
 |  |
2.3. Transformations
As useful as XML transformations can be, they are not simple to implement. In fact, rather than trying to specify the transformation of XML in the original XML 1.0 specification, three separate recommendations have come out to define how transformations should occur. Although one of these (XPath) is also used in several other XML specifications, by far the most common use of the components I outline here is to transform XML from one format into another.
Because these three specifications are tied together tightly and almost always used in concert, there is rarely a clear distinction between them. This can often make for a discussion that is easy to understand, but not necessarily technically correct. In other words, the term XSLT, which refers specifically to extensible stylesheet transformations, is often applied to both extensible stylesheets (XSL) and XPath. In the same fashion, XSL is often used as a grouping term for all three technologies. In this section, I distinguish among the three recommendations, and remain true to the letter of the specifications outlining these technologies. However, in the interest of clarity, I use XSL and XSLT interchangeably to refer to the complete transformation process throughout the rest of the book. Although this may not follow the letter of these specifications, it certainly follows their spirit, as well as avoiding lengthy definitions of simple concepts when you already understand what I mean.
2.3.1. XSL
XSL is the Extensible Stylesheet Language. It is defined as a language for expressing stylesheets. This broad definition is broken down into two parts:
-
XSL is a language for transforming XML documents.
-
XSL is an XML vocabulary for specifying the formatting of XML documents.
The definitions are similar, but one deals with moving from one XML document form to another, while the other focuses on the actual presentation of content within each document. Perhaps a clearer definition would be to say that XSL handles the specification of how to transform a document from format A to format B. The components of the language handle the processing and identification of the constructs used to do this.
2.3.1.1. XSL and trees
The most important concept to understand in XSL is that all data within XSL processing stages is in tree structures (see Figure 2-1). In fact, the rules you define using XSL are themselves held in a tree structure. This allows simple processing of the hierarchical structure of XML documents. Templates are used to match the root element of the XML document being processed. Then "leaf" rules are applied to "leaf" elements, filtering down to the most nested elements. At any point in this progression, elements can be processed, styled, ignored, copied, or have a variety of other things done to them.
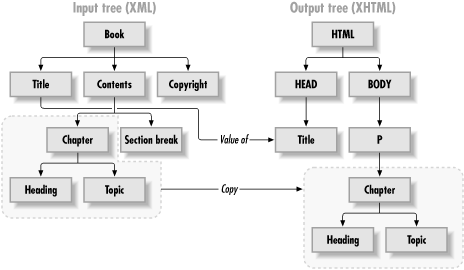
Figure 2-1. Tree operations within XSL
A nice advantage of this tree structure is that it allows the grouping of XML documents to be maintained. If element A contains elements B and C, and element A is moved or copied, the elements contained within it receive the same treatment.
This makes the handling of large data sections that need to receive the same treatment fast and easy to notate concisely in the XSL stylesheet. You will see more about how this tree is constructed when I talk specifically about XSLT in the next section.
2.3.1.2. Formatting objects
The XSL specification is almost entirely concerned with defining formatting objects. A formatting object is based on a large model, not surprisingly called the formatting model. This model is all about a set of objects that are fed as input into a formatter. The formatter applies the objects to the document, either in whole or in part, and what results is a new document that consists of all or part of the data from the original XML document in a format specific to the objects the formatter used. Because this is such a vague, shadowy concept, the XSL specification attempts to define a concrete model these objects should conform to. In other words, a large set of properties and vocabulary make up the set of features that formatting objects can use. These include the types of areas that may be visualized by the objects, the properties of lines, fonts, graphics, and other visual objects, inline and block formatting objects, and a wealth of other syntactical constructs.
Formatting objects are used heavily when converting textual XML data into binary formats such as PDF files, images, or document formats such as Microsoft Word. For transforming XML data to another textual format, these objects are seldom used explicitly. Although an underlying part of the stylesheet logic, formatting objects are rarely invoked directly, since the resulting textual data often conforms to another predefined markup language such as HTML. Because most enterprise applications today are based at least in part on web architecture and use a browser as a client, I spend the most time looking at transformations to HTML and XHTML. While formatting objects are covered only lightly, the topic is broad enough to merit its own coverage in a separate book. For further information, consult the XSL specification at http://www.w3.org/TR/WD-xsl.
2.3.2. XSLT
The second component of XML transformations is XSL Transformations. XSLT is the language that specifies the conversion of a document from one format to another (where XSL defined the means of that specification). The syntax used within XSLT is generally concerned with textual transformations that do not result in binary data output. For example, XSLT is instrumental is generating HTML or WML (Wireless Markup Language) from an XML document. In fact, the XSLT specification outlines the syntax of an XSL stylesheet more explicitly than the XSL specification itself!
Just as in the case of XSL, XSLT is always well-formed, valid XML. A DTD is defined for XSL and XSLT that delineates the allowed constructs. For this reason, you should only have to learn new syntax to use XSLT as opposed to the entirely new structures that had to be digested to use DTDs themselves. Just as in XSL, XSLT is based on a hierarchical tree structure of data, where nested elements are leaves, or children, of their parents. XSLT provides a mechanism for matching patterns within the original XML document (using an XPath expression, which I'll discuss next), and applying formatting to that data. This results in simply outputting the data without the unwanted XML element names, or inserting the data into a complex HTML table and displaying it to the user with highlighting and coloring. XSLT also provides syntax for many common operators, such as conditionals, copying of document tree fragments, advanced pattern matching, and the ability to access elements within the input XML data in an absolute and relative path structure. All these constructs are designed to ease the process of transforming an XML document into a new format. For a thorough treatment of the XSLT language, see Java and XSLT by Eric Burke (O'Reilly), which has an excellent discussion of how to put XSLT to work with Java.
2.3.3. XPath
The final piece of the XML transformations puzzle, XPath provides a mechanism for referring to the wide variety of element and attribute names and values in an XML document. As I mentioned earlier, many XML specifications are now using XPath, but this discussion is concerned only with its use in XSLT. With the complex structure that an XML document can have, locating one specific element or set of elements can be difficult. It is made more difficult because access to a DTD or other set of constraints that outlines the document's structure cannot be assumed; documents that are not validated must be able to be transformed just as valid documents can. To accomplish this addressing of elements, XPath defines syntax in line with the tree structure of XML, and the XSLT processes and constructs that use it.
Referencing any element or attribute within an XML document is most easily accomplished by specifying the path to the element relative to the current element being processed. In other words, if element B is the current element and element C and element D are nested within it, a relative path most easily locates them. This is similar to the relative paths used in operating system directory structures. At the same time, XPath also defines addressing for elements relative to the root of a document. This covers the common case of needing to reference an element not within the current element's scope; in other words, an element that is not nested within the element being processed. Finally, XPath defines syntax for actual pattern matching: find an element whose parent is element E and which has a sibling element F. This fills in the gaps left between the absolute and relative paths. In all these expressions, attributes can be used as well, with similar matching abilities. Several examples are shown in Example 2-6.
Example 2-6. XPath expressions
<!-- Match the element named Book relative to the current element --> <xsl:value-of select="Book" /> <!-- Match the element named Contents nested within the Book element --> <xsl:value-of select="Book/Contents" /> <!-- Match the Contents element using an absolute path --> <xsl:value-of select="/Book/Contents" /> <!-- Match the name attribute of the current element --> <xsl:value-of select="@name" /> <!-- Match the title attribute of the Chapter element --> <xsl:value-of select="Chapter/@title" />
Because the input document is often not fixed, an XPath expression can result in the evaluation of no input data, one input element or attribute, or multiple input elements and attributes. This ability makes XPath very useful and handy; it also causes the introduction of some additional terms. The result of evaluating an XPath expression is generally referred to as a node set. This name shouldn't be surprising, as it is in line with the idea of a hierarchical or tree structure, often dealt with in terms of its leaves or nodes. The resultant node set can then be transformed, copied, or ignored, or have any other legal operation performed on it. In addition to expressions to select node sets, XPath also defines several node set functions, such as not( ) and count( ). These functions take in a node set as input (typically in the form of an XPath expression) and then further pare the results. All of these expressions and functions are collectively part of the XPath specification and XPath implementations; however, XPath is also often used to signify any expression that conforms to the specification itself. As with XSL and XSLT, this makes it easier to talk about XSL and XPath, though it is not always technically correct.
With all that in mind, you're at least somewhat prepared to take a look at a simple XSL stylesheet, shown in Example 2-7. Although you may not understand all of this now, let's briefly look at some key aspects of the stylesheet.
Example 2-7. XSL stylesheet for Example 2-1
<?xml version="1.0"?>
<xsl:stylesheet xmlns:javaxml2="http://www.oreilly.com/javaxml2"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:ora="http://www.oreilly.com"
version="1.0"
>
<xsl:template match="javaxml2:book">
<html>
<head>
<title><xsl:value-of select="javaxml2:title" /></title>
</head>
<body>
<xsl:apply-templates select="*[not(self::javaxml2:title)]" />
</body>
</html>
</xsl:template>
<xsl:template match="javaxml2:contents">
<center>
<h2>Table of Contents</h2>
</center>
<hr />
<ul>
<xsl:for-each select="javaxml2:chapter">
<b>
Chapter <xsl:value-of select="@number" />.
<xsl:text> </xsl:text>
<xsl:value-of select="@title" />
</b>
<xsl:for-each select="javaxml2:topic">
<ul>
<li><xsl:value-of select="@name" /></li>
</ul>
</xsl:for-each>
</xsl:for-each>
</ul>
</xsl:template>
<xsl:template match="ora:copyright">
<p align="center"><font size="-1">
<xsl:copy-of select="*" />
</font></p>
</xsl:template>
</xsl:stylesheet>2.3.3.1. Template matching
The basis of all XSL work is template matching. For any element you want some sort of output to occur on, you generally provide a template that matches the element. You signify a template with the template keyword, and provide the name of the element to match in its match attribute:
<xsl:template match="javaxml2:book">
<html>
<head>
<title><xsl:value-of select="javaxml2:title" /></title>
</head>
<body>
<xsl:apply-templates select="*[not(self::javaxml2:title)]" />
</body>
</html>
</xsl:template>Here, the book element (in the javaxml2-associated namespace) is being matched. When an XSL processor encounters the book element, the instructions within this template are carried out. In the example, several HTML formatting tags are output (the html, head, title, and body tags). Be sure to distinguish your XSL elements from other elements (such as HTML elements) with proper use of namespaces.
Instead of applying a template, you can use the value-of construct to obtain the value of an element, and provide the element name to match through the select attribute. In the example, the character data within the title element is extracted and used as the title of the HTML form to output.
On the other hand, when you want to cause the templates associated with an element's children to be applied, use apply-templates. Be sure to do this, or nested elements can be ignored! You can specify the elements to apply templates to using the select attribute; by specifying a value of "*" to that attribute, all templates left will be applied to all nested elements. In the example, though, I want to exclude the title element (since I already used it in the document heading). To accomplish this, I've used the not keyword, and specified the title element on the self axis, which basically means "everything (*), except (not) the title element in this document (self::javaxml2:title). That's a quick overview, but I'm just trying to give you enough information to move on to the Java code.
2.3.3.2. Looping
You'll also often find a need for looping in XSL. Look at this fragment from Example 2-7:
<xsl:template match="javaxml2:contents">
<center>
<h2>Table of Contents</h2>
</center>
<hr />
<ul>
<xsl:for-each select="javaxml2:chapter">
<b>
Chapter <xsl:value-of select="@number" />.
<xsl:text> </xsl:text>
<xsl:value-of select="@title" />
</b>
<xsl:for-each select="javaxml2:topic">
<ul>
<li><xsl:value-of select="@name" /></li>
</ul>
</xsl:for-each>
</xsl:for-each>
</ul>
</xsl:template>Here, I'm looping through each element named chapter using the for-each construct. In Java, this would be:
for (Iterator i = chapters.iterator(); i.hasNext( ); ) {
// take action on each chapter
}Within the loop, the "current" element becomes the next chapter element encountered. For each, I output the chapter number; this is accomplished by getting the value (through value-of) of the number attribute. To indicate that I want an attribute (not the default, an element), I prefix the attribute name with the "@" sign. I do the same thing to get the title attribute's value, and then in a subloop I move through the topics for each chapter.
Notice the rather odd code fragment <xsl:text> <xsl:text>. The text construct provides a way to directly output characters to the result tree. This construct generates a space between the word "Chapter" and the chapter number (there is a single space between the opening and closing text tags).
2.3.3.3. Copying
You will also find times when all the template matching in the world isn't as useful as simply passing on the content, unchanged, to the output tree. This is the case with the copyright element:
<xsl:template match="ora:copyright"> <p align="center"><font size="-1"> <xsl:copy-of select="*" /> </font></p> </xsl:template>
In addition to a little bit of HTML formatting, this template instructs all the content of the copyright element to be copied to the output tree, using the copy-of construct. Simple enough.
You'll learn how to use a publishing framework like Cocoon to render the result of this transformation to HTML, a PDF, or more in Chapter 10, "Web Publishing Frameworks". Rather than keeping you waiting, though, Figure 2-2 shows the transformed output from Example 2-1 and the stylesheet in Example 2-6.
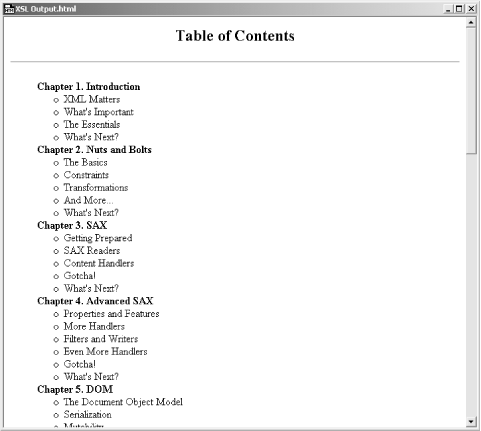
Figure 2-2. Result of XSL transformation
I realize that I've virtually flown through this material, but again, I'm just trying to get you past the basics and to the good stuff, the Java and XML. Have a reference handy, and don't sweat it too much.
|  | |
| 2.2. Constraints |  | 2.4. And More... |

Copyright © 2002 O'Reilly & Associates. All rights reserved.