
 |  |
9.3. Performance Techniques
One common criticism of XSLT is its performance. The overhead of transformation from XML to another format is the price paid for clean separation between data and programming logic, as well as the ability to customize transformations for different clients. In this section, we look at strategies for improving performance without giving up the benefits that XSLT offers.
The actual XSLT transformation is not always the root of performance problems. XML parsers have a significant impact on performance, along with many other factors such as database access time, time spent processing business logic, and network latency.
Obsessing over performance can be a dangerous trap to fall into. Focusing too heavily on optimization techniques often results in code that is difficult or impossible to understand and maintain. From a strictly technical viewpoint, the fastest technology sounds great. From a business viewpoint, time to market and maintainability are often far more important than runtime performance metrics. An application that meets performance requirements and is easy to maintain over the years makes better business sense than a highly tuned, cryptic application that runs fast but cannot be modified because the original author quit the company and nobody can figure out the code.
9.3.1. Stress Testing with JMeter
One good way to measure overall application throughput is to simulate how real users use an application. Apache's JMeter is designed to perform this task for web applications, measuring response time as the number of concurrent users increases. JMeter is written in Java and can display response time graphically as shown in Figure 9-8.
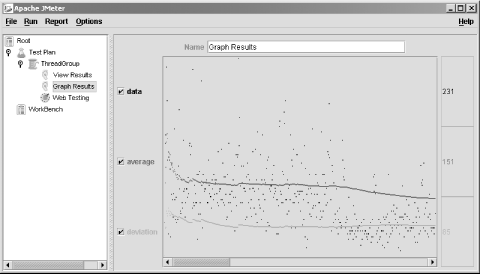
Figure 9-8. JMeter output
It should be noted that this is the output from Version 1.6 Alpha of JMeter, so later versions may change significantly. The GUI interface has been completely rewritten for Version 1.6, and many features are unfinished as this book is being written. On this display, the dots represent actual response times, the top line represents the average response time, and the bottom line represents the standard deviation from average.
Of the measurements shown on the graph, the average response time is the most useful. The numbers to the right are in milliseconds, so we can see that the average response time for this web application is 151 milliseconds. When using a tool such as JMeter, it is best to leave the stress test running for several minutes until the average response time stabilizes. It generally takes much longer for the first few tests to run because Java is loading classes, starting threads, and allocating memory. Over time, performance will fluctuate as the garbage collector runs and VMs such as HotSpot optimize code. Unless the application has memory leaks or simply cannot keep up with demand, the response time should eventually level off.
Table 9-3 shows how the View Month page from the discussion forum example in Chapter 7, "Discussion Forum" fared when tested with JMeter. In this table, worst case and best case scenarios are shown. Other combinations of servlet container, XSLT processor, and database are not shown. The number of threads in the fourth column indicates the number of simulated users. In the final column, lower numbers are better.
Table 9-3. View month response time
|
Servletcontainer |
XSLTprocessor |
Database |
Threads |
Average responsetime (ms) |
|---|---|---|---|---|
|
Tomcat 3.2.1 |
Xalan 2.0 |
Access 2000 |
1 |
130 |
|
'' |
'' |
'' |
5 |
320 |
|
'' |
'' |
'' |
10 |
760 |
|
'' |
'' |
'' |
20 |
1600 |
|
Tomcat 4.0 |
SAXON 6.2.2 |
MySQL |
1 |
18 |
|
'' |
'' |
'' |
5 |
150 |
|
'' |
'' |
'' |
10 |
320 |
|
'' |
'' |
'' |
20 |
610 |
This table does not paint the complete picture. However, it should illustrate the point that in many cases, merely changing to different tools and libraries can dramatically improve performance. For the measurements shown, JMeter was instructed to simulate up to 20 concurrent users with absolutely zero delay between requests. JMeter can also be configured to insert fixed or random delays between requests, which tends to be much more representative of real-world conditions.
The goal of this test was not to benchmark the performance of the discussion forum, but rather to compare the relative performance when switching to different tools.[52] Over a period of many hours, the discussion forum was restarted with various combinations of servlet containers, XSLT processors, and databases. Although Tomcat 4.0 and SAXON 6.2.2 tend to be slightly faster than Tomcat 3.2.1 and Xalan 2.0, the most dramatic performance delta occurs when switching from Microsoft Access to MySQL.
[52] Because XSLT processors and servlet containers are changing so fast, the actual tool names are not listed here.
9.3.2. More Detailed Measurements
In the previous example, the overall performance of an application was measured with Apache's JMeter. This is a great way to prove that an application scales well under stress, and it allows for comparisons between different software, hardware, and database configurations. If you reach a point where an application is simply not scaling as required, however, additional techniques must be employed to isolate bottlenecks within Java code. Tools such as JMeter show performance from an end user's perspective, rather than on a per-method basis within a Java application.
9.3.2.1. Commercial options
One approach is to purchase a commercial profiling tool such as Sitraka's JProbe, available from http://www.sitraka.com, or VMGear's OptimizeIt from http://www.vmgear.com. Among other things, these tools can report how many times each method in an application is called, how much time is spent in each method, and how much memory is allocated. The huge advantage of tools such as these is their unique ability to tell you exactly where the hotspots are within Java code. In general, a small fraction of methods consumes a vast majority of resources.[53] Optimizing these specific methods often yields the biggest performance gains with the least amount of effort.
[53] Typically referred to as the 80/20 rule.
9.3.2.2. JVMPI
Sun's Java 2 SDK offers a set of command-line options that enable the Java Virtual Machine Profiling Interface (JVMPI), which can write detailed profiling information to a log file as an application runs. Example 9-13 shows the Help page reported by typing the command: java -Xrunhprof:help.
Example 9-13. JVMPI command-line options
C:\>java -Xrunhprof:help Hprof usage: -Xrunhprof[:help]|[<option>=<value>, ...] Option Name and Value Description Default --------------------- ----------- ------- heap=dump|sites|all heap profiling all cpu=samples|times|old CPU usage off monitor=y|n monitor contention n format=a|b ascii or binary output a file=<file> write data to file java.hprof(.txt for ascii) net=<host>:<port> send data over a socket write to file depth=<size> stack trace depth 4 cutoff=<value> output cutoff point 0.0001 lineno=y|n line number in traces? y thread=y|n thread in traces? n doe=y|n dump on exit? y Example: java -Xrunhprof:cpu=samples,file=log.txt,depth=3 FooClass
Although this is only an experimental feature of the JVM, it is useful when other tools are not available. To locate processor bottlenecks, the cpu option should be set to samples, which uses statistical estimates based on periodic samples of performance. It defaults to off because this feature can significantly decrease performance.
Example 9-14 lists a very small portion of the output from a single run of a Java application using the JVMPI feature. This section ranks the methods according to which consume the most time. For instance, a method that takes 20 ms to execute but is called millions of times will probably rank very high on this list, while a method that consumes one second but is only called once will be much further down on the list.
Example 9-14. Partial JVMPI output
rank self accum count trace method
1 13.70% 13.70% 20 31 java.lang.ClassLoader.defineClass0
2 7.53% 21.23% 11 19 java.util.zip.ZipFile.getEntry
3 5.48% 26.71% 8 35 java.io.Win32FileSystem.getBooleanAttributes
4 4.11% 30.82% 6 26 java.util.zip.ZipFile.read
5 3.42% 34.25% 5 92 java.util.zip.Inflater.inflateBytes
6 3.42% 37.67% 5 6 java.lang.ClassLoader.findBootstrapClass
7 2.74% 40.41% 4 22 java.util.zip.ZipFile.getEntry
8 2.74% 43.15% 4 143 org.apache.xalan.templates
StylesheetRootnewTransformer
9 2.74% 45.89% 4 14 java.util.zip.ZipFile.open
10 1.37% 47.26% 2 4 java.net.URLClassLoader.defineClassThe actual file will grow to many megabytes in size, depending on how large an application is and how long the profiler runs. As expected, a difficult task is filtering through a file of this size to find bottlenecks that are actually caused by an application's code rather than by the Java class libraries.
A majority of the JVMPI output file consists of stack traces. A number identifies each trace, and the depth command-line option affects how many lines are displayed for each stack trace. The fifth column of data in Example 9-14 contains the trace number, making it possible to search through the file for the actual stack trace:
TRACE 31: java.lang.ClassLoader.defineClass0(ClassLoader.java:Native method) java.lang.ClassLoader.defineClass(ClassLoader.java:486) java.security.SecureClassLoader.defineClass(SecureClassLoader.java:111) java.net.URLClassLoader.defineClass(URLClassLoader.java:248) java.net.URLClassLoader.access$100(URLClassLoader.java:56) java.net.URLClassLoader$1.run(URLClassLoader.java:195)
By making the stack trace depth larger, it is more likely that some of your code will show up somewhere in the report. This makes the report much larger, however. These traces are useful because they show which methods are called leading up to each hotspot.
Companies that have the budget to do so should definitely consider purchasing a tool such as JProbe or OptimizeIt. Although the JVMPI interface offers much of the same functionality that these tools offer, JVMPI output is entirely textual, requiring quite a bit of manual detective work to isolate problems. The commercial profiling tools also require some analysis but present the results in a graphical format that is substantially easier to navigate.
9.3.2.3. Unit testing
The effectiveness of simpler approaches to measurement should not be dismissed. Often, the easiest technique is to simply write a 15-line Java program that tests a specific piece of functionality. For instance, you might want to start with a short Java program that performs an XSLT transformation as shown in Chapter 5, "XSLT Processing with Java". Next, use System.currentTimeInMillis( ) to measure the time immediately before and after each transformation. Then simply experiment with different XSLT stylesheets to see which approaches offer the best performance.
Similar standalone tests can be written for various database access routines, key pieces of business logic, and code that generates XML. Since JUnit reports the time spent in each unit test, you may want to combine these performance metrics with meaningful unit tests.
Regardless of how these individual test routines are written, it is critical that the first runs are ignored. This is because the results will be greatly skewed by Java class loading and initialization time. A good approach is to execute the unit test once before recording the system time. Then execute the test many thousands of times, recording the overall time at the end of the runs. The average response time, calculated by dividing the total time by the number of runs, will be much more accurate than taking a few isolated measurements.
Another point to consider is caching. In a real application, data may change with every single request, making it difficult to cache the transformation result. Unit tests that repeatedly transform the same file are not a good representation of real-world behavior because the processor may cache the transformation result and report artificially high performance.
9.3.3. Using XSLT Processors Effectively
Measuring performance is the first step towards making Java and XSLT applications faster. Once the bottlenecks have been located, it is time to fix the problems.
9.3.3.1. Stylesheet caching
As mentioned several times in this book, caching XSLT stylesheets is an essential performance technique. JAXP includes the Templates interface for this purpose, and we already saw the implementation of a stylesheet cache in Chapter 5, "XSLT Processing with Java". Table 9-4 illustrates the performance gains seen when using the Templates interface to transform a small XML file repeatedly. For this test, the same transformation is performed 100 times using various programming techniques.
Table 9-4. Benefits of caching
|
Processor |
No templates |
Templates |
Templates and cached XML |
|---|---|---|---|
|
Xalan 2.0 |
71.8ms |
45.9ms |
39.2ms |
|
SAXON 6.2.2 |
52.7ms |
37.3ms |
34.2ms |
In the "No templates" column, the Templates interface was not used for transformations. As you can see, this resulted in the slowest performance because the stylesheet had to be parsed from a file with each transformation. In the next column, a Templates instance was created once and reused for each transformation. As you can see, the performance increased substantially.
In the final column of the table, the XML data was read into memory and cached as a DOM Document. Instead of reparsing the XML file with each request, the same DOM tree was cached and reused for each of the transformations. This yielded a slight performance gain because the XML file did not have to be read from the file system with each transformation.
Although these results seem to imply that SAXON is faster than Xalan, this may be a faulty assumption. Performance can vary greatly depending on how large the input files are and which features of XSLT are used. It is wise to test performance with your application before choosing one set of tools over another.
9.3.3.2. Result caching
When the XML is highly dynamic and changes with each request, XSLT caching may be the best one can hope for. But when the same data is requested repeatedly, such as on the home page for your company, it makes sense to cache the result of the transformation rather than the XSLT stylesheet. This way, the transformation is performed only when the XML or XSLT actually change.
Example 9-15 presents a utility class that caches the results of XSLT transformations. In this implementation, both the XML data and XSLT stylesheet must come from static files. If the timestamp of either file changes, the transformation is performed again. Otherwise, a cached copy of the transformation result is returned to the caller.
Example 9-15. ResultCache.java
package com.oreilly.javaxslt.util;
import java.io.*;
import java.util.*;
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
/**
* A utility class that caches XSLT transformation results in memory.
*
* @author Eric M. Burke
*/
public class ResultCache {
private static Map cache = new HashMap( );
/**
* Flush all results from memory, emptying the cache.
*/
public static synchronized void flushAll( ) {
cache.clear( );
}
/**
* Perform a single XSLT transformation.
*/
public static synchronized String transform(String xmlFileName,
String xsltFileName) throws TransformerException {
MapKey key = new MapKey(xmlFileName, xsltFileName);
File xmlFile = new File(xmlFileName);
File xsltFile = new File(xsltFileName);
MapValue value = (MapValue) cache.get(key);
if (value == null || value.isDirty(xmlFile, xsltFile)) {
// this step performs the transformation
value = new MapValue(xmlFile, xsltFile);
cache.put(key, value);
}
return value.result;
}
// prevent instantiation of this class
private ResultCache( ) {
}
/////////////////////////////////////////////////////////////////////
// a helper class that represents a key in the cache map
/////////////////////////////////////////////////////////////////////
static class MapKey {
String xmlFileName;
String xsltFileName;
MapKey(String xmlFileName, String xsltFileName) {
this.xmlFileName = xmlFileName;
this.xsltFileName = xsltFileName;
}
public boolean equals(Object obj) {
if (obj instanceof MapKey) {
MapKey rhs = (MapKey) obj;
return this.xmlFileName.equals(rhs.xmlFileName)
&& this.xsltFileName.equals(rhs.xsltFileName);
}
return false;
}
public int hashCode( ) {
return this.xmlFileName.hashCode() ^ this.xsltFileName.hashCode( );
}
}
/////////////////////////////////////////////////////////////////////
// a helper class that represents a value in the cache map
/////////////////////////////////////////////////////////////////////
static class MapValue {
long xmlLastModified; // when the XML file was modified
long xsltLastModified; // when the XSLT file was modified
String result;
MapValue(File xmlFile, File xsltFile) throws TransformerException {
this.xmlLastModified = xmlFile.lastModified( );
this.xsltLastModified = xsltFile.lastModified( );
TransformerFactory transFact = TransformerFactory.newInstance( );
Transformer trans = transFact.newTransformer(
new StreamSource(xsltFile));
StringWriter sw = new StringWriter( );
trans.transform(new StreamSource(xmlFile), new StreamResult(sw));
this.result = sw.toString( );
}
/**
* @return true if either the XML or XSLT file has been
* modified more recently than this cache entry.
*/
boolean isDirty(File xmlFile, File xsltFile) {
return this.xmlLastModified < xmlFile.lastModified( )
|| this.xsltLastModified < xsltFile.lastModified( );
}
}
}The key to this class is its transform( ) method. This method takes filenames of an XML file and XSLT stylesheet as arguments and returns the transformation result as a String. If any error occurs, a TransformerException is thrown:
public static synchronized String transform(String xmlFileName,
String xsltFileName) throws TransformerException {The cache is implemented using a java.util.Map data structure, which requires key/value pairs of data. The MapKey helper class is used as the key:
MapKey key = new MapKey(xmlFileName, xsltFileName); File xmlFile = new File(xmlFileName); File xsltFile = new File(xsltFileName);
Next, the value is retrieved from the cache. Another helper class, MapValue, keeps track of the transformation result and when each file was last modified. If this is the first request, the value will be null. Otherwise, the isDirty( ) method determines if either file has been updated:
MapValue value = (MapValue) cache.get(key);
if (value == null || value.isDirty(xmlFile, xsltFile)) {
// this step performs the transformation
value = new MapValue(xmlFile, xsltFile);
cache.put(key, value);
}
return value.result;
}As the comment indicates, constructing a new MapValue causes the XSLT transformation to occur. Unless exceptions are thrown, the result of the transformation is returned to the caller.
When compared to the results shown earlier in Table 9-4, this approach to caching is much faster. In fact, the average response time is less than a millisecond once the initial transformation has been performed.
This approach is quite easy to implement for applications based on a collection of static files but is significantly more difficult for database-driven applications. Since more dynamic applications may generate new XML with each invocation, a generic utility class cannot simply cache the result of the transformation. Stale data is the biggest problem with dynamic caching. When the result of an XSLT transformation is stored in memory and the underlying database changes, the cache must be refreshed for users to see the correct data.
Let's suppose that we want to add result caching to the discussion forum application presented in Chapter 7, "Discussion Forum". Since messages cannot be modified once they have been posted, this should be fairly easy to implement for the View Message page. One easy approach is to keep a cache of a fixed number of messages. Whenever a user views a message, the generated web page is added to the cache. If the cache exceeds a specified number of messages, the oldest entries can be flushed.
For more dynamic pages, such as the Month View page, the database must be queried to determine when the most recent message was posted for that particular message board. If the most recently posted message is newer than the cached web page, the transformation must be performed again using the updated data. As you might guess, this sort of caching must be done on a case-by-case basis, because it is very tightly coupled to the database design.
WARNING: Web applications relying on URL rewriting for session tracking may not be able to cache transformation results. This is because, as outlined in Chapter 8, "Additional Techniques", every URL must be dynamically encoded with the jsessionid when cookies are disabled.
As with any other type of optimization, the benefits of caching must be carefully weighed against the costs of added complexity. The best approach is to analyze log files to see which pages are requested most often and to focus optimization efforts there.
9.3.4. Writing Effective XSLT
A big performance hit can be incurred during the XSLT transformation process. For large XML documents in particular, try to avoid situations where large portions of the tree must be processed repeatedly. The // operator can be particularly dangerous:
<xsl:apply-templates select="/.//name"/>
In this statement, the entire document is recursively searched for all <name> elements, beginning at the root. The XSLT processor has no way of knowing where <name> might appear, so it must check every node in the document. If the specific path is known, a more efficient approach is:
<xsl:apply-templates select="/company/employee/name"/>
Variables can also be used to improve performance. For example, key pieces of data may be copied to the result tree several times. Do not do this each time the company owner's name must be displayed:
<xsl:value-of select="/company/owner/name/last"/> <xsl:text> </xsl:text> <xsl:value-of select="/company/owner/name/first"/>
Instead, assign the name to a variable once and reuse that variable throughout the stylesheet. This has the added benefit of making the XSLT more readable:
<!-- output the value of the companyOwner variable --> <xsl:value-of select="$companyOwner"/>
Another common tip is to write inline code wherever possible. Instead of using <xsl:apply-templates> to recursively process XML data, use <xsl:value-of> to directly output the current node. This approach may result in duplicate code, however; a key reason to use templates is to modularize a stylesheet into reusable pieces of functionality. This is a good example of the tradeoff between code maintenance and raw performance that developers are often faced with.
Sorting within the XSLT may introduce performance problems, primarily because the entire node set must be sorted before any content can be output to the result tree. If it is easy to pre-sort the XML content using Java code, the XSLT processor may be able to transform the document using less memory by outputting some of the result tree before the entire document is processed.
Finally, writing smaller XSLT stylesheets is a great way to improve performance. Cascading style sheets (CSS) should be used whenever possible, because the CSS style instructions can be stored in a separate file, thus keeping the XSLT and result tree much smaller. JavaScript functions can also be placed in a separate file, eliminating the need to embed the JavaScript code within the stylesheet.
CSS was used in this manner back in Chapter 7, "Discussion Forum" for the discussion forum example. It is worth mentioning again that CSS is used only for defining styles, such as font colors, indentation, alignment, and colors. Many of these styles can also be defined directly in HTML, for instance:
<h1 align="center">Some Heading</h1>
By defining the alignment in a separate CSS file, however, the HTML is reduced to:
<h1>Some Heading</h1>
Because the HTML is now simplified, the XSLT stylesheet is also simplified. This is why CSS complements XSLT so nicely and should be used whenever possible.
9.3.5. Interacting with EJB
Enterprise JavaBeans (EJB) objects are server-side components that encapsulate business logic and access to data. Because EJBs execute inside of application servers, they are typically accessed remotely using Java Remote Method Invocation (RMI) interfaces. This implies that method calls to EJB components occur over a network connection; they are much slower than local method calls within the same VM. For this reason, care must be taken when sending data to and from the application server.
9.3.5.1. Sending XML from EJBs
From the perspective of Java and XSLT, the critical issue is determining where to produce XML. There are basically two options available. The first is to produce the XML within the EJB container, thus providing a pure XML interface to any client wishing to use the beans. For instance, a bean may have the following additional methods that know how to produce XML:
public String getLeaderXML( ) throws RemoteException; public String getTeamMembersXML( ) throws RemoteException; public String getProjectInformation( ) throws RemoteException;
Each of these methods simply returns a String that contains XML content.Figure 9-9 illustrates how this model works.
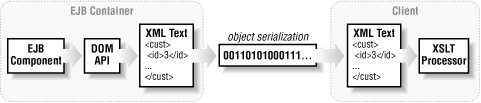
Figure 9-9. Generating XML in the EJB tier
NOTE: Another variation on this theme is to use a helper class whose sole responsibility is to produce XML from a bean, rather than embedding the XML production directly in the bean.
The EJB component is responsible for generating XML before sending a response to the client. Although DOM is shown in the figure, JDOM or any other XML generation API may be used. The client, whether a servlet container or a standalone Java client, sees XML only from the server.
At one extreme, each of these XML strings is a well-formed XML document. Another option, perhaps more useful, is returning fragments of XML. The client can then assemble many of these XML fragments into more complex XML documents. While this does put slightly more burden on the client to assemble the pieces properly, it does offer significantly more flexibility.
This approach may seem like it offers the cleanest interface to the EJB tier. As long as the structure of the XML remains the same, both client and server can change their internal object models without affecting the other.
WARNING: Many DOM implementations are not comprised of Serializable Java objects. Furthermore, the client may not use the same DOM implementation that the server uses. For these reasons, it is rarely a good idea to try sending DOM trees directly from an EJB to a client.
Producing XML on the EJB tier has significant drawbacks, however. First, the size of XML text is typically quite large. Compression of the text is essential, particularly as the size of the XML gets larger. While compression reduces bandwidth requirements, it increases the processor workload on both client and server for compression and decompression. This is supported by java.util.zip.GZIPInputStream and java.util.zip.GZIPOutputStream.
The second drawback is that 100 percent of an application's business logic can rarely be placed inside of EJB components. Although this is an admirable goal, it means that the client must make a remote network call to the server for every operation. By simply returning XML to the client, it is much harder for some of the business logic to be offloaded to the client machine.
9.3.5.2. Sending objects from EJBs
The second option is to leave XML out of the EJB components altogether. Instead, each bean method returns instances of helper classes such as Employee and ProjectInfo. With this approach, the client can perform some business logic by invoking methods locally on the returned objects. Figure 9-10 illustrates where XML production occurs in this model.

Figure 9-10. Generating XML on the client tier
As shown, the Employee object is serialized, and the serialized object is sent from the EJB container to the client, rather than a big text string of XML. On the client machine, the DOM API is used to convert the Employee into an XML representation, which is fed directly into an XSLT processor. By using DOM on the client, the XML never has to be completely converted to text, which tends to be slightly faster for transformations.
NOTE: While custom XML production using DOM is common today, more automated XML data-binding technologies are becoming increasingly popular. Sun's Java Architecture for XML Data Binding (JAXB) provides a standard Java API for mapping to and from XML documents and Java objects.
Although the bandwidth requirements for serialized objects are comparable to compressed XML, more finely grained requests are easier when returning objects instead of XML text. Consider an online benefit processing application. In this type of application, an employee may have a spouse, children, beneficiaries, and benefit elections. As the user moves from page to page in this application, the Employee object can be cached in the HttpSession. As new pages require additional data, they merely call methods on this cached Employee object:
// somewhere in a servlet...
if (employee.isMarried( )) {
// request the Spouse, which will make a call to the EJB tier
// unless the spouse was requested earlier and is cached
Person spouse = employee.getSpouse( );
// generate XML for the spouse...
} else {
// simply generate XML for the employee; do not call the EJB tier
}As the code fragment shows, when an employee does not have a spouse, no additional call to the EJB tier is required. If the EJB tier returns pure XML, then additional calls to the EJB tier are almost certainly required for each web page that is displayed. This is because the web tier sees only big blocks of XML text from the EJB tier, making it much more difficult to add any business logic to the web tier.
The biggest advantage of returning objects instead of XML is the ability to keep presentation logic out of the EJB tier. Most web applications combine data from several EJBs onto each web page. End user requirements for the user interface tend to change much more frequently than data requirements. It makes sense to keep the EJB tier stable while changing the XML generation code in the web tier more frequently.
|  | |
| 9.2. Testing and Debugging |  | 10. Wireless Applications |

Copyright © 2002 O'Reilly & Associates. All rights reserved.