a quorum server or a cluster lock (and what type of lock) and whether or not standby LANs are configured. (For further discussion, see “What Happens when a Node Times Out”. For advice on setting HEARTBEAT_INTERVAL and NODE_TIMEOUT, see “Cluster Configuration Parameters ”.) cmcld also manages Serviceguard packages, determining where to run them and when to start them.
The cmfileassistd daemon is used by cmcld to manage the files that it needs to read from, and write to, disk. This is to prevent any delays in issuing Input/Output from impacting the timing of cmcld. cmlogd is used by cmcld to write messages to syslog. Any message written to syslog by cmcld it written through cmlogd. This is to prevent any delays in writing to syslog from impacting the timing of cmcld. This daemon is responsible for keeping track of all the volume group(s) that have been made cluster aware. When a volume group is made cluster aware, a cluster node can only activate it in exclusive mode. This prevents the volume group from being activated in write mode by more than one node at a time. This daemon is responsible for providing information about the cluster to clients—external products or tools that depend on knowledge of the state of cluster objects. Clients send queries to the object manager and receive responses from it (this communication is done indirectly, through a Serviceguard API). The queries are decomposed into categories (of classes) which are serviced by various providers. The providers gather data from various sources, including, commonly, the cmclconfd daemons on all connected nodes, returning data to a central assimilation point where it is filtered to meet the needs of a particular query. This daemon is started by inetd(1M). There are entries in the /etc/inetd.conf file. This daemon may not be running on your system; it is used only by clients of the object manager. This daemon collaborates with the SNMP Master Agent to provide instrumentation for the cluster Management Information Base (MIB). The SNMP Master Agent and the cmsnmpd provide notification (traps) for cluster-related events. For example, a trap is sent when the cluster configuration changes, or when a Serviceguard package has failed. You must edit /etc/SnmpAgent.d/snmpd.conf to tell cmsnmpd where to send this information. You must also edit /etc/rc.config.d/cmsnmpagt to auto-start cmsnmpd. Configure cmsnmpd to start before the Serviceguard cluster comes up. For more information, see the cmsnmpd (1m) manpage. This daemon forks and execs any script or processes as required by the cluster daemon, cmcld. There are two type of forks that this daemon carries out:
For services, cmcld monitors the service process and, depending on the number of service retries, cmcld either restarts the service through cmsrvassistd or it causes the package to halt and moves the package to an available alternate node. Using a quorum server is one way to break a tie and establish a quorum when the cluster is re-forming; the other way is to use a cluster lock. See “Cluster Quorum to Prevent Split-Brain Syndrome” and “Cluster Lock”. The quorum server, if used, runs on a system external to the cluster and is started by the system administrator, not by Serviceguard. It is normally started from /etc/inittab with the respawn option, which means that it automatically restarts if it fails or is killed. All members of the cluster initiate and maintain a connection to the quorum server; if it dies, the Serviceguard nodes will detect this and then periodically try to reconnect to it. If there is a cluster re-formation while the quorum server is down and tie-breaking is needed, the re-formation will fail and all the nodes will halt (system reset). For this reason it is important to bring the quorum server back up as soon as possible. For more information about the Quorum Server software and how it works, see the latest version of the HP Serviceguard Quorum Server release notes at http://docs.hp.com -> High Availability -> Quorum Server. This daemon monitors the health of cluster networks, and performs local LAN failover. It also handles the addition and deletion of relocatable package IP addresses for both IPv4 and IPv6. If a lock LUN is being used, cmdisklockd runs on each node in the cluster and is started by cmcld when the node joins the cluster. Each member of the cluster initiates and maintains a connection to the cmdisklockd daemon locally. If the cmdisklockd daemon dies it will be restarted by cmcld and the node will reconnect to it. If there is a cluster reconfiguration while cmdisklockd is down and there is a partition in the cluster that requires tie-breaking, the reconfiguration will fail. Runs on every node on which cmcld is running (though currently not actually used by Serviceguard on HP-UX systems). The HP Serviceguard Storage Management Suite offers additional components for interfacing with the Veritas Cluster File System on some current versions of HP-UX (see “About Veritas CFS and CVM from Symantec”). Documents for the management suite are posted on http://docs.hp.com. Veritas CFS components operate directly over Ethernet networks that connect the nodes within a cluster. Redundant networks are required to avoid single points of failure. The Veritas CFS components are:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||