
 |  |
14.2. mytechbooks.com
With the Foobar Public Library allowing access to an XML listing of its new books, mytechbooks.com is moving closer to its goal of providing up-to-date content to its customers. In addition, mytechbooks.com already has an established standard for using Java for application development. This makes the process of accessing and using the XML from the library even easier, as Java has the excellent support for XML we have been looking at throughout this book. You'll need to allow mytechbooks.com to provide an online listing of new books first, and then look at how to get this information out to its customers automatically.
14.2.1. Filtering XML Data
If you remember, the Foobar Public Library allowed books on several different subjects to be entered into its system; mytechbooks.com wants only the books about computer-related subjects. Fortunately, the library captured this information in the subject attribute of the book element for each book in its XML data. The first task is to filter out any book whose subject is not "Computers". Once the technical books have been obtained, they should be formatted into an HTML page that can be shown to customers visiting mytechbooks.com.
For this company and application, there is no static HTML, since the page showing new listings must be generated each time it is accessed. I'm going to use a servlet here for handling these responses. Although Apache Cocoon would be an excellent choice for converting the XML data from the library into an HTML response, mytechbooks.com is under tremendous time pressure to make these book listings available, and does not want to introduce such a large change into its system immediately; instead, it would prefer to use XML parsers and processors and then add Cocoon in as a second-phase addition. This means that you'll have to handle conversion from XML to HTML as well as the filtering of the data and the addition of other presentation-specific items, such as a company logo and menu bar.
However, taking all the information at your disposal about XML and XSL, you remember that even without Cocoon you can use XSL to transform an XML document into HTML. Applying a transformation would also allow you to filter out the books that do not have the subject criteria that mytechbooks.com desires. With this in mind, it's simple to create an XSL stylesheet that can be applied to the XML response from the Foobar Public Library. Example 14-4 shows the beginning of this stylesheet, which handles generation of the HTML specific to the mytechbooks.com web site.
Example 14-4. XSL stylesheet for Foobar Public Library book listings
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0"
>
<xsl:template match="books">
<html>
<head>
<title>mytechbooks.com - Your Computer Bookstore</title>
</head>
<body background="/javaxml/techbooks/images/background.gif"
link="#FFFFFF" vlink="#FFFFFF" alink="#FFFFFF">
<h1 align="center">
<font face="Arial" color="#00659C">
<mytechbooks.com>
</font>
</h1>
<p align="center">
<i><b>
Your source on the Web for computing and technical books.
</b></i>
</p>
<p align="center">
<b><font size="4" color="#00659C">
<u>New Listings</u>
</font></b>
</p>
<table border="0" cellpadding="5" cellspacing="5">
<tr>
<td valign="top" align="center" nowrap="nowrap" width="115">
<p align="center">
<font color="#FFFFFF"><b>
<a href="/javaxml/techbooks/">Home</a>
</b></font>
</p>
<p align="center">
<font color="#FFFFFF"><b>
<a href="/javaxml/techbooks/current.html">Current Listings</a>
</b></font>
</p>
<p align="center">
<b><font color="#FFFFFF">
<i>New Listings</i>
</font></b>
</p>
<p align="center">
<font color="#FFFFFF"><b>
<a href="/javaxml/techbooks/contact.html">Contact Us</a>
</b></font>
</p>
</td>
<td valign="top" align="left">
<table border="0" cellpadding="5" cellspacing="5">
<tr>
<td width="450" align="left" valign="top">
<p>
<b>
Welcome to <font face="courier">mytechbooks.com</font>,
your source on the Web for computing and technical books.
Our newest offerings are listed on the left. To purchase
any of these fine books, simply click on the
"Buy this Book!" link, and you will be taken to
the shopping cart for our store. Enjoy!
</b>
</p>
<p>
<b>
You should also check out our current listings, information
about the store, and you can call us with your questions.
Use the links on the menu to the left to access this
information. Thanks for shopping!
</b>
</p>
</td>
<td align="left">
<!-- Handle creation of content for each new *computer* book -->
</td>
</tr>
</table>
</td>
</tr>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>While this doesn't yet filter the incoming XML data or transform that data, it does take care of the HTML interface for the user. Often it is much easier to take care of these presentation details first, and then add the transformation-specific logic afterwards.
NOTE: When developing XSL stylesheets, particularly for web applications, you should test the results with your XSLT Processor using its command-line capabilities. This can help you ensure that the stylesheet is transforming your document as you expect at each step of its development; trying to debug a large stylesheet's problems once it is complete is much more difficult. For this example, you could access the supplyBooks.pl script in a web browser, save the results to an XML file, and test that and the stylesheet as you follow the examples.
Similar to the Foobar Public Library's application, this provides a menu on the left with hyperlinks to other portions of the application, contains some text about the company and its offerings, and then leaves a right column open for the addition of new book listings.
Before filtering the content, you need to add a template for outputting HTML content from a single book element's entry. As you recall, an entry looks like this:
<book subject="Computers"> <title><![CDATA[Running Linux]]></title> <author><![CDATA[Matt Welsh]]></author> <publisher><![CDATA[O'Reilly & Associates]]></publisher> <numPages>729</numPages> <saleDetails> <isbn> 156592469X</isbn> <price>39.95</price> </saleDetails> <description><![CDATA[In the tradition of all O'Reilly books, Running Linux features clear, step-by-step instructions that always seem to provide just the right amount of information.]]></description> </book>
You can then convert this to HTML with the following XSL template:
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0"
>
<xsl:template match="books">
<!-- Presentation of User Interface -->
</xsl:template>
<xsl:template match="book">
<table border="0" cellspacing="1" bgcolor="#000000">
<tr>
<td>
<table border="0" cellpadding="3" cellspacing="0">
<tr>
<td width="100%" bgcolor="#00659C" nowrap="nowrap" align="center">
<b><font color="#FFFFFF">
<xsl:value-of select="title" />
</font></b>
</td>
</tr>
<tr>
<td width="100%" align="center" nowrap="nowrap" bgcolor="#FFFFFF">
<font color="#000000"><b>
Author: <xsl:value-of select="author" /><br />
Publisher: <xsl:value-of select="publisher" /><br />
Pages: <xsl:value-of select="numPages" /><br />
Price: <xsl:value-of select="saleDetails/price" /><br />
<br />
</b></font>
<xsl:element name="a">
<xsl:attribute name="href">/servlets/BuyBookServlet?isbn=
<xsl:value-of select="saleDetails/isbn" />
</xsl:attribute>
<font color="#00659C">Buy the Book!</font>
</xsl:element>
</td>
</tr>
</table>
</td>
</tr>
</table>
<br />
</xsl:template>
</xsl:stylesheet>This template matches the book element, and then creates a table with a heading in one row, and contents in the second row. The entire table is within another table with a black background, which results in the appearance of the table being surrounded by a beveled black border. The title is inserted into the header of the table, and the information about the book (author, publisher, pages, and price) is added to the content of the table. Finally, a link to a Java servlet, BuyBookServlet, is provided to allow easy access to purchasing the book. The value of the book's isbn element is supplied as an argument to this servlet, which enables it to load the book being purchased.
WARNING: In your XSL stylesheet, you should ensure that the line indicating the use of BuyBookServlet and the line with the xsl:value-of element selecting the book's ISBN number is actually one single line. If not, spaces and a carriage return could be inserted into the resultant URL, causing incorrect information to be passed to the servlet. The example stylesheet has this information broken into two lines because of the space constraints of the printed page.
The last addition you need to make to your stylesheet is to ensure that the new template is applied, and that only books with the subject "Computers" are passed to the new template. You can reference the value of the subject attribute with the @ symbol in your stylesheet, and filter the requests with the select attribute on the xsl:apply-templates element:
</td> <td align="left"> <!-- Handle creation of content for each new *computer* book --> <xsl:apply-templates select="book[@subject='Computers']" /> </td> </tr> </table>
This references the value of the attribute and compares it to a literal, enclosed within single quotes because the entire XPath expression is enclosed within double quotes. Because you are accessing an attribute of a nested element, you'll need to reference the element by name, and surround the expression on the element's attribute with brackets. This will ensure that only books with a subject of "Computers" have templates applied, and are therefore included in the HTML output. Once the stylesheet is complete, it can be saved as computerBooks.xsl and referenced programmatically by a Java servlet, which I'll show you how to write next.
14.2.2. XSLT from a Servlet
With your stylesheet ready for use, you need to add Java code to apply it to the XML data from the Foobar Public Library. This data is accessed easily by using Java's java.net.URL class to make an HTTP request to the library's system. Once you have this set up, all that is left is to actually apply the XSL transformation programmatically. Example 14-5 shows the Java servlet code that loads the XML data from the library, and indicates where the transformation code would be inserted.
Example 14-5. Java Servlet for transforming book listings into HTML
package com.techbooks;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.IOException;
import java.io.PrintWriter;
import java.net.URL;
import javax.servlet.*;
import javax.servlet.http.*;
public class ListBooksServlet extends HttpServlet {
/** Host to connect to for books list */
private static final String hostname = "newInstance.com";
/** Port number to connect to for books list */
private static final int portNumber = 80;
/** File to request (URI path) for books list */
private static final String file = "/cgi/supplyBooks.pl";
/** Stylesheet to apply to XML */
private static final String stylesheet =
"/home/bmclaugh/javaxml/techbooks/XSL/computerBooks.xsl";
public void service(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/html");
// Connect and get XML listing of books
URL getBooksURL = new URL("http", hostname, portNumber, file);
InputStream in = getBooksURL.openStream();
// Transform XML for InputStream into HTML output
}
}This simple servlet requests the Foobar Public Library's application through an HTTP request, and gets the XML response in an InputStream.[22] This stream should then be used as a parameter to the XSLT processor, as well as the XSL stylesheet defined as a constant in the servlet.
[22] For more information on the URL class and Java I/O, see Java I/O by Elliotte Rusty Harold (O'Reilly).
There is currently no Java API that specifies how XSLT transformations can occur programmatically; however, each processor vendor should have classes that allow a transformation to be invoked from your Java code. I continue to look at using the Apache Xalan processor here; you should consult your processor's vendor for the method or methods to invoke in your own programs.
For Apache Xalan, the XSLTProcessor class is provided in the org.apache.xalan.xslt package for just this purpose. It takes as parameters an XSLTInputSource wrapping the XML file to process, an XSLTInputSource wrapping the XSL stylesheet to apply, and an XSLTResultTarget to use for output of the transformation. All three of these helper classes are in the org.apache.xalan.xslt package as well. They can conveniently be created by passing in an InputStream (to XSLTInputSource) or an OutputStream (to XSLTResultTarget). You have the XML document as an InputStream, you can wrap the XSL stylesheet within a FileInputStream, and the servlet API provides easy access to the ServletOutputStream object through the getOutputStream() method on the HttpServletResponse object. The last detail to address is obtaining an instance of XSLTProcessor. Because there are several underlying mechanisms that can be used for processing, this class is not instantiated directly, but rather obtained through the XSLTProcessorFactory class, also in the org.apache.xalan.xslt package. You should be familiar with factory classes by now, so all that is left is to import the classes you'll need and add the processing method calls to the servlet:
package com.techbooks;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.IOException;
import java.io.PrintWriter;
import java.net.URL;
import javax.servlet.*;
import javax.servlet.http.*;
// Import Xalan XSLT Processor components
import org.apache.xalan.xslt.XSLTInputSource;
import org.apache.xalan.xslt.XSLTProcessor;
import org.apache.xalan.xslt.XSLTProcessorFactory;
import org.apache.xalan.xslt.XSLTResultTarget;
public class ListBooksServlet extends HttpServlet {
/** Host to connect to for books list */
private static final String hostname = "newInstance.com";
/** Port number to connect to for books list */
private static final int portNumber = 80;
/** File to request (URI path) for books list */
private static final String file = "/cgi/supplyBooks.pl";
/** Stylesheet to apply to XML */
private static final String stylesheet =
"/home/bmclaugh/javaxml/techbooks/XSL/computerBooks.xsl";
public void service(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/html");
// Connect and get XML listing of books
URL getBooksURL = new URL("http", hostname, portNumber, file);
InputStream in = getBooksURL.openStream();
// Transform XML for InputStream into HTML output
try {
XSLTProcessor processor = XSLTProcessorFactory.getProcessor();
// Transform XML with XSL stylesheet
processor.process(new XSLTInputSource(in),
new XSLTInputSource(
new FileInputStream(stylesheet)),
new XSLTResultTarget(
res.getOutputStream()));
} catch (Exception e) {
PrintWriter out = res.getWriter();
out.println("Error: " + e.getMessage());
out.close();
}
}
}NOTE: I could have also used JAXP 1.1's TrAX API for performing this translation. However, JAXP 1.1 is still pretty new as of this writing, and I see few people adopting it (yet). Additionally, most servlet engines, especially Tomcat, still ship with JAXP 1.0, and many are relying on that default behavior rather than supplying a newer version of JAXP.
When this new servlet is requested, it in turn requests the XML data from the Foobar Public Library. This data (a listing of the newly available books) is then transformed and output to the screen as HTML. The response from the servlet should look similar to Figure 14-4.
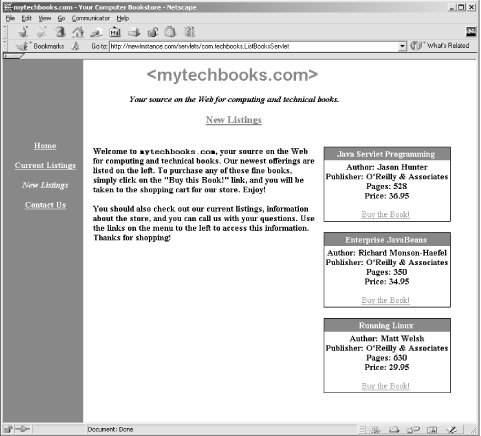
Figure 14-4. HTML output from mytechbooks.com new book listing
Along with the menu links on the left (not implemented in this example), the newest book listings are printed in a very nice format, all with up-to-date information (thanks to the changes at the Foobar Public Library!) as well as links to buy the book with a few mouseclicks. Now mytechbooks.com customers can easily browse the new book listings online; all that is left is to push this information out to these customers, so they don't even have to type in a URL. I'll look at solving this difficult problem next.
|  | |
| 14. Content Syndication |  | 14.3. Push Versus Pull |

Copyright © 2002 O'Reilly & Associates. All rights reserved.