
 |  |
Chapter 9. XPath
Contents:
The Tree Structure of an XML Document
Location Paths
Compound Location Paths
Predicates
Unabbreviated Location Paths
General XPath Expressions
XPath Functions
XPath is a non-XML language for identifying particular parts of XML documents. XPath lets you write expressions that refer to the first person element in a document, the seventh child element of the third person element, the ID attribute of the first person element whose contents are the string "Fred Jones", all xml-stylesheet processing instructions in the document's prolog, and so forth. XPath indicates nodes by position, relative position, type, content, and several other criteria. XSLT uses XPath expressions to match and select particular elements in the input document for copying into the output document or further processing. XPointer uses XPath expressions to identify the particular point in or part of an XML document to which an XLink links. The W3C XML Schema Language uses XPath expressions to define uniqueness and co-occurrence constraints. XForms relies on XPath to bind form controls to instance data, express constraints on user-entered values, and calculate values that depend on other values.
XPath expressions can also represent numbers, strings, or Booleans. This lets XSLT stylesheets carry out simple arithmetic for purposes such as numbering and cross-referencing figures, tables, and equations. String manipulation in XPath lets XSLT perform tasks such as making the title of a chapter uppercase in a headline or extracting the last two digits from a year.
9.1. The Tree Structure of an XML Document
An XML document is a tree made up of nodes. Some nodes contain one or more other nodes. There is exactly one root node, which ultimately contains all other nodes. XPath is a language for picking nodes and sets of nodes out of this tree. From the perspective of XPath, there are seven kinds of nodes:
-
The root node
-
Element nodes
-
Text nodes
-
Attribute nodes
-
Comment nodes
-
Processing-instruction nodes
-
Namespace nodes
One thing to note are the constructs not included in this list: CDATA sections, entity references, and document type declarations. XPath operates on an XML document after all these items have been merged into the document. For instance, XPath cannot identify the first CDATA section in a document or tell whether a particular attribute value was directly included in the source element start-tag or merely defaulted from the declaration of the element in a DTD.
Consider the document in Example 9-1. This exhibits all seven kinds of nodes. Figure 9-1 is a diagram of the tree structure of this document.
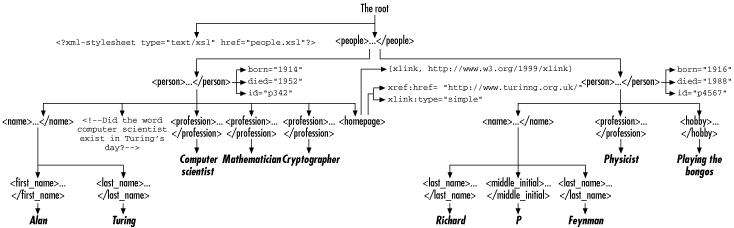
Figure 9-1. The tree structure of Example 9-1
Example 9-1. The example XML document used in this chapter
<?xml version="1.0"?>
<?xml-stylesheet type="application/xml" href="people.xsl"?>
<!DOCTYPE people [
<!ATTLIST homepage xlink:type CDATA #FIXED "simple"
xmlns:xlink CDATA #FIXED "http://www.w3.org/1999/xlink">
<!ATTLIST person id ID #IMPLIED>
]>
<people>
<person born="1912" died="1954" id="p342">
<name>
<first_name>Alan</first_name>
<last_name>Turing</last_name>
</name>
<!-- Did the word computer scientist exist in Turing's day? -->
<profession>computer scientist</profession>
<profession>mathematician</profession>
<profession>cryptographer</profession>
<homepage xlink:href="http://www.turing.org.uk/"/>
</person>
<person born="1918" died="1988" id="p4567">
<name>
<first_name>Richard</first_name>
<middle_initial>P</middle_initial>
<last_name>Feynman</last_name>
</name>
<profession>physicist</profession>
<hobby>Playing the bongoes</hobby>
</person>
</people>The XPath data model has several nonobvious features. First of all, the root node of the tree is not the same as the root element. The root node of the tree contains the entire document including the root element, as well as any comments and processing instructions that occur before the root element start-tag or after the root element end-tag. In Example 9-1, this means the root node contains the xml-stylesheet processing instruction, as well as the root element people.
However, the XPath data model does not include everything in the document. In particular, the XML declaration, the DOCTYPE declaration, and the various parts of the DTD are not addressable via XPath, though if the DTD provides default values for any attributes, then those attributes are noted by XPath. The homepage element has an xlink:type attribute that was supplied by the DTD. Similarly, any references to parsed entities are resolved. Entity references, character references, and CDATA sections are not individually identifiable, though any data they contain is addressable. For example, XSLT cannot make all the text in CDATA sections bold because XPath doesn't know which text is and isn't part of a CDATA section.
Finally, xmlns and xmlns:prefix attributes are not considered attribute nodes, even though that's how a non-namespace-aware parser will see them. However, namespace nodes are attached to every element and attribute node for which a declaration has scope. They are not only attached to the single element where the namespace is declared.
|  | |
| 8.11. Other XSLT Elements |  | 9.2. Location Paths |

Copyright © 2002 O'Reilly & Associates. All rights reserved.