
 |  |
5.7. Changing Content
The new paradigm of the W3C DOM's node-centric structure has the greatest impact on the way scripts modify text and element content in a document. Those scripters who learned DHTML under the element-centric Microsoft aegis can easily find themselves lost amid the new concepts that the W3C DOM imposes. While the W3C DOM makes a great deal of sense in a world tending toward XML (including the XML-flavored version of HTML), even experienced DHTML scripters soon discover that Microsoft implements many convenience features in its DOM that simplify DHTML scripting. Many of these conveniences, however, are not (or at least not yet) part of the released W3C DOM recommendations.
This state of affairs leaves browser makers, such as Mozilla, in an awkward position. On the one hand, browser makers want to produce the most standards-compliant browsers on the Web. But to do so would require that developers not only rewrite tons of scripts (already necessitated by their abandonment of the layer), but also master new, and seemingly complex, ways of carrying out tasks that a nonstandard DOM handles with ease. What's a browser maker to do?
The designers could invent their own extensions to the W3C DOM paradigm to bypass the complexities. Or they could yield to developer pressure and implement the popular, but nonstandard, techniques found in other browsers, as convenient alternatives to the ways cast in W3C stone. In the case of the Mozilla browser, it does a little of both. Thus, the syntactic and conceptual paths you wish to follow are entirely up to you. In this section, you will see how to use the IE and W3C DOM ways of modifying the text inside an element and the elements themselves. Your ultimate choice will depend on factors such as the browser platform(s) you must support, your dedication to standards, and your own programming practices.
5.7.1. Changing Element Text
Element text is nothing more than tagless content that resides inside an HTML container, such as a p, span, or td element. The tag provides the context for whatever words comprise the text. The IE DOM treats the text content as a property of an element object; the W3C DOM treats that same text as an object unto itself.
5.7.1.1. IE text
Every IE DOM container element object has an innerText property. The value of this read-write property is a string data type. You can use an assignment operator to place new text inside the container:
elementReference.innerText = "Your new text here.";
Assigning a value to this property with the = operator completely replaces its original content with the new text. You can also append text by using the += assignment operator. Style sheet rules that apply to the element govern the new text, just as they did for the original text.
A companion property, innerHTML, forces the container to treat the newly assigned string as if it were tagged HTML text. Although the innerHTML property is primarily for altering elements (as well as text), it's helpful to understand the differences between innerText and innerHTML. To help you visualize the differences between these properties, let's start with a nested pair of elements as they appear in a document's source code:
<p id="par1" style="font-style:normal">
A fairly short paragraph.
</p>Focus on the p element, whose properties will be adjusted in a moment. The inner component of the p element consists of the string of characters between the start and end tags, but not including those tags. Any changes you make to the inner content of this element still have everything wrapped inside a p element.
How an element's inner component responds to changes depends on whether you direct the element to treat the new material as raw text or as text that may have HTML tags inside (e.g., innerText or innerHTML). To demonstrate how these important nuances affect your work with these properties, the following sequence starts with the p element shown earlier, as it is displayed in the browser window. Then comes a series of statements that operate on the original element, alternating with the representation of the element as it appears in the browser window after each statement.
A fairly short paragraph.
document.all.par1.innerText = "How are <em>you</em>?";
How are <em>you</em>?
document.all.par1.innerHTML = "How are <em>you</em>?";
How are you?
Adjusting the inner material never touches the <p> tag, so the normal font style prevails, and no matter how often you modify the property values, the reference to the p element remains valid because the element is always there. Setting the innerText property tells the browser to render the content literally, without interpreting the <em> tags; setting innerHTML tells the browser to interpret the tags, which is why the word "you" is in italics after the second statement. Netscape 6 (and later) implements the IE innerHTML property of all container elements as a convenience to scripters. If the string you assign to the property contains no HTML elements, the result is the same as if the property were innerText. Thus, the one innerHTML property serves two purposes.
Another Microsoft invention is the insertAdjacentText( ) method of element objects, defined as follows:
insertAdjacentText(where, text)
This method assumes you have a valid reference to an existing element and wish to add content to the beginning or end of the element without disturbing existing text. The precise insert position for these methods is determined by the value of the where parameter. There are four choices:
- BeforeBegin
- In front of the start tag of the element
- AfterBegin
- After the start tag, but immediately before the text content of the element
- BeforeEnd
- At the very end of the content of the element, just in front of the end tag
- AfterEnd
- After the end tag of the element
Notice that the BeforeBegin and AfterEnd locations are outside of the element referenced in the statement. For example, consider the following nested pair of tags:
<span id="outer" style="color:red">
Start outer text.
<span id="inner" style="color:blue"> Some inner text.</span>
End of outer text.
</span>Now consider the following statement:
document.all.inner.insertAdjacentText("BeforeBegin", "Inserted!");The document changes so that the word "Inserted!" is rendered in a red font. This is because the text was added before the beginning of the inner item, and is therefore under the rule of the next outermost container: the outer element.
The insertAdjacentText( ) method was implemented for the first time in IE 4, in anticipation of what the unfinished W3C DOM was to be. But the W3C DOM took a different turn, so a number of Microsoft content manipulation inventions work only in IE (and some only in Windows versions). Table 5-2 provides a summary listing of the proprietary element object methods for a variety of text and element actions.
Table 5-2. IE element content manipulation methods
|
Method |
Description |
|---|---|
| contains(elemRef) |
Returns Boolean true if current element contains elemRef |
| getAdjacentText(where) |
Returns text sequence from position where (IE 5 and later for Windows only) |
| insertAdjacentElement(where, elemRef) |
Inserts new element object at position where (IE 5 and later for Windows only) |
| insertAdjacentHTML(where, HTMLText) |
Inserts text (at position where) which gets rendered as HTML |
| insertAdjacentText(where, text) |
Inserts text (at position where) as literal text |
| removeNode(deep) |
Deletes element or text node (and its child nodes if deep is true) |
| replaceAdjacentText(where, text) |
Replaces current text at position where with text (IE 5 and later for Windows only) |
| replaceNode(newNodeRef) |
Replace current node with new node (IE 5 and later for Windows only) |
| swapNode(otherNodeRef) |
Exchange current node with otherNodeRef, and return reference to removed node (IE 5 and later for Windows only) |
While all of these methods do their jobs in the IE versions that support them, they have counterparts or equivalent functionality in the W3C DOM, albeit with different syntax. IE 5 and later (both Windows and Mac) support the bulk of the W3C DOM versions of these methods, so there is little need to master both sets. For cross-DOM development, you are better served using the W3C DOM versions exclusively.
5.7.1.2. W3C DOM text
Absolutely everything in a document is an object of some kind in the eyes of the W3C DOM. As described in Chapter 1, the fundamental type of object in a W3C DOM document is the node. A document's structure can be described as a tree of nodes of various types. Each node object has a nodeType property that is one of twelve possible values (numbered 1 through 12). All nodes that represent a document's content grow from the root document node (a nodeType of 9). An element is another type of node (nodeType of 1), as is a text node (nodeType of 3) between the start and end tags of an element container.
Adjacent nodes bear parent-child-sibling relationships, the understanding of which is crucial to successful application of W3C node concepts. Consider the following series of element and text nodes:
<p id="myP">Where is <em id="myEM">Amy</em> today?</p>
The p element node has three child nodes. The first and third child nodes are text nodes, while the middle one is an element node (the em element). That em element, itself, has one child node—a three-character text node. The attributes in the two tags are themselves nodes (nodeType of 2), but attribute nodes are not part of the element and text node parent-child relationship model.
Each node object (regardless of type) has a set of properties that help scripts obtain references to adjacent nodes and read or write values associated with the node. Table 5-3 lists the common properties of every node object.
Table 5-3. Common node object properties
|
Property |
Value type |
Description |
|---|---|---|
| nodeName |
String |
Name associated with the node or node type |
| nodeValue |
String |
Value associated with the node (read-write) |
| nodeType |
Integer |
One of the 12 node types |
| parentNode |
Object |
Reference to next outermost container node |
| childNodes |
Array |
Child nodes in source code order |
| firstChild |
Object |
Reference to first child node |
| lastChild |
Object |
Reference to last child node |
| previousSibling |
Object |
Reference to preceding node at same generation |
| nextSibling |
Object |
Reference to next node at same generation |
| attributes |
NodeMap |
Collection of attribute nodes |
| ownerDocument |
Object |
Reference to root document node |
Of the properties listed in Table 5-3, the first three return important information, but their values depend upon the type of node. Table 5-4 lists the most common node types found in HTML documents and the kinds of values associated with the nodeType, nodeName, and nodeValue properties (see these properties' entries in Chapter 9 for all node types).
Table 5-4. Key W3C node types in HTML documents
|
nodeType constant |
nodeType integer |
nodeName |
nodeValue |
|---|---|---|---|
| ELEMENT_NODE | 1 | tag name | null |
| ATTRIBUTE_NODE | 2 | attribute name | attribute value |
| TEXT_NODE | 3 | #text | text data |
| COMMENT_NODE | 8 | #comment | comment text |
| DOCUMENT_NODE | 9 | #document | null |
The nodeValue property of a text node is of particular importance for a discussion of modifying an element's text. This property is the only read-write property of a text node, and is therefore the property to change if you wish to modify or replace existing text. The question remains, however, of how to reference a text node when the closest that your scripts can come to picking a node out of the document tree is an element node that has an ID assigned to it.
The element node that acts as the parent to the text node is the key. A script can reference that element, and use the properties of the element node to get a reference to the child text node. As an example, we'll use the same p element from the IE text example:
<p id="par1" style="font-style:normal">
A fairly short paragraph.
</p>The p element has one child text node . Equally valid references to that text node are:
document.getElementById("par1").firstChild
document.getElementById("par1").childNodes[0]One way to replace the text of that node with new text is to assign a string value to the nodeValue property of that text node:
document.getElementById("par1").firstChild.nodeValue = "Your new text here.";The W3C DOM, however, also provides a more formal way to replace one child node with another. In other words, you must first create a valid text node object that contains the new text, and then replace the old with the new. The sequence is as follows:
var newNode = document.createTextNode("Your new text here.");
var oldNode = document.getElementById("par1").firstChild;
var removedNode = document.getElementById("par1").replaceChild(newNode, oldNode);The replaceChild( ) method is one of several methods that all W3C DOM node objects have. Table 5-5 lists these methods.
Table 5-5. W3C DOM node object methods
|
Method |
Description |
|---|---|
| appendChild(newChildNode) |
Adds a child node to the end of the current node. Returns reference to newly appended node. |
| cloneNode(deep) |
Returns a copy of the node, with child nodes if deep argument is true. |
| hasChildNodes( ) |
Returns Boolean true if node has child nodes. |
| insertBefore(newNode, otherChildNode) |
Inserts newNode in front of otherChildNode (which must be a child of current node). |
| removeChild(childNode) |
Returns reference to child node removed from document tree. |
| replaceChild(newChild, oldChild) |
Replaces oldChild with newChild, returning reference to removed child. |
| supports(feature, version) |
Returns Boolean true if node supports a particular DOM feature. |
All of the text node manipulation techniques described here are implemented starting in IE 5 and Netscape 6. So, too, is the Microsoft innerHTML property, which can be used strictly for an element's text, as well. Which approach is best? No one approach is inherently better than the others; each has pros and cons.
Conceptually, the simplest way is the innerHTML property. It also tends to be the most compact approach, in case code size is one of your concerns. How long it will remain in browser implementations without becoming part of the W3C standard is anyone's guess. It should be a safe bet over the next few years, however.
Of the two W3C DOM approaches, the formal way of creating a text node and using a container's method to replace an existing text node best coincides with the spirit of the DOM. It is also good practice for working with node trees of XML documents and other parts of the DOM, such as event objects. The downside is the comparatively high cost in the number of source code bytes required to effect a relatively simple change.
5.7.2. Changing Elements and Document Structure
Essentially the same principles that affect modifying text also apply to modifying elements or chunks of HTML in a document. In other words, Microsoft invented some convenience properties that work nicely and quickly. They also invented a lot of additional syntax that was eventually trumped by W3C DOM syntax—and recent IE versions are saddled with all of that verbiage.
5.7.2.1. IE HTML and elements
The first DHTML implementation in IE 4 was predominantly HTML source code-oriented. That explains why the IE 4 DOM implemented the handy quartet of element object properties shown in Table 5-6.
Table 5-6. IE HTML and text properties
|
Property |
Description |
|---|---|
|
innerHTML |
All content inside the current element, rendered according to HTML rules |
|
innerText |
All content inside the current element, rendered according to HTML rules the current element, rendered as literal text |
|
outerHTML |
All content including the current element, rendered according to HTML rules |
|
outerText |
All content including the current element, rendered as literal text |
Assign a string to one of the "inner" properties to replace the current content with the new; use the "outer" properties to replace the current element with the new content. The "HTML" and "Text" suffixes of the properties instruct the browser how to render the string. Angle-bracketed tags assigned to the "Text" versions appear as-is; assigned to the "HTML" version, they get interpreted as if they were part of the source code. You have only one shot at assigning new content to an element's "outer" property, because the element disappears from the document once the new content appears.
To demonstrate the differences between the two "HTML" properties, we'll start with an empty td element (whose ID is cellB2) in a table:
<td id="cellB2"></td>
In the first transformation, we add some text with a tag in it. Even though we're modifying IE DOM properties, we'll use the W3C DOM element referencing terminology (to IE 5 and later, a reference is a reference, regardless of the syntax used to arrive at it):
document.getElementById("cellB2").innerHTML =
"Happy Birthday, <em id='birthdayboy'>Jack</em>!";The td element now looks like the following:
<td id="cellB2">Happy Birthday, <em id="birthdayboy">Jack</em>!</td>
For the second transformation, we wish to make the em element a span that holds different text and gets its style from a style sheet rule whose class selector is "hilite":
document.getElementById("birthdayboy").outerHTML =
"<span id='birthdaygirl' class='hilite'>Emma</span>";The td element now looks like the following:
<td id="cellB2">Happy Birthday, <span id="birthdaygirl" class="hilite">Emma</span>!</td>
Notice that the span element has completely replaced the em element.
Changes you make to these properties do not affect the source code view provided by the browser. But if you were to inspect the innerHTML or outerHTML properties of affected elements (perhaps through an alert dialog), you would see the effective HTML, as the browser sees it to build the object model for the document.
Of the properties in Table 5-5, the innerHTML property is the most popular. It allows a script to assemble a string of HTML tags, attributes, and content in a logical and easily debuggable way. Then bang, you can assign that string to replace whatever is currently inside an element's start and end tags. In fact, this property is so convenient and popular that content authors pressured the Mozilla engineers to implement it in their new browser, even though the property is not (at least not yet) part of the W3C DOM specification.
As for the rest of the Microsoft proprietary document tree manipulation methods (see Table 5-2) and properties, it may be better not to confuse the issue with too many examples. All of the vocabulary is listed in Chapter 9, but in the long run, you are better served by using the W3C DOM terminology for the more formal approach to adjusting elements and nodes. The W3C basics are implemented starting in IE 5, so the proprietary vocabulary is useful for IE 4 scripting, at best.
5.7.2.2. W3C DOM document tree
Modifying element content in the W3C DOM means that you are altering the node hierarchy of the document—the so-called document tree—and the rendered document at the same time. A typical HTML document has a skeletal node structure before you even get to the specific content of the page, as shown in Figure 5-1.
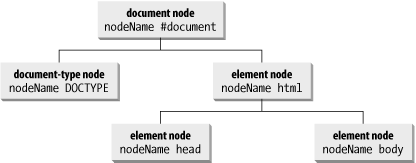
Figure 5-1. Skeletal node structure of a typical HTML document
In other words, the document node is the root node of the tree. It typically has two child nodes, represented in source code by the <!DOCTYPE> and <html> tags. Nested inside the <html> tag are one <head> tag and one <body> tag. All other document content is nested within the head and body elements. These fundamental nodes of an HTML document tree are immutable (a non-HTML-related XML document doesn't require these minimum elements, so very little is immutable in such a document). When we speak of modifying an HTML document tree structure, we're focusing on the elements and text nodes that go inside the head and body elements. The body element, of course, has several modifiable properties, but adjusting them does not impact the document tree.
Script access to nodes in the document tree is obtained exclusively by the various methods defined for the root Node object (see Table 5-5). If you have scripted changes to document content via the Microsoft innerHTML or outerHTML element object properties, it's important to understand that the W3C DOM Level 2 does not provide a string representation of the document tree. This goes for both reading and writing. Instead, you use methods to create and rearrange element and text node objects within the tree (for tables, however, see "Dynamic Tables" later in this chapter).
If your scripts need to generate new or replacement elements, they will follow a very typical W3C DOM sequence of operations:
-
For the first step, the scripts create an empty element object for a tag by calling document.createElement("tagName").
-
Then, set attribute values for the element object.
-
Create the text node with document.createTextNode("text") if the element is to contain a text node.
-
Append the text node to the element object with appendChild( ).
-
Insert the element into the document tree using some other addressable node as a referencing point.
The element and text node creation process takes place outside of the document tree. That is to say, you assign the results of a creation method to a script variable. That object is every bit the p, div, img, table, or other element object as those in the document tree, but if you were to walk the document tree structure, that new element will not be found until you explicitly insert it into the tree at the desired location.
To demonstrate this syntax, I'm going to repeat the td element modifications described earlier for the IE syntax. The first task is to insert some HTML into an empty td element. As a reminder, the string form of the inserted HTML looks like the following:
Happy Birthday, <em id="birthdayboy">Jack</em>!
To create content as nested W3C DOM node objects, it is frequently more convenient to start with the most nested content:
var txtNode = document.createTextNode("Jack");
var elem = document.createElement("em");
elem.setAttribute("id", "birthdayboy");
elem.appendChild(txtNode);We are now left with three sibling nodes (two not-yet-created text nodes and the element node) to stuff into the td element. There are a few different ways to accomplish this final part of the process.
The linear, brute force way is to create the first text node, append it to the td element, append the elem element, and then create and append the final text node to the td element. Carrying on from the first bit of code above, here's how we can assemble the rest of the content:
txtNode = document.createTextNode("Happy Birthday, "); // reuse var
var tdElem = document.getElementById("cellB2"); // for convenience
tdElem.appendChild(txtNode);
tdElem.appendChild(elem);
txtNode = document.createTextNode("!"); // reuse var again
tdElem.appendChild(txtNode);As an aside, you could also create nodes in the inverse order and insert from last to first via the insertBefore( ) method, rather than appendChild( ). For example, after defining tdElem:
tdElem.insertBefore(txtNode, tdElem.firstChild);
A second way to achieve the same goal is to assemble the inserted content inside a span element as a temporary container, and then drop the entire span into the td element. The need for the temporary span comes from the frame of reference of all Node object methods: that of a parent acting on its child nodes. In other words, you cannot simply glue one node to its sibling from the point of view of one of the sibling nodes. The parent rules the action. Thus, we get the following sequence:
var spanElem = document.createElement("span");
txtNode = document.createTextNode("Happy Birthday, "); // reuse var
spanElem.appendChild(txtNode);
spanElem.appendChild(elem);
txtNode = document.createTextNode("!"); // reuse var
spanElem.appendChild(txtNode);
document.getElementById("cellB2").appendChild(spanElem);If you don't want the span element cluttering up the td element, you can use another type of W3C DOM node object, the DocumentFragment. A document fragment is an arbitrary and context-less container of nodes. For the application here, it demonstrates one of its magical powers—removing itself when its contents get placed inside a real context. The sequence for this approach is:
var frag = document.createDocumentFragment( );
txtNode = document.createTextNode("Happy Birthday, "); // reuse var
frag.appendChild(txtNode);
frag.appendChild(elem);
txtNode = document.createTextNode("!"); // reuse var again
frag.appendChild(txtNode);
document.getElementById("cellB2").appendChild(frag );After the above sequence runs, the td cell has only the three child nodes in it, as desired. Be aware, however, that the DocumentFragment object is implemented only in Netscape 6 and later and IE 6 and later.
The next step in content modification is to replace one element with another from the point of view of the element being replaced (the functional equivalent of the IE outerHTML property). In our example, this means that a script has a reference to an element that is to be replaced by an entirely different element (or set of nested nodes).
The process begins by creating the replacement content. It consists of a span element and text within:
var newElem = document.createElement("span");
newElem.setAttribute("id", "birthdaygirl");
newElem.setAttribute("class", "hilite");
var newText = document.createTextNode("Emma");
newElem.appendChild(newText);Because all node methods operate on child nodes, the call to the replaceChild( ) method must come from the parent node of the element about to be replaced. The parentNode property provides the necessary reference:
var oldElem = document.getElementById("birthdayboy");
var removedNode = oldElem.parentNode.replaceChild(newElem, oldElem);The replaceChild( ) method returns a reference to the node that was removed. Although that old node is now out of the document tree, it is still in memory, and it could be placed elsewhere in the document, if desired.
Perhaps now you can understand why Mozilla pre-release testers rebelled against the long-winded process needed to modify element text and the document tree in an HTML document via the W3C model. The IE quartet of properties are more in the spirit of high-level scripting for which JavaScript was intended (in other words, Computer Science degree not required). They also require many fewer bytes of source code to reach the client. Although some programmers might disagree, Mozilla's designers deserve a lot of credit for implementing the innerHTML convenience property to supplement the orthodox W3C approach.
That's not to say that you should avoid the W3C approach and take the easy way out exclusively. While the verbosity and complexity of the W3C DOM can be intimidating at first, you may gain long-term leverage from the learning experience. If your scripting and programming will include more XML in the future, the core DOM techniques you learn now should be directly applicable. Both options—expediency or standards-based correctness—are valid for different sets of scripters and situations. Trust your own instincts.
|  | |
| 5.6. Changing Applied Style Values |  | 5.8. Dynamic Tables |

Copyright © 2003 O'Reilly & Associates. All rights reserved.