
 |  |
1.2. XML Review
In a nutshell, XML is a format for storing structured data. Although it looks a lot like HTML, XML is much more strict with quotes, properly terminated tags, and other such details. XML does not define tag names, so document authors must invent their own set of tags or look towards a standards organization that defines a suitable XML markup language. A markup language is essentially a set of custom tags with semantic meaning behind each tag; XSLT is one such markup language, since it is expressed using XML syntax.
The terms element and tag are often used interchangeably, and both are used in this book. Speaking from a more technical viewpoint, element refers to the concept being modeled, while tag refers to the actual markup that appears in the XML document. So <account> is a tag that represents an account element in a computer program.
1.2.1. SGML, XML, and Markup Languages
Standard Generalized Markup Language (SGML) forms the basis for HTML, XHTML, XML, and XSLT, but in very different ways for each. Figure 1-2 illustrates the relationships between these technologies.
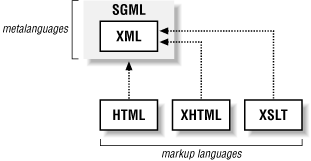
Figure 1-2. SGML heritage
SGML is a very sophisticated metalanguage designed for large and complex documentation. As a metalanguage, it defines syntax rules for tags but does not define any specific tags. HTML, on the other hand, is a specific markup language implemented using SGML. A markup language defines its own set of tags, such as <h1> and <p>. Because HTML is a markup language instead of a metalanguage, you cannot add new tags and are at the mercy of the browser vendor to properly implement those tags.
XML, as shown in Figure 1-2, is a subset of SGML. XML documents are compatible with SGML documents, however XML is a much smaller language. A key goal of XML is simplicity, since it has to work well on the Web where bandwidth and limited client processing power is a concern. Because of its simplicity, XML is easier to parse and validate, making it a better performer than SGML. XML is also a metalanguage, which explains why XML does not define any tags of its own. XSLT is a particular markup language implemented using XML, and will be covered in detail in the next two chapters.
XHTML, like XSLT, is also an XML-based markup language. XHTML is designed to be a replacement for HTML and is almost completely compatible with existing web browsers. Unlike HTML, however, XHTML is based strictly on XML, and the rules for well-formed documents are very clearly defined. This means that it is much easier for vendors to develop editors and programming tools to deal with XHTML, because the syntax is much more predictable and can be validated just like any other XML document. Many of the examples in this book use XHTML instead of HTML, although XSLT can easily handle either format.
XHTML Basics
XHTML is a W3C Recommendation that represents the future of HTML. Based on HTML 4.0, XHTML is designed to be compatible with existing web browsers while complying fully with XML. This means that a properly written XHTML document is always a well-formed XML document. Furthermore, XHTML documents must adhere to one or more of the XHTML DTDs, therefore XHTML pages can be validated using today's XML parsers such as Apache's Crimson.
XHTML is designed to be modular; therefore, subsets can be extracted and utilized for wireless devices such as cell phones. XHTML Basic, also a W3C Recommendation, is one such modularization effort, and will likely become a force to be reckoned with in the wireless space.
Here is an example XHTML document:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>Hello, World!</title> </head> <body> <p>Hello, World!</p> </body> </html>Some of the most important XHTML rules include:
XHTML documents must be well-formed XML and must adhere to one of the XHTML DTDs. As expected with XML, all elements must be properly terminated, attribute values must be quoted, and elements must be properly nested.
The <!DOCTYPE ...> tag is required.
Unlike HTML, tags must be lowercase.
The root element must be <html> and must designate the XHTML namespace as shown in the previous example.
<head> and <body> are required.
The preceding document adheres to the strict DTD, which eliminates deprecated HTML tags and many style-related tags. Two other DTDs, transitional and frameset, provide more compatibility with existing web browsers but should be avoided when possible. For full information, refer to the W3C's specifications and documentation at http://www.w3.org.
As we look at more advanced techniques for processing XML with XSLT, we will see that XML is not always dealt with in terms of a text file containing tags. From a certain perspective, XML files and their tags are really just a serialized representation of the underlying XML elements. This serialized form is good for storing XML data in files but may not be the most efficient format for exchanging data between systems or programmatically modifying the underlying data. For particularly large documents, a relational or object database offers far better scalability and performance than native XML text files.
1.2.2. XML Syntax
Example 1-1 shows a sample XML document that contains data about U.S. Presidents. This document is said to be well-formed because it adheres to several basic rules about proper XML formatting.
Example 1-1. presidents.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE presidents SYSTEM "presidents.dtd">
<presidents>
<president>
<term from="1789" to="1797"/>
<name>
<first>George</first>
<last>Washington</last>
</name>
<party>Federalist</party>
<vicePresident>
<name>
<first>John</first>
<last>Adams</last>
</name>
</vicePresident>
</president>
<president>
<term from="1797" to="1801"/>
<name>
<first>John</first>
<last>Adams</last>
</name>
<party>Federalist</party>
<vicePresident>
<name>
<first>Thomas</first>
<last>Jefferson</last>
</name>
</vicePresident>
</president>
<!-- remaining presidents omitted -->
</presidents>In HTML, a missing tag here and there or mismatched quotes are not disastrous. Browsers make every effort to go ahead and display these poorly formatted documents anyway. This makes the Web a much more enjoyable environment because users are not bombarded with constant syntax errors.
Since the primary role of XML is to represent structured data, being well-formed is very important. When two banking systems exchange data, if the message is corrupted in any way, the receiving system must reject the message altogether or risk making the wrong assumptions. This is important for XSLT programmers to understand because XSLT itself is expressed using XML. When writing stylesheets, you must always adhere to the basic rules for well-formed documents.
All well-formed XML documents must have exactly one root element . In Example 1-1, the root element is <presidents>. This forms the base of a tree data structure in which every other element has exactly one parent and zero or more children. Elements must also be properly terminated and nested:
<name> <first>George</first> <last>Washington</last> </name>
Although whitespace (spaces, tabs, and linefeeds) between elements is typically irrelevant, it can make documents more readable if you take the time to indent consistently. Although XML parsers preserve whitespace, it does not affect the meaning of the underlying elements. In this example, the <first> tag must be terminated with a corresponding </first>. The following XML would be illegal because the tags are not properly nested:
<name>
<first>George
<last>Washington</first>
</last>
</name>XML provides an alternate syntax for terminating elements that do not have children, formally known as empty elements . The <term> element is one such example:
<term from="1797" to="1801"/>
The closing slash indicates that this element does not contain any content , although it may contain attributes. An attribute is a name/value pair, such as from="1797". Another requirement for well-formed XML is that all attribute values be enclosed in quotes ("") or apostrophes ('').
Most presidents had middle names, some did not have vice presidents, and others had several vice presidents. For our example XML file, these are known as optional elements. Ulysses Grant, for example, had two vice presidents. He also had a middle name:
<president>
<term from="1869" to="1877"/>
<name>
<first>Ulysses</first>
<middle>Simpson</middle>
<last>Grant</last>
</name>
<party>Republican</party>
<vicePresident>
<name>
<first>Schuyler</first>
<last>Colfax</last>
</name>
</vicePresident>
<vicePresident>
<name>
<first>Henry</first>
<last>Wilson</last>
</name>
</vicePresident>
</president>Capitalization is also important in XML. Unlike HTML, all XML tags are case sensitive. This means that <president> is not the same as <PRESIDENT>. It does not matter which capitalization scheme you use, provided you are consistent. As you might guess, since XHTML documents are also XML documents, they too are case sensitive. In XHTML, all tags must be lowercase, such as <html>, <body>, and <head>.
The following list summarizes the basic rules for a well-formed XML document:
-
It must contain exactly one root element; the remainder of the document forms a tree structure, in which every element is contained within exactly one parent.
-
All elements must be properly terminated. For example, <name>Eric</name> is properly terminated because the <name> tag is terminated with </name>. In XML, you can also create empty elements like <married/>.
-
Elements must be properly nested. This is legal:
<b><i>bold and italic</i></b>
But this is illegal:
<b><i>bold and italic</b></i>
-
Attributes must be quoted using either quotes or apostrophes. For example:
<date month="march" day='01' year="1971"/>
-
Attributes must contain name/value pairs. Some HTML elements contain marker attributes, such as <td nowrap>. In XHTML, you would write this as <td nowrap="nowrap"/>. This is compatible with XML and should work in existing web browsers.
This is not the complete list of rules but is sufficient to get you through the examples in this book. Clearly, most HTML documents are not well-formed. Many tags, such as <br> or <hr>, violate the rule that all elements must be properly terminated. In addition, browsers do not complain when attribute values are not quoted. This will have interesting ramifications for us when we write XSLT stylesheets, which are themselves written in XML but often produce HTML. What this basically means is that the stylesheet must contain well-formed XML, so it is difficult to produce HTML that is not well-formed. XHTML is certainly a more natural fit because it is also XML, just like the XSLT stylesheet.
1.2.3. Validation
A well-formed XML document adheres to the basic syntax guidelines just outlined. A valid XML document goes one step further by adhering to either a Document Type Definition (DTD) or an XML Schema. In order to be considered valid, an XML document must first be well-formed. Stated simply, DTDs are the traditional approach to validation, and XML Schemas are the logical successor. XML Schema is another specification from the W3C and offers much more sophisticated validation capabilities than DTDs. Since XML Schema is very new, DTDs will continue to be used for quite some time. You can learn more about XML Schema at http://www.w3.org/XML/Schema.
The second line of Example 1-1 contains the following document type declaration:
<!DOCTYPE presidents SYSTEM "presidents.dtd">
This refers to the DTD that exists in the same directory as the presidents.xml file. In many cases, the DTD will be referenced by a URI instead:
<!DOCTYPE presidents SYSTEM "http://www.javaxslt.com/dtds/presidents.dtd">
Regardless of where the DTD is located, it contains rules that define the allowable structure of the XML data. Example 1-2 shows the DTD for our list of presidents.
Example 1-2. presidents.dtd
<!ELEMENT presidents (president+)> <!ELEMENT president (term, name, party, vicePresident*)> <!ELEMENT name (first, middle*, last, nickname?)> <!ELEMENT vicePresident (name)> <!ELEMENT first (#PCDATA)> <!ELEMENT last (#PCDATA)> <!ELEMENT middle (#PCDATA)> <!ELEMENT nickname (#PCDATA)> <!ELEMENT party (#PCDATA)> <!ELEMENT term EMPTY> <!ATTLIST term from CDATA #REQUIRED to CDATA #REQUIRED >
The first line in the DTD says that the <presidents> element can contain one or more <president> elements as children. The <president>, in turn, contains one each of <term>, <name>, and <party> in that order. It then may contain zero or more <vicePresident> elements. If the XML data did not adhere to these rules, the XML parser would have rejected it as invalid.
The <name> element can contain the following content: exactly one <first>, followed by zero or more <middle>, followed by exactly one <last>, followed by zero or one <nickname>. If you are wondering why <middle> can occur many times, consider this former president:
<name> <first>George</first> <middle>Herbert</middle> <middle>Walker</middle> <last>Bush</last> </name>
Elements such as <first>George</first> are said to contain #PCDATA , which stands for parsed character data. This is ordinary text that can contain markup, such as nested tags. The CDATA type, which is used for attribute values, cannot contain markup. This means that < characters appearing in attribute values will have to be encoded in your XML documents as <. The <term> element is EMPTY, meaning that it cannot have content. This is not to say that it cannot contain attributes, however. This DTD specifies that <term> must have from and to attributes:
<term from="1869" to="1877"/>
We will not cover the remaining syntax rules for DTDs in this book, primarily because they do not have much impact on our code as we apply XSLT stylesheets. DTDs are primarily used during the parsing process, when XML data is read from a file into memory. When generating XML for a web site, you generally produce new XML rather than parse existing XML, so there is much less need to validate. One area where we will use DTDs, however, is when we examine how to write unit tests for our Java and XSLT code. This will be covered in Chapter 9, "Development Environment, Testing, and Performance".
1.2.4. Java and XML
Java APIs for XML such as SAX, DOM, and JDOM will be used throughout this book. Although we will not go into a great deal of detail on specific parsing APIs, the Java-based XSLT tools do build on these technologies, so it is important to have a basic understanding of what each API does and where it fits into the XML landscape. For in-depth information on any of these topics, you might want to pick up a copy of Java & XML by Brett McLaughlin (O'Reilly).
A parser is a tool that reads XML data into memory. The most common pattern is to parse the XML data from a text file, although Java XML parsers can also read XML from any Java InputStream or even a URL. If a DTD or Schema is used, then validating parsers will ensure that the XML is valid during the parsing process. This means that once your XML files have been successfully parsed into memory, a lot less custom Java validation code has to be written.
1.2.4.1. SAX
In the Java community, Simple API for XML (SAX) is the most commonly used XML parsing method today. SAX is a free API available from David Megginson and members of the XML-DEV mailing list (http://www.xml.org/xml-dev). It can be downloaded[2] from http://www.megginson.com/SAX. Although SAX has been ported to several other languages, we will focus on the Java features. SAX is only responsible for scanning through XML data top to bottom and sending event notifications as elements, text, and other items are encountered; it is up to the recipient of these events to process the data. SAX parsers do not store the entire document in memory, therefore they have the potential to be very fast for even huge files.
[2] One does not generally need to download SAX directly because it is supported by and included with all of the popular XML parsers.
Currently, there are two versions of SAX: 1.0 and 2.0. Many changes were made in version 2.0, and the SAX examples in this book use this version. Most SAX parsers should support the older 1.0 classes and interfaces, however, you will receive deprecation warnings from the Java compiler if you use these older features.
Java SAX parsers are implemented using a series of interfaces. The most important interface is org.xml.sax.ContentHandler , which has methods such as startDocument( ) , startElement( ) , characters( ) , endElement( ) , and endDocument( ) . During the parsing process, startDocument( ) is called once, then startElement( ) and endElement( ) are called once for each tag in the XML data. For the following XML:
<first>George</first>
the startElement( ) method will be called, followed by characters( ), followed by endElement( ). The characters( ) method provides the text "George" in this example. This basic process continues until the end of the document, at which time endDocument( ) is called.
NOTE: Depending on the SAX implementation, the characters( ) method may break up contiguous character data into several chunks of data. In this case, the characters( ) method will be called several times until the character data is entirely parsed.
Since ContentHandler is an interface, it is up to your application code to somehow implement this interface and subsequently do something when the parser invokes its methods. SAX does provide a class called DefaultHandler that implements the ContentHandler interface. To use DefaultHandler, create a subclass and override the methods that interest you. The other methods can safely be ignored, since they are just empty methods. If you are familiar with AWT programming, you may recognize that this idiom is identical to event adapter classes such as java.awt.event.WindowAdapter.
Getting back to XSLT, you may be wondering where SAX fits into the picture. It turns out that XSLT processors typically have the ability to gather input from a series of SAX events as an alternative to static XML files. Somewhat nonintuitively, it also turns out that you can generate your own series of SAX events rather easily -- without using a SAX parser. Since a SAX parser just calls a series of methods on the ContentHandler interface, you can write your own pseudo-parser that does the same thing. We will explore this in Chapter 5, "XSLT Processing with Java" when we talk about using SAX and an XSLT processor to apply transformations to non-XML data, such as results from a database query or content of a comma separated values (CSV) file.
1.2.4.2. DOM
The Document Object Model (DOM) is an API that allows computer programs to manipulate the underlying data structure of an XML document. DOM is a W3C Recommendation, and implementations are available for many programming languages. The in-memory representation of XML is typically referred to as a DOM tree because DOM is a tree data structure. The root of the tree represents the XML document itself, using the org.w3c.dom.Document interface. The document root element, on the other hand, is represented using the org.w3c.dom.Element interface. In the presidents example, the <presidents> element is the document root element. In DOM, almost every interface extends from the org.w3c.dom.Node interface; Document and Element are no exception. The Node interface provides numerous methods to navigate and modify the DOM tree consistently.
Strangely enough, the DOM Level 2 Recommendation does not provide standard mechanisms for reading or writing XML data. Instead, each vendor implementation does this a little bit differently. This is generally not a big problem because every DOM implementation out there provides some mechanism for both parsing and serializing, or writing out XML files. The unfortunate result, however, is that reading and writing XML will cause vendor-specific code to creep into any application you write.
NOTE: At the time of this writing, a new W3C document called "Document Object Model (DOM) Level 3 Content Models and Load and Save Specification" was in the working draft status. Once this specification reaches the recommendation status, DOM will provide a standard mechanism for reading and writing XML.
Since DOM does not specify a standard way to read XML data into memory, most DOM (if not all) implementations delegate this task to a dedicated parser. In the case of Java, SAX is the preferred parsing technology. Figure 1-3 illustrates the typical interaction between SAX parsers and DOM implementations.
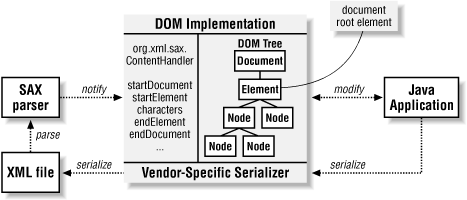
Figure 1-3. DOM and SAX interaction
Although it is important to understand how these pieces fit together, we will not go into detailed parsing syntax in this book. As we progress to more sophisticated topics, we will almost always be generating XML dynamically rather than parsing in static XML data files. For this reason, let's look at how DOM can be used to generate a new document from scratch. Example 1-3 contains XML for a personal library.
Example 1-3. library.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE library SYSTEM "library.dtd">
<library>
<!-- This is an XML comment -->
<publisher id="oreilly">
<name>O'Reilly</name>
<street>1005 Gravenstein Hwy North</street>
<city>Sebastopol</city>
<state>CA</state>
<postal>95472</postal>
</publisher>
<book publisher="oreilly" isbn="1-56592-709-5">
<edition>1</edition>
<publicationDate mm="10" yy="1999"/>
<title>XML Pocket Reference</title>
<author>Robert Eckstein</author>
</book>
<book publisher="oreilly" isbn="0-596-00016-2">
<edition>1</edition>
<publicationDate mm="06" yy="2000"/>
<title>Java and XML</title>
<author>Brett McLaughlin</author>
</book>
</library>As shown in library.xml, a <library> consists of <publisher> elements and <book> elements. To generate this XML, we will use Java classes called Library, Book, and Publisher. These classes are not shown here, but they are really simple. For example, here is a portion of the Book class:
public class Book {
private String author;
private String title;
...
public String getAuthor( ) {
return this.author;
}
public String getTitle( ) {
return this.title;
}
...
}Each of these three helper classes is merely used to hold data. The code that creates XML is encapsulated in a separate class called LibraryDOMCreator, which is shown in Example 1-4.
Example 1-4. XML generation using DOM
package chap1; import java.io.*; import java.util.*; import org.w3c.dom.Document; import org.w3c.dom.Element; /** * An example from Chapter 1, "Introduction ". Creates the library XML file using the * DOM API. */ public class LibraryDOMCreator { /** * Create a new DOM org.w3c.dom.Document object from the specified * Library object. * * @param library an application defined class that * provides a list of publishers and books. * @return a new DOM document. */ public Document createDocument(Library library) throws javax.xml.parsers.ParserConfigurationException { // Use Sun's Java API for XML Parsing to create the // DOM Document javax.xml.parsers.DocumentBuilderFactory dbf = javax.xml.parsers.DocumentBuilderFactory.newInstance( ); javax.xml.parsers.DocumentBuilder docBuilder = dbf.newDocumentBuilder( ); Document doc = docBuilder.newDocument( ); // NOTE: DOM does not provide a factory method for creating: // <!DOCTYPE library SYSTEM "library.dtd"> // Apache's Xerces provides the createDocumentType method // on their DocumentImpl class for doing this. Not used here. // create the <library> document root element Element root = doc.createElement("library"); doc.appendChild(root); // add <publisher> children to the <library> element Iterator publisherIter = library.getPublishers().iterator( ); while (publisherIter.hasNext( )) { Publisher pub = (Publisher) publisherIter.next( ); Element pubElem = createPublisherElement(doc, pub); root.appendChild(pubElem); } // now add <book> children to the <library> element Iterator bookIter = library.getBooks().iterator( ); while (bookIter.hasNext( )) { Book book = (Book) bookIter.next( ); Element bookElem = createBookElement(doc, book); root.appendChild(bookElem); } return doc; } private Element createPublisherElement(Document doc, Publisher pub) { Element pubElem = doc.createElement("publisher"); // set id="oreilly" attribute pubElem.setAttribute("id", pub.getId( )); Element name = doc.createElement("name"); name.appendChild(doc.createTextNode(pub.getName( ))); pubElem.appendChild(name); Element street = doc.createElement("street"); street.appendChild(doc.createTextNode(pub.getStreet( ))); pubElem.appendChild(street); Element city = doc.createElement("city"); city.appendChild(doc.createTextNode(pub.getCity( ))); pubElem.appendChild(city); Element state= doc.createElement("state"); state.appendChild(doc.createTextNode(pub.getState( ))); pubElem.appendChild(state); Element postal = doc.createElement("postal"); postal.appendChild(doc.createTextNode(pub.getPostal( ))); pubElem.appendChild(postal); return pubElem; } private Element createBookElement(Document doc, Book book) { Element bookElem = doc.createElement("book"); bookElem.setAttribute("publisher", book.getPublisher().getId( )); bookElem.setAttribute("isbn", book.getISBN( )); Element edition = doc.createElement("edition"); edition.appendChild(doc.createTextNode( Integer.toString(book.getEdition( )))); bookElem.appendChild(edition); Element publicationDate = doc.createElement("publicationDate"); publicationDate.setAttribute("mm", Integer.toString(book.getPublicationMonth( ))); publicationDate.setAttribute("yy", Integer.toString(book.getPublicationYear( ))); bookElem.appendChild(publicationDate); Element title = doc.createElement("title"); title.appendChild(doc.createTextNode(book.getTitle( ))); bookElem.appendChild(title); Element author = doc.createElement("author"); author.appendChild(doc.createTextNode(book.getAuthor( ))); bookElem.appendChild(author); return bookElem; } public static void main(String[] args) throws IOException, javax.xml.parsers.ParserConfigurationException { Library lib = new Library( ); LibraryDOMCreator ldc = new LibraryDOMCreator( ); Document doc = ldc.createDocument(lib); // write the Document using Apache Xerces // output the Document with UTF-8 encoding; indent each line org.apache.xml.serialize.OutputFormat fmt = new org.apache.xml.serialize.OutputFormat(doc, "UTF-8", true); org.apache.xml.serialize.XMLSerializer serial = new org.apache.xml.serialize.XMLSerializer(System.out, fmt); serial.serialize(doc.getDocumentElement( )); } }
This example starts with the usual series of import statements. Notice that org.w3c.dom.* is imported, but packages such as org.apache.xml.serialize.* are not. The code is written this way in order to make it obvious that many of the classes you will use are not part of the standard DOM API. These nonstandard classes all use fully qualified class and package names in the code. Although DOM itself is a W3C recommendation, many common tasks are not covered by the spec and can only be accomplished by reverting to vendor-specific code.
The workhorse of this class is the createDocument method, which takes a Library as a parameter and returns an org.w3c.dom.Document object. This method could throw a ParserConfigurationException, which indicates that Sun's Java API for XML Parsing (JAXP) could not locate an XML parser:
public Document createDocument(Library library)
throws javax.xml.parsers.ParserConfigurationException {The Library class simply stores data representing a personal library of books. In a real application, the Library class might also be responsible for connecting to a back-end data source. This arrangement provides a clear separation between XML generation code and the underlying database. The sole purpose of LibraryDOMCreator is to crank out DOM trees, making it easy for one programmer to work on this class while another focuses on the implementation of Library, Book, and Publisher.
The next step is to begin constructing a DOM Document object:
javax.xml.parsers.DocumentBuilderFactory dbf =
javax.xml.parsers.DocumentBuilderFactory.newInstance( );
javax.xml.parsers.DocumentBuilder docBuilder =
dbf.newDocumentBuilder( );
Document doc = docBuilder.newDocument( );This code relies on JAXP because the standard DOM API does not provide any support for creating a new Document object in a standard way. Different parsers have their own proprietary way of doing this, which brings us to the whole point of JAXP: it encapsulates differences between various XML parsers, allowing Java programmers to use a consistent API regardless of which parser they use. As we will see in Chapter 5, "XSLT Processing with Java", JAXP 1.1 adds a consistent wrapper around various XSLT processors in addition to standard SAX and DOM parsers.
JAXP provides a DocumentBuilderFactory to construct a DocumentBuilder, which is then used to construct new Document objects. The Document class is a part of DOM, so most of the remaining code is defined by the DOM specification.
In DOM, new XML elements must always be created using factory methods, such as createElement(...), on an instance of Document. These elements must then be added to either the document itself or one of the elements within the document before they actually become part of the XML:
// create the <library> document root element
Element root = doc.createElement("library");
doc.appendChild(root);At this point, the <library/> element is empty, but it has been added to the document. The code then proceeds to add all <publisher> children:
// add <publisher> children to the <library> element
Iterator publisherIter = library.getPublishers().iterator( );
while (publisherIter.hasNext( )) {
Publisher pub = (Publisher) publisherIter.next( );
Element pubElem = createPublisherElement(doc, pub);
root.appendChild(pubElem);
}For each instance of Publisher, a <publisher> Element is created and then added to <library>. The createPublisherElement method is a private helper method that simply goes through the tedious DOM steps required to create each XML element. One thing that may not seem entirely obvious is the way that text is added to elements, such as O'Reilly in the <name>O'Reilly</name> tag:
Element name = doc.createElement("name");
name.appendChild(doc.createTextNode(pub.getName( )));
pubElem.appendChild(name);The first line is pretty obvious, simply creating an empty <name/> element. The next line then adds a new text node as a child of the name object rather than setting the value directly on the name. This is indicative of the way that DOM represents XML: any parsed character data is considered to be a child of a node, rather than part of the node itself. DOM uses the org.w3c.dom.Text interface, which extends from org.w3c.dom.Node, to represent text nodes. This is often a nuisance because it results in at least one extra line of code for each element you wish to generate.
The main() method in Example 1-4 creates a Library object, converts it into a DOM tree, then prints the XML text to System.out. Since the standard DOM API does not provide a standard way to convert a DOM tree to XML, we introduce Xerces specific code to convert the DOM tree to text form:
// write the document using Apache Xerces
// output the document with UTF-8 encoding; indent each line
org.apache.xml.serialize.OutputFormat fmt =
new org.apache.xml.serialize.OutputFormat(doc, "UTF-8", true);
org.apache.xml.serialize.XMLSerializer serial =
new org.apache.xml.serialize.XMLSerializer(System.out, fmt);
serial.serialize(doc.getDocumentElement( ));As we will see in Chapter 5, "XSLT Processing with Java", JAXP 1.1 does provide a mechanism to perform this task using its transformation APIs, so we do not technically have to use the Xerces code listed here. The JAXP approach maximizes portability but introduces the overhead of an XSLT processor when all we really need is DOM.
1.2.4.3. JDOM
DOM is specified in the language independent Common Object Request Broker Architecture Interface Definition Language (CORBA IDL), allowing the same interfaces and concepts to be utilized by many different programming languages. Though valuable from a specification perspective, this approach does not take advantage of specific Java language features. JDOM is a Java-only API that can be used to create and modify XML documents in a more natural way. By taking advantage of Java features, JDOM aims to simplify some of the more tedious aspects of DOM programming.
JDOM is not a W3C specification, but is open source software[3] available at http://www.jdom.org. JDOM is great from a programming perspective because it results in much cleaner, more maintainable code. Since JDOM has the ability to convert its data into a standard DOM tree, it integrates nicely with any other XML tool. JDOM can also utilize whatever XML parser you specify and can write out XML to any Java output stream or file. It even features a class called SAXOutputter that allows the JDOM data to be integrated with any tool that expects a series of SAX events.
[3] Sun has accepted JDOM as Java Specification Request (JSR) 000102; see http://java.sun.com/aboutJava/communityprocess/.
The code in Example 1-5 shows how much easier JDOM is than DOM; it does the same thing as the DOM example, but is about fifty lines shorter. This difference would be greater for more complex applications.
Example 1-5. XML generation using JDOM
package com.oreilly.javaxslt.chap1; import java.io.*; import java.util.*; import org.jdom.DocType; import org.jdom.Document; import org.jdom.Element; import org.jdom.output.XMLOutputter; /** * An example from Chapter 1, "Introduction ". Creates the library XML file. */ public class LibraryJDOMCreator { public Document createDocument(Library library) { Element root = new Element("library"); // JDOM supports the <!DOCTYPE...> DocType dt = new DocType("library", "library.dtd"); Document doc = new Document(root, dt); // add <publisher> children to the <library> element Iterator publisherIter = library.getPublishers().iterator( ); while (publisherIter.hasNext( )) { Publisher pub = (Publisher) publisherIter.next( ); Element pubElem = createPublisherElement(pub); root.addContent(pubElem); } // now add <book> children to the <library> element Iterator bookIter = library.getBooks().iterator( ); while (bookIter.hasNext( )) { Book book = (Book) bookIter.next( ); Element bookElem = createBookElement(book); root.addContent(bookElem); } return doc; } private Element createPublisherElement(Publisher pub) { Element pubElem = new Element("publisher"); pubElem.addAttribute("id", pub.getId( )); pubElem.addContent(new Element("name").setText(pub.getName( ))); pubElem.addContent(new Element("street").setText(pub.getStreet( ))); pubElem.addContent(new Element("city").setText(pub.getCity( ))); pubElem.addContent(new Element("state").setText(pub.getState( ))); pubElem.addContent(new Element("postal").setText(pub.getPostal( ))); return pubElem; } private Element createBookElement(Book book) { Element bookElem = new Element("book"); // add publisher="oreilly" and isbn="1234567" attributes // to the <book> element bookElem.addAttribute("publisher", book.getPublisher().getId( )) .addAttribute("isbn", book.getISBN( )); // now add an <edition> element to <book> bookElem.addContent(new Element("edition").setText( Integer.toString(book.getEdition( )))); Element pubDate = new Element("publicationDate"); pubDate.addAttribute("mm", Integer.toString(book.getPublicationMonth( ))); pubDate.addAttribute("yy", Integer.toString(book.getPublicationYear( ))); bookElem.addContent(pubDate); bookElem.addContent(new Element("title").setText(book.getTitle( ))); bookElem.addContent(new Element("author").setText(book.getAuthor( ))); return bookElem; } public static void main(String[] args) throws IOException { Library lib = new Library( ); LibraryJDOMCreator ljc = new LibraryJDOMCreator( ); Document doc = ljc.createDocument(lib); // Write the XML to System.out, indent two spaces, include // newlines after each element new XMLOutputter(" ", true, "UTF-8").output(doc, System.out); } }
The JDOM example is structured just like the DOM example, beginning with a method that converts a Library object into a JDOM Document:
public Document createDocument(Library library) {The most striking difference in this particular method is the way in which the Document and its Element s are created. In JDOM, you simply create Java objects to represent items in your XML data. This contrasts with the DOM approach, which relies on interfaces and factory methods. Creating the Document is also easy in JDOM:
Element root = new Element("library");
// JDOM supports the <!DOCTYPE...>
DocType dt = new DocType("library", "library.dtd");
Document doc = new Document(root, dt);As this comment indicates, JDOM allows you to refer to a DTD, while DOM does not. This is just another odd limitation of DOM that forces you to include implementation-specific code in your Java applications. Another area where JDOM shines is in its ability to create new elements. Unlike DOM, text is set directly on the Element objects, which is more intuitive to Java programmers:
private Element createPublisherElement(Publisher pub) {
Element pubElem = new Element("publisher");
pubElem.addAttribute("id", pub.getId( ));
pubElem.addContent(new Element("name").setText(pub.getName( )));
pubElem.addContent(new Element("street").setText(pub.getStreet( )));
pubElem.addContent(new Element("city").setText(pub.getCity( )));
pubElem.addContent(new Element("state").setText(pub.getState( )));
pubElem.addContent(new Element("postal").setText(pub.getPostal( )));
return pubElem;
}Since methods such as addContent( ) and addAttribute( ) return a reference to the Element instance, the code shown here could have been written as one long line. This is similar to StringBuffer.append( ), which can also be "chained" together:
buf.append("a").append("b").append("c");In an effort to keep the JDOM code more readable, however, our example adds one element per line.
The final piece of this pie is the ability to print out the contents of JDOM as an XML file. JDOM includes a class called XMLOutputter, which allows us to generate the XML for a Document object in a single line of code:
new XMLOutputter(" ", true, "UTF-8").output(doc, System.out);The three arguments to XMLOutputter indicate that it should use two spaces for indentation, include linefeeds, and encode its output using UTF-8.
1.2.4.4. JDOM and DOM interoperability
Current XSLT processors are very flexible, generally supporting any of the following sources for XML or XSLT input:
-
a DOM tree or output from a SAX parser
-
any Java InputStream or Reader
-
a URI, file name, or java.io.File object
JDOM is not directly supported by some XSLT processors, although this is changing fast.[4] For this reason, it is typical to convert a JDOM Document instance to some other format so it can be fed into an XSLT processor for transformation. Fortunately, the JDOM package provides a class called DOMOutputter that can easily make the transformation:
[4] As this book went to press, Version 6.4 of SAXON was released with beta support for transforming JDOM trees. Additionally, JDOM beta 7 introduces two new classes, JDOMSource and JDOMResult, that interoperate with any JAXP-compliant XSLT processor.
org.jdom.output.DOMOutputter outputter =
new org.jdom.output.DOMOutputter( );
org.w3c.dom.Document domDoc = outputter.output(jdomDoc);The DOM Document object can then be used with any of the XSLT processors or a whole host of other XML libraries and tools. JDOM also includes a class that can convert a Document into a series of SAX events and another that can send XML data to an OutputStream or Writer. In time, it seems likely that tools will begin offering native support for JDOM, making extra conversions unnecessary. The details of all these techniques are covered in Chapter 5, "XSLT Processing with Java".
|  | |
| 1. Introduction |  | 1.3. Beyond Dynamic Web Pages |

Copyright © 2002 O'Reilly & Associates. All rights reserved.