
 |  |
4.2. The Universal Design
Despite the proliferation of APIs, frameworks, and template engines, most web application approaches seem to be consolidating around the idea of model-view-controller (MVC). Clean separation between data, presentation, and programming logic is a key goal of this design. Most web frameworks implement this pattern, and the hybrid approach of JSP and servlets follows it. XSLT implementations also use this pattern, which leads to the conclusion that model-view-controller is truly a universal approach to development on the web tier.
4.2.1. Web Frameworks
A framework is a value-added class library that makes it easier to develop certain types of applications. For example, an imaging framework may contain APIs for reading, writing, and displaying several image formats. This makes it much easier to build applications because someone else already figured out how to structure your application.
Servlet frameworks are no different. Now that servlets, JSP, and hybrid approaches have been available for a few years, common architectural patterns are emerging as "best practices." These include separation of Java code and HTML generation, using servlets in conjunction with JSP, and other variations. Once basic patterns and themes are understood, it becomes desirable to write common frameworks that automate the mundane tasks of building web applications.
The most important tradeoff you make when selecting a framework is vendor lock-in versus open standards. At this time, there are no open standards for frameworks. Although there are numerous open source frameworks, none is backed by a standards organization or even Sun's Java Community Process. The low-level servlet and JSP APIs are very well defined and widely implemented Java standard extensions. But a framework can offer much more sophisticated features such as enhanced error checking, database connection pooling, custom tag libraries, and other value-added features. As you add more framework-specific features, however, your flexibility to choose another framework or vendor quickly diminishes.
One typical framework is Turbine, which is one of many different frameworks supported by Apache. Turbine is a large framework with many value-added features including:
-
Database connection pooling, integration with object to relational mapping tools, and relational database abstractions
-
Integration with numerous template engines
-
Role-based security and access control lists
-
Web browser detection
-
Integration with JavaMail
This is only a short list of Turbine's features. At its core, however, the compelling reason to use a framework like Turbine is the underlying object model. The fundamental approach of Turbine is to cleanly separate validation logic, the servlet itself, and page rendering into distinctly different modules. In fact, Turbine uses a single servlet, so your validation and rendering logic have to go elsewhere. The approach is to define helper classes called actions, which are responsible for validation of incoming requests. Once an action has validated the inbound request, other classes such as Layout, Page, and Navigation are responsible for rendering a view back to the browser.
When compared to a pure XML/XSLT approach, frameworks have the advantage of value-added features. If you remove all of the non-web features, such as database connection pooling and object-to-relational mapping tools, you will see that the underlying model-view-controller architecture is very easy to implement. You should be wary of any framework that provides too much non-web-related functionality because many of these features should be placed on the application server instead of the web server anyway. The remainder of this chapter is devoted to showing you how to structure a complex web application without committing yourself to a specific framework.
4.2.2. Model-View-Controller
Cleanly separating data and presentation logic is important. What exactly are the benefits? First and foremost, when data is completely isolated from the user interface, changes can be made to the visual appearance of an application without affecting the underlying data. This is particularly important in web applications that have to support multiple incompatible browsers or even WML, XHTML Basic, or HTML. It is much harder to adapt to new user interface requirements when data and presentation are mixed.
Programming logic should also be separated from data and presentation logic. To a certain extent, programming logic must depend in part on both data and presentation. But you can generally isolate business logic, which depends on the data, and presentation logic, which depends on the user interface. Figure 4-4 illustrates these dependencies.
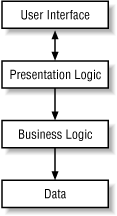
Figure 4-4. Dependencies
The arrows indicate dependencies. For example, if your underlying data changes, then the business logic will probably have to change. However, that does not always flow up and break your presentation logic. In general, if changes are sweeping, it is hard to avoid affecting upper layers, but minor changes can almost always be encapsulated. If the implementation of your business logic changes, however, there is no reason to change the underlying data. Likewise, you should be able to make changes to the presentation logic without breaking the business logic. Later in this chapter, we will see how Java, XML, and XSLT can be utilized to satisfy these dependencies.
The dominant pattern in scalable web sites is model-view-controller. The MVC pattern originated with Smalltalk-80 as a way to develop graphical user interfaces in an object-oriented way. The basics are simple. GUI components represent the view and are responsible for displaying visual information to the user. The model contains application data. The controller is responsible for coordinating between the model and the view. It intercepts events from the view components, queries the model for its current state, makes modifications to the model, and notifies the view of changes to the model. Figure 4-5 illustrates the interaction between these three components.
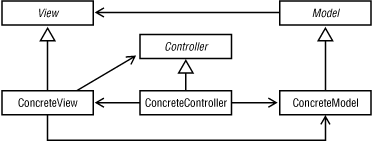
Figure 4-5. Model-view-controller
As shown, the Model, View, and Controller are either abstract classes or interfaces. The concrete classes are application-specific, and the open arrows indicate the direction of association between the various classes. For example, the abstract Model sends notifications only to the abstract View, but ConcreteView knows about its ConcreteModel. This makes sense when you consider how hard it would be to create a specific view, such as a customer editor panel, without knowledge of a specific data model like Customer. Since the Model only knows about View instances in an abstract way, however, it can send generic notifications when it changes, allowing new views to be attached later.
It is important to remember that this is just a pattern; specific implementations may vary somewhat and use different class names. One variation is to eliminate the explicit references from ConcreteView to ConcreteModel and from Model to View. In this approach, the Controller would take a more prevalent role. A common theme in Java is to remove the explicit controller using data models and view components that send notifications to event listeners. Although typically thought of in terms of GUI applications, the MVC architecture is not limited to this domain. For web applications, it is commonly used in:
-
The hybrid servlet + JSP approach
-
Most servlet frameworks
-
The XSLT approach
In the hybrid approach, the servlet is the controller and the JSP is the view. It is assumed that the data will be retrieved from a database or Enterprise JavaBeans (EJB) components, which act as the model. A good framework may make the distinction between model, view, and controller more explicit. Instead of using the servlet as a controller, a common pattern is to use a single servlet that delegates work to helper classes that act as controllers. Each of these classes is equivalent to ConcreteController in Figure 4-5 and has knowledge of specific web pages and data.
Although originally intended for Smalltalk GUIs, MVC has always been one of the most frequently used patterns in all sorts of GUIs, from Motif to Java. On the web, MVC is also prevalent, although a few mechanics are slightly different. In a web environment, we are restricted to the HTTP protocol, which is stateless . With each click of a hyperlink, the browser must establish a new connection to the web server. Once the page has been delivered, the connection is broken. It is impossible for the server to initiate a conversation with the client, so the server merely waits until the next request arrives.
Implementing MVC in this stateless architecture results in looser coupling between the controller and the view. In a GUI environment, the controller immediately notifies the view of any changes to the underlying model. In a web environment, the controller must maintain state information as it waits for the browser to make another request. As each browser request arrives, it is the controller's job to validate the request and forward commands on to the model. The controller then sends the results back to the view.
This may all sound academic and vague at this point. The next few sections will present much more detailed diagrams that show exactly how MVC is implemented for an XSLT-driven web site.
4.2.3. XSLT Implementation
All of the approaches presented up to this point are, of course, building up to the XSLT approach. In many respects, the XSLT approach is simultaneously the most powerful and the easiest to understand. For a single web page, the XSLT approach is probably harder than a servlet or JSP to configure. Configuration of the XML parser and XSLT processor can be quite difficult, mostly due to CLASSPATH issues.[15] But as the complexity of a web application increases, the benefits of using XSLT become obvious. Figuring out how to tackle these complex web applications is the real goal of this chapter.
[15] This can be a frustrating experience when the servlet container comes with an older XML parser that uses DOM or SAX Version 1. Most XSLT processors require Version 2 parsers.
The XSLT approach maps fairly directly to the MVC pattern. The XML represents the model, the servlet represents the controller, and the XSLT produces HTML, which represents the view. The XSLT stylesheets may contain a minimal amount of logic, potentially blurring the line between view and controller. Figure 4-6 represents a conceptual view of how the XSLT approach maps to MVC.
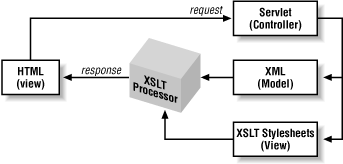
Figure 4-6. XSLT conceptual model
One weakness common to every approach other than XSLT is the HTML-centric viewpoint. In every example presented thus far, it was assumed that we generated HTML. What happens when the requirement to support cellular phones arises? It is very likely that these devices will not use HTML. Instead, they will use WML, XHTML Basic, or some other technology that has not been invented yet. For now, consider that you would have to write brand new servlets or JSPs to support these devices when using traditional approaches. Any programming logic embedded into JSP pages would be duplicated or would have to be factored out into common helper classes. In a pure servlet approach, the hardcoded HTML generation logic would have to be completely rewritten.
XSLT offers an elegant solution -- simply create a second stylesheet. Instead of transforming XML into HTML, this new stylesheet transforms XML into WML. You can even support different web browsers with the XSLT approach. Again, just write different stylesheets for browser-specific functions. Since XSLT stylesheets can import and include functionality from other stylesheets, much of the code can be shared and reused across a project.
Regardless of what your XSLT will produce, start by producing the XML. For the schedule web application, the XML is dynamic and must be programmatically generated. JDOM code is shown in Example 4-4, which produces the XML necessary to create the schedule web page.
Example 4-4. ScheduleJDOM.java
package chap4;
import java.text.SimpleDateFormat;
import org.jdom.*;
import org.jdom.output.*;
/**
* Produces a JDOM Document for a tv schedule.
*/
public class ScheduleJDOM {
private SimpleDateFormat dateFmt = new SimpleDateFormat("hh:mm a");
/**
* Simple main( ) method for printing the XML document to System.out,
* useful for testing.
*/
public static void main(String[] args) throws Exception {
Document doc = new ScheduleJDOM().getTodaysShows( );
new XMLOutputter(" ", true, "UTF-8").output(doc, System.out);
}
/**
* @return a new JDOM Document for all TV shows scheduled for today.
*/
public Document getTodaysShows( ) {
Schedule sched = Schedule.getInstance( );
Show[] shows = sched.getTodaysShows( );
Element rootElem = new Element("schedule");
for (int i=0; i<shows.length; i++) {
rootElem.addContent(createShowElement(shows[i]));
}
return new Document(rootElem);
}
/**
* A helper method to convert a Show object into a JDOM Element.
*/
public Element createShowElement(Show show) {
Element e = new Element("show");
e.addContent(new Element("channel").setText(
Integer.toString(show.getChannel( ))));
e.addContent(new Element("from").setText(
this.dateFmt.format(show.getStartTime( ))));
e.addContent(new Element("to").setText(
this.dateFmt.format(show.getEndTime( ))));
e.addContent(new Element("title").setText(show.getTitle( )));
return e;
}
}You might be wondering why this JDOM code is that much better than the servlet code, which also used Java to programmatically produce output. The difference is fundamental and important. With this JDOM example, println( ) statements are not used. Instead, a data structure representing the television schedule is created. By virtue of the JDOM API, the data structure is guaranteed to produce well-formed XML. We could very easily add a DTD, writing a unit test that validates the integrity of the generated data structure.
In addition to ensuring the integrity of the data, the JDOM code will typically be much smaller than the servlet or JSP code. In this basic web page, the servlet and JSP were quite small because the HTML did not contain any significant formatting or layout. In a real-world web page, however, the servlet and JSP will continue to grow in complexity as the HTML layout gets more sophisticated, while the JDOM code remains exactly the same.
Although the XSLT stylesheet will get larger as the HTML gets more complex, this is arguably less of a problem because the presentation logic is completely separated from the underlying XML data. Once fully tested, the XSLT can be deployed to the web server without recompiling the Java code or restarting the servlet. The XML data produced by JDOM is shown in Example 4-5.
Example 4-5. XML for schedule web page
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="schedule.xslt"?>
<schedule>
<show>
<channel>2</channel>
<from>06:00 AM</from>
<to>06:30 AM</to>
<title>Baseball</title>
</show>
<show>
<channel>3</channel>
<from>06:00 AM</from>
<to>08:00 AM</to>
<title>Stand up Comedy</title>
</show>
...remaining XML omitted
</schedule>The stylesheet that produces the exact same output as the JSP and servlet is listed in Example 4-6.
Example 4-6. schedule.xslt
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<!-- ========== Produce the HTML Document ========== -->
<xsl:template match="/">
<html>
<head><title>Today's Shows</title></head>
<body>
<h1>Today's Shows</h1>
<table cellpadding="3" border="1" cellspacing="0">
<tr>
<th>Channel</th>
<th>From</th>
<th>To</th>
<th>Title</th>
</tr>
<!-- ===== select the shows ===== -->
<xsl:apply-templates select="schedule/show"/>
</table>
</body>
</html>
</xsl:template>
<!-- ======== Display each show as a row in the table ======== -->
<xsl:template match="show">
<tr>
<td><xsl:value-of select="channel"/></td>
<td><xsl:value-of select="from"/></td>
<td><xsl:value-of select="to"/></td>
<td><xsl:value-of select="title"/></td>
</tr>
</xsl:template>
</xsl:stylesheet>The remaining piece of the puzzle is to write a servlet that combines all of these pieces and delivers the result of the XSLT transformation to the client (see Chapter 6, "Servlet Basics and XSLT"). In a nutshell, the servlet acts as a controller between the various components, doing very little of the actual work. The client request is intercepted by the servlet, which tells ScheduleJDOM to produce the XML data. This XML is then fed into an XSLT processor such as Xalan, along with schedule.xslt. Finally, the output is sent to the browser as HTML, XHTML, WML, or some other format.
NOTE: Another interesting option made possible by this architecture is allowing the client to request raw XML without any kind of XSLT transformation. This allows your web site to support nonbrowser clients that wish to extract meaningful business data in a portable way.
We examined the weaknesses of other approaches, so it is only fair to take a critical look at the XSLT approach. First, XSLT is a new language that developers or web content authors have to learn. Although the syntax is strange, it can be argued that XSLT is easier to learn than a sophisticated programming language like Java. There is resistance on this front, however, which is typical of a new technology that is unfamiliar.
The second potential weakness of the XSLT approach is runtime performance. There is a performance penalty associated with XSLT transformation. Fortunately, there are numerous optimizations that can be applied. The most common involves the caching of stylesheets so they do not have to be parsed with each request. This and other techniques for optimization will be covered in later chapters.
Since XSLT stylesheets are actually XML documents, any available XML editor will work for XSLT. But eventually we should see more and more specialized XSLT editors that hide some of the implementation details for nonprogrammers. As with first-generation Java GUI builders, these early tools may not generate stylesheets as cleanly as a handcoded effort.
4.2.4. Development and Maintenance Benefits of XSLT
As mentioned earlier, testing JSPs can be difficult. Since they can be executed only within a JSP container, automated unit tests must start a web server and invoke the JSP via HTTP requests in order to test their output. The XSLT-based web approach does not suffer from this problem.
Referring back to Figure 4-6, you can see that the data model in an XSLT web application is represented as XML. This XML is generated independently of the servlet container, so a unit test can simply create the XML and validate it against a DTD or XML Schema. Tools such as XML Spy make it easy to create XSLT stylesheets and test them interactively against sample XML files long before they are ever deployed to a servlet container. XML Spy is available from http://www.xmlspy.com. If you are looking for alternatives, a directory of XML tools can be found at http://www.xmlsoftware.com.
The XSLT processor is another piece of the puzzle that is not tied to the servlet in any way. Because the processor is an independent component, additional unit tests can perform transformations by applying the XSLT stylesheets to the XML data, again without any interference from a web server or servlet container. If your stylesheets produce XHTML instead of HTML, the output can be easily validated against one of the W3C DTDs for XHTML. JUnit, an open source unit-testing tool, can be used for all of these tests. It can be downloaded from http://www.junit.org.
|  | |
| 4. Java-Based Web Technologies |  | 4.3. XSLT and EJB |

Copyright © 2002 O'Reilly & Associates. All rights reserved.