
 |  |
Chapter 16. The World Wide Web and Electronic Mail
Contents:
The previous chapter put you on a network. It may have been hard work, but the result was quite an accomplishment: your system is now part of a community. If you are connected to the Internet, the next step is to get access to all the riches this medium offers. People generally agree that the most useful applications on the Internet are the World Wide Web and electronic mail; they are the subjects of this chapter.
16.1. The World Wide Web
Most certainly, everybody who has even the slightest connection with computers has used the World Wide Web by now. Like word processors or spreadsheets some centuries ago, the Web is what gets many people to use computers at all in the first place. We'll cover here some of the tools you can use to access the Web on Linux.
Linux was from the beginning intimately connected to the Internet in general and the Web in particular. For example, the Linux Documentation Project (LDP) provides various Linux-related documents via the Web. The LDP home page, located at http://www.tldp.org, contains links to a number of other Linux-related pages around the world. The LDP home page is shown in Figure 16-1.
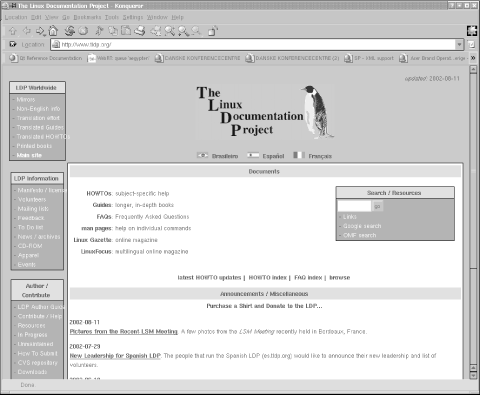
Figure 16-1. LDP home page on the World Wide Web
Linux web browsers usually can display information from several types of servers, not just HTTP servers sending clients HTML pages. For example, when accessing a document via HTTP, you are likely to see a page such as that displayed in Figure 16-1 — with embedded pictures, links to other pages, and so on. When accessing a document via FTP, you might see a directory listing of the FTP server, as seen in Figure 16-2. Clicking a link in the FTP document either retrieves the selected file or displays the contents of another directory.
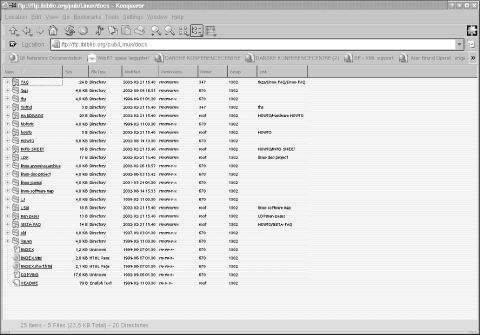
Figure 16-2. FTP directory as displayed in the Konqueror web browser
The way to refer to a document or other resource on the Web, of course, is through its Uniform Resource Locator, or URL. A URL is simply a pathname uniquely identifying a web document, including the machine it resides on, the filename of the document, and the protocol used to access it (FTP, HTTP, etc.). For example, the Linux Gazette, an online Linux periodical on the LDP web site, has the URL:
http://www.tldp.org/LDP/LG/current/index.html
Let's break this down. The first part of the URL, http:, identifies the protocol used for the document, which in this case is HTTP. The second part of the URL, //www.tldp.org, identifies the machine where the document is provided. The final portion of the URL, LDP/LG/current/index.html, is the logical pathname to the document on www.tldp.org. This is similar to a Unix pathname, in that it identifies the file index.html in the directory LDP/LG/current. Therefore, to access the current issue of the Linux Gazette, you'd fire up a browser, telling it to access http://www.tldp/LDP/LG/current/index.html. What could be easier?
Actually, the conventions of web servers do make it easier. If you specify a directory as the last element of the path, the server understands that you want the file index.html in that directory. So you can reach the current Linux Gazette issue with a URL as short as:
http://www.tldp.org/LDP/LG/current/
To access a file via anonymous FTP, we can use a URL, such as:
ftp://ftp.ibiblio.org/pub/linux/docs/INFO-SHEET/
This URL retrieves the introductory Linux information on ftp.ibiblio.org. Using this URL with your browser is identical to using ftp to fetch the file by hand.
The best way to understand the Web is to explore it. In the following section we'll explain how to get started with some of the available browsers. Later in the chapter, we'll cover how to configure your own machine as a web server for providing documents to the rest of the Web.
Of course, in order to access the Web, you'll need a machine with direct Internet access (via either Ethernet or PPP). In the following sections, we assume that you have already configured TCP/IP on your system and that you can successfully use clients, such as ssh and ftp.
16.1.1. Using Konqueror and Other Web Browsers
Konqueror is one of the most popular browsers for Linux. It features JavaScript and Java support, can run Netscape plug-ins (which allow you to add functions such as viewing Flash presentations), and is well integrated into the KDE desktop described in Section 11.2. Actually, when you install KDE, Konqueror will be installed as an integral part of the system. In the section on KDE, we have already described how to use Konqueror to read local information files. Now we are going to use it to browse the web.
Most things in Konqueror are quite obvious, but if you want to read more about it, you can use Konqueror to check out http://www.konqueror.org.
Here, we assume that you're using a networked Linux machine running X and that you have Konqueror installed. As stated before, your machine must be configured to use TCP/IP, and you should be able to use clients, such as ssh and ftp.
Starting Konqueror is simple. Run the command:
eggplant$ konqueror url
where url is the complete web address, or URL, for the document you wish to view. If you don't specify a URL, Konqueror will display a splash screen as shown in Figure 16-3.
Figure 16-3. The Konqueror splash screen
If you run Konqueror from within KDE, you can simply type Alt-F2 to open the so-called minicli window, and type the URL. This will start up Konqueror and point it directly to the URL you have specified.
We assume that you have already used a web browser to browse the Web on some computer system, so we won't go into the very basics here; we'll just point out a few Linux-specific things.
Keep in mind that retrieving documents on the Web can be slow at times. This depends on the speed of the network connection from your site to the server, as well as the traffic on the network at the time. In some cases, web sites may be so loaded that they simply refuse connections; if this is the case, Konqueror displays an appropriate error message. At the bottom edge of the Konqueror window, a status report is displayed, and while a transfer is taking place, the KDE gear logo in the upper-right corner of the window animates. Clicking the logo takes you back to the Konqueror home page.
As you traverse links within Netscape Navigator, each document is saved in the window history, which can be recalled using the Go menu. Pressing the Back button (the one that shows an arrow pointing to the left) in the top toolbar of the Konqueror window moves you back through the window history to previously visited documents. Similarly, the Forward button moves you forward through the history.
You can also
bookmark frequently visited web sites (or URLs) to
Konqueror's
"bookmarks." Whenever you are
viewing a document that you might want to return to later, choose Add
Bookmark from the Bookmarks menu, or simply press Ctrl-B. You can
display your bookmarks by choosing the Bookmarks menu. Selecting any
item in this menu retrieves the corresponding document from the Web.
Finally, you can also display your bookmarks permanently in a
separate subwindow to the left of the main browser window by
selecting Window  Show Navigation Panel, and
clicking the first of the selection buttons here (the one that looks
like a real bookmark). You can also use the navigation panel for
navigating your home directory, your hardware, your session history,
and many other things. Just try it, and you will discover many useful
features.
Show Navigation Panel, and
clicking the first of the selection buttons here (the one that looks
like a real bookmark). You can also use the navigation panel for
navigating your home directory, your hardware, your session history,
and many other things. Just try it, and you will discover many useful
features.
As mentioned previously, you can access new URLs by running konqueror with the URL as the argument. However, you can also simply type the URL in the location bar near the top of the Konqueror window. The location bar has autocompletion: if you start typing an address that you have visited before, Konqueror will automatically display it for your selection. Once you are done entering the URL (with or without help from autocompletion), you simply press the Enter key, and the corresponding document is retrieved.
Konqueror
is a powerful application with many options. You can customize
Konqueror's behavior in many ways by selecting
Settings Configure Konqueror.... The sections
Konqueror Browser and Enhanced Browsing provide particularly
interesting settings. In the section Cookies, you can configure
whether you want to accept cookies domain by domain and even check
the cookies already stored on your computer. Compare this to browsers
that hide the cookies deep in some hidden directory and make it hard
for you to view them (or even impossible without the use of extra
programs!).
Finally, one particular feature deserves mention. Web browsers register themselves with the server using the so-called "User Agent" string, which is a piece of text that can contain anything, but usually contains the name and version of the web browser, and the name and version of the host operating system. Some notably stupid webmasters serve different web pages (or none at all!) when the web browser is not Internet Explorer because they think that Internet Explorer is the only web browser capable of displaying their web site.[62] But by going to the User Agent section, you can fool the web server into believing that you are using a different browser, one that the web server is not too snobbish to serve documents to. Simply click New, select the domain name that you want to access, and either type a User Agent string of your own, or select one of the predefined ones.
[62]A web site that can be browsed with only one browser or that calls itself "optimized for browser X" should make you virtually run away, wringing your hands in wrath over such incompetence on the part of the webmaster.
Konqueror is not the only browser that reads web documents. Another browser available for Linux is Mozilla, the open source version of Netscape Navigator, the browser that made the Web popular to many in the first place. If your distribution does not contain Mozilla already, you can get it from http://www.mozilla.org. Mozilla's features are quite similar to Konqueror's, and whatever you do with one you should be able to do with the other. One thing Mozilla sports, but Konqueror doesn't, is the possibility of keeping several web pages in different "tab pages" within the main browser window. In order to view different web pages at the same time in Konqueror, you have to open several Konqueror windows (a mode that Mozilla supports as well).
Yet another versatile browser is Lynx. It is a text-based browser, so you miss the pictures on a web site. But this makes it fast, and you may find it convenient. You can also use it without the X Window System. Furthermore, when you want to save a page as plain text, Lynx often provides a better format than other browsers. And finally, for those who never want to leave Emacs, there is Emacs/W3, a fully featured web browser you can use within Emacs or XEmacs.
16.1.2. Configuring Your Own Web Server
Now that you've seen what the Web provides, you're ready to set up your own gas station on the information superhighway. Running your own web server is easy. It consists of two tasks: configuring the httpd daemon and writing documents to provide on the server.
httpd is the daemon that services HTTP requests on your machine. Any document accessed with an http URL is retrieved using httpd. Likewise, ftp URLs are accessed using ftpd, gopher URLs using gopherd, and so on. There is no single web daemon; each URL type uses a separate daemon to request information from the server.
Several HTTP servers are available. The one discussed here is the Apache httpd server, which is easy to configure and very flexible. In this section, we'll discuss how to install and configure the basic aspects of this version of httpd. Later in the chapter, we talk about how to write your own documents in HyperText Markup Language (HTML, the markup language used by web pages) as well as more advanced aspects of server configuration, such as providing interactive forms.
All Linux versions should carry Apache today as their default httpd server. However, if you have selected a "minimal" or "desktop" install, it might not have been installed during the installation procedure, and you might have to install it manually afterward. Or you may want to have a newer version than the one that your distribution carries (at the time of this writing, 2.0.40 is the current stable version); in this case you can download both sources and binaries from http://www.apache.org and build it yourself. The apache.org web site contains complete documentation for the software.
Apache — The Definitive Guide by Ben Laurie and Peter Laurie (O'Reilly) covers everything about Apache, including sophisticated configuration issues.
Where the various files of an Apache installation go depends on your distribution or the package you installed, but the following is a common setup. You should locate the various pieces in your system before continuing:
- /usr/sbin/httpd
- The binary executable, which is the server itself. On Debian, this is /usr/sbin/apache instead.
- /etc/httpd
- Contains the configuration files for httpd, most notably httpd.conf. We discuss how to modify these files later. On Debian systems, this is /etc/apache instead of /etc/httpd.
- /usr/local/httpd
- Contains the HTML scripts to be served up to the site's clients. This directory and those below it, the web space, are accessible to anyone on the Web and therefore pose a severe security risk if used for anything other than public data.
- /var/log/httpd
- Holds log files stored by the server.
Our task now is to modify the configuration files in the configuration subdirectory. You should notice at least the following four files in this directory: access.conf-dist, httpd.conf-dist, mime.types, and srm.conf-dist. Copy the files with names ending in -dist and modify them for your own system. For example, access.conf-dist is copied to access.conf and edited.
The latest version of Apache pretty much configures itself, but in case things go wrong, we'll tell you here how to do it manually so that you can fix things yourself.
At http://www.apache.org, you will find complete documentation on how to configure httpd. Here, we'll present sample configuration files that correspond to an actual running httpd.
16.1.2.1. httpd.conf
The file httpd.conf is the main server-configuration file. First, copy httpd.conf-dist to httpd.conf and edit it. We'll only cover some of the more important options here; the file httpd.conf-dist is vastly commented.
The ServerType directive is used to specify how the server will run — either as a standalone daemon (as seen here) or from inetd. For various reasons, it's usually best to run httpd in standalone mode. Otherwise, inetd must spawn a new instance of httpd for each incoming connection.
One tricky item here is the port number specification. You may wish to run httpd as a user other than root (that is, you may not have root access on the machine in question and wish to run httpd as yourself). In this case, you must use a port numbered 1024 or above. For example, if we specify:
Port 2112
we may run httpd as a regular user. In this case, HTTP URLs to this machine must be specified as:
http://www.ecoveggie.org:2112/...
If no port number is given in the URL (as is the usual case), port 80 is assumed.
With:
DocumentRoot "/usr/local/httpd/htdocs"
we specify the DocumentRoot directive, where documents to be provided via HTTP are stored. These documents are written in HTML.
For example, if someone were to access the URL:
http://www.ecoveggie.org/fruits.html
the actual file accessed would be /usr/local/httpd/htdocs/fruits.html.
The UserDir directive specifies a directory each user may create in his home directory for storing public HTML files. For example, if we were to use the URL:
http://www.ecoveggie.org/~mdw/linux-info.html
the actual file accessed would be ~mdw/public_html/linux-info.html.
The following lines enable the indexing features of httpd.
# If a URL is received with a directory but no filename, retrieve this # file as the index (if it exists). DirectoryIndex index.html # Turn on 'fancy' directory indexes IndexOptions FancyIndexing
In this case, if a browser attempts to access a directory URL, the file index.html in that directory is returned, if it exists. Otherwise, httpd generates a "fancy" index with icons representing various file types. Figure 16-2 shows an example of such an index.
Icons are assigned using the AddIcon directive, as seen here:
# Set up various icons for use with fancy indexes, by filename # E.g., we use DocumentRoot/icons/movie.xbm for files ending # in .mpg and .qt AddIcon /icons/movie.xbm .mpg AddIcon /icons/back.xbm .. AddIcon /icons/menu.xbm ^^DIRECTORY^^ AddIcon /icons/blank.xbm ^^BLANKICON^^ DefaultIcon /icons/unknown.xbm
The icon filenames (such as /icons/movie.xbm) are relative to DocumentRoot by default. (There are other ways to specify pathnames to documents and icons — for example, by using aliases. This is discussed later.) There is also an AddIconByType directive, which lets you specify an icon for a document based on the document's MIME type, and an AddIconByEncoding directive, which lets you specify an icon for a document based on the document's encoding (i.e., whether and how it is compressed).
You can also specify an icon to be used when none of the above matches. This is done with the DefaultIcon directive.
The optional ReadmeName and HeaderName directives specify the names of files to be included in the index generated by httpd:
ReadmeName README HeaderName HEADER
Here, if the file README.html exists in the current directory, it will be appended to the index. The file README will be appended if README.html does not exist. Likewise, HEADER.html or HEADER will be included at the top of the index generated by httpd. You can use these files to describe the contents of a particular directory when an index is requested by the browser:
# Local access filename. AccessFileName .htaccess # Default MIME type for documents. DefaultType text/plain
The AccessFileName directive specifies the name of the local access file for each directory. (This is described later, along with the discussion about the access.conf file.) The DefaultType directive specifies the MIME type for documents not listed in mime.types.
The following lines specify directories for useful files.
# Set location of icons. Alias /icons/ /usr/local/html/icons/ # Set location of CGI binaries. ScriptAlias /cgi-bin/ /usr/local/httpd/cgi-bin/
The Alias directive specifies a pathname alias for any of the documents listed in srm.conf or accessed by a URL. Earlier, we used the AddIcon directive to set icon names using pathnames such as /icons/movie.xbm. Here, we specify that the pathname /icons/ should be translated to /usr/local/html/icons/. Therefore, the various icon files should be stored in the latter directory. You can use Alias to set aliases for other pathnames as well.
The ScriptAlias directive is similar in nature, but it sets the actual location of CGI scripts on the system. Here, we wish to store scripts in the directory /usr/local/httpd/cgi-bin/. Anytime a URL is used with a leading directory component of /cgi-bin/, it is translated into the actual directory name. More information on CGI and scripts is included in the book CGI Programming with Perl by Scott Guelich, Shishir Gundavaram, and Gunther Birznieks (O'Reilly).
<Directory> entries specify the options and attributes for a particular directory, as in:
# Set options for the cgi-bin script directory. <Directory /usr/local/html/cgi-bin> Options Indexes FollowSymLinks </Directory>
Here, we specify that the CGI script directory should have the access options Indexes and FollowSymLinks. A number of access options are available. These include:
- FollowSymLinks
- Symbolic links in this directory should be followed to retrieve the documents to which they point.
- ExecCGI
- Allow the execution of CGI scripts from this directory.
- Indexes
- Allow indexes to be generated from this directory.
- None
- Disable all options for this directory.
- All
- Enable all options for this directory.
There are other options as well; see the httpd documentation for details.
Next, we enable several options and other attributes for /usr/local/httpd/htdocs, the directory containing our HTML documents:
<Directory /usr/local/httpd/htdocs> Options Indexes FollowSymLinks # Allow the local access file, .htaccess, to override any attributes # listed here. AllowOverride All # Access restrictions for documents in this directory. <Limit GET> order allow,deny allow from all </Limit> </Directory>
Here, we turn on the Indexes and FollowSymLinks options for this directory. The AllowOverride option allows the local access file (named .htaccess) in each directory that contains documents to override any of the attributes given here. The .htaccess file has the same format as the global access.conf but applies only to the directory in which it is located. This way, we can specify attributes for particular directories by including a .htaccess file in those directories instead of listing the attributes in the global file.
The primary use for local access files is to allow individual users to set the access permissions for personal HTML directories (such as ~/public_html) without having to ask the system administrator to modify the global access file. Security issues are associated with this, however. For example, a user might enable access permissions in her own directory such that any browser can run expensive server-side CGI scripts. If you disable the AllowOverride feature, users cannot get around the access attributes specified in the global access.conf. This can be done by using:
AllowOverride None
which effectively disables local .htaccess files.
The <Limit GET> field is used to specify access rules for browsers attempting to retrieve documents from this server. In this case, we specify order allow,deny, which means that allow rules should be evaluated before deny rules. We then instate the rule allow from all, which simply means any host may retrieve documents from the server. If you wish to deny access from a particular machine or domain, you could add the line:
deny from .nuts.com biffnet.biffs-house.us
The first entry denies access from all sites in the nuts.com domain. The second denies access from the site biffnet.biffs-house.us.
16.1.2.2. srm.conf and access.conf
These files should be kept empty. In earlier Apache versions, srm.conf stood for Server Resource Map and listed facilities provided by the server, while access.conf controlled access to Apache files. All the resources originally placed in those files are now listed in the main httpd.conf file.
16.1.2.3. Starting httpd
Now you're ready to run httpd, allowing your machine to service HTTP URLs. As mentioned previously, you can run httpd from inetd or as a standalone server. Here, we describe how to run httpd in standalone mode.
All that's required to start httpd is to run the command:
httpd -f configuration-file
where configuration-file is the pathname of httpd.conf. For example:
/usr/sbin/httpd -f /etc/httpd/httpd.conf
starts up httpd, with configuration files found in /etc/httpd.
Watch the httpd error logs (the location of which is given in httpd.conf) for any errors that might occur when trying to start up the server or when accessing documents. Remember you must run httpd as root if it is to use a port numbered 1023 or less. Once you have httpd working to your satisfaction, you can start it automatically at boot time by including the appropriate httpd command line in one of your system rc files, such as /etc/init.d/boot.local.
Some releases of Apache also provide a utility called apachectl that controls the starting, stopping, reloading, and so on of the httpd process. Particularly, calling:
apachectl configtest
is a good way of checking whether the configuration file is actually correct before starting the server. Finally, we should mention that you can also start, restart, and stop Apache by using /etc/init.d/apache plus one of the parameters start, restart, or stop.
Of course, in order to request documents via HTTP from your browser, you'll need to write them, something that we cannot cover in this book. Two good sources for HTML information are the O'Reilly books HTML & XML — The Definitive Guide by Chuck Musciano and Bill Kennedy and HTML Pocket Reference by Jennifer Niederst. A special kind of web page, that which is filled with data from a database, is also covered in Chapter 18 of this book.
|  | |
| 15.5. NFS and NIS Configuration |  | 16.2. Electronic Mail |

Copyright © 2003 O'Reilly & Associates. All rights reserved.