|
|

The information in this chapter is provided to help you set up servers and services in the most practical manner to use the Cisco User Control Point (UCP) efficiently. This chapter includes:
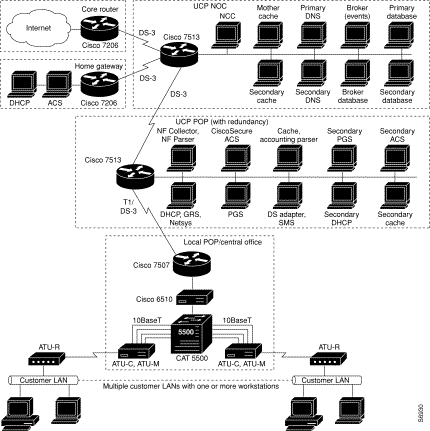
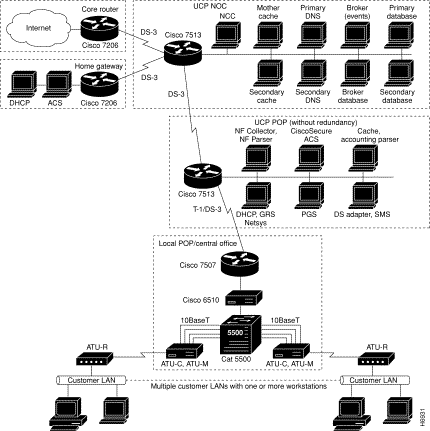
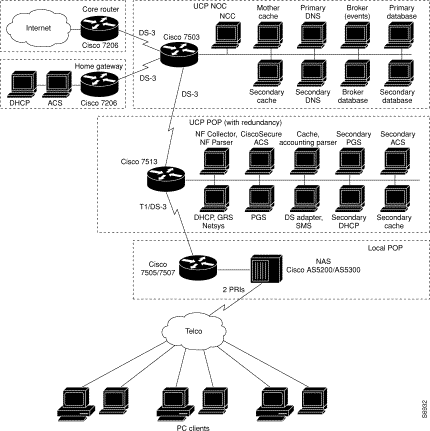
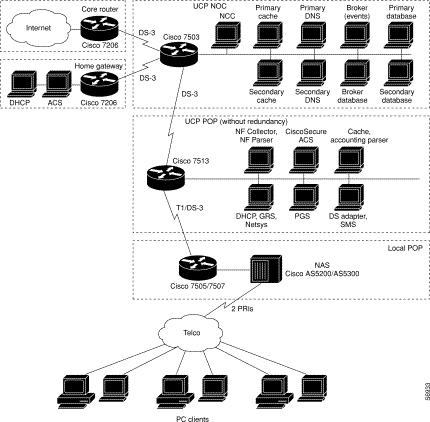
UCP consists of a number of distributed components called services that are connected by an Information Bus and monitored through the Network Control Console (NCC). Services reside on servers---the physical hardware where they are installed.
There are three levels of objects in the UCP model:
Servers run at POPs, which is where the hardware components---servers, routers, modem banks, dial-in routers, aggregation routers, and so on---reside. POP services contain configurations that point to IP addresses of known external services, IP addresses of known clients, systems in place to perform load balancing, and so on.
The following components are found at the NOC. For optimum performance, these services should be run on powerful Sun Microsystems workstations:
Each of the POPs or central servers must be configured with the IP address of the Information Broker. Each server has an IP address so that when events are generated, they are routed properly.
Servers and components at the local POPs include:
There are no servers that cannot reside together at a single POP.
A fault-tolerant system is one that operates continuously with acceptable results even in the event of unexpected failures. A fault-tolerant system must be able to:
Fault tolerance in UCP:
The NOC services such as DNS, ActiveWeb Information Broker, the mother cache, and the directory store) will cover a number of POPs. Failure in any of these components will impact a much larger portion of a network. For this reason, Cisco recommends the installation of high-end Sun workgroup systems or small-to-medium-sized Sun Ultra Enterprise systems at the central or NOC locations.
When trying to reach an external service, UCP components configured for load balancing (such as the Protocol Gateway Service) automatically adjust the load by accessing two external service components. UCP maintains a hashed table of entries sent to various configured external service components. It periodically ranks the external components based on response times, the number of milliseconds that packets wait in a queue to access the external service, the number of timeouts generated from an external service, and so on.
The external service with the highest rank becomes the primary external service. As this service slows down, the client program will shift the load to the other service.
The following sections discuss redundancy on a service-by-service basis.
The Control Adapter (CA) on each system can be configured to watch the various services that are running and restart any when it detects the failure of one to report the restart to the NCC via an exception event. If repeated restarts fail, the CA reports a restart failure using an exception event.
Cisco recommends that two or more instances of the Protocol Gateway Service (PGS) be running at all times. In the event of a fault or failure, the PGS is first expected to respond gracefully and report the problem; in case of a failure, a dependent component or subsystem must be able to use the backup PGS without any interruption or loss of data by UCP.
To withstand hardware failure, PGS redundancy is required.
Cisco recommends that two instances of the CiscoSecure Access Control Server (ACS) be running at all times. Each PGS is configured to recognize each instance of a CiscoSecure ACS. The PGS records and maintains each CiscoSecure ACS processing time for each packet. A failure in one instance will cause the PGS to use other instances of CiscoSecure ACS.
Cisco recommends that two or more instances of the Dynamic Host Configuration Protocol (DHCP) service be configured on a local POP. Each instance will control a subset of all available IP addresses represented in one or more IP pools. Each instance of a DHCP server must support all possible user type pools.
Multiple instances of the ActiveWeb Information Broker (IB) cannot be used with the same UCP servers and services. There should be two IB servers for one or more POPs on the network---one dedicated to processing heartbeat events, and the other to process the remainder of event types for all publishers and subscribers in the network.
Active Software does not support redundancy for the IB. Therefore, a hardware failure in the system will halt traffic on the IB until another broker replaces the down server. Cisco recommends either:
Because UCP services and servers can be configured with the IP address of only one IB, the replacement system should have the same IP address, and should be connected to the same subnet as the down server. The impact on UCP operation is the loss of events in the IB volatile memory and any events sent by publishers while the down server is replaced with another.
Two or more instances of the mother cache are required to support fault tolerance. All instances of mother cache services subscribe to all event types that contain mother cache updates, but only one instance is configured to publish update events to the local caches. The backup mother caches monitor the primary mother cache; if the primary mother cache fails, one of the backup servers reconfigures itself to publish events and assumes the role of the primary mother cache.
At a local POP, you can configure UCP to run two cache services. To do so, you must configure all instances of UCP caches to subscribe to the same event types. All services that interact with a cache outside the information bus must be configured with a list of cache services at UCP installation time. If the primary cache fails, a timeout on the client component (the CiscoSecure ACS translator) causes the client to resend the request to the next cache service in line.
UCP uses a primary and secondary DNS server; both subscribe to the same events, allowing each server to be a backup for the other.
The network topology diagrams on the following pages are provided to illustrate environments into which UCP can be integrated:
|
|