|
|

Failover provides a mechanism for LocalDirector to be redundant by allowing two identical units to serve the same functionality. One LocalDirector unit is considered the "primary" unit while the other is considered the "secondary" unit (determined by the failover cable). The primary unit is also the active unit by default, and it performs normal network functions while the backup unit (standby) only monitors, ready to take control should the active unit fail.
The two units must be running the same version of software. Configuration replication (version 1.6 or later) will occur under the following conditions:
The active unit uses the system IP address and the MAC address of the primary unit. The standby unit uses the failover IP address and the secondary MAC address. Because the active unit uses the same IP and MAC addresses (regardless of which physical unit it is), no ARP entries need to change or timeout anywhere on the network.
Failover monitors failover communications, the power status of the other unit, and hello packets that are received on each interface. A failure of any of these parameters on the active unit will cause the standby unit to take active control. The standby unit assumes the active role using the system IP address and the primary MAC addresses. When a failure or switch occurs SYSLOG messages are generated indicating the cause of the failure.
To take a unit out of the "failed" state, cycle the power or use the failover reset command. The failover reset command will also clear timers and counters for the LocalDirector unit. When a failed primary unit is fixed and brought back on line it will not automatically resume as the active unit. This ensures that active control will not resume on a unit that could immediately enter a failed state again. However, if a failure is due to a lost signal on a network interface card, failover will "auto-recover" when the network is available again.
Use the failover active command to initiate a failover switch from the standby unit, or the no failover active command from the active unit to initiate a failover switch. You can use this feature to return a failed unit to service, or to force an active unit offline for maintenance. Because the standby unit does not keep state information on each connection, all active connections will be dropped and must be re-established by the clients.
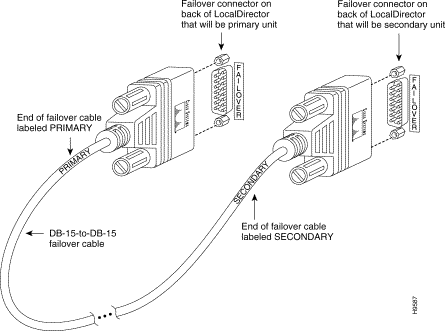
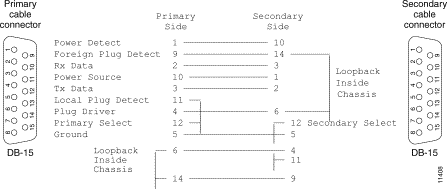
Attach the end of the cable labeled "Primary" to the unit that will be the primary unit (the failover cable is shown in Figure 5-4). Attach the other end to the secondary unit. Connect an interface on both LocalDirector units to the hub or switch that goes to the outside network, and connect another interface on both LocalDirector units to the hub or switch that connects to your servers.
Use the failover ip address command to set the IP address for the standby unit, and use the replicate command to set stateful failover. A third interface can be dedicated to stateful failover. See the failover and replicate command descriptions in Chapter 6, "Command Reference" for more information.
The show failover command indicates the status of the connection and which unit is active. See the "Show Failover Output" section for more information about this command. The show ip address command shows the current IP address of the unit. If the unit is active the system IP address is displayed, and if the unit is standby the failover IP address is displayed.
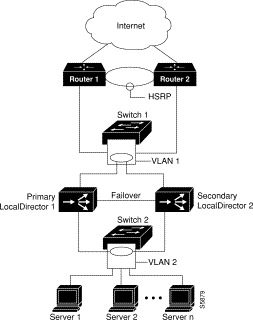
Figure 5-1 shows a basic failover implementation. Note that the third interface on the LocalDirector 410 is not being used. In this example, the no interface 2 command must be used to disable the interface, otherwise the unit will be seen as failed.
Figure 5-2 shows stateful failover with a dedicated interface.
Use the replicate interface command to identify the dedicated interface as follows:
replicate interface 3
The ports on the 4-port interface are numbered 0-3, so this would dedicate the bottom port on the card to stateful failover.
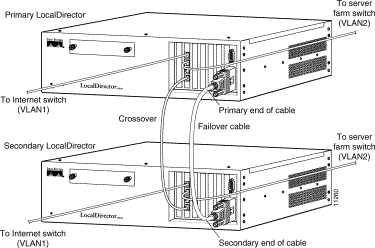
Figure 5-3 shows a LocalDirector configuration that is fault-tolerant.
If a failure is due to a condition other than a loss of power on the other unit, failover will begin a series of tests to determine which unit is failed. This series of tests will begin when hello messages are not heard for two consecutive 15-second intervals. Hello messages are sent over both network interfaces and the serial cable every 5 seconds.
These tests generate network traffic in order to determine which (if either) unit is failed. At the start of each test, each unit clears its received packet count for its interfaces. At the conclusion of each test, each unit looks to see if it has received any traffic. If it has, the interface is considered operational. If one unit receives traffic for a test and the other unit does not, the unit that received no traffic is considered failed. If neither unit has received traffic, they go to the next test.
Failover messages always have a SYSLOG priority level of 2, which indicates a critical condition. All failover SYSLOG messages are also sent as SNMP SYSLOG traps.
To receive SNMP SYSLOG traps (SNMP failover traps), you must configure the SNMP agent to send SNMP traps to SNMP management stations, define a SYSLOG host, and also have compiled the Cisco SYSLOG MIB into your SNMP management station. See the snmp-server and syslog command descriptions in Chapter 6, "Command Reference" for more information.
The SYSLOG messages sent to record failover events are listed in Appendix A, "Troubleshooting" in the "Failover Messages" section.
The following is the normal output of the show failover command. Note that the IP address that each unit is using is displayed.
ld-prim(config)# show failover
Failover On
Cable status: Normal
This host: Primary - Active
Active time: 6885 (sec)
Interface 0 (192.168.89.1): Normal
Interface 1 (192.168.89.1): Normal
Other host: Secondary - Standby
Active time: 0 (sec)
Interface 0 (192.168.89.2): Normal
Interface 1 (192.168.89.2): Normal
Failover will not start monitoring the network interfaces until it has heard the second hello packet from the other unit on that interface. This should happen within 30 to 60 seconds.
If the unit is attached to a switch running spanning tree, this will take twice the forward delay time configured in the switch (typically 15 seconds) plus 30 seconds. This is because at bootup (and immediately following a failover event) the network switch will detect a temporary bridge loop. When this bridge loop is detected, the switch will stop forwarding packets for the duration of the forwarding delay time. It will then enter "listen" mode for an additional forward delay time during which time the switch is listening for bridge loops but still not forwarding traffic (and thus not forwarding failover hello packets).
After twice the forward delay time (30 seconds) traffic should resume. The LocalDirector will remain in "waiting" mode until it hears two hello packets (1 every 15 seconds for a total of 30 seconds). During this time the LocalDirector is passing traffic, and it will not fail the unit based on not hearing the hello packets. All other failover monitoring is still occurring (power, interface, and failover cable hello).
The following example shows the output if failover has not started monitoring the network interfaces:
ld-prim(config)# show failover
Failover On
Cable status: Normal
This host: Primary - Active
Active time: 6930 (sec)
Interface 0 (192.168.89.1): Normal (Waiting)
Interface 1 (192.168.89.1): Normal (Waiting)
Other host: Secondary - Standby
Active time: 15 (sec)
Interface 0 (192.168.89.2): Normal (Waiting)
Interface 1 (192.168.89.2): Normal (Waiting)
The following example shows that a failure has been detected. Note that interface 1 on the primary unit is the source of the failure. The units are back in waiting mode because of the failure. The failed unit has removed itself from the network (interfaces are down) and it is no longer sending hello packets on the network. The active unit will remain in the waiting state until the failed unit is replaced and failover communications start again.
ld-prim(config)# show failover
Failover On
Cable status: Normal
This host: Primary - Standby (Failed)
Active time: 7140 (sec)
Interface 0 (192.168.89.2): Normal (Waiting)
Interface 1 (192.168.89.2): Failed (Waiting)
Other host: Secondary - Active
Active time: 30 (sec)
Interface 0 (192.168.89.1): Normal (Waiting)
Interface 1 (192.168.89.1): Normal (Waiting)
This section contains some frequently asked questions about the failover feature.
|
|