
 |  |
2.2. Transformation Process
Now that we have seen an example, let's back up and talk about some basics. In particular, it is important to understand the relationship between <xsl:template match=...> and <xsl:apply-templates select=...>. This should help to solidify your understanding of the previous example and lay the groundwork for more sophisticated processing. Although XSLT is a language, it is not intended to be a general-purpose programming language. Because of its specialized mission as a transformation language,[6] the design of XSLT works in the way that XML is structured, which is fundamentally a tree data structure.
[6] XSLT is declarative in nature, while mainstream programming languages tend to be more procedural.
2.2.1. XML Tree Data Structure
Every well-formed XML document forms a tree data structure. The document itself is always the root of the tree, and every element within the document has exactly one parent. Since the document itself is the root, it has no parent. As you learn XSLT, it can be helpful to draw pictures of your XML data that show its tree structure. Figure 2-2 illustrates the tree structure for discussionForumHome.xml.
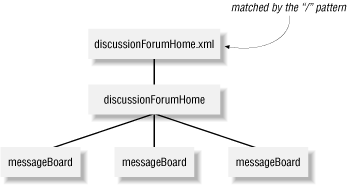
Figure 2-2. Tree structure for discussionForumHome.xml
The document itself is the root of the tree and may contain processing instructions, the document root element, and even comments. XSLT has the ability to select any of these items, although you will probably want to select elements and attributes when transforming to HTML. As mentioned earlier, the "/" pattern matches the document itself, which is the root node of the entire tree.
A tree data structure is fundamentally recursive because it consists of leaf nodes and smaller trees. Each of these smaller trees, in turn, also consist of leaf nodes and still smaller trees. Algorithms that deal with tree structures can almost always be expressed recursively, and XSLT is no exception. The processing model adopted by XSLT is explicitly designed to take advantage of the recursive nature of every well-formed XML document. This means that most stylesheets can be broken down into highly modular, easily understandable pieces, each of which processes a subset of the overall tree (i.e., a subtree).
Two important concepts in XSLT are the current node and current node list. The current node is comparable to the current working directory on a file system. The <xsl:value-of select="."/> element is similar to printing the name of the current working directory. The current node list is similar to the list of subdirectories. The key difference is that in XSLT, the current node appears in your source XML document. The current node list is a collection of nodes. As processing proceeds, the current node and current node list are constantly changing as you traverse the source tree, looking for patterns in the data.
2.2.2. Recursive Processing with Templates
Most transformation in XSLT is driven by two elements: <xsl:template> and <xsl:apply-templates> . In XSLT lingo, a node can represent anything that appears within your XML data. Nodes are typically elements such as <message> or element attributes such as id="123". Nodes can also be XML processing instructions, text, or even comments. XSLT transformation begins with a current node list that contains a single entry: the root node. This is the XML document and is represented by the "/" pattern. Processing proceeds as follows:
-
For each node "X" in the current node list, the processor searches for all <xsl:template match="pattern"> elements in your stylesheet that potentially match that node. From this list of templates, the one with the best match[7] is selected.
[7] See section 5.5 of the XSLT specification for conflict-resolution rules.
-
The selected <xsl:template match="pattern"> is instantiated using node "X" as its current node. This template typically copies data from the source document to the result tree or produces brand new content in combination with data from the source.
-
If the template contains <xsl:apply-templates select="newPattern"/>, a new current node list is created and the process repeats recursively. The select pattern is relative to node "X", rather than the document root.
As the XSLT transformation process continues, the current node and current node list are constantly changing. This is a good thing, since you do not want to constantly search for patterns beginning from the document root element. You are not limited to traversing down the tree, however; you can iterate over portions of the XML data many times or navigate back up through the document tree structure. This gives XSLT a huge advantage over CSS because CSS is limited to displaying the XML in the order in which it appears in the document.
Let's suppose that your source document contains the following XML:
<school> <name>SIUC</name> <city>Carbondale</city> <state>Illinois</state> </school>
The following template could be used to match the <school> element and output its contents:
<xsl:template match="school"> <b><xsl:value-of select="name"/> is located in <xsl:value-of select="city"/>, <xsl:value-of select="state"/>.</b> </xsl:template>
The result will be something like:
<b>SIUC is located in Carbondale, Illinois.</b>
As you can see, elements that do not start with xsl: are simply copied to the result tree, as is plain text such as "is located in."[8] We do not show this here, but if you try the example you will see that whitespace characters (spaces, tabs, and linefeeds) are also copied to the result tree. When the destination is HTML, it is usually safe to ignore this issue because the browser will collapse that whitespace. If you view the actual source code of the generated HTML, it can look pretty ugly. An alternative to simply including "is located in" is to use:
[8] Technically, elements that do not belong to the XSLT namespace are simply copied to the result tree; the namespace prefix might not be xsl:.
<xsl:text> is located in </xsl:text>.
This provides explicit control over how whitespace and linefeeds are treated.
<xsl:value-of> copies the value of something in the XML source tree to the result tree. In this case, the current node is <school>, so <xsl:value-of select="name"/> selects the text content of the <name> element contained within <school>. This is the simplest usage of XPath, which will be introduced shortly. XPath is not limited to the current node, so it can also be used to locate elements in other parts of the source document. It can even select attributes, processing instructions, or anything else that can occur in XML.
2.2.3. Built-in Template Rules
All XSLT processors must include four built-in template rules that have lower precedence than any other rules, so they can be overridden by simply writing a new template rule that matches the same pattern. The best way to think about built-in rules is to assume they are always in the background, ready to be applied if no other rule is found that matches a node.
The first rule allows recursive processing to continue in case an explicit rule does not match the current node or the root node:
<xsl:template match="*|/"> <xsl:apply-templates/> </xsl:template>
This template matches all elements (*) and the root node (/), i.e., the document itself. It will not match processing instructions, comments, attributes, or text. The <xsl:apply-templates/> causes all children that are not attribute nodes or processing instruction nodes to be processed.
The second built-in rule is identical to the first, except it applies to each mode used in the stylesheet:
<xsl:template match="*|/" mode="m"> <xsl:apply-templates mode="m"/> </xsl:template>
Template modes are discussed in the next chapter, so we will not go into details here. The third built-in rule simply copies all text and attribute nodes to the result tree:
<xsl:template match="text( )|@*"> <xsl:value-of select="."/> </xsl:template>
And finally, the built-in rule for processing instructions and comments does nothing. This is why comments and processing instructions in the input XML data do not automatically show up in the result tree:
<xsl:template match="processing-instruction()|comment( )"/>
2.2.4. A Skeleton Stylesheet
As your XML documents get more complex, you will most likely want to break up your stylesheets into several templates. The starting point is a template that matches the "/" pattern:
<xsl:template match="/"> ...content </xsl:template>
This template matches the document itself and is usually where you output the basic <html>, <head>, and <body> elements. Somewhere within this template, you must tell the processor to continue searching for additional patterns, thus beginning the recursive transformation process. In a typical stylesheet, <xsl:apply-templates> is used for this purpose, instructing the processor to search for additional content in the XML data.
It should be stressed that this is not the only way to write a stylesheet, but it is a very natural way to handle the recursive nature of XML. Example 2-4 contains a skeleton XSLT stylesheet that you can use as a starting point for most of your projects.
Example 2-4. Skeleton stylesheet
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<!--****************************************************************
** "/" template matches the document and is the starting point
*************************************************************-->
<xsl:template match="/">
<html>
<head>
<title>[title goes here]</title>
</head>
<body>
<xsl:apply-templates select="[some XPath expression]"/>
</body>
</html>
</xsl:template>
<!--****************************************************************
** "[???]" template
*************************************************************-->
<xsl:template match="???">
[continue the process...]
<xsl:apply-templates select="[another XPath expression]"/>
[you can also include more content here...or even include
multiple apply-templates...]
</xsl:template>
</xsl:stylesheet>Deciding how to modularize the stylesheet is a subjective process. One suggestion is to look for moderately sized chunks of XML data repeated numerous times throughout a document. For example, a <customer> element may contain a name, address, and phone number. Creating a template that matches "customer" is probably a good idea. You may even want to create another template for the <name> element, particularly if the name is broken down into subelements, or if the name is reused in other contexts such as <employee> and <manager>.
When you need to produce HTML tables or unordered lists in the result tree, two templates (instead of one) can make the job very easy. The first template will produce the <table> or <ul> element, and the second will produce each table row or list item. The following fragment illustrates this basic pattern:
<!-- the outer template produces the unordered list -->
<!-- (note: plural 'customers') -->
<xsl:template match="customers">
<ul>
<xsl:apply-templates select="customer"/>
</ul>
</xsl:template>
<!-- the inner template is repeated for each customer -->
<xsl:template match="customer">
<li><xsl:value-of select="name"/></li>
</xsl:template> |  | |
| 2. XSLT Part 1 -- The Basics |  | 2.3. Another XSLT Example, Using XHTML |

Copyright © 2002 O'Reilly & Associates. All rights reserved.