
 |  |
1.2. XML Basics
Almost everything we do in this book deals with XML documents. XSLT stylesheets are XML documents themselves, and they're designed to transform an XML document into something else. If you don't have much experience with XML, we'll review the basics here. For more information on XML, check out Erik T. Ray's Learning XML (O'Reilly, 2001) and Elliotte Rusty Harold and W. Scott Means's XML in a Nutshell (O'Reilly, 2001).
1.2.1. XML's Heritage
XML's heritage is in the Standard Generalized Markup Language (SGML). Created by Dr. Charles Goldfarb in the 1970s, SGML is widely used in high-end publishing systems. Unfortunately, SGML's perceived complexity prevented its widespread adoption across the industry (SGML also stands for "sounds great, maybe later"). SGML got a boost when Tim Berners-Lee based HTML on SGML. Overnight, the whole computing industry was using a markup language to build documents and applications.
The problem with HTML is that its tags were designed for the interaction between humans and machines. When the Web was invented in the late 1980s, that was just fine. As the Web moved into all aspects of our lives, HTML was asked to do lots of strange things. We've all built HTML pages with awkward table structures, 1-pixel GIFs, and other nonsense just to get the page to look right in the browser. XML is designed to get us out of this rut and back into the world of structured documents.
Whatever its limitations, HTML is the most popular markup language ever created. Given its popularity, why do we need XML? Consider this extremely informative HTML element:
<td>12304</td>
What does this fascinating piece of content represent?
-
Is it the postal code for Schenectady, New York?
-
Is it the number of light bulbs replaced each month in Las Vegas?
-
Is it the number of Volkswagens sold in Hong Kong last year?
-
Is it the number of tons of steel in the Sydney Harbour Bridge?
The answer: maybe, maybe not. The point of this silly example is that there's no structure to this data. Even if we included the entire table, it takes intelligence (real, live intelligence, the kind between your ears) to make sense of this data. If you saw this cell in a table next to another cell that contained the text "Schenectady," and the heading above the table read "Postal Codes for the State of New York," as a human being, you could interpret the contents of this cell correctly. On the other hand, if you wanted to write a piece of code that took any HTML table and attempted to determine whether any of the cells in the table contained postal codes, you'd find that difficult, to say the least.
Most HTML pages have one goal in mind: the appearance of the document. Veterans of the markup industry know that this is definitely not the way to create content. The separation of content and presentation is a long-established tenet of the publishing industry; unfortunately, most HTML pages aren't even close to approaching this ideal. An XML document should contain information, marked up with tags that describe what all the pieces of information are, as well as the relationship between those items. Presenting the document (also known as rendering) involves rules and decisions separate from the document itself. As we work through dozens of sample documents and applications, you'll see how delaying the rendering decisions as long as possible has significant advantages.
Let's look at another marked-up document. Consider this:
<?xml version="1.0"?>
<postalcodes>
<title>Most-used postal codes in November 2000</title>
<item>
<city>Schenectady</city>
<postalcode>12304</postalcode>
<usage-count>2039</usage-count>
</item>
<item>
<city>Kuala Lumpur</city>
<postalcode>57000</postalcode>
<usage-count>1983</usage-count>
</item>
<item>
<city>London</city>
<postalcode>SW1P 4RG</postalcode>
<usage-count>1722</usage-count>
</item>
...
</postalcodes>Although we're still in the realm of contrived examples, it would be fairly easy to write a piece of code to find the postal codes in any document that used this set of tags (as opposed to HTML's <table>, <tr>, <td>, etc.). Our code would look for the contents of any <postalcode> elements in the document. (Not to get ahead of ourselves here, but writing an XSLT stylesheet to do this might take all of 30 minutes, including a 25-minute nap.) A well-designed XML document identifies each piece of data in the document and models the relationships between those pieces of data. This means we can be confident that we're processing an XML document correctly.
Again, the key idea here is that we're separating content from presentation. Our XML document clearly delineates the pieces of data and puts them into a format we can parse easily. In this book, we illustrate a number of techniques for transforming this XML document into a variety of formats. Among other things, we can transform the item <postalcode>12304</postalcode> into <td>12304</td>.
1.2.2. XML Document Rules
Continuing our trip through the basics of XML, there are several rules you need to keep in mind when creating XML documents. All stylesheets we develop in this book are themselves XML documents, so all the rules of XML documents apply to everything we do. The rules are pretty simple, even though the vast majority of HTML documents don't follow them.
One important point: The XML 1.0 specification makes it clear that when an XML parser finds an XML document that breaks the rules, the parser is supposed to throw an exception and stop. The parser is not allowed to guess what the document structure should actually be. This specification avoids recreating the HTML world, where lots of ugly documents are still rendered by the average browser.
1.2.2.1. An XML document must be contained in a single element
The first element in your XML document must contain the entire document. That first element is called the document element or the root element. If more than one document element is in the document, the XML parser throws an exception. This XML document is perfectly legal:
<?xml version="1.0"?> <greeting> Hello, World! </greeting>
(To be precise, this document is well-formed. XML documents are described as well-formed and valid; we'll define those terms in a minute.) This XML document isn't legal at all:
<?xml version="1.0"?> <greeting> Hello, World! </greeting> <greeting> Hey, Y'all! </greeting>
There are two root elements in this document, so an XML parser refuses to process it. Also, be aware that the XML declaration (the <?xml version="1.0"?> part, more on this in a minute) isn't an element at all.
1.2.2.2. All elements must be nested
If you start one element inside another, you have to end it there, too. An HTML browser is happy to render this document:
<b>I really, <i>really</b> like XML.</i>
But an XML parser will throw an exception when it sees this document. If you want the same effect, you would need to code this:
<b>I really, <i>really</i></b><i> like XML.</i>
1.2.2.3. All attributes must be quoted
You can quote the attributes with either single quotes or double quotes. These two XML tags are equivalent:
<a outsideurl="> <a href='http://www.oreilly.com'>
If you need to define an attribute with the value , you can use single quotes inside double quotes, as we just did. If you need both single and double quotes in an attribute, use the predefined entities " for double quotes and ' for single quotes.
One more note: XML doesn't allow attributes without values. In other words, HTML elements like <ol compact> aren't valid in XML. To code this element in XML, you'd have to give the attribute a value, as in <ol compact="yes">.
1.2.2.4. XML tags are case-sensitive
In HTML, <h1> and <H1> are the same. In XML, they're not. If you try to end an <h1> element with </H1>, the parser will throw an exception.
1.2.2.5. All end tags are required
This is another area where most HTML documents break. Your browser doesn't care whether you don't have a </p> or </br> tag, but your XML parser does.
1.2.2.6. Empty tags can contain the end marker
In other words, these two XML fragments are identical:
<lily age="6"></lily>
<lily age="6"/>Notice that there is nothing, not even whitespace, between the start tag and the end tag in the first example; that's what makes this an empty tag.
1.2.2.7. XML declarations
Some XML documents begin with an XML declaration. An XML declaration is a line similar to this:
<?xml version="1.0" encoding="ISO-8859-1"?>
If no encoding is specified, the XML parser assumes you're using UTF-8, a Unicode standard that uses different numbers of bytes to represent virtually every character and ideograph from the world's languages. Be aware that each parser supports a different set of encodings, so you need to check your parser's documentation to find out what your options are.
1.2.2.8. Document Type Definitions (DTDs) and XML Schemas
All of the rules we've discussed so far apply to all XML documents. In addition, you can use DTDs and Schemas to define other constraints for your XML documents. DTDs and Schemas are metalanguages that let you define the characteristics of an XML vocabulary. For example, you might want to specify that any XML document describing a purchase order must begin with a <po> element, and the <po> element in turn contains a <customer-id> element, one or more <item-ordered> elements, and an <order-date> element. In addition, each <item-ordered> element must contain a part-number attribute and a quantity attribute.
Here's a sample DTD that defines the constraints we just mentioned:
<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT po (customer-id , item-ordered+ , order-date)>
<!ELEMENT customer-id (#PCDATA)>
<!ELEMENT item-ordered EMPTY>
<!ATTLIST item-ordered part-number CDATA #REQUIRED
quantity CDATA #REQUIRED >
<!ELEMENT order-date EMPTY>
<!ATTLIST order-date day CDATA #REQUIRED
month CDATA #REQUIRED
year CDATA #REQUIRED >And here's an XML Schema that defines the same document type:
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2000/10/XMLSchema">
<xsd:element name="po">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="customer-id"/>
<xsd:element ref="item-ordered" maxOccurs="unbounded"/>
<xsd:element ref="order-date"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="customer-id" type="xsd:string"/>
<xsd:element name="item-ordered">
<xsd:complexType>
<xsd:attribute name="part-number" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:pattern value="[0-9]{5}-[0-9]{4}-[0-9]{5}"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
<xsd:attribute name="quantity" use="required" type="xsd:integer"/>
</xsd:complexType>
</xsd:element>
<xsd:element name="order-date">
<xsd:complexType>
<xsd:attribute name="day" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:integer">
<xsd:maxInclusive value="31"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
<xsd:attribute name="month" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:integer">
<xsd:maxInclusive value="12"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
<xsd:attribute name="year" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:integer">
<xsd:maxInclusive value="2100"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
</xsd:complexType>
</xsd:element>
</xsd:schema>Schemas have two significant advantages over DTDs:
-
They can define datatypes and other complex structures that are difficult or impossible to do in a DTD. In the previous example, we defined various constraints for the data in our XML documents. We defined that the day attribute must be an integer between 1 and 31, and the month attribute must be an integer between 1 and 12. We also used a regular expression to define a part-number attribute as a five-digit number, a dash, a four-digit number, a dash, and another five-digit number. None of those things are possible in a DTD.
-
Schemas are themselves XML documents. Since they are XML documents, we can write XSLT stylesheets to manipulate them. There are products in the marketplace today that take a schema and generate documentation from it. Figure 1-1 shows some sample output generated from our schema.
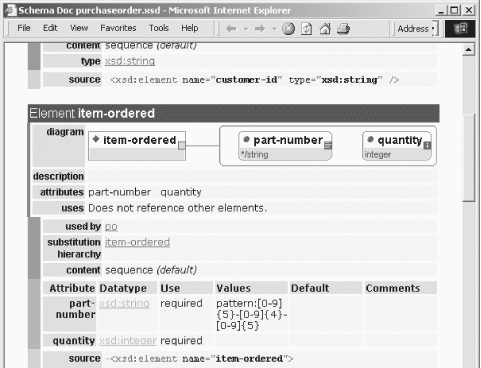
Figure 1-1. Automatically generated XML Schema documentation
Generating this output is relatively straightforward because the tool transforms an XML document. The schema defines a variety of elements and attributes and constraints on valid data, all of which can be easily converted into other formats, such as the HTML shown in Figure 1-1.
1.2.2.9. Well-formed versus valid documents
Any XML document that follows the rules described here is said to be well-formed. In addition, if an XML document references a set of rules that define how the document is structured (either a DTD or an XML Schema), and it follows all those rules, it is said to be a valid document.
All valid documents are well-formed; on the other hand, not all well-formed documents are valid.
1.2.2.10. Tags versus elements
Although many people use the two terms interchangably, a tag is different from an element. A tag is the text between the angle brackets (< and >). There are start tags, end tags, and empty tags. A tag consists of a tag name and, if it is a start tag or an empty tag, some optional attributes. (Unlike other markup languages, end tags in XML cannot contain attributes.) An element consists of the start tag for the element, the end tag for the element, and everything in between. This might include text, other elements, and comments, as well as other things such as entity references and processing instructions.
1.2.2.11. Namespaces
A final XML topic we'll mention here is namespaces. Namespaces are designed to distinguish between two tags that have the same name. For example, if I design an XML vocabulary for books and you design an XML vocabulary for paintings, it's likely that both of us will define a <title> element. My <title> element refers to the title of a book, while yours refers to the title of a painting. If someone needs to create an XML document that refers to both books and paintings, they can use a namespace to distinguish between the two <title> elements. Namespaces are defined and used as follows:
<xyz xmlns:books="http://www.myco.com/books.dtd"
xmlns:paintings="http://www.yourco.com/paintings.xsd">In this example, the xmlns:books attribute associates a string with the books DTD, and the xmlns:paintings attribute associates a string with the paintings schema. This means that a title element from the books DTD would be coded as <books:title>, while a title element from the paintings schema would be referred to as <paintings:title>.
I mention namespaces here primarily because all XSLT elements we use in this book are prefixed with the xsl namespace prefix. All stylesheets we write begin like this:
<?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
This opening associates the xsl namespace prefix with the string http://www.w3.org/1999/XSL/Transform. The value of the namespace prefix doesn't matter; we could start our stylesheets like this:
<?xml version="1.0"?> <pdq:stylesheet xmlns:pdq="http://www.w3.org/1999/XSL/Transform" version="1.0">
What matters is the string to which the namespace prefix is mapped. Also keep in mind that all XSLT stylesheets use namespace prefixes to process the XML elements they contain. By default, anything that doesn't use the xsl namespace prefix is not processed -- it's written to the result tree. We'll discuss these topics in more detail as we go through the book.
1.2.3. DOM and SAX
The two most popular APIs used to parse XML documents are the Document Object Model (DOM) and the Simple API for XML (SAX). DOM is an official recommendation of the W3C (available at http://www.w3.org/TR/REC-DOM-Level-1), while SAX is a de facto standard created by David Megginson and others on the XML-DEV mailing list (http://lists.xml.org/archives). We'll discuss these two APIs briefly here. We won't use them much in this book, but discussing them will give you some insight into how most XSLT processors work.
TIP: See http://www.megginson.com/SAX/ for the SAX standard. (Make sure the letters SAX are in uppercase.) If you'd like to learn more about the XML-DEV mailing list, send email with "subscribe xml-dev" in the body of the message to majordomo@xml.org. You can also check out http://www.lists.ic.ac.uk/hypermail/xml-dev to see the XML-DEV mailing list archives.
1.2.3.1. DOM
DOM is designed to build a tree view of your document. Remember that all XML documents must be contained in a single element; that single element becomes the root of the tree. The DOM specification defines several language-neutral interfaces, described here:
- Node
- This interface is the base datatype of the DOM. Element, document, text, comment, and attr all extend the Node interface.
- Document
- This object contains the DOM representation of the XML document. Given a Document object, you can get the root of the tree (the Document element); from the root, you can move through the tree to find all elements, attributes, text, comments, processing instructions, etc., in the XML document.
- Element
- This interface represents an element in an XML document.
- Attr
- This interface represents an attribute of an element in an XML document.
- Text
- This interface represents a piece of text from the XML document. Any text in your XML document becomes a Text node. This means that the text of a DOM object is a child of the object, not a property of it. The text of an Element is represented as a Text child of an Element object; the text of an Attr is also represented that way.
- Comment
- This interface represents a comment in the XML document. A comment begins with <!-- and ends with -->. The only restriction on its contents is that two consecutive hyphens (--) can appear only at the start or end of the comment. Other than that, a comment can include angle brackets (< >), ampersands (&), single or double quotation marks (' "), and anything else.
- ProcessingInstruction
-
This interface represents a processing instruction in the XML document. Processing instructions look like this:
<?xml-stylesheet href="case-study.xsl" type="text/xsl"?> <?cocoon-process type="xslt"?>
Processing instructions contain processor-specific information. The first of the two PIs (PI is XML jargon -- feel free to drop this into casual conversations to impress your friends) is the standard way to associate an XSLT stylesheet with an XML document (more on this in a minute). The second PI is used by Cocoon, an XML publishing framework from the Apache Software Foundation. (If you're not familiar with Cocoon, look at the Cocoon home page at http://xml.apache.org/cocoon.)
When you parse an XML document with a DOM parser, it:
-
Creates objects (Elements, Attr, Text, Comments) representing the contents of the document. These objects implement the interfaces defined in the DOM specification.
-
Arranges these objects in a tree. Each Element in the XML document has some properties (such as the element's name), and may also have some children.
-
Parses the entire document before control returns to your code. This means that for large documents, there is a significant delay while the document is parsed.
The most significant thing about the DOM is that it is based on a tree view of your document. An XSLT processor uses a very similar tree view (with some slight differences, such as the fact that not everything we deal with in XPath and XSLT has the same root element). Understanding how a DOM parser works makes it easier to understand how an XSLT processor views your document.
1.2.3.1.1. A sample DOM tree
DOM, XSLT, and XPath all use tree structures to represent data from an XML document. For this reason, it's important to have at least a casual knowledge of how DOM builds a tree structure. Our earlier <postalcodes> document is shown as a DOM tree in Figure 1-2.

Figure 1-2. DOM tree representation of an XML document
NOTE: The image in Figure 1-2 was produced by the DOMit servlet, an XML validation service available at http://www-106.ibm.com/developerworks/features/xmlvalidatorform.html.
If we want to find different parts of our XML document, sort the subtrees based on the first character of the text of the <postalcode> element, or select only the subtrees in which the text of the <usage-count> element has a numeric value greater than 500, we have to start at the top of the DOM tree and work our way down through the root element's descendants. When we write XSLT stylesheets, we also start at the root of the tree and work our way down.
WARNING: To be honest, the DOM tree built for our document is more complicated than our beautiful picture indicates. The whitespace characters in our document (carriage return/line feed, tabs, spaces, etc.) become Text nodes. Normally it's a good idea to remove this whitespace so the DOM tree won't be littered with these useless Text nodes, but I included them here to give you a sense of the XML document's structure.
1.2.3.2. SAX
The Simple API for XML was developed by David Megginson and others on the XML-DEV mailing list. It has several important differences from DOM:
-
The SAX API is interactive. As a SAX parser processes your document, it sends events to your code. You don't have to wait for the parser to finish the entire document as you do with the DOM; you get events from the parser immediately. These events let you know when the parser finds the start of the document, the start of an element, some text, the end of an element, a processing instruction, the end of the document, etc.
-
SAX is designed to avoid the large memory footprint of DOM. In the SAX world, you're told when the parser finds things in the XML document; it's up to you to save those things. If you don't do anything to store the data found by the parser, it goes into the bit bucket.
-
SAX doesn't provide the hierarchical view of the document that DOM does. If you need to know a lot about the structure of an XML document and the context of a given element, SAX isn't much help. Each SAX event is stateless; that is, a SAX event won't tell you, "Here's some text for the <postalcode> element I mentioned earlier." A SAX parser only tells you, "Here's some text." If you need to know about an XML document's structure, you have to keep track of that information yourself.
The best thing about SAX is that it is interactive. Most of the transformations currently done with XSLT take place on the server. As of this writing, most XSLT processors are based on DOM parsers. In the near future, however, we'll see XSLT processors based on SAX parsers. This means that the processor can start generating results almost as soon as the parse of the source document begins, resulting in better throughput and creating the perception of faster service. Because DOM, XPath, and XSLT all use trees to represent XML documents, DOM is more relevant to our discussions here. Nevertheless, it's useful to know how SAX parsers work, especially as SAX-based XSLT processors begin to rear their speedy little heads.
1.2.4. XML Standards
When we talk about writing stylesheets, we'll work with two standards: XSLT and XPath. XSLT defines a set of primitives used to describe a document transformation, while XPath defines a syntax for describing locations in XML documents. When we write stylesheets, we'll use XSLT to tell the processor what to do, and we'll use XPath to tell the processor what to do it to. Both standards are available at the W3C's web site; see http://www.w3.org/TR/xslt and http://www.w3.org/TR/xpath for more information.
There are other XML-related standards, of course. We'll discuss them here briefly, with a short mention of how (or whether) they relate to our work with XSLT and XPath.
1.2.4.1. XML 1.0
XML 1.0 is the foundation upon which everything else is built. See http://www.w3.org/TR/REC-xml.
1.2.4.2. The Extensible Stylesheet Language (XSL)
Also called the Formatting Objects specification or XSL-FO, this standard deals with rendering XML elements. Although most people think of rendering as formatting for a browser or a printed page, researchers use the specification to render XML elements as Braille or as audio files. (That being said, the main market for this technology is in producing high-quality printed output.) As of this writing, the XSL-FO specification is a Candidate Recommendation at the W3C. A couple of our examples in this book use formatting objects and the Apache XML Project's Formatting Object to PDF translator (FOP) tool; see http://xml.apache.org/fop for more information on FOP. For more information on XSL, see http://www.w3.org/TR/xsl.
1.2.4.3. XML Schemas
In our earlier examples, we had a brief example of an XML Schema. Part 1 of the specification deals with XML document structures; it contains XML elements that define what can appear in an XML document. You use these elements to specify which elements can be nested inside others, how many times each element can appear, the attributes of those elements, and other features. Part 2 of the specification defines basic datatypes used in XML Schemas and rules for deriving new datatypes from existing ones.
The two specifications are available at http://www.w3.org/TR/xmlschema-1 and http://www.w3.org/TR/xmlschema-2. For a good introduction to XML Schemas, see the XML Schema Primer, available at http://www.w3.org/TR/xmlschema-0.
1.2.4.4. The Simple API for XML (SAX)
The SAX API defines the events and interfaces used to interact with a SAX parser. SAX and DOM are the most common APIs used to work with XML documents. See http://www.megginson.com/SAX/ for the complete specification. (Note that the letters "SAX" must be in uppercase.)
1.2.4.5. Document Object Model (DOM) Level 1
The DOM, as we discussed earlier, is a programming API for documents. It defines a set of interfaces and methods used to view an XML document as a tree structure. XSLT and XPath use a similar tree view of XML documents. See http://www.w3.org/TR/REC-DOM-Level-1 for more information.
1.2.4.6. Document Object Model (DOM) Level 2
The DOM Level 2 standard builds on DOM Level 1. It adds several new features:
-
HTML support, providing a DOM view of HTML documents
-
CSS and stylesheet interfaces
-
Document events
-
Tree traversal methods
-
Range selection methods
-
Views of DOM trees, in which the view is separate from the DOM itself
The new features of DOM Level 2 don't affect our work directly. If you read the specification, you'll see that certain features, such as views, stylesheet interfaces, and tree traversal, provide features useful to an XSLT processor. Although future XSLT processors will be built on XML parsers that provide these functions, that won't change any of the techniques we cover in this book. See http://www.w3.org/TR/DOM-Level-2 for the complete specification.
1.2.4.7. Namespaces in XML
As we mentioned earlier, namespaces provide a way to avoid name collisions when two XML elements have the same name. See http://www.w3.org/TR/REC-xml-names for more information.
1.2.4.8. Associating stylesheets with XML documents
It's possible to reference an XSLT stylesheet within an XML document. This specification uses processing instructions to define one or more stylesheets that should be used to transform an XML document. You can define different stylesheets to be used for different browsers. See http://www.w3.org/TR/xml-stylesheet for complete information. Here's the start of an XML document, with two associated stylesheets:
<?xml version="1.0"?> <?xml-stylesheet href="docbook/html/docbook.xsl" type="text/xsl"?> <?xml-stylesheet href="docbook/wap/docbook.xsl" type="text/xsl" media="wap"?>
In this example, the first stylesheet is the default because it doesn't have a media attribute. The second stylesheet will be used when the User-Agent field from the HTTP header contains the string wap, identifying the requester of a document as a WAP browser. The advantage of this technique is that you can define several different stylesheets within a particular document and have each stylesheet generate useful results for different browser or client types. The disadvantage of this technique is that we're effectively putting rendering instructions into our XML document, something we prefer to avoid.
If you use Microsoft Internet Explorer Version 5.0 or higher, you can install the Microsoft's XSLT processor so that opening an XML document in your browser will cause it to be transformed and rendered automatically. For more details on how to install and configure the XML tools to work with the brower, see http://www.microsoft.com/xml. In the previous example, if we opened an XML document that began this way, the browser would transform the XML document according to the rules defined in docbook/html/docbook.xsl and render the results as if it were any HTML page.
1.2.4.9. Scalable Vector Graphics (SVG)
The SVG specification defines an XML vocabulary for vector graphics. Described by some as "PostScript with angle brackets," it allows you to define images that can be scaled to any size or resolution. See http://www.w3.org/TR/SVG/ for details.
1.2.4.10. Canonical XML Version 1.0
Sometimes comparing two XML documents is necessary (when digitally signing an XML document, for example). The Canonical XML specification defines a canonical form of XML that makes comparing two documents easy. See http://www.w3.org/TR/xml-c14n for the complete specification.
1.2.4.11. XML digital signatures
A joint effort of the W3C and the Internet Engineering Task Force (IETF), XML digital signatures provide a mechanism for storing digital signatures in an XML document. The XML document then provides an envelope used to store, send, and retrieve digital signatures for any kind of digital resource. The latest draft of the specification can be found at http://www.w3.org/TR/xmldsig-core.
1.2.4.12. XML Pointer Language (XPointer) Version 1.0
XPointer provides a way to identify a fragment of a web resource. It uses XPath to identify fragments. For details, see http://www.w3.org/TR/xptr.
1.2.4.13. XML Linking Language (XLink) Version 1.0
XLink defines an XML vocabulary for linking to other web resources within an XML document. It supports the unidirectional links we're all familiar with in HTML, as well as more sophisticated links. See http://www.w3.org/TR/xlink/.
|  | |
| 1. Getting Started |  | 1.3. Installing Xalan |

Copyright © 2002 O'Reilly & Associates. All rights reserved.