
6.5. Indexing the Right Stuff
So, let's get back to whether you need a search engine. Let's assume that you do intend to slap a search engine on top of your web site. Shouldn't be a problem right? Just point the indexer at the directory where all the pages live, and, voilà! Searchable site!
Of course, you knew it wasn't that simple. Searching only works well when the stuff that's being searched is the same as the stuff that users want. This means you may not want to index the entire site. We'll explain.
6.5.1. Indexing the Entire Site
Search engines are frequently used to index an entire site without regard for the content and how it might vary -- every word of every page, whether it contains real content or help information, advertising, navigation menus, and so on.
However, searching works much better when the information space is defined narrowly and contains homogeneous content. In other words, the more you search through indices that combine apples and oranges, the worse your retrieval results will be. After all, when you search a site, you're probably looking for apples only, not oranges. As already discussed, a site's content is usually a mix of apples, oranges, kumquats, bell peppers, chainsaws, and Barbie dolls to begin with. So, when you tell your search engine to index your entire site, the site's users will be performing searches against all kinds of stuff -- navigation, destination, and other kinds of pages -- all at once. What they retrieve can often be ugly.
Let's try an example to see what happens. Searching Netscape's site for plug-ins, what do we find? Exactly 100 documents.[16] Of these:
[16] Search done on February 2, 1997.
58 documents are Welcome to Netscape Navigator version X.X pages for just about every version of Netscape Navigator and include information about plug-ins.
16 documents are in German (a language I don't read).
6 documents contain the potentially relevant term application in their titles, but 5 of these 6 have exactly the same title (Netscape Handbook: Application Features).
2 documents actually contain plug-in in their titles.
18 other assorted documents may be relevant, but are not labeled in a way that indicates whether this is the case.
Analyzing these search results, we find two common problems. First, we are presented with documents that clearly don't belong. If the site had been selectively indexed with audience differences in mind, 16% of the results would not have been displayed at all. Second, regarding relevant documents, it's not clear why we need 58 versions of the same type of document. It would have been useful to index pages more selectively, such as files relevant to Windows or Macintosh users, or recent versions versus older versions of the software. Are very many people still interested in old Netscape Beta versions? So, our search is less successful than it could have been; it gave us a lot of irrelevant documents, and too many that could be relevant.
Our search performed poorly because all the content in the site was indexed together. By doing so, the site's architects chose to ignore two very important things: that the information in their site isn't all the same, and that it makes good sense to respect the lines already drawn between different types of content. For example, it's clear that German and English content are vastly different and that their audiences overlap very little (if at all), so why not create separately searchable indices along those divisions?
The site designers at Netscape are already doing this, in a limited way. They have put a lot of effort into helping you download the right version of the software from the nearest location. To download the software, you get asked several questions (not unlike those in a reference interview). Shown in Figure 6-15, the site asks the user:
What operating system does your computer use?
What language do you speak?
Which of our products do you need?
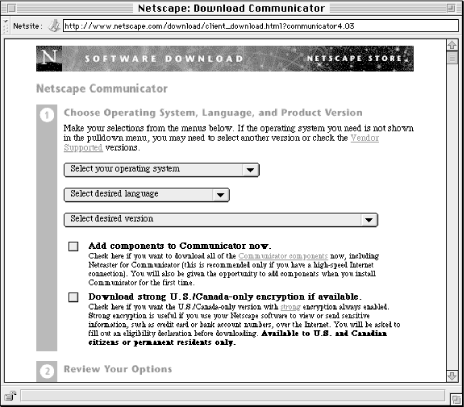
Figure 6-15. Three pull-down menus perform a brief reference interview sufficient to help users download the appropriate software product.
The result is a list of links to download sites that provide the user the right information (i.e., software appropriate to the user's platform), taking into account his or her geographic location and language. Why not apply this same careful approach to matching users with the right information to the entire site, instead of just to this specific situation?
6.5.2. Search Zones: Selectively Indexing the Right Content
Search zones are subsets of a web site that have been indexed separately from the rest of the site's content. When you search a search zone, you have, through interaction with the site, already identified yourself as a member of a particular audience or as someone searching for a particular type of information. The search zones in a site match those specific needs, and the result is improved retrieval performance. The user is simply less likely to retrieve irrelevant information.
The Microsoft site has a good example of search zone use. Although this site suffers from other searching problems, it compares favorably to the Netscape site when searching for our old stand-by, plug-ins. On the search page you're asked where you want to search in the Microsoft site, and are provided with the options on a pull-down menu (Figure 6-16).
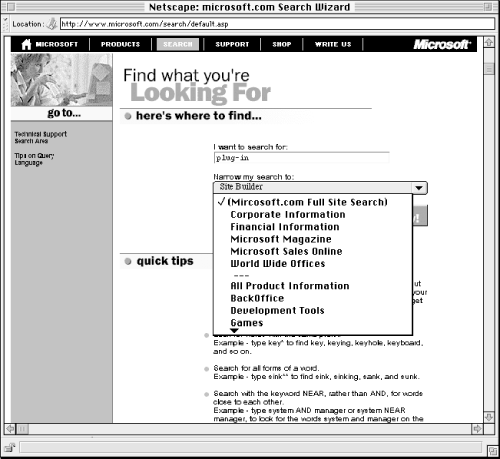
Figure 6-16. Microsoft's site employs search zones to help focus the user's search before submitting a query to the search engine.
You've got many options to review, but you can quickly find the Internet Explorer area of the site where you'd want to look for plug-ins. Consider how well the effort the user expends in reviewing and selecting from this menu compares to the much greater effort of searching the entire site and then sifting through a tremendously larger retrieval set. Also note the Full Site Search option; sometimes it does make sense to maintain an index of the entire site, especially for users who are unsure where to look, who are doing a comprehensive leave-no-stones-unturned search, or who just haven't had any luck searching the more narrowly defined indices.
How is search zone indexing set up? It depends on the search engine software used. Most support the creation of search zones, but some provide interfaces that make this process easier, while others require you to manually provide a list of pages to index. In either case, search zone indexing requires more work on your part than simply pointing the search engine at the entire site: you'll need to review and mark each page that should be indexed. To make this easier, you might design your site so that pages that should be indexed together are located in the same directory; that way, you would mark for indexing a directory (and, implicitly, its contents) instead of its individual pages. You may also be working with pages that are generated from a database. In this case, you could design the database to include a field for each record denoting which index the generated page should belong to.
You can create search zones in many ways. Examples of four common approaches are:
by content type
by audience
by subject
by date
Note that these approaches are similar to the organization schemes discussed in Chapter 3, "Organizing Information". The decisions you made in selecting your site's organization scheme will often work for determining search zones as well. You could also try other ways; the most important consideration is to choose an approach appropriate to your site's audiences and their information needs.
6.5.2.1. Apples and apples: indexing similar content types
Most web sites contain, at minimum, two major and dissimilar types of pages: navigation and destination. Destination pages contain the actual information you want from a web site: sport scores, book reviews, software documentation, and so on. The primary purpose of a site's navigation pages is to get you to the destination pages. Navigation pages may include main pages, search pages, and pages that help you browse a site.
When a user searches a site, he or she is generally looking for destination pages. If navigation pages are part of the retrieval, they will just clutter up the retrieval results. In fact, the reason that the user is searching rather than browsing some other way could be because the navigation system is performing poorly in the first place. So why keep showing the user navigation pages that don't work and aren't relevant to the search?
Let's take a simple example: your company sells computer products via its web site. The destination pages consist of descriptions, pricing, and ordering information, one page for each product. Also, a number of navigation pages help users find products, such as listings of products for different platforms (e.g., Macintosh versus Windows), listings of products for different applications (e.g., word processing, bookkeeping), listings of business versus home products, and listings of hardware versus software products. If the user is searching for Intuit's Quicken, what's likely to happen? Instead of simply retrieving Quicken's product page, they might get all these pages:
Financial Products Index Page
Home Products Index Page
Macintosh Products Index Page
Quicken Product Page
Software Products Index Page
Windows Products Index Page
The user retrieves the right destination page (i.e., the Quicken Product Page), but also five more that are purely navigation pages. In other words, 83% of the retrieval is in the way. And keep in mind that this example is simple; what if the user had to ignore 83% of a much larger retrieval set, say, 200 documents?
Of course, indexing similar content isn't always easy, because "similar" is a highly relative term. It's not always clear where to draw the line between navigation and destination pages. In some cases, a page can be considered both. For example, we tried the approach described here for the SIGGRAPH 96 Conference web site.[17] We found that some pages didn't really fit the navigation/destination breakdown. For example, the Exhibition Hall Map page appears to be navigation. It links to pages for each of the five sections of the hall. These five pages appear to be destination, presenting detailed maps of their respective sections, including booth numbers and the names of exhibitors. But their parent page also provides important information, such as where the hall entrances are, and where the five sections are in relation to one another. So isn't the main Exhibition Hall Map page destination as well as navigation? The best solution, in this particular case, was to index these hybrid pages, but it wasn't ideal.
[17]This site evolved greatly during the year leading up to SIGGRAPH 96, and then some after the conference was complete. The fullest version of this site is archived at http://siggraph.anecdote.com/conferences/siggraph96.
The more important lesson from this experience was to test out the navigation/destination distinctions before actually applying them. The weakness of the navigation/destination approach is that it is essentially an exact organization scheme (discussed in Chapter 3, "Organizing Information") which requires the pages to be either one thing (in this case destination) or another (navigation). In the following three approaches, the organization approaches are ambiguous, and therefore more forgiving of pages that fit into multiple categories.
6.5.2.2. Who's going to care? Indexing for specific audiences
If you've already decided to create an architecture for your site that uses an audience-oriented organization scheme, it may make sense to create search zones by audience breakdown as well. We found this a useful approach for the original Library of Michigan web site.
The Library of Michigan has three primary audiences: members of the Michigan state legislature and their staffs, Michigan libraries and their librarians, and the citizens of Michigan. The information needed from this site is different for each of these audiences; for example, each has a very different circulation policy. Why would a state legislator care how long a citizen can check a book out for?
So we created four indices: one for the content relevant to each audience, and one unified index of the entire site in case the audience-specific indices didn't do the trick for a particular search. Here are the results from running a query on the word circulation against each of the four indices:
|
Index |
Number of Documents Retrieved |
Retrieval Reduced By |
|---|---|---|
|
Unified |
40 |
- |
|
Legislature Area |
18 |
55% |
|
Libraries Area |
24 |
40% |
|
Citizens Area |
9 |
78% |
As with any search zone, less overlap between indices improves performance. If the sizes of retrieval results were reduced by a very small figure, let's say, 10% or 20%, it may not be worth the overhead of creating separate audience-oriented indices. But in this case, much of the site's content is specific to one of the audiences.
6.5.2.3. Drilling down: Indexing by subject
If your site uses a strong subject-oriented or topical organization scheme, you've already distinguished many of the site's search zones. Yahoo! is perhaps the most popular site to employ subject-oriented search zones. Every subject category and subcategory in Yahoo! can be searched individually. For example, let's say you're looking for sites that deal with science fiction movies. If you search for science fiction against the whole Yahoo! search index, you'll retrieve a lot of stuff: 35 category and subcategory matches and 816 site matches. But you're not looking for science fiction in general; you're looking for science fiction movies. So, instead you can run the same science fiction search against the index for the Yahoo! subcategory Movies and Films. This time you'll be happier with your retrieval: 2 category and subcategory matches and 19 site matches. This is another excellent example of how hierarchical search zones allow for increased specificity, and therefore improved retrieval results.
6.5.2.4. Yesterday's news: Indexing recent content
Chronologically organized content allows for perhaps the easiest implementation of search zones. (Not surprisingly, it's probably the most common example of search zones.) Because dated materials are generally not ambiguous, indexing them by date is staightforward.
News.Com is a great example (Figure 6-17); it supports highly flexible chronological searching by:
Date Range (e.g., from 5/20/97 to 6/26/97)
3 Days Back
7 Days Back
14 Days Back
21 Days Back
30 Days Back
60 Days Back
90 Days Back
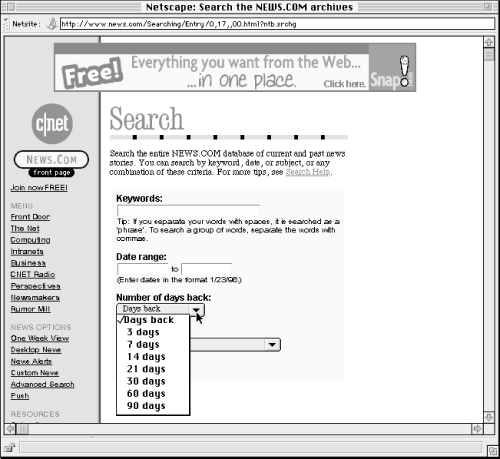
Figure 6-17. News.com's search interface uses two components (Date range and Number of days back) to allow for powerful chronological searching.
Regular users can return to the site and check up on the news depending on how regularly they use the site (e.g., every week, two weeks, three weeks). Users who are looking for news during a particular date range can essentially generate a custom search zone on the fly. The only negative in News.Com's implementation is that they don't seem to support a search against all news articles, regardless of age.[18]
[18]There does seem to be a work-around to this problem: leave the pull-down menu on the default setting of Days back, and the resulting retrieval seems larger than 90 days. But this is simply a guess...
 |  |  |
| 6.4. In an Ideal World: The Reference Interview |  | 6.6. To Search or Not To Search? |

Copyright © 2002 O'Reilly & Associates. All rights reserved.