 |  |
Chapter 8. Database Applications
We have spent the entire book so far discussing the database as if it exists in some sort of vacuum. But it serves its purpose only when being used by other applications. We should therefore take a look at how the database relates to the other elements of a database application before exploring the details of database application development in various languages. This detour examines conceptual issues important not only to programming with MySQL, but to programming with any relational database engine. Our look at database programming covers such complex issues as understanding the basic architectures common to web-oriented database applications and how to map complex programming models into a relational database.
8.1. Architecture
Architecture describes how the different components of a complex application relate to one another. A simple web application using Perl to generate dynamic content has the architecture shown in Figure 8-1. This architecture describes four components: the web browser, the web server, the Perl CGI engine, and the MySQL database.

Figure 8-1. The architecture of a simple web application
Architecture is the starting point for the design of any application. It helps identify at a high level all of the relevant technologies and the standards those technologies will use to integrate. In the web architecture, for example, the web browser talks to the server using HTTP.
As we will cover in the later chapters of this section, MySQL exposes itself through a variety of APIs tailored to specific programming languages. Java applications access MySQL through JDBC, Python applications through the Python DB-API, etc.
There are numerous architectures used in database applications. In this chapter, we will cover the three most common architectures: client/server, distributed, and web. Though one could argue that they are all variations on a theme, they do represent three very different philosophical approaches to building database applications.
8.1.1. Client/Server Architecture
At its simplest, the client/server architecture is about dividing up application processing into two or more logically distinct pieces. The database makes up half of the client/server architecture. The database is the "server"; any application that uses that data is a "client." In many cases, the client and server reside on separate machines; in most cases, the client application is some sort of user-friendly interface to the database. Figure 8-2 provides a graphical representation of a simple client/server system.

Figure 8-2. The client/server architecture
You have probably seen this sort of architecture all over the Internet. The Web, for example, is a giant client/server application in which the web browser is the client and the web server is the server. In this scenario, the server is not a relational database server, but instead a specialized file server. The essential quality of a server is that it serves data in some format to a client.
8.1.1.1. Application logic
Because a client/server architecture specifically separates out components for UI and data processing, actual application processing is left up to the programmer to integrate. In other words, a client/server architecture does not provide an obvious place for a banking application to do interest calculations. Some client/server applications place this kind of processing in the database in the form of stored procedures; others put it in the client with the UI controls. There is no general solution.
Under MySQL, the current method is to put the processing in the client because of the lack of stored procedure support in MySQL. Stored procedures are on the MySQL to-do list, and—perhaps even by the time you read this book—stored procedures will eventually be a viable place for application logic in a client/server configuration. Whether or not MySQL has stored procedures, however, MySQL is rarely used in a client/server environment. It is instead much more likely to be used with the web architecture we will describe later in this chapter.
8.1.1.2. Fat and thin clients
There used to be two kinds of clients: fat clients and thin clients. A fat client included application processing; a thin client simply had user interface (UI) logic. With the advent of web applications, we now have the term ultra-thin to add to the list. An ultra-thin client has only display logic. Controller logic (what happens when you press "Submit") happens elsewhere. In short, an ultra-thin client might be a web form.
The advantage of an ultra-thin client is it makes real the concept of a ubiquitous client. As long as you can describe the application layout to a client using some sort of markup language, the client can paint the UI for a user without the programmer needing to know the details of the underlying platform. When the UI needs to respond to a user action, it sends information about the action to another component in the architecture to respond to the action. Client/server architecture, of course, has no such component.
8.1.2. Distributed Application Architecture
The distributed application architecture provides a place where application logic is supposed to occur. Figure 8-3 shows the layout of an application under the distributed application architecture.
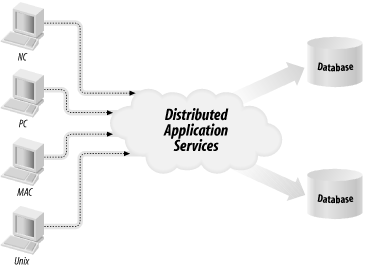
Figure 8-3. The distributed application architecture
As you can see, this architecture is basically the client/server architecture with a special place for application logic—the middle tier. This small difference, however, represents a major philosophical shift from the client/server design. It says, in short, that it is important to separate application logic from other kinds of logic.
In fact, placing application logic in the database or in the UI hinders your application's ability to grow with changing demands. If, for example, you need a simple change to your data model, you will have to make significant changes to your stored procedures if your application logic is in the database. A change to application logic in the UI, on the other hand, forces you to touch the UI code as well and thus risk adding bugs to systems that have nothing to do with the changes you are introducing.
The distributed application architecture does two things. It provides a home for application processing so that it does not get mixed in with database or UI code. However, it also makes the UI independent of the underlying data model. Under this architecture, changes to the data model affect only how the middle tier gets data from and puts data into the database. The client has no knowledge of this logic and thus does not care about such changes.
The distributed application architecture introduces two truly critical elements. First of all, the application logic tier enables the reuse of application logic by multiple clients. Specifically, by abstracting out the application logic with well-defined integration points, it is possible to reuse that logic with UIs not conceived when the application logic was written.
The second, not so obvious thing this architecture offers applications is the ability to provide easy support for failover and scalability. The components in this architecture are logical components, meaning that they can be spread out across multiple actual instances. When a database or an application server introduces clustering, it can act and behave as a single tier while spreading processing across multiple physical machines. If one of those machines goes down, the middle tier itself is still up and running.
8.1.3. Web Architecture
The web architecture is another step in evolution that appears to be only slightly different from the distributed application architecture. It makes a true ultra-thin client possible by providing only display information in the form of HTML to a client. All controller logic occurs in a new component, the web server. Figure 8-4 illustrates the web architecture.
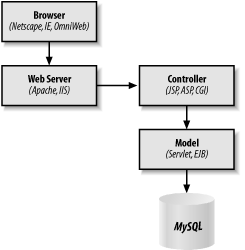
Figure 8-4. The web application architecture
The controller comes in many different forms, depending on the technologies you are using. PHP, CGI, JSP, ASP, ColdFusion, and WebObjects are all examples of technologies for processing user events. Some of these technologies even divide things further into content creation and controller logic. If you use a content management system such as OpenMarket, for example, your JSP is nothing more than a tool for dynamically building your HTML. The actual controller logic is passed off to a servlet action handler that performs any application server interaction.
The focus of this book will be the web architecture since it is the most common architecture in which MySQL is used. We will use both the vision of the web architecture shown in Figure 8-4 and a simpler one in which the application logic is embedded with controller logic in the web server. The simpler architecture is mostly relevant to MySQL applications since MySQL performs best for heavy read applications—applications without complex application logic.
|  | |
| III. MySQL Programming |  | 8.2. Connections and Transactions |

Copyright © 2003 O'Reilly & Associates. All rights reserved.