
5.4. Creating Effective Labeling Systems
Successful labeling systems mirror the thinking and language of a site's users, not its owners. If you've done your homework and created a sound organizational system for your site, the labeling system should follow its lead. So, for example, the labeling system should be topical if the organization system is topical. But once you've established a general approach (e.g., topical, task-oriented), where should the actual labels, the words themselves, come from?
5.4.1. Sources for Labeling Systems
5.4.1.1. The labels currently in place
Your web site already has labels by default. As you made some decisions during the course of the site's creation, you probably won't want to throw those labels out and start over. Instead, use them as a starting point for developing a complete labeling system, taking into consideration the decisions you made while creating the original system (if you can still remember them).
Capture the existing labels in a single document. To do so, you'll have to walk the entire site, either manually or automatically, to gather the labels. You might consider assembling them as a simple label table. Here's an example:
|
Page Title (rendered as a graphic at top of page) |
Page Title (rendered with <TITLE> tags) |
URL |
Headings on Page |
|---|---|---|---|
|
Argus Associates, Inc. |
Argus Associates, Inc. |
|
|
|
Who We Are |
The Argus Team |
|
|
|
What We Do |
Web Site Design |
|
|
|
Clients |
Argus Clients |
|
|
|
Contact Argus |
Contacting Argus |
(none) |
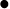 Who We Are.
Who We Are.This label table is short because the site is small. Arranging these labels in a condensed form provides a more accurate and complete view as a system than if you looked at each label within the site page by page. Inconsistencies are easier to catch; for example, we learned that we were using three different labels for the same content (e.g., What We Do vs. What We Do. vs. Web Site Design, and Contact Argus. vs. Contact Argus vs. Contacting Argus). As you can see, both the wording and the use of periods was inconsistent, and possibly confusing. Shame on us! This proves the point that it's easy to create inconsistent labels even within a relatively small site.
5.4.1.2. Other web sites
If you don't have a site in place or are looking for new ideas, you'll want to look elsewhere for labeling systems. The open nature of the Web encourages an atmosphere of benevolent plagiarism, so, just as you might view the source of a wonderfully designed page, you can "borrow" from another site's great labeling system. Make sure you're in top critical consumer mode to ensure that your audiences' needs are well-represented. Then surf your competitors' sites, borrowing what works and noting what doesn't. Also look at academic sites that deal with your site's subject; colleges and universities often have the luxury of retaining label-happy librarians on their staffs to assist in site creation.
5.4.1.3. Controlled vocabularies and thesauri
If you're feeling more ambitious, other places have labeling systems from which to borrow. Controlled vocabularies and thesauri are often useful sources created by professionals with library or subject-specific backgrounds. A controlled vocabulary is simply a list of predetermined terms that describe a topic, such as art or computer science. They are controlled in that you must use the vocabulary's terms for a topic, and not an alternative term. A common example is the set of categories found in any yellow pages directory. When you're looking for movies or cinemas, you'll find them listed under "Theatres-Cinema" and nowhere else (why the Ann Arbor area directory uses the British spelling for "theaters" is beyond us).
A thesaurus is a controlled vocabulary that includes relationships between those terms, including:
"See" or "Use" terms: Some thesauri include common terms that aren't part of the controlled vocabulary, with a reference to the appropriate controlled term to use. So, in Figure 5-7, if you're looking for the term Draft, you're instructed to use Compulsory military service instead.
"See Also" or "Related" terms: These relationships help you find other terms that might be of interest; in Figure 5-8, the term Domestic politics and foreign policy is related to Bipartisan foreign policy, Congress and foreign policy, and so on.
"Broader" or "Parent" terms: If a term is too specific (i.e., its level of granularity is too fine), you might look to see what topic it is a part of. In Figure 5-8, Domestic politics and foreign policy is part of the broader area of foreign relations.
"Narrower" or "Child" terms: Conversely, a narrower term may provide the level of specificity you need. Dog is a narrower term of Mammal.

Figure 5-7. A subsection of the LIV (Legislative Indexing Vocabulary) thesaurus. Note that some terms are not considered part of the controlled vocabulary; instead, they refer you to a similar term that is part of the controlled vocabulary (e.g., for the uncontrolled term Draft, use Compulsory military service).
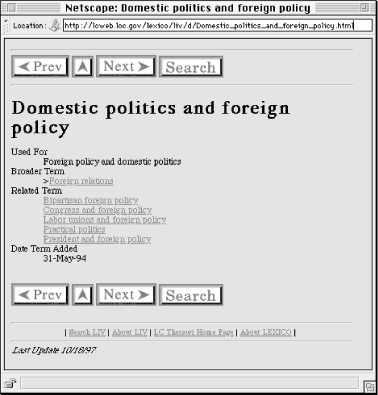
Figure 5-8. The value of a thesaurus is in the relationships it specifies between terms: selecting a term in the controlled vocabulary (e.g., Domestic politics and foreign policy) displays a broader term, related terms, and a similar term (Used For) that is not part of this controlled vocabulary.
These additional relationships can be useful for determining the labeling of the different levels of your site. If you've ever used a library catalog, you are already familiar with a thesaurus: the subject keywords associated with each book come from the Library of Congress Subject Headings (LCSH).
You can use and adapt terms from controlled vocabularies and thesauri, but remember: the more narrow and specific the vocabulary or thesaurus, the better its terms will perform for your site. The LCSH is a thesaurus of terms intended to describe the whole universe of knowledge. This is an expansive and expensive task, and it's hard to keep up with all the changes going on in the world; LCSH still includes arcane terms like water closet. LCSH may often be out-of-date and is designed to be all things to all people; therefore, its terms may not be the best fit for your site, which probably doesn't deal with all aspects of human knowledge.
Instead, seek out vocabularies that are more narrowly focused and that help specific audiences to access specific types of content. For example, if your site's users are computer scientists, a computer science thesaurus "thinks" the same way the users do more than a general scheme like LCSH would. A good example of a specific controlled vocabulary is the Legislative Indexing Vocabulary (LIV), available at http://lcweb.loc.gov/lexico/liv/brsearch.html, which was designed by the Congressional Research Service to help users search in the Bill Summary & Status files of THOMAS, the Library of Congress' web site for federal legislative information. If your site contains legislative information, or if your site's audience are legislative types, you might start with LIV as the basis of your site's labeling system.
5.4.1.4. Labels from content
Labels can come from the documents themselves. For example, if your site includes a number of technical reports created by a host of different authors, you can use the document's titles as part of an alphabetically sorted labeling system. Or, if you're creating a subject-oriented labeling system, you can learn a lot about these documents from the terms used in their titles and from their abstracts, if available. Perhaps you'll even read the reports themselves and come up with some terms that describe their content.
If you do use terms directly from the documents, be careful! A common (and wrong) assumption is that a document's author is the best candidate to label its content. For example, Gone With the Wind makes for an enticing title as we're sure Margaret Mitchell intended, but as a label it doesn't work at all. It has nothing to do with wind itself. Even if she had selected a representational title for her book, Ms. Mitchell wasn't concerned with how her book's title fit in with the titles of other books and how well the title would support users who were searching for it in an information system. If authors did have such concerns, they might select their titles from thesauri like Library of Congress Subject Headings! For various reasons (artistic, marketing-related, and more), authors' motives when they label their content may have absolutely nothing to do with ensuring that their information gets found. That's why it makes sense for someone else to take a close look at what's being labeled instead of relying upon the source to label the information accurately.
5.4.1.5. Labels from users and experts
Lastly, the users of a site may be telling you, directly or indirectly, what the labels should be. This isn't the easiest information to get your hands on, but if you can, it's the best source of labeling there is.
It would be great to simply ask them what terms they use, but this wouldn't be very practical. There is a less-intrusive source of useful information on what labels your site's audiences actually use: your search engine's query log (most search engines do log user queries). Query analysis is a great way to understand the types of labels your site's users typically use (see Figures Figure 5-9 and Figure 5-10). Besides shedding some light on user searching behavior, query analysis can also help you understand the content users are specifically asking for from your site. In the case of search queries that retrieve no results, consider these terms as candidates for inclusion in your labeling system, or consider adding relevant content to your site so that queries using these terms actually retrieve something in the future.
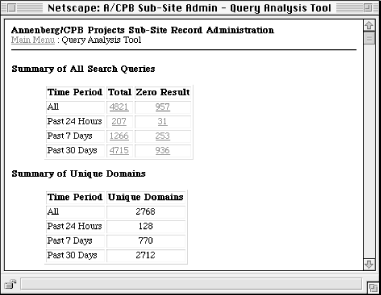
Figure 5-9. Among other things, this custom-designed query analysis tool shows how many searches took place in total, as well as how many of those searches retrieved no results at all. It was developed by InterConnect of Ann Arbor.
Figure 5-10. Here the same query analysis tool helps us to view specific queries, how many results they retrieved, where they came from, and when they took place. The third through eighth came from the same IP address, and all took place within four minutes; this suggests that they were part of the same session by the same user.
Another less technical approach is to determine if there are any advanced users or experts, such as librarians, switchboard operators, or other information specialists who are very familiar with the users' information needs, and who could therefore speak on the users' behalf.
We found this to be a useful exercise with one of our clients, a major health system. Working with their library staff, we set out to create two labeling systems, one with medical terms to help medical professionals browse the services offered by the health system, the other for the lay audience to access the same content. It wasn't difficult to come up with the medical terms, as there are many thesauri and controlled vocabularies geared toward labeling medical content. It was much more difficult to come up with a scheme for the layperson's list of terms. There didn't seem to be an ideal controlled vocabulary, and we couldn't draw labels from the site's content very easily, as it hadn't been created yet. So we were truly starting from scratch.
We solved this dilemma by asking ourselves what the users really wanted out of the site. We considered their general needs, and came up with a few major ones:
They need information about or a solution for a problem, illness, or condition.
The problem is with a particular organ or part of the body.
They want to know about the diagnostics or tests the health care professionals will perform to learn more about the problem.
They need information on the treatment, drug, or solution that will be provided by the health system.
They want to know how they can pay for the service.
They want to know how they can maintain their health.
We then could come up with basic terms to cover the majority of these six categories, taking care to use terms appropriate to this audience of laypersons. Here are some examples:
|
Category |
Sample Labels |
|---|---|
|
problem/illness/condition |
HIV, fracture, arthritis, depression |
|
organ/body part |
heart, joints, mental health |
|
diagnostics/test |
blood pressure, X-ray |
|
treatment/drug/solution |
hospice, bifocals, joint replacement |
|
payment |
administrative services, health maintenance organization, medical records |
|
health maintenance |
exercise, vaccination |
By starting with a few groupings, we were able to generate labels to support indexing the site. We knew a bit about the audience (who were laypersons), and so were able to generate the right kinds of terms to support their needs (e.g., leg instead of femur). The secret was working with people (in this case, staff librarians) who were knowledgeable about the kind of information the users want.
 |  |  |
| 5.3. Types of Labeling Systems |  | 5.5. Fine-Tuning the Labeling System |

Copyright © 2002 O'Reilly & Associates. All rights reserved.