
 |  |
Chapter 1. The Simple API for XML
Contents:
Types of XML APIs
Why Choose SAX?
Why Not to Choose SAX?
A Short History of SAX
Packages in the SAX2 API
Some Popular SAX2 Parser Distributions
Installing a SAX2 Parser
What XML Are We Talking About?
When XML started, Java was best known as a fun new language that made developing programs for the World Wide Web easy. XML was intended to be the data foundation for the next generation of web infrastructure tools, and it clearly needed the same kind of support that Java offered. The Java programming environment included ways to fetch data over the Web with URLs, which was a novel notion at that. It even had support for Unicode, so working with languages used anywhere on the Web would be easy. Since both those capabilities were important for working with XML, there was already a very active community of XML developers using Java when the XML 1.0 Recommendation was finalized in early 1998. More XML parsers were available at that time for Java than for the more widely adopted C programming language!
Those parsers quickly came to share one feature: applications weren't restricted to some particular product's API. The Simple API for XML, SAX, was well under way; it was the first API usable with all the popular Java parsers. SAX helped make Java a premiere language for developing XML-based applications.
Since then the adoption of XML has exploded, as has the use of Java in web-oriented (and other) applications. Today's Java programmer has an embarrassingly large selection of XML-related APIs to choose from, and SAX has retained its role as a premier XML API. In this chapter we look at why this is true, and learn more about where SAX came from and its current state.
1.1. Types of XML APIs
An Application Programming Interface (API) is a set of interfaces and classes used to expose particular functionality to a variety of applications. Some APIs are specific to particular products. Better Java APIs, like SAX, use the interface facility to work with multiple products: they are defined so that multiple implementations can coexist. Such implementations behave the same except for differences allowed by the API. For example, one might be faster, while another might leverage private interfaces to some subsystem. (In that case an application could use the fast implementation most of the time and the slower one only when those added features are needed.) APIs differ in how they expose functionality, which affects how well applications work.
For the purposes of this book, there are two kinds of APIs to XML. We'll call one a "parser API" and the other a "high-level API." Parser-level APIs model documents in terms of XML notions such as elements, attributes, and character data, and hide all the details of actually turning XML text into information that applications can use. High-level APIs generally focus on non-XML notions, usually to make XML itself seem only an implementation artifact that might be easily replaced by other data interchange technology, or more rarely, by another document technology. This spectrum is not as wide as you might expect. Parser-level APIs are well-suited for working with XML-centric applications, higher-level APIs try to focus on particular visions of the data being encoded with XML, and some APIs "hop" between levels.
SAX is a parser-level API that is rather unique in flavor because it leaves all data structure choices up to higher levels. This feature helps scale XML applications, since it lets SAX be an unobtrusive and extremely effective building block. SAX models documents in terms of a stream of event callbacks; this has been called an "active" API. The events are more structured than the stream of mouse and keyboard events you may know from AWT or Swing. Events are sent to application handlers for basic XML content (such as elements and characters) in exactly the order they're found in the document, as shown in Figure 1-1. That's the same order in which you'd traverse a tree model of that markup: you'd start an element, look at its children, and then end the element.
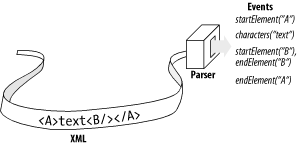
Figure 1-1. A streaming parser API
Most other parser-level APIs provide a generic, object tree data structure mirroring the parse tree; these have been called "passive" APIs. Figure 1-2 shows some XML text, and its transformation to such a data structure.
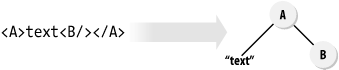
Figure 1-2. An object tree parser API
Examples of such generic data structures include W3C's DOM and more Java-friendly variants such as DOM4J and jDOM. Such generic tree structures are usually built with the output of an underlying SAX parser, and so are slightly higher level than SAX. However, these generic structures place significant constraints on application structure and scalability. A popular alternative approach involves building custom data structures from that same SAX output, instead of generic ones, larger than some fraction of available virtual memory. Because the data structures are custom built, they tend to be faster and more task-appropriate than structures built by generic APIs.
|  | |
| 0.5. Acknowledgments |  | 1.2. Why Choose SAX? |

Copyright © 2002 O'Reilly & Associates. All rights reserved.