|
|

The Cisco device can be configured to send SNMP traps when important system events occur such as when an interface starts or stops running, temperature thresholds are crossed, or when authentication failures occur. Traps are translated into Cisco EMF alarms when specific conditions are met, then arise against the appropriate object. Alarms display in the Event Browser and alarm indicators appear in the Map Viewer accordingly. Alarms clear automatically (if the resolution can be clearly detected by the EM) or manually from the Event Browser.
 |
Note For details regarding the Event Browser and Map Viewer, see the Cisco Element Management Framework User Guide. |
In order to receive (SNMP) trap data from the device, the following configurations must be in place:
|
Note For details on configuring the EM to receive trap information from the device, see the Cisco Access Router Manager Installation Guide. |
This chapter contains the following information:
The EM enables you to identify events, or alarms, which occur on the chassis. Within the Map Viewer application, alarm notification occurs on individual objects by the colored status icons next to each managed object name in the left-hand pane or as colored outlines on the chassis map. The following table details all status colors and their related severities.
| Color | Severity of Alarm |
Alarms propagate up the object hierarchy, and are reflected at the highest level. For example, say a critical (red) alarm occurs on an interface. If you do not have the chassis map open, and if the interface text is not apparent, how would you know an alarm had occurred at that level? The answer is: propagation. The interface alarm propagates up the hierarchy to site level. This means that whatever level you are working at, you will see that an alarm has occurred. You can follow the path to discover where the alarm exists.
|
Note Among other features, the Event Manager enables you to set thresholds for certain system parameters and to monitor any supported MIB variables. For further information on the Event Manager tool, see the Cisco Element Management Framework User Guide Release 3.2. |
Complete alarm data is available in the Event Browser application that is part of the Cisco EMF.
Event Browser can be launched in two ways:
Event Browser allows you to view all alarms on all objects. The Query Editor window appears automatically when you launch the Event Browser application. The Query Editor allows you to set up a query (or filter) that allows you to filter all the alarms available and display only the alarms matching the query criteria you selected.
|
Note For further details on using the Event Browser, see the Cisco Element Management Framework User Guide. |
|
Note For detailed information on using the Query Editor, see the Cisco Element Management Framework User Guide. |
When a fault occurs on a managed object in the network, the EM receives immediate notification, through a "trap" that is sent through the network. This trap manifests itself as an alarm through Cisco EMF functionality. The following areas support traps in the EM:
A trap on any of these objects can be one of five severity types:
The following table provides information on traps that result in alarms which raise against the chassis and lists the alarms which automatically clear when a new alarm of that type enters the system.
Table 11-2 Alarms Raised Against Chassis Objects
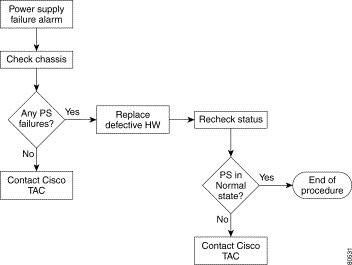
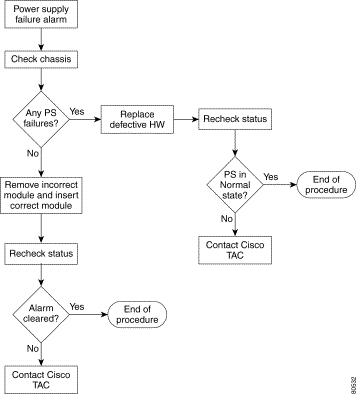
Temperature traps include the affected slot in the alarm description. This functionality will be extended to other environmental alarms in future releases. Similarly, power supply alarms identify the affected power supply, PS0 or PS1.
As can be seen from the table, Cisco EMF alarms may be cleared automatically when other alarms enter the system. The general pattern is that an incoming environmental or power supply alarm clears existing alarms of the same type, no matter the severity. All other alarms must be cleared manually.
The following table provides information on traps that result in alarms raised against interface objects.
The alarm description includes the link interface index.
 |
Caution Care should be taken when using the Syslog alarm feature since there are multiple possible severity levels that can be activated which can result in large trap volumes. This can affect performance (for example, when opening an Event Browser) and hinder effective monitoring because of the high numbers of alarms that will be raised. It is advised that only the high severity traps are monitored by default, switching on others if more information is required. Cisco EMF provides the capabilities to customize the alarm data that displays in the Event Browser through queries. |
|
Note For additional information on customizing the alarm data which displays in the Event Browser, see the Cisco Element Management Framework User Guide. |
Like the other supported alarms, Cisco IOS can be configured to send Syslog traps to a designated server. There are eight levels of Syslog information which are mapped into four categories of Cisco EMF alarm severity. Syslog specific data is inserted into the Message portion of the Cisco EMF alarm. In all cases, alarms are raised against the Chassis object. There is no automatic clearing of Syslog Alarms.
The following table summarizes the severity mappings between traps and alarms.
Syslog alarms have a Description in the Event Browser application in the following format:
"Asserted [<clogHistMsgText>] by facility [<clogHistFacility>], Message name [<clogHistMsgName>]"
An example Syslog Alarm Description is:
"Asserted [Critical/high priority process ATM Periodic may not dismiss.] by facility [SCHED], Message name [EDISMSCRIT]"
Corresponding syslog events associated with syslog traps display in the SysLog Messages window. For further information, see the "System Log" section.
When a change is made to the configuration of a Cisco router, Cisco IOS can send a "configuration management event trap". This trap is translated into a Cisco EMF alarm with the following description:
"Config Change, Command Source: <ccmHistoryEventCommandSource>, Config Source: < ccmHistoryEventConfigSource>, Config Destination: < ccmHistoryEventConfigDestination>"
An example Configuration Management Event Alarm Description is:
"Config Change, Command Source: commandLine, Config Source: running, Config Destination: commandSource"
This would be received when a "show running config" command was issued.
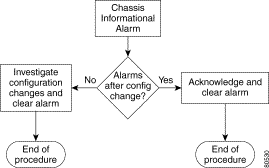
Alarms are raised against the Chassis object with Informational Severity. There is no automatic clearing.
Heartbeat polling begins automatically when you commission a chassis. There are two types of heartbeat polling: Connectivity Management and Operational Status Polling.
The Heartbeat Polling section covers the following areas:
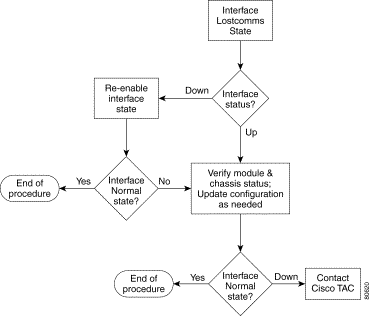
The EM polls the management interface on the chassis every 60 seconds to determine network connectivity. If management connectivity is lost, the chassis enters into a lost comms state and this state ripples down to all subchassis objects. A critical lost comms alarm is raised against the chassis. The chassis continues to poll. If it detects re-establishment, it puts the chassis state back to the relevant state and this state ripples down to all subchassis objects as well. An alarm of Normal severity is then raised which clears the critical lost comms alarm.
Operational status polling occurs at module and interface levels. Each module and interface object polls for its own operational status. Modules poll every 5 minutes and interfaces poll every fifteen minutes. If a module detects that its operational status is down, it enters the Errored state and raises a Major alarm. The Errored state does not propagate down to PVCs, SPVCs, and sub-interfaces. If an interface goes down, you can see this in the Generic Interface Status window. In the Errored state the module or interface will continue to poll if the condition has been rectified. If it detects that the operational state has moved back to normal then the object will transition into the Normal state and raise an alarm of Normal severity which will clear the previous Major alarm.
You can stop heartbeat polling on an individual interface by decommissioning the interface. You might want to do this if you have interfaces that are not yet connected or live. For example, when you commission a chassis, subchassis discovery is automatically initiated. If you have pre-deployed interfaces that are not yet live, these are discovered and put into an Errored state, after no connectivity is detected on them. An alarm is also raised on the interface. To correct this situation, you need to decommission the inactive interface and clear the alarm manually.
Heartbeat polling is unaffected if an object is in the performance logging state.
This section describes troubleshooting techniques to help identify and resolve specific system alarms. If you are unable to resolve an alarm on your own, the Cisco Technical Assistance Center is available to help. For the Cisco Technical Assistance Center contact information, see the "Technical Assistance Center" section.
The Troubleshooting Alarms section is broken down into the following alarm categories:
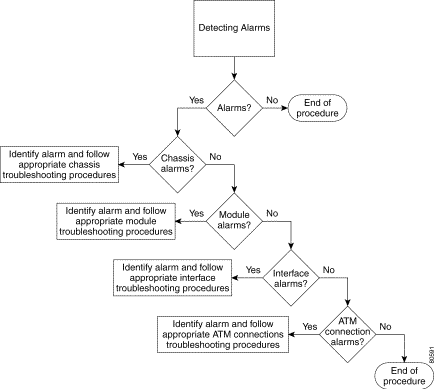
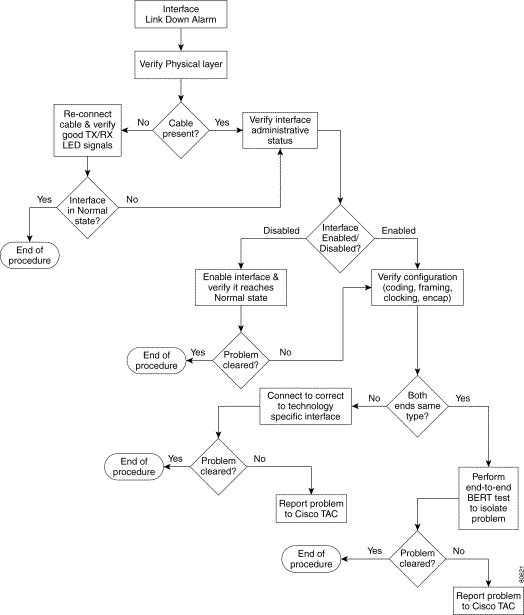
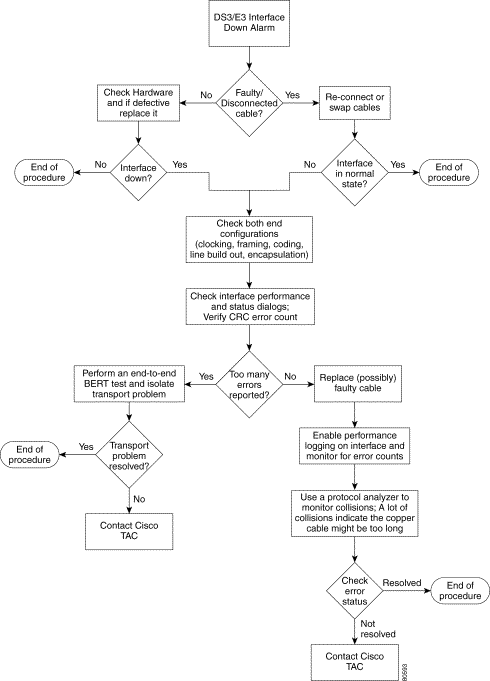
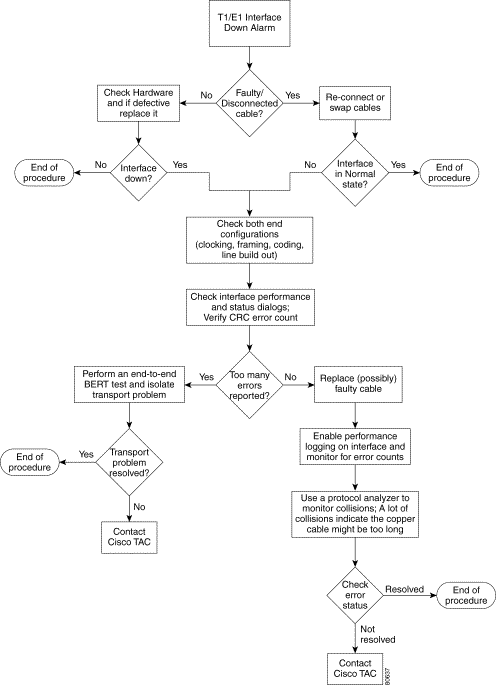
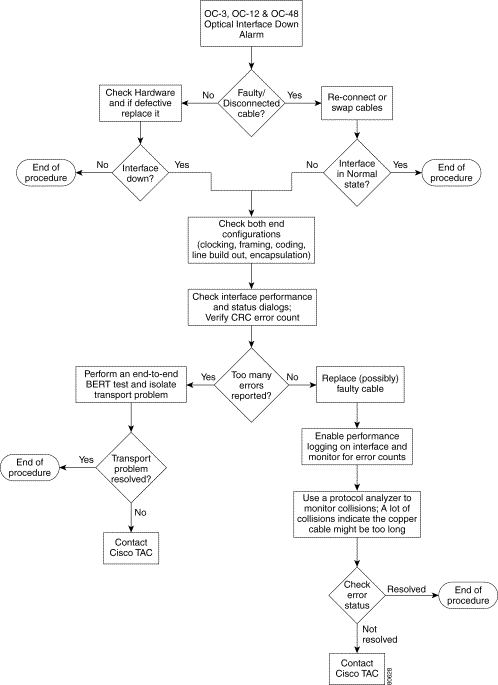
The following figure provides the basic alarm detection flow and points you to the proper section.
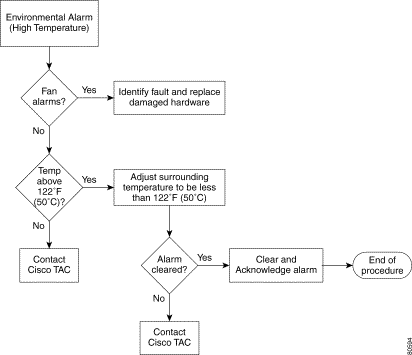
Troubleshooting assistance is provided for the following environmental alarms:
Troubleshooting assistance is provided for the following chassis alarms:
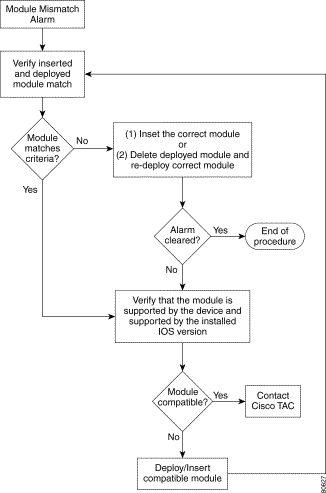
Troubleshooting assistance is provided for the following module alarms:
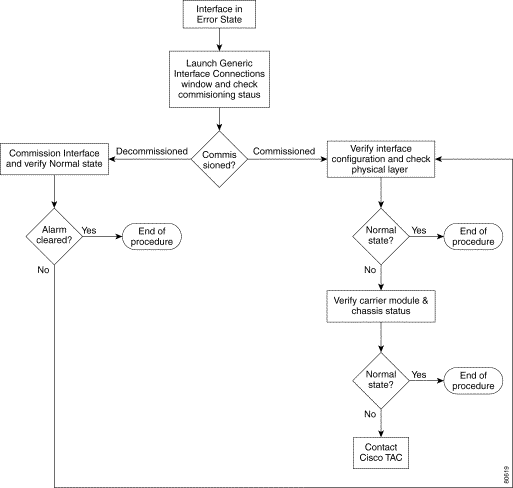
Troubleshooting assistance is provided for the following interface alarms:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Posted: Wed Feb 12 09:54:36 PST 2003
All contents are Copyright © 1992--2002 Cisco Systems, Inc. All rights reserved.
Important Notices and Privacy Statement.