|
|

One of the most important aspects of network management is the ability to identify events on the system and to take action to resolve them quickly and efficiently. For example, there may be a power supply fault in a chassis that would require an engineer to be sent out to rectify the fault. This fault is critical to the running of the network and would need prompt attention.
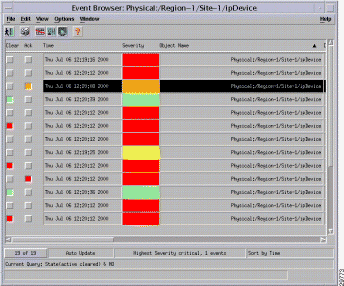
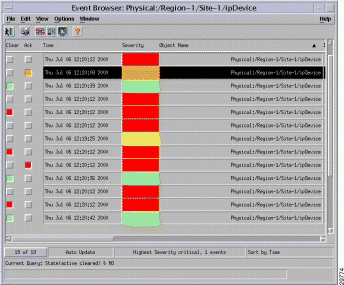
In CMNM, when a condition (fault) occurs on a managed object in the network, the system is notified immediately. This notification is shown as an event or alarm and can be viewed with the CEMF Event Browser. The Event Browser is opened from the CEMF Launchpad. A screen similar to Figure 8-1 is displayed.
The Event Browser provides a tool to manage the network efficiently; you can list, query, and sort all or some events according to how you want to manage the network. Services can be invoked on events so that faults can be attended to from the screen that shows the event.
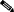 |
Note You can also view events on CEMF maps, however, only the most severe fault on a managed object is shown on the map icon. |
You can have more than one Event Browser session open at any one time. Each Event Browser session can have different queries specified. All users can see any event. In the Event Browser window, you can acknowledge that a particular event is one that you are going to deal with, and all other users then see that the event is being handled. When the event is cleared, it is shown in the Event Browser window, so other users know that the event requires no further attention.
When an event is received, it is shown as active and unacknowledged (the two indicators are shown as grey). At this stage, no one has taken responsibility to deal with it. You may not want to view all events on the system, so a query can be set up using the CEMF Query Editor to view specific events.
A CEMF event represents a notification from a managed entity that a certain condition has just occurred. These events usually represent error conditions on managed elements.
Each event is associated with the object for which it provides notification. Therefore, an object can have a number of events related to itself at any one time.
The default information stored against all CEMF events includes:
Descriptions of event state and severity are given below.
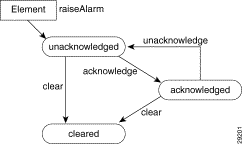
The event state indicates whether the event is acknowledged or unacknowledged and active or cleared.
When a new event is received by the system, its state is active/unacknowledged. You may acknowledge the event, which indicates to other users that the event is being handled. Once the event has been dealt with, you may clear the event. When you cannot clear an event due to an existing problem, it can be returned to the unacknowledged state and subsequently acknowledged or cleared by another user.
When an event is in the unacknowledged or acknowledged state, it is counted as being active and, therefore, it is still affecting the state of the object upon which it was raised.
After events are cleared, they continue to be stored within the system for a configurable amount of time to maintain an event history for an element. These events can be viewed and manipulated in the same way as any other event.
Each event has a severity, indicating the importance of the event, and is identified with a corresponding color as shown in Table 8-1.
The source domain identifies where an event was generated. In CEMF, the source domain can be one of the following:
This is the management domain of SNMP trap information. The SNMP MIB specific information typically defines the equipment type generating a trap.
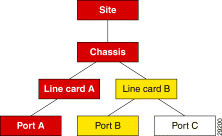
In order to make the identification of potential problems easy, CEMF propagates the alarm state of objects upwards through each object view.
In real terms, this means that if an object receives an event, then not only does it change color to reflect its new state, but all parent objects within a view, also change color, to reflect the most severe alarm on any of the children. The example in the following diagram shows a typical physical view of the network. The line cards are contained within the chassis, the chassis within a bay, the bay within a site, and so on.
If a minor alarm was received on Port B, then it, and all of the objects up to the region, turn yellow to indicate a potential minor problem, as illustrated in Figure 8-3.
If a critical alarm was then received on Port A, then it, and all of the objects up to the region, turn red to indicate a potential critical problem, as illustrated in Figure 8-4.
If the critical alarm is then cleared, the icons return to yellow.
CMNM provides fault management of the Cisco MGC node, including the Cisco MGC host, the
Cisco SLT, and the LAN switch. Traps generated by these elements are displayed within the CEMF system. When an alarm is received for an object, a pop-up balloon on Map Viewer shows the number and severity of the alarms for that object. The balloon color indicates the severity of the most severe alarms. The fault management features of the Cisco MGC allow you to view, acknowledge, and clear alarms for a given object.
CMNM handles numerous connectivity traps. CMNM defines the necessary trap mappings and containment trees, allowing CMNM to delegate all traps relating to the connectivity network to the nodes that represent it. You can display these alarms in the Event Browser.
When the Cisco MGC host detects a problem with one of its logical connections, it generates a trap. CMNM receives these traps and maps them to the object that represents that logical connection. For example, if CMNM receives a trap that the link to a media gateway is down, CMNM maps that trap to the object that represents the media gateway link and displays an alarm icon on the Map Viewer.
CMNM maps the incoming traps to alarms. However, not all traps are mapped to alarms. CMNM filters out duplicate traps from a network element. It also filters out traps from network elements that report a problem, and then reports within a few seconds (up to 6) when the problem is resolved. That is, the
Cisco MGC automatically clears existing alarms when a network element reports that an alarm condition is no longer present. This reduces the number of unnecessary alarms displayed in the Event Browser. You cannot configure when an alarm should be automatically cleared.
CMNM periodically polls each managed object (the Cisco MGC host, Cisco SLT, Cisco MGX 8260, LAN switch, and BAMS) to ensure that the device is still reachable using SNMP. If the device is not reachable, it is indicated by annotation on the map display and an alarm is generated. In addition the object is placed into the CEMF errored state.
After the object loses connectivity, CEMF continues to poll the object until it can be reached. Once connectivity is reestablished, the alarm is cleared and the annotation on Map Viewer is removed. In addition the object is returned to the CEMF normal state.
CMNM also displays the status of the Cisco MGC host connectivity network. This includes the logical connections from the active Cisco MGC host to the:
The logical connections from the active Cisco MGC host are shown as subnodes under the common Cisco MGC host object. If the standby Cisco MGC host is not processing calls, only the network connectivity of the active Cisco MGC host is shown.
By default, each CEMF object can contain only a single IP address. For example, when the user deploys a Cisco SLT, the user can specify only a single IP address. CEMF uses this IP address for all management transactions including presence polling and performance polling. In addition, the IP address is used to map incoming faults to the CEMF object. When a trap arrives from the network element, CEMF matches the IP address of the trap sender to the IP address of an object in the database.
In reality, a physical device may have more than one IP address. Traps may come from any interface on the device. Since CEMF/CMNM is aware of only a single IP address, traps received from an alternate interface might be dropped.
Any interface on the device may go down (either operationally or administratively). If the management interface goes down, all SNMP-based operations fail. That is, not all SNMP queries are completed, nor does status polling or performance polling function. CMNM is designed to avoid these situations by using trap proxies and IP address failover, which are described in the following sections.
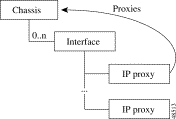
To prevent the dropping of traps received from an alternate interface, CMNM models each IP address on the device. When a trap comes in on any interface, it is mapped to its logical chassis object.
During auto-discovery, the RFC1213-MIB.ipAddrTable is queried. Each IP address is deployed as a child of its corresponding interface (see Figure 8-5).
The IP Proxy object acts as stand-in for its network element. When a trap is received from the network element, it is bound for one of the IP proxy objects. Internally, CMNM redirects the trap to the proxied object. For example, all traps received on any Cisco SLT interface are redirected to the SLT Chassis object. In this way all traps on all interfaces are shown, logically, on the object that represents that device.
Since CMNM models each IP Address on the device, it is possible to implement an IP address failover mechanism. When a device is first deployed, the user specifies an IP address on the management interface. If the management interface goes down or the management addresses becomes unreachable, CMNM automatically fails over to another IP address. When the management interface/IP address is restored, CMNM resumes using it for all device communication.
CMNM periodically polls each IP address to ensure that that route is reachable via SNMP. If the management IP address becomes unreachable, CMNM searches for a new IP address using the following rules:
When CMNM searches for an alternate interface, it starts with the Ethernet interfaces. If none are available, it attempts to use any other available interfaces (for example TDM interfaces on a Cisco SLT). Once a usable interface is found, CMNM must decide which IP address to use on that interface. Because there is no way to distinguish IP addresses, CMNM simply uses the first available IP address child of the interface. Technically this should be the first IP address defined in the ipAddrTable for that interface.
If no IP addresses are available (they are all unreachable), CMNM raises a critical alarm on the chassis. This alarm indicates that the device is truly unreachable and requires immediate operator attention. Once at least one IP address is restored, the alarm is automatically cleared.
CMNM periodically polls each IP address to see if is reachable via SNMP by sending an SNMP get message to the IP address object, retrieving the value of the SNMP:RFC1213-MIB.sysUpTime attribute.
If the attribute is available, it assumed the IP address is reachable. Otherwise, the IP address is unreachable and is transitioned into the unreachable state. Once connectivity is reestablished, the object is transitioned back into the normal state.
Besides performing status polling on each IP address object, CMNM also performs status polling on various other components. These include:
CMNM performs status polling to reflect the state of each network interface. Depending on the operational and administrative status of the interface, the object representing the network interface is transitioned into different state as indicated in Table 8-2.
Note that the chassis is queried for the state of its interfaces. That is, the status of the interface reported by CMNM is identical to the status reported by the chassis on its current management IP address. However, the status of each interface is reported by the chassis via that object's specific IP addresses. In this way CMNM can better reflect the true health of the chassis.
When a network interface goes down, the device sends a link down trap to CMNM. When CMNM detects this trap, it transitions the object representing that interface to the down state. To handle the case where CMNM may have missed a trap, the status polling mechanism raises an alarm if it detects that the interface is down. When the interface comes back up, the device raises a link-up trap. If CMNM detects this trap, it transitions the interface back into the normal state. If CMNM missed this trap, the next status poll will detect that the interface is back up. Internally, CMNM transitions the interface back to the normal state and clears the appropriate alarms on the object.
When an interface goes down, all IP address on that interface become unreachable. Since, during the next status-poll cycle, all IP addresses on that interface will fail, CMNM automatically transitions all of the child IP address objects into the unreachable state. Doing so prevents a potential flood of alarms.
CMNM periodically checks the status of each MGC Node device. The attribute SNMP:CISCO-TRANSPATH-MIB.tpCompOpStatus is retrieved and its value is used to determine the required state of the object as indicated in Table 8-3
CMNM periodically checks the status of each BAMS device. The SNMP:ACECOMM-BAMS-SYSPARM-MIB.sysStatus attribute is retrieved and its value is used to determine the required state of the object as indicated in Table 8-4
CMNM allows the user to configure status polling frequencies for each type of device. For example, the user can set the status polling frequency for Cisco SLT devices to be different than that of the
Cisco MGC host devices.
The status polling frequency controls the rate at which the IP Address objects are polled. In addition, this frequency is used to determine the rate at which the status of the various devices is queried.
Given the polling interval, all objects are polled at some point in that interval. For example, if the status polling frequency for a Cisco SLT is set to 5 minutes, all IP address objects on all Cisco SLTs are polled at some point during a five-minute interval.
Besides the periodic polling, CMNM provides a mechanism to check the SNMP visibility of a device or set of devices. You can click a button that causes a manual SNMP poll to occur. The results of this manual poll are displayed.
The following sections outline the southbound traps that are handled from the network elements. CMNM does not handle every possible trap that can be generated from each of the network elements, only those traps that are used for management of the devices.
CMNM converts traps to alarms which are displayed in the Event Browser. For the Cisco SLT, the Catalyst LAN switches, and the Cisco MGX 8260, each trap has a corresponding CMNM alarm. For example, the linkDown trap from the Cisco SLT corresponds to the "Link down" Event Description in the CMNM Event Browser. For the BAMS and the Cisco MGC, the trap serves as an envelope that can carry any one of numerous alarm messages.
In addition to device-specific traps, CMNM generates internal alarms. "BAMS, Cisco MGC, and CMNM Messages" provides an explanation of these internal messages and references to documentation on alarm messages from the BAMS and the Cisco MGC.
All BAMS alarms are carried on a single trap, the AlarmTrap.
See "BAMS, Cisco MGC, and CMNM Messages" for references to documentation on BAMS alarms.
Table 8-7 Catalyst 5500 Alarms
|
Table 8-8 Catalyst 2900XL Alarms
|
Table 8-9 Catalyst 2900 Alarms
|
CMNM handles the traps in Table 8-10 from the Cisco MGC hosts. Each trap is used as an envelope for alarms of that type. See "BAMS, Cisco MGC, and CMNM Messages" for references to documentation on MGC alarms.
CMNM traps application-related events that occur on the Cisco MGC hosts or the BAMS.
Table 8-11 Resource Alarms
|
Table 8-12 Cisco MGX 8260 Traps and Alarms
|
CMNM does not provide any guarantee that it received a trap from the southbound systems or network elements. CMNM does not perform any negotiation with the network elements to detect or recover lost traps. However, you can perform presence polling to display trap data that may have been lost.
CMNM can clear alarms using CEMF Clear Correlation files. On receipt of an incoming clear alarm, the rules defined in these files indicate which active alarms on a given object should be cleared. For example, a link-up alarm clears a link-down alarm, a process normal alarm clears a process error alarm, and a communication success alarm clears a communication failure alarm.
A sample Clear Correlation file is:
INCOMING_ALARM_CLASS linkUpAlarmClass
ALARM_CLASS_TO_CLEAR linkDownAlarmClass
When a clear condition is received, the cleared alarm is automatically removed from the appropriate screens and the clear alarm is forwarded to northbound systems like any other alarm.
The following sections map the alarms to their clear conditions for each Cisco MGC node device.
Table 8-14 maps the alarms to their clear conditions for the Cisco MGC host.
Table 8-15 maps the alarms to their clear conditions for the Cisco SLT.
Table 8-16 maps the alarms to their clear conditions for the LAN switch.
Table 8-17 maps the alarms to their clear conditions for the CIAgent.
Table 8-17 CIAgent Clear Correlation
|
|
1 The varbind criaAppName in the trap/clear must match. 2 The varbind siFsMonName in the trap/clear must match. 3 The varbind siFsMonName in the trap/clear must match. |
CMNM provides forwarding of traps generated by each component of the Cisco MGC node (the
Cisco MGC host, Ciso SLT, BAMS, and LAN switch) to northbound systems.
|
Note If you plan to configure CMNM to forward traps to northbound systems, you should configure SNMP Version 1 traps only on network devices. CMNM only forwards SNMP Version 1 traps to northbound systems. For more information on configuring SNMP on network devices, see "Configuring Network Devices for Management." |
Traps are forwarded to the northbound systems using standard SNMP transport. To receive traps, northbound systems must register with CMNM. If the northbound system wants to receive standard SNMP traps, you must manually enter the IP address of the northbound system in CMNM. CMNM either provides a dialog where this information is entered or you must deploy an object that represents the northbound system.
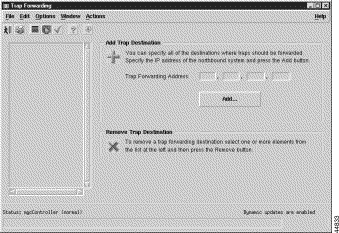
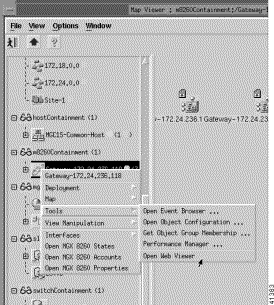
To forward traps to another system:
Step 2 Right-click to display the pull-down menu, select Tools, then Open Trap Forwarding.
You see the screen in Figure 8-6.
Step 3 Next to Trap Forwarding Address, enter the IP address to which you want to forward traps and click Add.
You see the screen in Figure 8-7.
Step 4 Click Close, then close the Trap Forwarding screen shown in Figure 8-6.
Step 5 Select the MGC-Node-View icon on the Map Viewer, right-click to display the pull-down menu, select Tools, then Open Trap Forwarding.
You see the Trap Forwarding screen shown in Figure 8-6 with the IP address you specified added to the left pane.
|
Note To remove an IP address, from the Trap Forwarding screen select the IP address, select Actions, then select Remove. You see a screen confirming your action. Click OK. |
The Event Browser application is launched using the  icon in the CEMF Launchpad screen. The Query Editor window is displayed.
icon in the CEMF Launchpad screen. The Query Editor window is displayed.
Set your query (the Event Browser displays events that match the query criteria). For more information, see the "Filtering Events Using Queries" section.
From the pop-up menu available when you right-click one or more objects in the Map Viewer (the Event Browser displays only the events associated with the selected objects), or from other CEMF applications, select the Event Browser option.
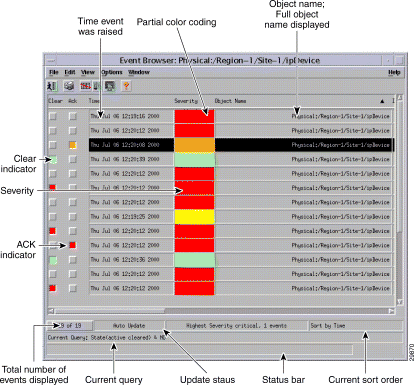
The main panel in the Event Browser window, shown in Figure 8-8, displays a list of events including:
Two indicators, color-coded to the severity of the event, are available to the left of the object name:
Click Ack to indicate to other users that the fault is being worked on. The button changes to the color of the severity, in this case, red. If for any reason you cannot clear the problem, this button can be deselected so the event can be reassigned. Click Clear when the fault has been rectified to indicate that the event requires no further attention.
|
Note The option to unacknowledge an event is available only to an administrator or to the user who acknowledged the event initially. |
Menus are available that provide you with options for modifying the way the information is displayed. From the Edit menu, you can:
From the View menu you have the following options to manage the way events are viewed on each object:
The Full Event Description window allows you to view the status of a selected event. For more information, refer to the "Viewing a Full Description of an Event" section.
Clicking an event severity, name, time, or description selects that event. One or more events can be selected; this gives the opportunity to perform bulk operations. With one or more events selected, clicking the right mouse button displays a pop-up menu that shows the common services available on those events.
The Event Browser window also displays other information in the status bar:
|
Note The Event Browser can display a maximum of 10,000 entries. If there are more events on the system, this is indicated in the status bar. |
In the Event Browser, you can use Print to save the contents of all or part of the browser to a file or to print a paper copy.
The Event Browser monitors all events on all devices. To work efficiently, you may want to specify the objects on the network with which you are concerned. The Event Browser gives you the option to do this through queries that can be configured to match your requirements. With queries you can choose to include or exclude devices or criteria. For example, you could choose to monitor a particular device, specify a time period, and choose to look only at events that are warnings or are critical. You define a query so that the Event Browser displays only the events that meet the criteria you defined.
|
Note Any changes made to the queries are not stored after exiting the Event Browser. |
To define a query, click the icon in the CEMF Launchpad window, or
in the Event Browser, select the Edit menu's Query Setup option, or
click the Query Filter icon  from the Toolbar.
from the Toolbar.
The Query Editor window, similar to Figure 8-9, is displayed. The criteria that can be used to specify a query are available on individual tabs. Values or criteria can be selected on each tab. A dark gray tab is active (On); its query is used in the Event Browser. A light gray tab is inactive (Off); its query is not used.
The Query Editor is split into the following tabbed sections (see the next section, "Setting Filtering Criteria," for more information):
The Event Browser is updated with events that match the query criteria. A progress bar indicates that CEMF is querying for events and the window is being updated. The total number of events displayed is shown in blue until you acknowledge it by clicking on the number.
To set filtering (query) criteria:
You see the screen in Figure 8-10.
Step 2 From the Available Values list, select the desired alarm level.
Step 3 Click the right arrows to transfer the alarm level to the Selected Value list.
Step 4 Click the Time tab.
You see the screen in Figure 8-11.
Step 5 Select the time range and the date range for collecting the alarms.
Step 6 Click the Event Status tab.
You see the screen in Figure 8-12.
Step 7 From the Available Values list, select the events and click the right arrows to transfer them to the Selected Values list.
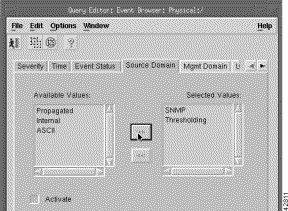
Step 8 Click the Source Domain tab.
You see the screen in Figure 8-13.
Step 9 From the Available Values list, select Domain values and click the right arrows to transfer the values to the Selected Values list.
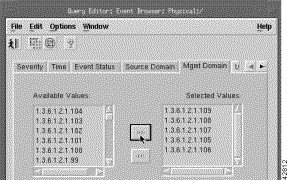
Step 10 Click the Mgnt Domain tab.
You see the screen in Figure 8-14.
Step 11 From the Available Values list, select management domains and click the right arrows to transfer the values to the Selected Values list.
Step 12 Click the arrows on the right side of the tabs to scroll to additional tabs.
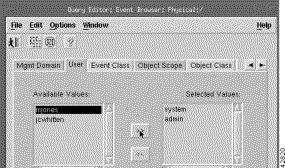
Step 13 Click the User tab.
You see the screen in Figure 8-15.
Step 14 From the Available Values list, select users and click the right arrows to transfer the values to the Selected Values list.
Step 15 Click the Event Class tab.
You see the screen in Figure 8-16.
Step 16 From the Available Values list, select event classes and click the right arrows to transfer the values to the Selected Values list.
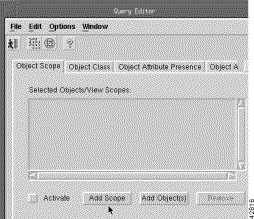
Step 17 Click the Object Scope tab to display all the events of a node and all its children.
You see the screen in Figure 8-17.
Step 18 Click Add Scope.
You see the screen in Figure 8-18.
Step 19 In the View Scope selector, select the node.
Step 20 Type the number of levels to view. This can be more than needed.
Step 21 Click the diamond to the left of Descendants and click Apply.
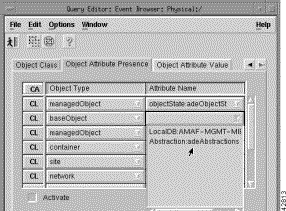
Step 22 On the Query Editor screen, click the Object Classes tab.
You see the screen in Figure 8-19.
Step 23 From the Available Values list, select the desired object classes and click the right arrows to transfer the values to the Selected Values list.
Step 24 Click the Object Attribute Presence tab. Click a pull-down menu under Object Type to select a value and click a pull-down menu under Attribute Name to select a value, as shown in Figure 8-20.
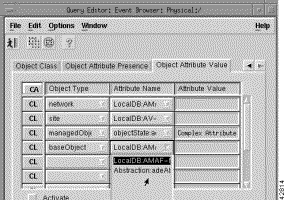
Step 25 Click the Object Attribute Value tab. Click a pull-down menu under Object Type to select a value, click a pull-down menu under Attribute Name to select a value, and click a pull-down menu under Attribute Value to select a value, as shown in Figure 8-21.
Step 26 After all values are set, click Apply and close the Query Editor.
You see the following message:
Step 27 Click Yes.
The Event Browser begins collecting the data using the criteria you selected and displays it in the Event Browser window.
|
Note Query changes are saved for the immediate session only. When you close the Event Browser, the query criteria is reset to the default. |
You can change the alarm criteria displayed in the Event Browser at any time by launching the Query Editor and changing the values.
Step 2 Set up the query by selecting values as described in the "Setting Filtering Criteria" section.
Step 3 Close the Query Setup screen. The Event Browser displays the data.
Query Editor configuration allows you to specify the events you want to see. Sorting gives you options to change the order in which you view the events that match your query criteria.
From the Edit menu, select Sorting Options. A pull-down menu is displayed listing the available sorting options. An indicator shows which option is selected. Selecting an option causes the Event Browser display to change to show the appropriate information. The sort option selected is shown in the status bar. You can sort by:
When the Event Browser shows a sorted list of events that match the query criteria set, you can start to manage those events. This is the place to acknowledge an event, which shows that you have taken responsibility for managing that event. If you cannot continue to manage an event, it can be unacknowledged and then becomes available to other users.
|
Note The option to unacknowledge an event is available only to an administrator or to the user who acknowledged the event initially. |
When the fault has been rectified and the event requires no further attention, clear the event. It is then removed from the Event Browser.
Three methods are available for managing events:
Clicking an event severity, name, time, or description selects that event. One or more events can be selected; this gives you the opportunity to perform bulk operations.
 on the Toolbar.
on the Toolbar.
This displays the Events Clearing window. Enter the reason for clearing the event, then click Apply to save or click Cancel to exit the window without saving. The indicator changes to the new color of the severity of the event.
Step 2 Select the Ack indicator to acknowledge an event. The indicator changes to the color of the severity of the event. To unacknowledge an event, select the Ack indicator, which is then shown as deselected.
|
Note This option is available only to the user who acknowledged the event or to a user with administrative access. |
From the Edit menu, you can select the Edit Event State option. A pull-down menu is displayed, which provides options to manage the events.
|
Note This option is available only to the user who acknowledged the event or to a user with administrative access. |
Auto Update is the default state and allows you to view incoming events that are automatically updated in the window.
The status box displays the current update state, either Auto or Manual. If Auto Update is enabled, the status box displays Auto Update.
When the update state is Manual (Auto Update is disabled), you should refresh the window at regular intervals using the View menu's Refresh option or the Refresh icon  so that new events are displayed.
so that new events are displayed.
|
Note If an indicator is displayed on the pull-down menu, to the left of Enable Auto Update, the Auto Update application is enabled. |
|
Note The message in the status box changes to Manual Update. |
Three color-coding options are available to you. The color you choose depends on the severity of the event. The options are as follows:
Step 2 From the menu that appears, select one of the options.
The selected option is implemented immediately.
Event history allows you to display any events that match the current query criteria and have had their state changed, either acknowledged, cleared, or unacknowledged. This is disabled by default. To view this information, select the View menu's Event History option.
The Event Browser displays current events that match the criteria set in the query.
Step 2 From the View menu, select Event History.
The Event Browser now displays any events that meet that query and have been cleared.
|
Note By default, cleared events are stored by the system for seven days. Therefore, only events that match the current query and have had their state changed in the last seven days, are displayed when the Event History is enabled. |
Ensure that Manual Update is selected; this is shown as a current status message. You can then:
|
Note You should refresh the window at regular intervals to show an up-to-date list of events. |
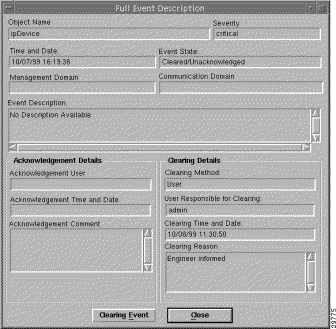
Double-clicking an event displays the Full Event Description window. This provides details of the event with Acknowledge and Clearing details.
To view a full description of an event, place the cursor over the relevant event in the Event Browser, then double-click the left mouse button or select Event Description, then select Event Information Dialog from the pop-up menu available on a selected object.
A window similar to Figure 8-24 is displayed.
|
Note If the event has not been cleared, the Event State displays Active and the Clearing Method,
User Responsible for Clearing, and Clearing Time and Date sections are disabled. The information displayed cannot be altered. If an event has been cleared, you can view the method used to clear it by clicking Clearing Event. |
The Full Event description window displays the following information:
You can view and manage faults on the Cisco MGX 8260 with the Web View tool. To use Web View:
Step 2 When the Web Browser appears, type your user ID and password and click Login.
You can manage Cisco MGC host faults and performance from the MGC Toolbar.
You see the screen in Figure 8-27.
From the MGC Toolbar you can click the following buttons:
You see the screen in Figure 8-29.
Step 2 Click Yes.
You see the screen in Figure 8-30.
Step 3 In the Select Component box, use the Comp Type and CompList pull-down menus to select values.
Step 4 In the Select Category box, use the catType and measList pull-down menus to select values.
Step 5 Select a file from the list on the right of the screen.
Step 6 Click Execute to run the query.
The results appear in the box at the bottom of the screen.
Step 7 Click the Alarm Record View tab to display alarm records.
You see the screen in Figure 8-31.
Step 8 In the Select Component box, use the Comp Type and CompList pull-down menus to select values.
Step 9 In the Select Category box, use the alarmCategory pull-down menu to select a value.
Step 10 Select a file from the list on the right of the screen.
Step 11 Click Execute to run the query.
The results appear in the box at the bottom of the screen.
You see the screen in Figure 8-32.
Step 2 Click Yes to proceed.
You see the screen in Figure 8-33.
Step 3 Select an action to perform.
Step 4 Click the Config tab.
You see the screen in Figure 8-34.
Step 5 From the All Possible Message Types list, select the messages you want to filter and click Transfer to transfer them to the Selected filtering list.
You see the screen in Figure 8-35.
Step 2 Click Yes to continue.
You see the screen in Figure 8-36.
Step 3 Enter the number of the list item to be executed and press Enter.
You see the screen in Figure 8-37.
Step 2 Click Yes to proceed.
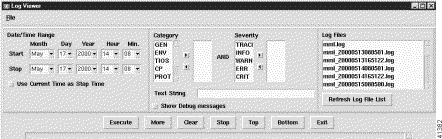
You see the screen in Figure 8-38.
Step 3 Select categories and severities from the lists, then select a log file.
Step 4 Select an action to execute.
You see the screen in Figure 8-39.
Step 2 Click Yes to continue.
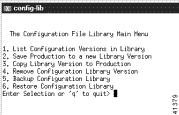
You see the screen in Figure 8-40.
Step 3 Select a trace file to view and click View.
You see the screen in Figure 8-41.
Step 2 Click Yes to continue.
You see the screen in Figure 8-42.
Step 3 Type a four-digit dial plan number in the field provided.
Step 4 Click Execute to finish.
Step 5 Click SaveInFile to save the data in a file for later viewing.
Step 6 Click the Config tab to display related environmental variables.
Step 7 You see the screen in Figure 8-43.
You see the screen in Figure 8-44.
Step 2 Click a file, then click an action to execute it.
All alarms are automatically stored in the CEMF database. Periodically CEMF purges the alarms from the database to free up room for new alarms.
The alarmDeleter utility controls the deletion of alarms. CEMF does not do any archiving of old alarms, but it can be configured to delete alarms of a specific age and state. Upon installation, a cron job is set up to run the Alarm Deleter at midnight every night. At this time, the Deleter queries the alarm database, deleting alarms that meet the specified criteria. The alarmDelete.ini file, shown below, allows you to define these rules. The default is to delete cleared alarms that are seven days old.
[logger]
#include "loggercommon.include"
loggingName = alarmDeleter
[AlarmDeleter]
databaseName = [[OSDBROOT]]/alarm.db
segmentDeletionInterval = 15
ageOfAlarmsInDays = 7
ageOfAlarmsInHours = 0
ageOfAlarmsInMinutes = 0
deleteAllAlarms = 0
[Database]
#include "databaseCommon.include"
The variables used in defining the deletion rules are described in Table 8-18.
Table 8-18 Alarm Deleter Attributes
|
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Posted: Mon Sep 15 14:40:58 PDT 2003
All contents are Copyright © 1992--2003 Cisco Systems, Inc. All rights reserved.
Important Notices and Privacy Statement.