
 |  |
2.2. Beginning SAX
This chapter explores SAX through some progressively more functional examples, which build on each other to present the key concepts that are discussed later in more detail. Essential producer and consumer interfaces are presented together to show how they interact, and you'll see how to customize classic SAX configurations. We'll focus first on the producer side, saving most details about consumer-side APIs for a bit later.
2.2.1. How Do the Parts Fit Together?
In the simplest possible example, you (in your role as director) will get an XML parser, which will later produce parsing events. Then you will get a consumer and connect it to the producer for processing the most important events. Finally, you'll ask that parser to produce events, pushing them through to the consumer.
To start, focus on what the different parts are, and how they relate to each other. Example 2-1 is a simple SAX program, which you can compile and run if you like.
Example 2-1. SAX2 application skeleton
import java.io.IOException;
import org.xml.sax.*;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;
public class Skeleton {
// argv[0] must be the absolute URL of an XML document
public static void main (String argv [])
{
XMLReader producer;
DefaultHandler consumer;
// Get an instance of the default XML parser class
try {
producer = XMLReaderFactory.createXMLReader ();
} catch (SAXException e) {
System.err.println (
"Can't get parser, check configuration: "
+ e.getMessage ());
return;
}
// Set up the consumer
try {
// Get a consumer for all the parser events
consumer = new DefaultHandler ();
// Connect the most important standard handler
producer.setContentHandler (consumer);
// Arrange error handling
producer.setErrorHandler (consumer);
} catch (Exception e) {
// Consumer setup can uncover errors,
// though this simple one shouldn't
System.err.println (
"Can't set up consumers:"
+ e.getMessage ());
return;
}
// Do the parse!
try {
producer.parse (argv [0]);
} catch (IOException e) {
System.err.println ("I/O error: ");
e.printStackTrace ();
} catch (SAXException e) {
System.err.println ("Parsing error: ");
e.printStackTrace ();
}
}
}This is a complete SAX application, though it's sort of boring since it throws away all the data the parser delivers. The only reason this program would print anything at all is if you didn't pass it an argument that was the URL for a well-formed XML file. Other than that, it's fairly typical of how you'll be using SAX2, at least in terms of the basic structure. You can make real programs from this skeleton if you substitute smarter components for the simple ones shown here.
We introduced a few SAX classes and interfaces, so we can add some details to our earlier producer/consumer picture to get Figure 2-2. This producer is an XMLReader, and we're listening to one consumer interface and the ErrorHandler. The whole thing is driven by an application which is pulling the whole document through the reader.
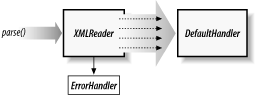
Figure 2-2. Basic SAX roles and components
- XMLReader producer;
The most common type of SAX2 event producer is an XML parser. Like most parsers, XML parsers implement the XMLReader interface. Whether or not they parse actual XML (instead of HTML or something else), they are required to produce events as if they did.
Don't confuse this class with the java.io.Reader from which you can pull a stream of character data. SAX parsers produce streams of SAX events, which they push to event consumers. Those are rather different models for how to deliver data.
- producer = XMLReaderFactory.createXMLReader ();
This is the best all-around SAX2 bootstrap API when you need an XML parser. The only time it should produce any kind of exception is when your environment is misconfigured. For example, you might need to set the org.xml.sax.driver system property to the class name for your parser (see Section 3.2.1, "The XMLReaderFactory Class" in Chapter 3, "Producing SAX2 Events").
You can (and should!) keep reusing this XMLReader, but you should only have one thread touch a parser at a time. That is, parsing is not re-entrant. Parsers are perfectly safe to use with multiple threads, except that two threads can't use the same parser at the same time. (That's a good rule of thumb for most objects in multithreaded code, in all programming languages; it should feel natural to apply that rule to SAX parsers.)
- consumer = new DefaultHandler ();
The DefaultHandler class is particularly handy when you're just starting to use SAX. It implements most of the event consumer interfaces, providing stubbed out (no-op) implementations for each method that's not part of an extension handler. That means it's easy to subclass this method if you need a place to start: just override each stub method to provide real code when you need it. We'll use DefaultHandler to avoid presenting extra callback methods.
- producer.setContentHandler (consumer);
In this chapter, we're only showing the most commonly used consumer interfaces. ContentHandler is used to report elements, attributes, and characters; that's enough to get almost all serious XML work done.
- producer.setErrorHandler (consumer);
ErrorHandler lets applications control handling of various kinds of errors, and we'll need it in later examples. We'll usually look at error handling as a specialized kind of task, different from other consumer roles. Even though "handler" is part of its name, it's a different kind of object.
- producer.parse (argv [0]);
This call tells a parser to read the XML text found at a particular fully qualified URL. There's another call you'll use when you don't have a URL for that text, but most of the time this is the call you ought to use. If you're tempted to pass filenames or relative URIs, just say no! Filenames need to be converted to URLs first (see Section 3.1.3, "Filenames Versus URIs" in Chapter 3, "Producing SAX2 Events"), and relative URIs must be converted to absolute ones.
Parsing can report exceptions. This is important, and not just because it's the only way that a chunk of code like this (using just an XMLReader) could seem to "do" anything. Normally, those exceptions will be thrown only for fatal errors, such as well-formedness errors in an XML document, or for document I/O problems.
The application thread is "pulling" the XML text through the XMLReader-style producer: the parse() call won't return until the whole document is parsed, or until parsing is aborted by throwing an exception. Until it returns, the thread that called the XMLReader is either blocking on I/O, parsing data that it just read, or "pushing" data into one of the consumer interfaces. That is, from the perspective of event consumers SAX2 is a "push" API: handlers do nothing until they're asked.
2.2.2. What Are the SAX2 Event Handlers?
SAX2 events are grouped into several interfaces, which we explore later in more detail. All except two are implemented by DefaultHandler. Each interface encapsulates a set of events; to see those events, applications give parsers objects that implement the handler interfaces they're interested in.
- org.xml.sax.ContentHandler
Essentially every significant use of SAX2 involves this handler. The element and character data callbacks (discussed later in this chapter) are defined in this interface, as are callbacks for most other SAX2 events for general-purpose data. Many SAX2 applications will focus primarily on this interface. If you only need the core XML data model (elements, attributes, and text), this could be the only handler you use.
- org.xml.sax.ext.DeclHandler
This handler reports DTD declarations that aren't exposed through DTDHandler (or in one case LexicalHandler) callbacks: declarations for elements, attributes, and parsed entities.
Because it is an extension handler, it won't necessarily be recognized by all SAX2 parsers, and DefaultHandler doesn't provide no-op implementations for its callbacks.
- org.xml.sax.DTDHandler
This handler reports DTD declarations that the XML 1.0 specification requires all processors to expose: declarations for notations and for unparsed entities. Most applications won't use this interface unless they're connected to SGML-based infrastructure that depends on such tools. This is probably the most exotic SAX handler interface; web-oriented XML applications will use MIME types instead of notations and URIs instead of unparsed entities.
- org.xml.sax.ErrorHandler
The events reported by this class are errors and warnings. These behaviors are part of XML, but not part of the data model so they don't show up in the Infoset. Grouping these events in one interface lets application code centralize treatment of XML or application data errors. After ContentHandler, it's probably the most important SAX2 handler. It's also usefully managed apart from other handlers, so in this book it's usually not lumped with "real" handlers. (This interface is discussed later in this chapter.)
- org.xml.sax.ext.LexicalHandler
This interface mostly exposes information that is intended to be semantically meaningless, such as comments and CDATA section boundaries, as well as entity and DTD boundaries.
Because it is an extension handler, it won't necessarily be recognized by all SAX2 parsers, and DefaultHandler doesn't provide no-op implementations for its callbacks.
With the exception of ErrorHandler, you'll normally want to work with all of these interfaces as a single group: four interfaces, two for content in the document body and two for DTD content. That way, you will work with all the XML data from a document (its Infoset) as part of a cohesive whole. There are SAX2 helper classes (like DefaultHandler and XMLFilterImpl) that group most of these interfaces into classes, but they ignore the two extension handlers (Decl and Lexical handlers in the org.xml.sax.ext package). SAX2 application layers often handle such grouping; for example, you can subclass those helper classes in a different package, adding extension interface support.
The logic behind keeping these interfaces separate, rather than merging all of their methods into one huge interface, is that it's more appropriate for simple applications. You must explicitly ask for bells and whistles; they aren't thrust upon you by default. You can easily prune out certain data by ignoring the interfaces that report it. Most code only uses ContentHandler and ErrorHandler implementations, so the methods in other interfaces are easy to ignore. Plus, from the application perspective, parser recognition of the extension handlers isn't guaranteed. There's a slight awkwardness associated with needing to bind each type of handler separately, but that's a small trade-off for the benefit of having a modular API extension model already in place.
SAX2 defines another important interface beyond these handlers and the XMLReader: parsers use EntityResolver to retrieve external entity text they must parse. That interface is also stubbed out by DefaultHandler. If you want the parser to use local copies of DTDs rather than DTDs accessed from a server that might not be available, you'll want to become familiar with EntityResolver. However, it isn't really a consumer API since it doesn't deal directly with parsed XML data (the Infoset); it deals with accessing raw unparsed text, the same stuff that's given to XMLReader.parse() methods. This book presents it as a producer-side helper for parsers, in Section 3.4, "The EntityResolver Interface" in Chapter 3, "Producing SAX2 Events".
2.2.3. XMLWriter: an Event Consumer
The next part of SAX we show in this overview is really not a part of SAX, except that it uses SAX to do something you'll likely need to do fairly often. (Pretty much everyone does!) As you've seen, SAX2 includes an XMLReader interface, used to turn XML text into a stream of SAX events. But it does not include the corresponding XMLWriter to reverse the process: turning such events back into text and supporting XML for program outputs as well as inputs. SAX isn't only for reading XML. The same APIs are used to write XML too.
It's almost a tradition to show how to write most of such a class as an example when explaining SAX. We avoid that in this book because getting all the XML details right is tricky, and because this class is a clear example of something that should be treated as a reusable SAX library component. There are lots of ways the data needs to be escaped, and sometimes you need to use output encodings (like ASCII) that have problems representing some XML characters.
There's a better solution: use one of several such classes, which are widely available. This book uses the gnu.xml.util.XMLWriter class (bundled with gnujaxp.jar andÆlfred) when it needs XML generation functionality, because it doesn't force applications to discard as much of the XML data. It supports all of the SAX2 handlers, including the extension handlers LexicalHandler and DeclHandler, so it can round-trip almost all XML data. To use such classes, at least in their simple low-fidelity modes, you can modify the skeleton program shown earlier to something like this:
import java.io.FileOutputStream;
import gnu.xml.util.XMLWriter;
public class ... {
...
setContentHandler (
new XMLWriter (new FileOutputStream ("out.xml"))
);
...
}In addition to the GNU class used in this book, other versions are available. One is provided with DOM4J org.dom4j.io.XMLWriter, which supports Content and Lexical handlers and evolved from the com.megginson.sax.XMLWriter class, which supports only ContentHandler. Curiously, neither Crimson nor Xerces include such SAX-to-text functionality at this time.
2.2.3.1. Event pipelines
Of course, just parsing and echoing data is not very useful. Such classes are best used to output XML data that you've massaged a bit. We'll look at two ways to do this later. One way is to use an XML pipeline, where consumers produce data for other consumers, as illustrated in Figure 2-3. For example, one stage could filter the event stream from a parser to remove various uninteresting elements, or otherwise transform the data, and then feed the result to an XMLWriter. You can combine several such stages into a "pipeline" and debug them using an XMLWriter to watch data as it flows through particular stages. Remember that XMLReader isn't the only kind of SAX event producer: programs can write events and feed the result to an XMLWriter. Also, the consumer doesn't need to be an XMLWriter; it could construct any kind of useful data structure. In fact we'll look later at doing this with DOM.

Figure 2-3. Simple SAX2 event pipeline
This kind of processing pipeline is a fundamental model for more advanced uses of SAX and for structuring components that are SAX-aware. We look at pipelines again in Section 4.5, "XML Pipelines " in Chapter 4, "Consuming SAX2 Events". For now, keep in mind that sometimes event consumers will be producing events for later processing components.
2.2.3.2. Concerns when writing XML text
There are several important issues to consider when writing XML output, which should be mentioned in the documentation for the XMLWriter you use. You may even be able to use your XMLWriter to canonicalize output, so you can safely compare processor output or create digital signatures. The GNU class shown earlier handles most of these directly, but that's not true for all such classes.
You need the flexibility to choose different line endings, such as Macintosh style (CR only), DOS style (CRLF), and Unix style (LF only). The default should be right for the host Operating System, but sometimes that's not right for the destination.
The SAX2 event stream might discard essential namespace prefix information. If you're using documents with namespaces, you need to provide a sanitized event stream, making sure either that such data is not discarded (using the "mixed mode" namespace handling discussed later in this chapter) or that corresponding data gets synthesized (maybe in some pipeline stage).
You might be sending XML to applications that don't handle DTDs or external entities very well. For example, many web browsers won't read DTDs. To talk robustly to such applications, you might need to send standalone documents.
If your application just uses ContentHandler events, you'll have discarded information needed to re-create "high-fidelity" output reflecting DTD content, comments, entity references, and CDATA section boundaries. More handlers are detailed in Chapter 4, "Consuming SAX2 Events" as well as and briefly summarized later in this section; most of the writers implement many such interfaces.
If you don't want to use UTF-8 as your character encoding (or UTF-16), you'll have to be sure the names used by your markup can be expressed using that character encoding. That's because while numeric character references can be used inside text, they can't be used inside markup components like element and attribute names. ASCII, for example, is hopeless at handling element names that use Japanese ideographic characters, but it can handle Japanese text if you don't mind that every character in the document text is cryptically expressed as a numeric character reference.
The first time you try to debug XML output where a single line is even just a few kilobytes in length, you'll want your XMLWriter to be "pretty printing." Minimally it should add line breaks; ideally it should be able to indent to show document structure.
Such an XMLWriter is part of almost every developer's SAX toolkit, even though it isn't part of SAX itself. As you work with SAX, you'll probably start to collect and develop your own library of such reusable event consumer code.
|  | |
| 2. Introducing SAX2 |  | 2.3. Basic ContentHandler Events |

Copyright © 2002 O'Reilly & Associates. All rights reserved.