
 |  |
6.2. Grouping Nodes
When grouping nodes, we sort things to get them into a certain order, then we group all items that have the same value for the sort key (or keys). We'll use xsl:sort for this grouping, then use variables or functions like key() or generate-id() to finish the job.
6.2.1. Our First Attempt
For our first example, we'll take our list of addresses and group them. We'll look for all unique values of the <zip> element and list the addresses that match each one. What we'll do is sort the list by Zip Code, then go through the list. If a given item doesn't match the previous Zip Code, we'll print out a heading; if it does match, we'll just print out the address. Here's our first attempt:
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" indent="no"/>
<xsl:variable name="newline">
<xsl:text>
</xsl:text>
</xsl:variable>
<xsl:template match="/">
<xsl:text>Addresses sorted by Zip Code</xsl:text>
<xsl:value-of select="$newline"/>
<xsl:for-each select="addressbook/address">
<xsl:sort select="zip"/>
<xsl:if test="zip!=preceding-sibling::address[1]/zip">
<xsl:value-of select="$newline"/>
<xsl:text>Zip code </xsl:text>
<xsl:value-of select="zip"/>
<xsl:text> (</xsl:text>
<xsl:value-of select="city"/>
<xsl:text>, </xsl:text>
<xsl:value-of select="state"/>
<xsl:text>): </xsl:text>
<xsl:value-of select="$newline"/>
</xsl:if>
<xsl:if test="name/title">
<xsl:value-of select="name/title"/>
<xsl:text> </xsl:text>
</xsl:if>
<xsl:value-of select="name/first-name"/>
<xsl:text> </xsl:text>
<xsl:value-of select="name/last-name"/>
<xsl:value-of select="$newline"/>
<xsl:value-of select="street"/>
<xsl:value-of select="$newline"/>
<xsl:value-of select="$newline"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>Our approach in this stylesheet consists of two steps:
-
Sort the addresses by Zip Code.
<xsl:sort select="zip"/>
-
For each Zip Code, if it doesn't match the previous Zip Code, print out a heading, then print out the addresses that match it.
<xsl:if test="zip!=preceding-sibling::address[1]/zip"> <xsl:value-of select="$newline"/> <xsl:text>Zip code </xsl:text> ...
(Remember that preceding-sibling returns a NodeSet, so preceding-sibling::address[1] represents the first preceding sibling.)
That sounds reasonable, doesn't it? Let's take a look at the results:
Addresses sorted by Zip Code Zip code 00218 (Winter Harbor, ME): Ms. Natalie Attired 707 Breitling Way Zip code 02718 (Skunk Haven, MA): Mary Backstayge 283 First Avenue Harry Backstayge 283 First Avenue Zip code 02930 (Lynn, MA): Ms. Amanda Reckonwith 930-A Chestnut Street Zip code 27318 (Boylston, VA): Mary McGoon 103 Bryant Street Mr. Chester Hasbrouck Frisby 1234 Main Street
Yes, that certainly seemed like a good approach, but there's one minor problem: it doesn't work.
Looking at our results, there seems to be only one problem: one of the addresses (Mr. Chester Hasbrouck Frisby) is grouped under the heading for Boylston, Virginia, but he actually lives in Sheboygan, Wisconsin, Zip Code 48392. The problem here is that the axes work with the document order, not the sorted order we've created inside the xsl:for-each element.
As straightforward as our logic seemed, we'll have to find another way.
6.2.2. A Brute-Force Approach
One thing we could do is make the transformation in two passes; we could write an intermediate stylesheet to sort the names and generate a new XML document, then use the stylesheet we've already written, because document order and sorted order will be the same. Here's how that intermediate stylesheet would look:
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" indent="no"/>
<xsl:strip-space elements="*"/>
<xsl:template match="/">
<addressbook>
<xsl:for-each select="addressbook/address">
<xsl:sort select="name/last-name"/>
<xsl:sort select="name/first-name"/>
<xsl:copy-of select="."/>
</xsl:for-each>
</addressbook>
</xsl:template>
</xsl:stylesheet>This stylesheet generates a new <addressbook> document that has all of the <address> elements sorted correctly. We can then run our original stylesheet against the sorted document and get the results we want. This works, but it's not very elegant. Even worse, it's really slow because we have to stop in the middle and write a file out to disk, then read that data back in. We'll find a way to group elements in a single stylesheet, but we'll have to do it with a different technique.
6.2.3. Grouping with <xsl:variable>
We mentioned earlier that sometimes <xsl:variable> is useful for grouping, so let's try that approach. We'll save the value of the <zip> element each time through the <xsl:for-each> element and use preceding-sibling in a slightly different way. Here's how attempt number three looks:
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" indent="no"/>
<xsl:variable name="newline">
<xsl:text>
</xsl:text>
</xsl:variable>
<xsl:template match="/">
<xsl:text>Addresses sorted by Zip Code</xsl:text>
<xsl:value-of select="$newline"/>
<xsl:for-each select="addressbook/address">
<xsl:sort select="zip"/>
<xsl:sort select="name/last-name"/>
<xsl:sort select="name/first-name"/>
<xsl:variable name="lastZip" select="zip"/>
<xsl:if test="not(preceding-sibling::address[zip=$lastZip])">
<xsl:text>Zip code </xsl:text>
<xsl:value-of select="zip"/>
<xsl:text>: </xsl:text>
<xsl:value-of select="$newline"/>
<xsl:for-each select="/addressbook/address[zip=$lastZip]">
<xsl:sort select="name/last-name"/>
<xsl:sort select="name/first-name"/>
<xsl:if test="name/title">
<xsl:value-of select="name/title"/>
<xsl:text> </xsl:text>
</xsl:if>
<xsl:value-of select="name/first-name"/>
<xsl:text> </xsl:text>
<xsl:value-of select="name/last-name"/>
<xsl:value-of select="$newline"/>
<xsl:value-of select="street"/>
<xsl:value-of select="$newline"/>
<xsl:value-of select="$newline"/>
</xsl:for-each>
</xsl:if>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>This stylesheet generates what we want:
Addresses sorted by Zip Code Zip code 00218: Ms. Natalie Attired 707 Breitling Way Zip code 02718: Harry Backstayge 283 First Avenue Mary Backstayge 283 First Avenue Zip code 02930: Ms. Amanda Reckonwith 930-A Chestnut Street Zip code 27318: Mary McGoon 103 Bryant Street Zip code 48392: Mr. Chester Hasbrouck Frisby 1234 Main Street
So why does this approach work when our first attempt didn't? The answer is: we don't count on the sorted order of the elements to generate the output. The downside of this approach is that we go through several steps to get the results we want:
-
We sort all the addresses by Zip Code:
<xsl:sort select="zip"/>
-
We store the current <zip> element's value in the variable lastZip:
<xsl:variable name="lastZip" select="zip"/>
-
For each <zip> element, we look at all of its preceding siblings to see if this is the first time we've encountered this particular value (stored in lastZip). If it is, there won't be any preceding siblings that match.
<xsl:if test="not(preceding-sibling::address[zip=$lastZip])">
-
If this is the first time we've encountered this value in the <zip> element, we go back and reselect all <address> elements with <zip> children that match this value. Once we have that group, we sort them by first name within last name and print each address.
<xsl:for-each select="/addressbook/address[zip=$lastZip]"> <xsl:sort select="name/last-name"/> <xsl:sort select="name/first-name"/>
So, we've found a way to get the results we want, but it's really inefficient. We sort the data, then we look at each Zip Code in sorted order, then see if we've encountered that value before in document order, then we reselect all the items that match the current Zip Code and resort them before we write them out. Whew! There's got to be a better way, right? Well, since we're not at the end of the chapter, it's a safe bet we'll find a better way in the next section. Read on....
6.2.4. The <xsl:key> Approach
In this section, we'll look at using <xsl:key> to group items in an XML document. This approach is commonly referred to as the "Muench method," after Oracle XML Evangelist (and O'Reilly author) Steve Muench, who first suggested this technique. The Muench method has three steps:
-
Define a key for the property we want to use for grouping.
-
Select all of the nodes we want to group. We'll do some tricks with the key() and generate-id() functions to find the unique grouping values.
-
For each unique grouping value, use the key() function to retrieve all nodes that match it. Because the key() function returns a node-set, we can do further sorts on the set of nodes that match any given grouping value.
Well, that's how the technique works -- let's start building the stylesheet that makes the magic happen. The first step, creating a key function, is easy. Here's how it looks:
<xsl:key name="zipcodes" match="address" use="zip"/>
This <xsl:key> element defines a new index called zipcodes. It indexes <address> elements based on the value of the <zip> element they contain.
Now that we've defined our key, we're ready for the complicated part. We use the key() and generate-id() functions together. Here's the syntax, which we'll discuss extensively in a minute:
<xsl:for-each select="//address[generate-id(.)=
generate-id(key('zipcodes', zip)[1])]">Okay, let's take a deep, cleansing breath and start digging through this syntax. What we're selecting here is all <address> elements in which the automatically generated id matches the automatically generated id of the first node returned by the key() function when we ask for all <address> elements that match the current <zip> element.
Well, that's clear as crystal, isn't it? Let me try to explain that again from a slightly different perspective.
For each <address>, we use the key() function to retrieve all <address>es that have the same <zip>. We then take the first node from that node-set. Finally, we use the generate-id() function to generate an id for both nodes. If the two generated ids are identical, then the two nodes are the same.
Whew. Let me catch my breath.
If this <address> matches the first node returned by the key() function, then we know we've found the first <address> that matches this grouping value. Selecting all of the first values (remember, our previous predicate ends with [1]) gives us a node-set of some number of <address> elements, each of which contains one of the unique grouping values we need.
Well, that's how this technique works. At this point, we've got a way to generate a node-set that contains all of the unique grouping values; now we need to process those nodes. From this point, we'll do several things, all of which are comparatively simple:
-
Sort all nodes based on the grouping property. In this example, the property is the <zip> element. We start by selecting the first occurrence of every unique <zip> element in the document, then we sort those <zip> elements. Here's how it looks in the stylesheet:
<xsl:for-each select="//address[generate-id(.)=generate-id(key('zipcodes', zip)[1])]"> <xsl:sort select="zip"/> -
The outer <xsl:for-each> element selects all the unique values of the <zip> element. Next, we use the key() function to retrieve all <address> elements that match the current <zip> element:
<xsl:for-each select="key('zipcodes', zip)"> -
The key() function gives us a node-set of all matching <address> elements. We sort that node-set based on the <last-name> and <first-name> elements, then process them in turn:
<xsl:sort select="name/last-name"/> <xsl:sort select="name/first-name"/> <tr> <xsl:if test="position() = 1"> <td valign="center" bgcolor="#999999"> <xsl:attribute name="rowspan"> <xsl:value-of select="count(key('zipcodes', zip))"/> </xsl:attribute> <b> <xsl:text>Zip code </xsl:text><xsl:value-of select="zip"/> </b> </td> </xsl:if> <td align="right"> <xsl:value-of select="name/first-name"/> <xsl:text> </xsl:text> <b><xsl:value-of select="name/last-name"/></b> </td> <td> <xsl:value-of select="street"/> <xsl:text>, </xsl:text> <xsl:value-of select="city"/> <xsl:text>, </xsl:text> <xsl:value-of select="state"/> <xsl:text> </xsl:text> <xsl:value-of select="zip"/> </td> </tr> </xsl:for-each> </xsl:for-each>We generate a table cell that contains the Zip Code common to all addresses, creating a rowspan attribute based on the number of matches for the current Zip Code. From there, we write the other data items into table cells.
Here's our complete stylesheet:
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="no"/>
<xsl:key name="zipcodes" match="address" use="zip"/>
<xsl:template match="/">
<table border="1">
<xsl:for-each select="//address[generate-id(.)=
generate-id(key('zipcodes', zip)[1])]">
<xsl:sort select="zip"/>
<xsl:for-each select="key('zipcodes', zip)">
<xsl:sort select="name/last-name"/>
<xsl:sort select="name/first-name"/>
<tr>
<xsl:if test="position() = 1">
<td valign="center" bgcolor="#999999">
<xsl:attribute name="rowspan">
<xsl:value-of select="count(key('zipcodes', zip))"/>
</xsl:attribute>
<b>
<xsl:text>Zip code </xsl:text><xsl:value-of select="zip"/>
</b>
</td>
</xsl:if>
<td align="right">
<xsl:value-of select="name/first-name"/>
<xsl:text> </xsl:text>
<b><xsl:value-of select="name/last-name"/></b>
</td>
<td>
<xsl:value-of select="street"/>
<xsl:text>, </xsl:text>
<xsl:value-of select="city"/>
<xsl:text>, </xsl:text>
<xsl:value-of select="state"/>
<xsl:text> </xsl:text>
<xsl:value-of select="zip"/>
</td>
</tr>
</xsl:for-each>
</xsl:for-each>
</table>
</xsl:template>
</xsl:stylesheet>When we view the generated HTML document in a browser, it looks like Figure 6-1.
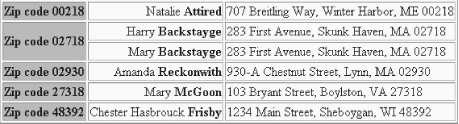
Figure 6-1. HTML document with grouped items
Notice how the two <xsl:for-each> and the various <xsl:sort> elements work together. The outer <xsl:for-each> element selects the unique values of the <zip> element and sorts them; the inner <xsl:for-each> element selects all <address> elements that match the current <zip> element, and then sorts them by <last-name> and <first-name>.
|  | |
| 6. Sorting and Grouping Elements |  | 6.3. Summary |

Copyright © 2002 O'Reilly & Associates. All rights reserved.