
 |  |
Chapter 6. Advanced sed Commands
Contents:
Multiline Pattern Space
A Case for Study
Hold That Line
Advanced Flow Control Commands
To Join a Phrase
In this chapter, we cover the remaining sed commands. These commands require more determination to master and are more difficult to learn from the standard documentation than any of the basic commands. You can consider yourself a true sed-master once you understand the commands presented here.
The advanced commands fall into three groupings:
Working with a multiline pattern space (N,D,P).
Using the hold space to preserve the contents of the pattern space and make it available for subsequent commands (H,h,G,g,x).
Writing scripts that use branching and conditional instructions to change the flow of control (:,b,t).
If the advanced scripts in this chapter have one thing in common, it is that they alter the sequential flow of execution or control. Normally, a line is read into the pattern space and each command in the script, one right after the other, is applied to that line. When the bottom of the script is reached, the line is output and the pattern space is cleared. Then a new line is read into the pattern space and control passes back to the top of the script. That is the normal flow of control in a sed script.
The scripts in this chapter interrupt or break the normal flow of control for various reasons. They might want to prevent commands in the script from executing except under certain circumstances, or to prevent the contents of the pattern space from being cleared out. Altering the flow of control makes a script much more difficult to read and understand. In fact, the scripts may be easier to write than they are to read. When you are writing a difficult script, you have the benefit of testing it to see how and why commands work.
We'd recommend that you test the scripts presented in this chapter and experiment by adding or removing commands to understand how the script is working. Seeing the results for yourself will help you understand the script much better than simply reading about it.
6.1. Multiline Pattern Space
We have emphasized in previous discussions of regular expressions that pattern matching is line-oriented. A program like grep attempts to match a pattern on a single line of input. This makes it difficult to match a phrase, for instance, which can start at the end of one line and finish at the beginning of the next line. Other patterns might be significant only when repeated on multiple lines.
Sed has the ability to look at more than one line in the pattern space. This allows you to match patterns that extend over multiple lines. In this section, we will look at commands that create a multiline pattern space and manipulate its contents. The three multiline commands (N,D,P) all correspond to lowercase basic commands (n,d,p) that were presented in the previous chapter. The Delete (D) command, for instance, is a multiline version of the delete command (d). The difference is that while d deletes the contents of the pattern space, D deletes only the first line of a multiline pattern space.
6.1.1. Append Next Line
The multiline Next (N) command creates a multiline pattern space by reading a new line of input and appending it to the contents of the pattern space. The original contents of pattern space and the new input line are separated by a newline. The embedded newline character can be matched in patterns by the escape sequence "\n". In a multiline pattern space, the metacharacter "^" matches the very first character of the pattern space, and not the character(s) following any embedded newline(s). Similarly, "$" matches only the final newline in the pattern space, and not any embedded newline(s). After the Next command is executed, control is then passed to subsequent commands in the script.
The Next command differs from the next command, which outputs the contents of the pattern space and then reads a new line of input. The next command does not create a multiline pattern space.
For our first example, let's suppose that we wanted to change "Owner and Operator Guide" to "Installation Guide" but we found that it appears in the file on two lines, splitting between "Operator" and "Guide."
For instance, here are a few lines of sample text:
Consult Section 3.1 in the Owner and Operator Guide for a description of the tape drives available on your system.
The following script looks for "Operator" at the end of a line, reads the next line of input and then makes the replacement.
/Operator$/{
N
s/Owner and Operator\nGuide/Installation Guide/
}In this example, we know where the two lines split and where to specify the embedded newline. When the script is run on the sample file, it produces the two lines of output, one of which combines the first and second lines and is too long to show here. This happens because the substitute command matches the embedded newline but does not replace it. Unfortunately, you cannot use "\n" to insert a newline in the replacement string. You must use a backslash to escape the newline, as follows:
s/Owner and Operator\nGuide /Installation Guide\ /
This command restores the newline after "Installation Guide". It is also necessary to match a space following "Guide" so the new line won't begin with a space. Now we can show the output:
Consult Section 3.1 in the Installation Guide for a description of the tape drives available on your system.
Remember, you don't have to replace the newline but if you don't it can make for some long lines.
What if there are other occurrences of "Owner and Operator Guide" that break over multiple lines in different places? You could modify the regular expression to look for a space or a newline between words, as shown below:
/Owner/{
N
s/Owner *\n*and *\n*Operator *\n*Guide/Installation Guide/
}The asterisk indicates that the space or newline is optional. This seems like hard work, though, and indeed there is a more general way. We have also changed the address to match "Owner," the first word in the pattern instead of the last. We can read the newline into the pattern space and then use a substitute command to remove the embedded newline, wherever it is.
s/Owner and Operator Guide/Installation Guide/
/Owner/{
N
s/ *\n/ /
s/Owner and Operator Guide */Installation Guide\
/
}The first line matches "Owner and Operator Guide" when it appears on a line by itself. (See the discussion after the example about why this is necessary.) If we match the string "Owner," we read the next line into the pattern space, and replace the embedded newline with a space. Then we attempt to match the whole pattern and make the replacement followed by a newline. This script will match "Owner and Operator Guide" regardless of how it is broken across two lines. Here's our expanded test file:
Consult Section 3.1 in the Owner and Operator Guide for a description of the tape drives available on your system. Look in the Owner and Operator Guide shipped with your system. Two manuals are provided including the Owner and Operator Guide and the User Guide. The Owner and Operator Guide is shipped with your system.
Running the above script on the sample file produces the following result:
$ sed -f sedscr sample Consult Section 3.1 in the Installation Guide for a description of the tape drives available on your system. Look in the Installation Guide shipped with your system. Two manuals are provided including the Installation Guide and the User Guide. The Installation Guide is shipped with your system.
In this sample script, it might seem redundant to have two substitute commands that match the pattern. The first one matches it when the pattern is found already on one line and the second matches the pattern after two lines have been read into the pattern space. Why the first command is necessary is perhaps best demonstrated by removing that command from the script and running it on the sample file:
$ sed -f sedscr2 sample Consult Section 3.1 in the Installation Guide for a description of the tape drives available on your system. Look in the Installation Guide shipped with your system. Two manuals are provided including the Installation Guide and the User Guide.
Do you see the two problems? The most obvious problem is that the last line did not print. The last line matches "Owner" and when N is executed, there is not another input line to read, so sed quits (immediately, without even outputting the line). To fix this, the Next command should be used as follows to be safe:
$!N
It excludes the last line ($) from the Next command. As it is in our script, by matching "Owner and Operator Guide" on the last line, we avoid matching "Owner" and applying the N command. However, if the word "Owner" appeared on the last line we'd have the same problem unless we use the "$!N" syntax.
The second problem is a little less conspicuous. It has to do with the occurrence of "Owner and Operator Guide" in the second paragraph. In the input file, it is found on a line by itself:
Look in the Owner and Operator Guide shipped with your system.
In the output shown above, the blank line following "shipped with your system." is missing. The reason for this is that this line matches "Owner" and the next line, a blank line, is appended to the pattern space. The substitute command removes the embedded newline and the blank line has in effect vanished. (If the line were not blank, the newline would still be removed but the text would appear on the same line with "shipped with your system.") The best solution seems to be to avoid reading the next line when the pattern can be matched on one line. So, that is why the first instruction attempts to match the case where the string appears all on one line.
6.1.1.1. Converting an Interleaf file
FrameMaker and Interleaf make WYSIWYG technical publishing packages. Both of them have the ability to read and save the contents of a document in an ASCII-coded format as opposed to their normal binary file format. In this example, we convert an Interleaf file into troff; however, the same kind of script could be applied to convert a troff-coded file to Interleaf format. The same is true of FrameMaker. Both place coding tags in the file, surrounded by angle brackets.
In this example, our conversion demonstrates the effect of the change command on a multiline pattern space. In the Interleaf file, "<para>" marks a paragraph. Before and after the tag are blank lines. Look at the sample file:
<para> This is a test paragraph in Interleaf style ASCII. Another line in a paragraph. Yet another. <Figure Begin> v.1111111111111111111111100000000000000000001111111111111000000 100001000100100010001000001000000000000000000000000000000000000 000000 <Figure End> <para> More lines of text to be found after the figure. These lines should print.
This file also contains a bitmap figure, printed as a series of 1s and 0s. To convert this file to troff macros, we must replace the "<para>" code with a macro (.LP). However, there's a bit more to do because we need to remove the blank line that follows the code. There are several ways to do it, but we will use the Next command to create a multiline pattern space, consisting of "<para>" and the blank line, and then use the change command to replace what's in the pattern space with a paragraph macro. Here's the part of the script that does it:
/<para>/{
N
c\
.LP
}The address matches lines with the paragraph tag. The Next command appends the next line, which should be blank, to the pattern space. We use the Next command (N) instead of next (n) because we don't want to output the contents of the pattern space. The change command overwrites the previous contents ("<para>" followed by a newline) of the pattern space, even when it contains multiple lines.
In this conversion script, we'd like to extract the bitmapped figure data and write it to a separate file. In its place, we insert figure macros that mark the figure in the file.
/<Figure Begin>/,/<Figure End>/{
w fig.interleaf
/<Figure End>/i\
.FG\
<insert figure here>\
.FE
d
}This procedure matches the lines between "<Figure Begin>" and "<Figure End>" and writes them to the file named fig.interleaf. Each time this instruction is matched, the delete command will be executed, deleting the lines that have been written to file. When "<Figure End>" is matched, a pair of macros are inserted in place of the figure in the output. Notice that the subsequent delete command does not affect the text output by the insert command. It does, however, delete "<Figure End>" from the pattern space.
Here's the entire script:
/<para>/{
N
c\
.LP
}
/<Figure Begin>/,/<Figure End>/{
w fig.interleaf
/<Figure End>/i\
.FG\
<insert figure here>\
.FE
d
}
/^$/dThe third instruction simply removes unnecessary blank lines. (Note that this instruction could be depended upon to delete the blank line following the "<para>" tag; but you don't always want to remove all blank lines, and we wanted to demonstrate the change command across a multiline pattern space.)
The result of running this script on the test file produces:
$ sed -f sed.interleaf test.interleaf .LP This is a test paragraph in Interleaf style ASCII. Another line in a paragraph. Yet another. .FG <insert figure here> .FE .LP More lines of text to be found after the figure. These lines should print.
6.1.2. Multiline Delete
The delete command (d) deletes the contents of the pattern space and causes a new line of input to be read with editing resuming at the top of the script. The Delete command (D) works slightly differently: it deletes a portion of the pattern space, up to the first embedded newline. It does not cause a new line of input to be read; instead, it returns to the top of the script, applying these instructions to what remains in the pattern space. We can see the difference by writing a script that looks for a series of blank lines and outputs a single blank line. The version below uses the delete command:
# reduce multiple blank lines to one; version using d command
/^$/{
N
/^\n$/d
}When a blank line is encountered, the next line is appended to the pattern space. Then we try to match the embedded newline. Note that the positional metacharacters, ^ and $, match the beginning and the end of the pattern space, respectively. Here's a test file:
This line is followed by 1 blank line. This line is followed by 2 blank lines. This line is followed by 3 blank lines. This line is followed by 4 blank lines. This is the end.
Running the script on the test file produces the following result:
$ sed -f sed.blank test.blank This line is followed by 1 blank line. This line is followed by 2 blank lines. This line is followed by 3 blank lines. This line is followed by 4 blank lines. This is the end.
Where there was an even number of blank lines, all the blank lines were removed. Only when there was an odd number was a single blank line preserved. That is because the delete command clears the entire pattern space. Once the first blank line is encountered, the next line is read in, and both are deleted. If a third blank line is encountered, and the next line is not blank, the delete command is not applied, and thus a blank line is output. If we use the multiline Delete command (D rather than d), we get the result we want:
$ sed -f sed2.blank test.blank This line is followed by 1 blank line. This line is followed by 2 blank lines. This line is followed by 3 blank lines. This line is followed by 4 blank lines. This is the end.
The reason the multiline Delete command gets the job done is that when we encounter two blank lines, the Delete command removes only the first of the two. The next time through the script, the blank line will cause another line to be read into the pattern space. If that line is not blank, then both lines are output, thus ensuring that a single blank line will be output. In other words, when there are two blank lines in the pattern space, only the first one is deleted. When there is a blank line followed by text, the pattern space is output normally.
6.1.3. Multiline Print
The multiline Print command differs slightly from its lowercase cousin. This command outputs the first portion of a multiline pattern space, up to the first embedded newline. After the last command in a script is executed, the contents of the pattern space are automatically output. (The -n option or #n suppresses this default action.) Therefore, print commands (P or p) are used when the default output is suppressed or when flow of control in a script changes such that the bottom of the script is not reached. The Print command frequently appears after the Next command and before the Delete command. These three commands can set up an input/output loop that maintains a two-line pattern space yet outputs only one line at a time. The purpose of this loop is to output only the first line in the pattern space, then return to the top of the script to apply all commands to what had been the second line in the pattern space. Without this loop, when the last command in the script was executed, both lines in the pattern space would be output. The flow through a script that sets up an input/output loop using the Next, Print, and Delete commands is illustrated in Figure 6.1. A multiline pattern space is created to match "UNIX" at the end of the first line and "System" at the beginning of the second line. If "UNIX System" is found across two lines, we change it to "UNIX Operating System". The loop is set up to return to the top of the script and look for "UNIX" at the end of the second line.
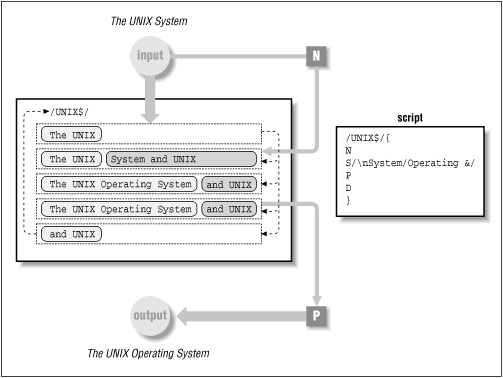
Figure 6.1. The Next, Print, and Delete commands used to set up an input/output loop
The Next command appends a new input line to the current line in the pattern space. After the substitute command is applied to the multiline pattern space, the first part of the pattern space is output by the Print command and then removed by the Delete command. That means the current line is output and the new line becomes the current line. The Delete command prevents the script from reaching bottom, which would output both lines and clear the contents of the pattern space. The Delete command lets us preserve the second portion of the pattern space and pass control to the top of the script where all the editing commands can now be applied to that line. One of those commands is the Next command which reads another new line into the pattern space.
The following script implements the same loop:
/UNIX$/{
N
/\nSystem/{
s// Operating &/
P
D
}
}The substitute command matches "\nSystem" and replaces it with "Operating \nSystem." It is important that the newline be maintained, or else there will be only a single line in the pattern space. Note the order of the Print and Delete commands. Here's our test file:
Here are examples of the UNIX System. Where UNIX System appears, it should be the UNIX Operating System.
Running the script on the test file produces:
$ sed -f sed.Print test.Print Here are examples of the UNIX Operating System. Where UNIX Operating System appears, it should be the UNIX Operating System.
The input/output loop lets us match the occurrence of UNIX at the end of the second line. It would be missed if the two-line pattern space was output normally.
If the relationship between the P and D commands remains unclear to you, we'll have another go at it in the next example. You can also experiment by removing either command from the above script, or try using their lowercase cousins.
|  | |
| 5.12. Quit |  | 6.2. A Case for Study |

Copyright © 2003 O'Reilly & Associates. All rights reserved.