
 |  |
2.4. XPath Basics
XPath is another recommendation from the W3C and is designed for use by XSLT and another technology called XPointer. The primary goal of XPath is to define a mechanism for addressing portions of an XML document, which means it is used for locating element nodes, attribute nodes, text nodes, and anything else that can occur in an XML document. XPath treats these nodes as part of a tree structure rather than dealing with XML as a text string. XSLT also relies on the tree structure that XPath defines. In addition to addressing, XPath contains a set of functions to format text, convert to and from numbers, and deal with booleans.
Unlike XSLT, XPath itself is not expressed using XML syntax. A simplified syntax makes sense when you consider that XPath is most commonly used inside of attribute values within other XML documents. XPath includes both a verbose syntax and a set of abbreviations, which end up looking a lot like path names on a file system or web site.
2.4.1. How XSLT Uses XPath
XSLT uses XPath in three basic ways:
-
To select and match patterns in the original XML data. Using XPath in this manner is the focus of this chapter. You see this most often in <xsl:template match="pattern"> and <xsl:apply-templates select="node-set-expression"/>. In either case, XPath syntax is used to locate various types of nodes.
-
To support conditional processing. We will see the exact syntax of <xsl:if> and <xsl:choose> in the next chapter, both of which rely on XPath's ability to represent boolean values of true and false.
-
To generate text. A number of string formatting instructions are provided, giving you the ability to concatenate strings, manipulate substrings, and convert from other data types to strings. Again, this will be covered in the next chapter.
2.4.2. Axes
Whenever XSLT uses XPath, something in the XML data is considered to be the current context node. XPath defines seven different types of nodes, each representing a different part of the XML data. These are the document root, elements, text, attributes, processing instructions, comments, and nodes representing namespaces. An axis represents a relationship to the current context node, which may be any one of the preceding seven items.
A few examples should clear things up. One axis is child, representing all immediate children of the context node. From our earlier schedule.xml example, the child axis of <name> includes the <first> and <last> elements. Another axis is parent, which represents the immediate parent of the context node. In many cases the axis is empty. For example, the document root node has no parent axis. Figure 2-4 illustrates some of the other axes.
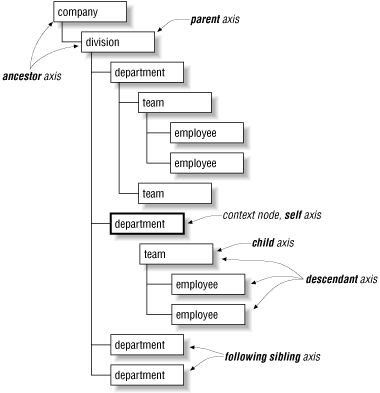
Figure 2-4. XPath axes
As you can see, the second <department> element is the context node. The diagram illustrates how some of the more common axes relate to this node. Although the names are singular, in most cases the axes represent node sets rather than individual nodes. The code:
<xsl:apply-templates select="child::team"/>
selects all <team> children, not just the first one. Table 2-1 lists the available axes in alphabetical order, along with a brief description of each.
Table 2-1. Axes summary
|
Axis name |
Description |
|---|---|
ancestor |
The parent of the context node, its parent, and so on until the root node is reached. The ancestor of the root is an empty node set. |
ancestor-or-self |
The same as ancestor, with the addition of the context node. The root node is always included. |
attribute |
All attributes of the context node. |
child |
All immediate children of the context node. Attributes and namespace nodes are not included. |
descendant |
All children, grandchildren, and so forth. Attribute and namespace nodes are not considered descendants of element nodes. |
descendant-or-self |
Same as descendant, with the addition of the context node. |
following |
All elements in the document that occur after the context node. Descendants of the context node are not included. |
following-sibling |
All following nodes in the document that have the same parent as the context node. |
namespace |
The namespace nodes of the context node. |
parent |
The immediate parent of the context node, if a parent exists. |
preceding |
All nodes in the document that occur before the context node, except for ancestors, attribute nodes, and namespace nodes. |
preceding-sibling |
All nodes in the document that occur before the context node and have the same parent. This axis is empty if the context node is an attribute node or a namespace node. |
self |
The context node itself. |
2.4.3. Location Steps
As you may have guessed, an axis alone is only a piece of the puzzle. A location step is a more complex construct used by XPath and XSLT to select a node set from the XML data. Location steps have the following syntax:
axis::node-test[predicate-1]...[predicate-n]
The axis and node-test are separated by double colons and are followed by zero or more predicates. As mentioned, the job of the axis is to specify the relationship between the context node and the node-test. The node-test allows you to specify the type of node that will be selected, and the predicates filter the resulting node set.
Once again, discussion of XSLT and XPath tends to sound overly technical until you see a few basic examples. Let's start with a basic fragment of XML:
<message>
<header> <!-- the context node -->
<subject>Hello, World</subject>
<date mm="03" dd="01" yy="2002"/>
<sender>pres@whitehouse.gov</sender>
<recipient>burke_e@ociweb.com</recipient>
<recipient>burke_e@yahoo.com</recipient>
<recipient>aidan@burke.com</recipient>
</header>
<body>
...
</body>
</message>If the <header> is the context node, then child::subject will select the <subject> node, child::recipient will select the set of all <recipient> nodes, and child::* will select all children of <header>. The asterisk (*) character is a wildcard that represents all nodes of the principal node type. Each axis has a principal node type, which is always element unless the axis is attribute or namespace. If <date> is the context node, then attribute::yy will select the yy attribute, and attribute::* will select all attributes of the <date> element.
Without any predicates, a location step can result in zero or more nodes. Adding a predicate simply filters the resulting node set, generally reducing the size of the resulting node set. Adding additional predicates applies additional filters. For example, child::recipient[position( )=1] will initially select all <recipient> elements from the previous example then filter (reduce) the list down to the first one: burke_e@ociweb.com. Positions start at 1, rather than 0. As Example 2-8 will show, predicates can contain any XPath expression and can become quite sophisticated.
2.4.4. Location Paths
Location paths consist of one or more location steps, separated by slash (/) characters. An absolute location path begins with the slash (/) character and is relative to the document root. All other types of location paths are relative to the context node. Paths are evaluated from left to right, just like a path in a file system or a web site. The XML shown in Example 2-7 is a portion of a larger file containing basic information about U.S. presidents. This is used to demonstrate a few more XSLT and XPath examples.
Example 2-7. presidents.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="xpathExamples.xslt"?>
<presidents>
<president>
<term from="1789" to="1797"/>
<name>
<first>George</first>
<last>Washington</last>
</name>
<party>Federalist</party>
<vicePresident>
<name>
<first>John</first>
<last>Adams</last>
</name>
</vicePresident>
</president>
<president>
<term from="1797" to="1801"/>
<name>
<first>John</first>
<last>Adams</last>
</name>
<party>Federalist</party>
<vicePresident>
<name>
<first>Thomas</first>
<last>Jefferson</last>
</name>
</vicePresident>
</president>
/**
* remaining presidents omitted
*/The complete file is too long to list here but is included with the downloadable files for this book. The <vicePresident> element can occur many times or not at all because some presidents did not have vice presidents. Names can also contain optional <middle> elements. Using this XML data, the XSLT stylesheet in Example 2-8 shows several location paths.
Example 2-8. Location paths
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" />
<xsl:template match="/">
<html>
<body>
<h1>XPath Examples</h1>
The third president was:
<ul>
<xsl:apply-templates select="presidents/president[position( ) = 3]/name"/>
</ul>
Presidents without vice presidents were:
<ul>
<xsl:apply-templates
select="presidents/president[count(vicePresident) = 0]/name"/>
</ul>
Presidents elected before 1800 were:
<ul>
<xsl:apply-templates
select="presidents/president[term/@from < 1800]/name"/>
</ul>
Presidents with more than one vice president were:
<ul>
<xsl:apply-templates
select="descendant::president[count(vicePresident) > 1]/name"/>
</ul>
Presidents named John were:
<ul>
<xsl:apply-templates
select="presidents/president/name[child::first='John']"/>
</ul>
Presidents elected between 1800 and 1850 were:
<ul>
<xsl:apply-templates
select="presidents/president[(term/@from > 1800) and
(term/@from < 1850)]/name"/>
</ul>
</body>
</html>
</xsl:template>
<xsl:template match="name">
<li>
<xsl:value-of select="first"/>
<xsl:text> </xsl:text>
<xsl:value-of select="middle"/>
<xsl:text> </xsl:text>
<xsl:value-of select="last"/>
</li>
</xsl:template>
</xsl:stylesheet>In the first <xsl:apply-templates> element, the location path is as follows:
presidents/president[position( ) = 3]/name
This path consists of three location steps separated by slash (/) characters, but the final step is what we want to select. This path is read from left to right, so it first selects the <presidents> children of the current context. The next step is relative to the <presidents> context and selects all <president> children. It then filters the list according to the predicate. The third <president> element is now the context, and its <name> children are selected. Since each president has only one <name>, the template that matches "name" is instantiated only once.
This location path shows how to perform basic numeric comparisons:
presidents/president[term/@from < 1800]/name
Since the less-than (<) character cannot appear in an XML attribute value, the < entity must be substituted. In this particular example, we use the @ abbreviated syntax to represent the attribute axis.
2.4.5. Abbreviated Syntax
Using descendant::, child::, parent::, and other axes is very verbose, requiring a lot of typing. Fortunately, XPath supports an abbreviated syntax for many of these axes that requires a lot less effort. The abbreviated syntax has the added advantage in that it looks like you are navigating the file system, so it tends to be somewhat more intuitive. Table 2-2 compares the abbreviated syntax to the verbose syntax. The abbreviated syntax is almost always used and will be used throughout the remainder of this book.
Table 2-2. Abbreviated syntax
|
Abbreviation |
Axis |
|---|---|
// |
descendant |
. |
self |
.. |
parent |
@ |
attribute |
child |
In the last row, the abbreviation for the child axis is blank, indicating that child:: is an implicit part of a location step. This means that vicePresident/name is equivalent to child::vicePresident/child::name. Additional explanations follow:
-
vicePresident selects the vicePresident children of the context node.
-
vicePresident/name selects all name children of vicePresident children of the context node.
-
//name selects all name descendants of the context node.
-
. selects the context node.
-
../term/@from selects the from attribute of term children of the context node's parent.
|  | |
| 2.3. Another XSLT Example, Using XHTML |  | 2.5. Looping and Sorting |

Copyright © 2002 O'Reilly & Associates. All rights reserved.