5.2. Perl Functions in Alphabetical Order
Returns the absolute value of its
argument (or $_ if omitted).
accept newsocket, genericsocket
| |
Readies a server process to accept
socket connections from clients. Execution is suspended until a
connection is made, at which time the
newsocket filehandle is opened and
attached to the newly made connection. The function returns the
connected address if the call succeeds or false otherwise (and it
puts the error code into $!).
genericsocket must be a filehandle already
opened via the socket function and bound to one of
the server's network addresses.
Sends a
SIGALRM signal to the executing Perl program after
n seconds. On some older systems, alarms
go off "at the top of the second,"
so, for instance, an alarm 1 may go off anywhere
between 0 to 1 seconds from now, depending on when in the current
second it is. An alarm 2 may go off anywhere from
1 to 2 seconds from now. And so on.
Each call disables the previous timer, and an argument of
0 may be supplied to cancel the previous timer
without starting a new one. The return value is the number of seconds
remaining on the previous timer.
Returns the
arctangent of
y/xin the range - 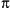 to . A quick way to get an
approximate value of is to say:
$pi = atan2(1,1) * 4;
For the tangent operation, you may use the POSIX::tan(
) function, or use the familiar relation:
sub tan { sin($_[0]) / cos($_[0]) }
Attaches an address to an
already opened socket specified by the
socket filehandle. The function returns
true for success, false otherwise (and puts the error code into
$!). address should be
a packed address of the proper type for the socket.
Arranges for the
file to be treated in binary mode on operating systems that
distinguish between binary and text files. It should be called after
open but before any I/O is done on the filehandle.
The only way to reset binary mode on a filehandle is to reopen the
file.
binmode has no effect under Unix, Plan9, or other
systems that use a single \n (newline) character
as a line delimiter. On systems such as Win32 or MS-DOS,
binmode is needed to prevent the translation of
the line delimiter characters to and from \n.
Looks up the item
pointed to by reference ref and tells the
item that it is now an object in the
classname package—or the current
package if no class name is specified. It returns the reference for
convenience, since a bless is often the last thing
in a constructor function. (Always use the two-argument version if
the constructor doing the blessing might be inherited by a derived
class. In such cases, the class you want to bless your object into
will normally be found as the first argument to the constructor in
question.)
Returns information
about the stack of current subroutine calls. Without an argument, it
returns the package name in a scalar context; in a list context, it
returns the package name, filename, and line number from which the
currently executing subroutine was called:
($package, $filename, $line) = caller;
With an argument it evaluates n as the
number of stack frames to go back before the current one. It also
reports some additional information that the debugger uses to print a
stack trace:
$i = 0;
while (($pack, $file, $line, $subname, $hasargs,
$wantarray, $evaltext, $is_require) = caller($i++)) {
...
}
Furthermore, when called from within the DB package,
caller returns more detailed information: it sets
the list variable @DB::args as the argument passed
in the given stack frame.
Changes the working
directory to dirname, if possible. If
dirname is omitted, it changes to the home
directory. The function returns 1 upon success,
0 otherwise (and puts the error code into
$!).
Changes the
permissions of a list of files. The first argument must be the
permissions mode given in its octal number representation. The
function returns the number of files successfully changed. For
example:
$cnt = chmod 0755, 'file1', 'file2';
will set $cnt to 0,
1, or 2, depending on how many
files got changed (in the sense that the operation succeeded, not in
the sense that the bits were different afterward).
Removes any
line-ending characters of a string in
$var, or each string in
@list, that correspond
to the current value of $/ (not just any last
character, as chop does). chomp
returns the number of characters deleted. If $/ is
empty (in paragraph mode), chomp removes all
newlines from the selected string (or strings, if
chomping a list). If no argument is given, the
function chomps the $_
variable.
Chops off the last
character of a string contained in the variable
$var (or strings in
each element of a
@list) and returns the
character chopped. The chop operator is used
primarily to remove the newline from the end of an input record but
is more efficient than s/\n$//. If no argument is
given, the function chops the $_ variable.
Changes the owner
and group of a list of files. The first two arguments must be the
numerical uid and
gid, in that order. The function returns
the number of files successfully changed.
On most systems, you are not allowed to change the ownership of the
file unless you're the superuser, although you
should be able to change the group to any of your secondary groups.
On insecure systems, these restrictions may be relaxed, but this is
not a portable assumption.
Returns
the character represented by number in the
character set. For example, chr(65) is
"A" in ASCII.
Changes the root
directory for the current process to
dirname—the starting point for
pathnames beginning with /. This directory is
inherited across exec calls and by all
subprocesses. There is no way to undo a chroot.
Only the superuser can use this function.
Closes the file, socket,
or pipe associated with the given filehandle. You
don't have to close
filehandle if you are immediately going to
do another open on it, since the next
open will close it for you. However, an explicit
close on an input file resets the line counter
( $.), while the implicit close
done by open does not. Closing a pipe will wait
for the process executing on the pipe to complete and will prevent
the script from exiting before the pipeline is finished. Also,
closing a pipe explicitly puts the status value of the command
executing on the pipe into $?.
filehandle may be an expression with a
value that gives a real filehandle name. It may also be a reference
to a filehandle object returned by some of the object-oriented I/O
packages.
Closes a
directory associated with the given directory handle opened by
opendir.
Initiates a
connection with another process that is waiting at an
accept on the filehandle
socket. The function returns true for
success, false otherwise (and puts the error code into
$!). address is a
packed network address of the proper type for
socket.
To disconnect a socket, use either close or
shutdown.
Returns the cosine of
num (expressed in radians). For the
inverse cosine operation, you may use the POSIX::acos(
) function, or use this relation:
sub acos { atan2( sqrt(1 - $_[0] * $_[0]), $_[0] ) }
Used by the
passwd function on Unix systems to produce a
unique 13-character string (stored in the system's
password file) from the first 8 characters of the given
string and the 2-character
salt. The Perl function operates the same
way and returns a 13-character string with the first 2 characters as
the salt. crypt uses a
modified version of the Data Encryption Standard, which produces a
one-way encryption; the resulting string cannot be decrypted to
determine the original string. crypt can be used
to check that a password is correct by comparing the string from the
function to the string found in /etc/passwd (if
you have permission to do this):
if (crypt ($guess, $pass) eq $pass) {
# guess is correct
}
The variable $pass is the password string from the
password file. crypt merely uses the first two
characters from this string for the saltargument.
Breaks the
binding between a DBM file and a hash.
This function is actually just a call to untie
with the proper arguments, but is provided for backward compatibility
with older versions of Perl.
dbmopen %hash, dbname, mode
| |
Binds a DBM file
( dbname) to a hash
(% hash). dbnameis the name of the database without the .dir or
.pag extension. Note that while not deprecated,
dbmopen has basically been superseded by
tie( ). If the database does not exist, and a
valid mode is specified, the database is created with the permissions
specified by mode (as modified by the
umask). To prevent creation of the database if it
doesn't exist, you may specify a
mode of undef, and the
function will return a false value if it can't find
an existing database. If your system supports only the older DBM
functions, you may have only one dbmopen in your
program.
Values assigned to the hash prior to the dbmopen
are not accessible. If you don't have write access
to the DBM file, you can only read the hash variables, not set them.
This function is actually just a call to tie with
the proper arguments, but is provided for backward compatibility with
older versions of Perl.
Returns a Boolean
value saying whether the scalar value resulting from
expr has a real value. If no argument is
given, defined checks $_.
A scalar that contains no valid string, numeric, or reference value
is known as the undefined value, or undef. Many
operations return the undefined value under exceptional conditions,
such as end-of-file, uninitialized variable, system error, and so on.
This function allows you to distinguish between an undefined null
string and a defined null string when you're using
operators that might return a real null string.
You can use defined to see if a subroutine exists,
that is, if the subroutine definition has been successfully parsed.
However, using defined on an array or a hash is
not guaranteed to produce intuitive results and should be avoided.
delete $hash{key}
delete @hash{@keys}
| |
Deletes the specified
key or keys and
associated values from the specified hash.
(It doesn't delete a file. See unlink for that.) Deleting from
$ENV{} modifies the environment. Deleting from a
hash that is bound to a (writable) DBM file deletes the entry from
the DBM file.
For normal hashes, the delete function returns the
value (not the key) that was deleted, but this behavior is not
guaranteed for tied hashes, such as those bound to DBM files. To test
whether a hash element has been deleted, use
exists.
Prints
message to the standard error output and
exits the Perl program with a nonzero exit status.
message can be a list value, like the
arguments to print, from which the elements are
concatenated into a single string for output. If
message does not end with a newline
( \n), the current script filename, line number,
and input line number (if any) are appended to the message with a
newline. With no argument, the function outputs the string
Died as its default.
die exits the programs with the current value of
the $! variable, which contains the text
describing the most recent operating system error value. This value
can be used in the message to describe
what the problem may have been.
die behaves differently inside an
eval statement. It places the error message in the
$@ variable and aborts the
eval, which returns an undefined value. This use
of die can raise runtime exceptions that can be
caught at a higher level of the program.
Executes
the sequence of commands in the block and
returns the value of the last expression evaluated. When modified by
a loop modifier, Perl executes the blockonce before testing the loop condition. (On other statements, the
loop modifiers test the conditional first.)
During
program execution, causes an immediate core dump after code previous
to it has already been executed. Primarily, this is so that you can
use the undump program to turn your core dump into
an executable binary after having initialized all your variables at
the beginning of the program. Please note that you
shouldn't use dump( ) or
undump( ) with the availability of the Perl
Compiler (B modules) as part of your Perl distribution. In addition,
you're unlikely to have success with
dump or undump on most modern
Unix systems (that support dynamic loading from
libdl). dump arranges for the
revived binary, when run, to begin by executing a
goto label (with all the restrictions that
goto suffers). Think of the operation as a
goto with an intervening core dump and
reincarnation. If label is omitted, the
function arranges for the program to restart from the top. Note that
any files opened at the time of the dump will no longer be open when
the program is reincarnated. See also the -u
command-line switch.
As of Perl 5.8, dump is now largely obsolete,
partly because it's difficult to convert a core file
into an executable, and because the real compiler backends for
generating portable bytecode and compilable C code have superseded
it. That's why you should now invoke it as "CORE::dump(
)" if you don't want to be warned against a possible typo.
The undump program is not available on all systems
and may not be compatible with specific ports of Perl.
Returns a two-element
list consisting of the key and value for the next element of a hash.
With successive calls to each, you can iterate
over the entire hash. Entries are returned in an indeterminate order.
When the hash is entirely read, a null list is returned. The next
call to each after that will start a new
iteration. The iterator can be reset either by reading all the
elements from the hash or by calling the keys
function in scalar context. You must not add elements to the hash
while iterating over it, although you are permitted to use
delete. In a scalar context,
each returns only the key.
There is a single iterator for each hash, shared by all
each, keys, and
values function calls in the program. This means
that after a keys or values
call, the next each call will start again from the
beginning.
Closes the groups
file (usually /etc/group on Unix systems) if
open. Not implemented on Win32 systems.
Closes the
hosts file (usually /etc/hosts on Unix systems)
if open. Not implemented on Win32 systems.
Closes the
networks file (usually /etc/networks on Unix
systems) if open. Not implemented on Win32 systems.
Closes the
prototypes file (usually /etc/prototypes on Unix
systems) if open. Not implemented on Win32 systems.
Closes the
password file ( /etc/passwd or equivalent on Unix
systems) if open. Not implemented on Win32 systems.
Closes the
services file (usually /etc/services on Unix
systems) if open. Not implemented on Win32 systems.
Returns true if the
next read on filehandle will return
end-of-file, or if filehandle is not open.
filehandle may be an expression with a
value that gives the real filehandle name. An eof
without an argument returns the end-of-file status for the last file
read. Empty parentheses ( ) may be used in
connection with the combined files listed on the command line. That
is, inside a while (<>) loop, eof(
) will detect the end of only the last of a group of files.
Use eof(ARGV) or eof (without
parentheses) to test each file in a while
(<>) loop. For example, the following code inserts
dashes just before the last line of the last file:
while (<>) {
if (eof( )) {
print "-" x 30, "\n";
}
print;
}
Evaluates the
expression or code in its argument at runtime as a separate Perl
program within the context of the larger script. Any variable
settings remain afterward, as do any subroutine or format
definitions. The code of the eval is treated as a
block, so any locally scoped variables declared within the
eval last only until the eval
is done. (See also local and
my.) The value returned from an
eval is the value of the last expression
evaluated. Like subroutines, you may also use the
return function to return a value and exit the
eval.
With eval string, the
contents of string are compiled and
executed at runtime. For example:
$a = 3, $b = 4;
$c = '$a * $b';
print (eval "$c"); # Prints 12
The string form of eval is useful for executing
strings produced at runtime from standard or other dynamic input
sources. If the string produces an error, either from syntax or at
runtime, the eval exits with the undefined value
and places the error in $@. If
string is omitted, the operator evaluates
$_.
The block form of eval is used in Perl programs to
handle runtime errors (exceptions). The code in
block is compiled only once during the
compilation of the main program. If there is a syntax error in the
block, it will produce an error at compile time. If the code in
block produces a runtime error (or if a
die statement is encountered), the
eval exits, and the error is placed in
$@. For example, the following code can be used to
trap a divide-by-zero error at runtime:
eval {
$a = 10; $b = 0;
$c = $a / $b; # Causes runtime error
# Trapped by eval
};
print $@; # Prints "Illegal division by 0 at
# try.pl line 3"
As with any code in a block, a final semicolon is not required.
Terminates the
currently running Perl script and executes the program named in
command. The Perl program does not resume
after the exec unless the exec
cannot be run and produces an error. Unlike
system, the executed
command is not forked off into a child
process. An exec completely replaces the script in
its current process.
command may be a scalar containing a
string with the name of the program to run and any arguments. This
string is checked for shell metacharacters, and if there are any,
passes the string to /bin/sh/ -c for parsing.
Otherwise, the string is read as a program command, bypassing any
shell processing. The first word of the string is used as the program
name, with any remaining words used as arguments.
command may also be a list value in which
the first element is parsed as the program name and remaining
elements as arguments. For example:
exec 'echo', 'Your arguments are: ', @ARGV;
The exec function is not implemented for Perl on
Win32 platforms.
Returns true if the
specified hash key exists, even if the corresponding value is
undefined.
Exits the current
Perl process immediately with that value given by
status. This could be the entire Perl
script you are running or only a child process created by
fork. Here's a fragment that lets
a user exit the program by typing x or
X:
$ans = <STDIN>;
exit 0 if $ans =~ /^[Xx]/;
If status is omitted, the function exits
with 0. You shouldn't use
exit to abort a subroutine if
there's any chance that someone might want to trap
whatever error happened. Use die instead, which
can be trapped by an eval.
Returns
e to the power of
num. If num is
omitted, it gives exp($_). To do general
exponentiation, use the ** operator.
fcntl filehandle, function, arg
| |
Calls
the file control function (with the
function-specific arg) to use on the file
or device opened with filehandle.
fcntl calls Unix's
fcntl function (not available on Win32 platforms).
If the function is not implemented, the program exits with a fatal
error. fcntl sets file descriptors for a
filehandle. This built-in command is usable when you use the Fcntl
module in the standard distribution:
use Fcntl;
This module imports the correct functiondefinitions. See the description of the Fcntl module in Chapter 8, "Standard Modules".
The return value of fcntl (and
ioctl) is as follows:
|
System call returns
|
Perl returns
|
|
-1
|
Undefined value
|
|
0
|
String "0 but true"
|
|
Anything else
|
That number
|
Thus Perl returns true on success and false on failure, yet you can
still easily determine the actual value returned by the operating
system.
Returns the file
descriptor for a filehandle. (A file descriptor is a small integer,
unlike the filehandle, which is a symbol.) It returns
undef if the handle is not open.
It's useful for constructing bitmaps for
select and for passing to certain obscure system
calls if syscall is implemented.
It's also useful for double-checking that the
open function gave you the file descriptor you
wanted.
flock filehandle, operation
| |
Establishes or
removes a lock on a file opened with
filehandle. This function calls one of the
Unix functions flock, lockf, or
the locking capabilities of fcntl, whichever your
system supports. If none of these functions exist on your system,
flock will produce a fatal error.
operation is the type of locking function
to perform. The number by each operation name is the argument that
Perl's flock takes by default.
You may also use the operation names if you explicitly import them
from the Fcntl module with use Fcntl ":flock".
- LOCK_SH (1)">LOCK_SH (1)
-
Establishes a shared lock on the file (read lock).
- LOCK_EX (2)">LOCK_EX (2)
-
Establishes an exclusive lock on the file (write lock).
- LOCK_UN (8)">LOCK_UN (8)
-
Removes a lock from the file.
- LOCK_NB (4)">LOCK_NB (4)
-
Prevents flock from blocking while trying to
establish a lock with LOCK_SH or
LOCK_EX and instructs it to return immediately.
LOCK_NB must be ored with the
other operation as an expression for the operation argument, i.e.,
(LOCK_EX | LOCK_NB).
Spawns a child
process that executes the code immediately following the
fork call until the process is terminated (usually
with an exit). The child process runs parallel to
the parent process and shares all the parent's
variables and open filehandles. The function returns the child pid to
the parent process and 0 to the child process on
success. If it fails, it returns the undefined value to the parent
process, and no child process is created. If you
fork your child processes, you'll
have to wait on their zombies when they die.
The
fork function is unlikely to be implemented on any
operating system not resembling Unix, unless it purports POSIX
compliance.
formline picture, variables
| |
Internal function
used by formats, although you may also call it. It formats a list of
values ( variables) according to the
contents of picture, placing the output
into the format output accumulator, $^A. When a
write is done, the contents of
$^A are written to a filehandle, but you can also
read $^A yourself and set $^A
back to "". Note that a format
typically does one formline per line of form, but
the formline function itself
doesn't care how many newlines are embedded in the
picture. This means that the
~ and ~~ tokens will treat the
entire picture as a single line. Thus, you
may need to use multiple formlines to implement a single-record
format, such as the format compiler.
Be careful if you put double quotes around the picture, since an
@ character may be taken to mean the beginning of
an array name. formline always returns true. See
Chapter 4, "The Perl Language" for more information.
Returns the next byte
from the input file attached to
filehandle. At end-of-file, it returns a
null string. If filehandle is omitted, the
function reads from STDIN. This operator is very slow, but is
occasionally useful for single-character input from the keyboard.
Returns the next
entry from the systems group file (usually
/etc/group on Unix systems) starting from the
top. Returns null when end-of-file is reached. The return value from
getgrent in list context is:
($name, $passwd, $gid, $members)
in which $members contains a space-separated list
of the login names of the members of the group. In scalar context,
getgrent returns only the group name.
Retrieves a group
file ( /etc/group) entry by group number
gid. The return value in list context is:
($name, $passwd, $gid, $members)
in which $members contains a space-separated list
of the login names of the members of the group. If you want to do
this repeatedly, consider caching the data in a hash using
getgrent. In scalar context,
getgrgid returns only the group name.
Retrieves a group
file entry by the group name name. The
return value in list context is:
($name, $passwd, $gid, $members)
in which $members contains a space-separated list
of the login names of the members of the group. In scalar context,
getgrnam returns only the numeric group ID.
gethostbyaddr address, [addrtype]
| |
Retrieves
the hostname (and alternate addresses) of a packed binary network
address.
( addrtype indicates the type of address
given. Since gethostbyaddr is used almost solely
for Internet IP addresses, addrtype is not
needed.) The return value in list context is:
($name, $aliases, $addrtype, $length, @addrs)
in which @addrs is a list of packed binary
addresses. In the Internet domain, each address is four bytes long
and can be unpacked by something like:
($a, $b, $c, $d) = unpack('C4', $addrs[0]);
In scalar context, gethostbyaddr returns only the
hostname.
Retrieves
the address (and other names) of a network hostname. The return value
in list context is:
($name, $aliases, $addrtype, $length, @addrs)
in which @addrs is a list of raw addresses. In
scalar context, gethostbyname returns only the
host address.
Retrieves the
next entry from your system's network hosts file
(usually /etc/hosts on Unix). The return value
from gethostent is:
($name, $aliases, $addrtype, $length, @addrs)
in which @addrs is a list of raw addresses.
Scripts that use this function should not be considered portable.
Returns the
current login from /etc/utmp (Unix systems
only), if any. If null, use getpwuid. For example:
$login = getlogin || getpwuid($<) || "Intruder!!";
getnetbyaddr address, [addrtype]
| |
Retrieves the
network name or names of the given network
address.
( addrtype indicates the type of address.
Often, this function is used for IP addresses, in which the type is
not needed.) The return value in list context is:
($name, $aliases, $addrtype, $net)
In scalar context, getnetbyaddr returns only the
network name.
Retrieves the
network address of a network name. The
return value in list context is:
($name, $aliases, $addrtype, $net)
In scalar context, getnetbyname returns only the
network address.
Retrieves the
next line from your /etc/networks file, or
system equivalent. The return value in list context is:
($name, $aliases, $addrtype, $net)
In scalar context, getnetent returns only the
network name.
Returns the
packed socket address of the other end of the
socket connection. For example:
use Socket;
$hersockaddr = getpeername SOCK;
($port, $heraddr) = unpack_sockaddr_in($hersockaddr);
$herhostname = gethostbyaddr($heraddr, AF_INET);
$herstraddr = inet_ntoa($heraddr);
Returns the
current process group for the specified process ID
( pid). Use a
pid of 0 for the
current process. Invoking getpgrp will produce a
fatal error if used on a machine that doesn't
implement the getpgrp system call. If
pid is omitted, the function returns the
process group of the current process (the same as using a
pid of 0). On systems
implementing this operator with the POSIX
getpgrp(2) system call,
pid must be omitted or, if supplied, must
be 0.
Returns the
process ID of the parent process. On a typical Unix system, if your
parent process ID changes to 1, your parent
process has died, and you've been adopted by the
init program.
Returns the
current priority for a process, a process group, or a user.
type indicates which of these three
process types to return. (The type identifiers are system-specific.
Consult the manpage for getpriority.) The
id gives the specific ID of the
corresponding process type in type: a
process ID, a process-group ID, or a user ID. The value
0 in who gives the priority
for the current process, process group, or user.
The priority will be an integer value. Lower values indicate higher
priority (negative values may be returned on some systems). Invoking
getpriority will produce a fatal error if used on
a machine that doesn't implement the
getpriority system call.
Translates
a protocol name to its corresponding number. The return value in list
context is:
($name, $aliases, $protocol_number)
In scalar context, getprotobyname returns only the
protocol number.
Translates
a protocol number to its corresponding name. The return value in list
context is:
($name, $aliases, $protocol_number)
In scalar context, getprotobynumber returns only
the protocol name.
Retrieves the
next line from the /etc/protocols file (on some
Unix systems). Returns null at the end of the file. The return value
from getprotoent is:
($name, $aliases, $protocol_number)
In scalar context, getprotoent returns only the
protocol name.
Retrieves the
next line from the /etc/passwd file (or its
equivalent coming from another server). Returns null at the end of
the file. The return value in list context is:
($name,$passwd,$uid,$gid,$quota,$comment,$gcos,$dir,$shell)
Some machines may use the quota and comment fields for other
purposes, but the remaining fields will always be the same. To set up
a hash for translating login names to uids, do this:
while (($name, $passwd, $uid) = getpwent) {
$uid{$name} = $uid;
}
In scalar context, getpwent returns only the
username.
Retrieves the
passwd file entry of a user
name. The return value in list context is:
($name,$passwd,$uid,$gid,$quota,$comment,$gcos,$dir,$shell)
If you want to do this repeatedly, consider caching the data in a
hash using getpwent.
In scalar context, getpwnam returns only the
numeric user ID.
Retrieves the
passwd file entry with the user ID
uid. The return value in list context is:
($name,$passwd,$uid,$gid,$quota,$comment,$gcos,$dir,$shell)
If you want to do this repeatedly, consider slurping the data into a
hash using getpwent.
In scalar context, getpwuid returns the username.
getservbyname name, proto
| |
Translates a
service (port) name to its corresponding port number.
proto is a protocol name such as
tcp. The return value in list context is:
($name, $aliases, $port_number, $protocol_name)
In scalar context, getservbyname returns only the
service port number.
getservbyport port, proto
| |
Translates a
service (port) number to its corresponding names.
proto is a protocol name such as
tcp. The return value in list context is:
($name, $aliases, $port_number, $protocol_name)
In scalar context, getservbyport returns only the
service port name.
Retrieves the
next listing from the /etc/services file or its
equivalent. Returns null at the end of the file. The return value in
list context is:
($name, $aliases, $port_number, $protocol_name)
In scalar context, getservent returns only the
service port name.
Returns the
packed socket address of this end of the
socket connection.
getsockopt socket, level, optname
| |
Returns the
value of the socket option optname, or the
undefined value if there is an error.
level identifies the protocol level used
by socket. Options vary for different
protocols. See also setsockopt.
Performs filename
expansion (globbing) on expr, returning
the next successive name on each call. If
expr is omitted, $_ is
globbed instead. This is the internal function
implementing the <*> operator, except that
it may be easier to type this way.
The glob function is not related to the Perl
notion of typeglobs, other than that they both use a
* to represent multiple items.
Converts a time
string as returned by the time function to a
nine-element list with the time correct for Greenwich Mean Time zone
(a.k.a. GMT, UTC, etc.). Typically used as follows:
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) =
gmtime(time);
All list elements are numeric and come straight out of a C language
struct tm. In particular, this means that
$mon has the range 0..11,
$wday has the range 0..6, and
the year has had 1,900 subtracted from it. (You can remember which
elements are 0-based because
you're always using these as subscripts into
0-based arrays containing month and day names.) If
expr is omitted, it does
gmtime(time). For example, to print the current
month in London:
$london_month = (qw(Jan Feb Mar Apr May Jun
Jul Aug Sep Oct Nov Dec))[(gmtime)[4]];
The Perl library module Time::Local contains a subroutine,
timegm( ), that can convert in the opposite
direction.
In scalar context, gmtime returns a
ctime(3)-like string based on the GMT time value.
Finds the statement
labeled with label (or an expression that
evaluates to a label) and resumes execution there. It may not be used
to go into any construct that requires initialization, such as a
subroutine or a foreach loop. It also
can't be used to go into a construct that is
optimized away. It can be used to go almost anywhere else within the
dynamic scope, including out of subroutines, but for that purpose,
it's usually better to use another construct, such
as last or die.
goto
&name substitutes a
call to the named subroutine for the currently running subroutine.
This is used by AUTOLOAD subroutines that wish to
load another subroutine and pretend that this subroutine—and
not the original one—had been called in the first place (except
that any modifications to @_ in the original
subroutine are propagated to the replacement subroutine). After the
goto, not even caller will be
able to tell that the original routine was called first.
grep expr, list
grep {block} list
| |
Evaluates
expr or blockin a Boolean context for each element of
list, temporarily setting
$_ to each element in turn. In list context, it
returns a list of those elements for which the expression is true.
Mostly used like Unix grep, in which
expr is a search pattern, and list
elements that match are returned. In scalar context,
grep returns the number of times the expression
was true.
For example, presuming @all_lines contains lines
of code, this example weeds out comment lines:
@code_lines = grep !/^#/, @all_lines;
Converts a hexadecimal
string hexnum into its equivalent decimal
value. If hexnum is omitted, it interprets
$_. The following code sets
$number to 4,294,906,560:
$number = hex("ffff12c0");
To do the inverse function, use: sprintf "%lx", $number; # That's a letter 'l', not a one
index string, substr, [start]
| |
Returns the position of
the first occurrence of substr in
string. The
start, if specified, specifies the
position to start looking in the string. Positions are integer
numbers based at 0. If the substring is not found,
the index function returns -1.
Returns
the integer portion of num. If
num is omitted, the function uses
$_.
ioctl filehandle, function, arg
| |
Calls the
ioctl Unix system call to perform
function (with the function-specific
arg) on the file or device opened with
filehandle. See fcntl
for a description of return values.
Joins the separate
strings of list into a single string with
fields separated by the value of char and
returns the string. For example:
$_ = join ':', $login,$passwd,$uid,$gid,$gcos,$home,$shell;
To do the opposite, see split. To join things
together into fixed-position fields, see pack.
Returns a list
consisting of all the keys of the named hash. The keys are returned
in an apparently random order, but it is the same order that either
the values or each function
produces (assuming that the hash has not been modified between
calls).
In scalar context, keys returns the number of
elements of the hash (and resets the each
iterator).
keys can be used as an lvalue to increase the
number of hash buckets allocated for the hash:
keys %hash = 200;
Sends a signal,
sig, to a list of
processes. You may use a signal name in
quotes (without a SIG on the front). This function
returns the number of processes successfully signaled. If the signal
is negative, the function kills process groups instead of processes.
Immediately exits the loop
identified by label. If
label is omitted, the command refers to
the innermost enclosing loop.
Returns a
lowercase version of string (or
$_, if omitted). This is the
internal function implementing the \L escape in
double-quoted strings.
Returns a version
of string (or $_, if
omitted) with the first character lowercased. This is the internal
function implementing the \l escape in
double-quoted strings.
Returns the length
in bytes of the scalar value val. If
val is omitted, the function returns the
length of $_.
Do not try to use length to find the size of an
array or hash. Use scalar
@array for the size of an array,
and scalar keys %hashfor the size of a hash.
Creates
a Unix hard link from a new filename,
newfile, to an existing file,
oldfile, on the same filesystem. The
function returns 1 for success,
0 otherwise (and puts the error code into
$!). This function is unlikely to be implemented
on non-Unix systems. See also symlink.
Tells the operating
system that you are ready to accept connections on
socket and sets the number of waiting
connections to queuesize. If the queue is
full, clients trying to connect to the socket will be refused
connection.
Declares one or more
global variables vars to have temporary
values within the innermost enclosing block, subroutine,
eval, or file. The new value is initially
undef for scalars and ( ) for
arrays and hashes. If more than one variable is listed, the list must
be placed in parentheses, because the operator binds more tightly
than a comma. All the listed variables must be legal lvalues, that
is, something you can assign to. This operator works by saving the
current values of those variables on a hidden stack and restoring
them upon exiting the block, subroutine, eval, or
file.
Subroutines called within the scope of a local variable will see the
localized inner value of the variable. The technical term for this
process is "dynamic scoping." Use
my for true private variables.
Converts the
value returned by time to a nine-element list with
the time corrected for the local time zone. It's
typically used as follows:
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) =
localtime(time);
All list elements are numeric. The element $mon
(month) has the range 0..11, and
$wday (weekday) has the range
0..6. The year has had 1,900 subtracted from it.
(You can remember which elements are 0-based
because you're always using them as subscripts into
0-based arrays containing month and day names.) If
val is omitted, it does
localtime(time). For example, to get the name of
the current day of the week:
$thisday = (Sun,Mon,Tue,Wed,Thu,Fri,Sat)[(localtime)[6]];
The Perl library module Time::Local contains a subroutine,
timelocal( ), that can convert in the opposite
direction.
In scalar context, localtime returns a
ctime(3)-like string based on the localtime value.
Returns
logarithm (base e) of
num. If num is
omitted, the function uses $_.
Like
stat, returns information on
file, except that if
file is a symbolic link,
lstat returns information about the link;
stat returns information about the file pointed to
by the link. (If symbolic links are unimplemented on your system, a
normal stat is done instead.)
map {block} list
map expr, list
| |
Evaluates the
block or exprfor each element of list (locally setting
$_ to each element) and returns the list value
composed of the results of each evaluation. It evaluates
block or exprin a list context, so each element of listmay produce zero, one, or more elements in the returned value. These
are all flattened into one list. For instance:
@words = map { split ' ' } @lines;
splits a list of lines into a list of words. Often, though, there is
a one-to-one mapping between input values and output values:
@chars = map chr, @nums;
This statement translates a list of numbers to the corresponding
characters.
Creates the
directory specified by filename, with
permissions specified by the numeric mode(as modified by the current umask). If it succeeds, it returns
1; otherwise, it returns 0 and
sets $! (from the value of
errno).
Calls the
msgctl system call, which is used to perform
different control operations on IPC message queues. (See the
msgctl documentation on your system for details.)
If cmd is
&IPC_STAT, then argmust be a variable that will hold the returned
msqid_ds structure. The return values work like
those of fnctl: the undefined value for error,
0 but true for zero, or the
actual return value otherwise. On error, it puts the error code into
$!. Before calling, you should say:
require "ipc.ph";
require "msg.ph";
This function is available only on machines supporting System V IPC.
Calls the System V
IPC msgget system call. See the
msgget documentation on your system for details.
The function returns the message queue ID, or the undefined value if
there is an error. On error, it puts the error code into
$!. Before calling, you should say:
require "ipc.ph";
require "msg.ph";
This function is available only on machines supporting System V IPC.
msgrcv id, var, size, type, flags
| |
Calls the System V
IPC msgrcv system call to receive a message from
message queue id into variable
var with a maximum message size of
size. When a message is received, the
message type will be the first thing in
var, and the maximum length of
var is sizeplus the size of the message type. The function returns true if
successful, or false if there is an error. On error, it puts the
error code into $!. Before calling, you should
say:
require "ipc.ph";
require "msg.ph";
This function is available only on machines supporting System V IPC.
Calls the System V
IPC msgsnd system call to send the message
msg to the message queue
id. msg must
begin with the long integer message type. You can create a message
like this:
$msg = pack "L a*", $type, $text_of_message;
The function returns true if successful, or false if there is an
error. On error, it puts the error code into $!.
Before calling, you should say:
require "ipc.ph";
require "msg.ph";
This function is available only on machines supporting System V IPC.
Declares one or more
private variables to exist only within the innermost enclosing block,
subroutine, eval, or file. The new value is
initially undef for scalars and (
) for arrays and hashes. If more than one variable is
listed, the list must be placed in parentheses, because the operator
binds more tightly than a comma. Only simple scalars or complete
arrays and hashes may be declared this way. The variable name may not
be package-qualified, because package variables are all global, and
private variables are not related to any package.
Unlike local, this operator has nothing to do with
global variables, other than hiding any other variable of the same
name from view within its scope. (A global variable can always be
accessed through its package-qualified form or a symbolic reference,
however.) A private variable is not visible until the statement after
its declaration. Subroutines called from within the scope of such a
private variable cannot see the private variable unless the
subroutine is also textually declared within the scope of the
variable.
Immediately jumps to
the next iteration of the loop identified by
label or the innermost enclosing loop, if
there is no argument. If there is a continue
block, it will be executed immediately after the
next, before the loop is reiterated.
Effectively
"undoes" the use
function. Used to deactivate pragmas (compiler directives) for
sections of your program. For instance:
no strict 'refs'
allows soft references to the end of the block scope if: use strict 'refs'
was previously invoked.
Interprets
ostring as an octal string and returns the
equivalent decimal value. (If ostringhappens to start with 0x, it is interpreted as a
hex string instead.) The following will handle decimal, octal, and
hex in the standard notation:
$val = oct $val if $val =~ /^0/;
If ostring is omitted, the function
interprets $_. To perform the inverse function on
octal numbers, use:
$oct_string = sprintf "%lo", $number;
open filehandle, filename
open filehandle, mode, filename
open filehandle, mode, expr, list (new in 5.8)
open filehandle, mode, reference (new in 5.8)
| |
Opens
the file given by filename and associates
it with filehandle. If
filehandle is omitted, the scalar variable
of the same name as the filehandle must
contain the filename. (And you must also be careful to use
or die after the statement rather than
|| die, because the precedence
of || is higher than list operators such as
open.)
If filename is preceded by either
< or nothing, the file is opened for input
(read-only). If filename is preceded by
>, the file is opened for output. If the file
doesn't exist, it will be created; if the file
exists, it will be overwritten with output using
>. Preceding the filename with
>> opens an output file for appending. For
both read and write access, use a + before
< or >.
If you choose to use the three-or-more-arguments form of
open, you can use separate
mode and
filename arguments, such as
open($fh,
$mode,
$filename),
in which $moderepresents an open mode or pipe. For example:
my $mode = '+<';
my $filename = 'whatever.txt';
open(FH, $mode, $filename)
or die("can't open $filename: $!");
As covered in Chapter 4, "The Perl Language", you can build Perl 5.8
and newer with PerlIO support, which offers additional features for
your system's I/O (STDIO). This allows you to do
neat things, such as specify utf-8 as your default
encoding for all of your I/O, or set your default line endings with
'crlf'. In addition, you can select piping to or
extracting information from an external program with
'|-' and '-|', respectively.
For example:
my $prog = "webster overworked";
open($fh, '-|', $prog)
or die("can't open pipe to '$prog': $!");
or, similarly: my @prog_info = qw(/usr/contrib/bin/webster overworked);
open($fh, '-|', @prog_info)
or die(...);
A filehandle may also be attached to a process by using a piped
command. If the filename begins with |, the
filename is interpreted as a command to which output is to be piped.
If the filename ends with a |, the filename is
interpreted as a command that pipes input to you. You may not have an
open command that pipes both in and out.
Any pipe command containing shell metacharacters is passed to the
shell for execution; otherwise, it is executed directly by Perl. The
filename - refers to STDIN, and
> refers to STDOUT. open
returns nonzero upon success, the undefined value otherwise. If the
open involved a pipe, the return value happens to
be the process ID of the subprocess.
opendir dirhandle, directory
| |
Opens a
directory for processing by
readdir, telldir,
seekdir, rewinddir, and
closedir. The function returns true if successful.
Directory handles have their own namespace separate from filehandles.
Returns the numeric
ASCII value of the first character of
expr. If expr is
omitted, it uses $_. The return value is always
unsigned. If you want a signed value, use
unpack('c',
expr). If you want all
the characters of the string converted to a list of numbers, use
unpack('C*',
expr) instead.
Declares the listed
variables to be valid globals within the enclosing block, file, or
eval. vars must be in
parentheses if more than one value is used. our( )
has the same scoping rules as a
"my" declaration but does not
create a local variable. Variables that you create with our(
) will be visible across its lexical scope and may cross
package boundaries. Unlike usevars, our( )
is not package scoped; the package in which the variable is entered
is determined at the point of declaration, not at the time of use.
This means the following behavior holds:
package Foo;
our $bar; # Declares $Foo::bar for rest of lexical scope
$bar = 20;
package Bar;
print $bar; # Prints 20
You my use multiple our declarations in the same
lexical scope if they are in different packages. If they are in the
same package, Perl will emit warnings if you have asked for them:
use warnings;
package Foo;
our $bar; # Declares $Foo::bar for rest of lexical scope
$bar = 20;
package Bar;
our $bar = 30; # Declares $Bar::bar for rest of lexical scope
print $bar; # Prints 30
our $bar; # Emits warning
Takes a
list of values and packs it into a binary structure, returning the
string containing the structure. templateis a sequence of characters that give the order and type of values,
as follows:
|
Character
|
Meaning
|
|
@
|
Null-fill to absolute position.
|
|
(
|
Start of a ( ) group.
|
|
a
|
An ASCII string, will be null padded.
|
|
A
|
An ASCII string, will be space padded.
|
|
b
|
A bit string, low-to-high order (such as vec( )).
|
|
B
|
A bit string, high-to-low order.
|
|
c
|
A signed char value.
|
|
C
|
An unsigned char value.
|
|
d
|
A double-precision float in the native format.
|
|
D
|
A long double-precision float in the native format. Long doubles are
avai able only if your system supports long double values and if Perl
has been compiled to support these values. Causes a fatal error
otherwise. New in 5.8.
|
|
f
|
A single-precision float in the native format.
|
|
F
|
A floating-point value in the native format, i.e., a Perl internal
floating-point value (NV). New in 5.8.
|
|
h
|
A hexadecimal string, low nybble first.
|
|
H
|
A hexadecimal string, high nybble first.
|
|
i
|
A signed integer value.
|
|
I
|
An unsigned integer value.
|
|
l
|
A signed long value.
|
|
j
|
A signed integer value, i.e., a Perl internal integer (IV). New in
5.8.
|
|
J
|
An unsigned integer value, i.e., a Perl internal unsigned integer
(UV). New in 5.8.
|
|
L
|
An unsigned long value.
|
|
n
|
A short in "network" (big-endian)
order.
|
|
N
|
A long in "network" (big-endian)
order.
|
|
p
|
A pointer to a string.
|
|
P
|
A pointer to a structure (fixed-length string).
|
|
q
|
A signed quad (64-bit) value. New in 5.8.
|
|
Q
|
An unsigned quad value. Quads are available only if your system
supports 64-bit integer values and if Perl has been compiled to
support these values. Causes a fatal error otherwise. New in 5.8.
|
|
s
|
A signed short value.
|
|
S
|
An unsigned short value.
|
|
v
|
A short in "VAX" (little-endian)
order.
|
|
V
|
A long in "VAX" (little-endian)
order.
|
|
u
|
A uuencoded string.
|
|
U
|
A Unicode character number. Encodes to UTF-8 internally (or
UTF-EBCDIC in EBCDIC platforms). New in 5.8.
|
|
w
|
A BER compressed integer.
|
|
x
|
A null byte.
|
|
X
|
Back up a byte.
|
|
Z
|
A null terminated (ASCII) string. Will be null padded. New in 5.8.
|
Each character may optionally be followed by a number that gives a
repeat count. Together the character and the repeat count make a
field specifier. Field specifiers may be separated by whitespace,
which will be ignored. With all types except a and
A, the pack function will
gobble up that many values from the list.
Specifying * for the repeat count means to use
however many items are left. The a and
A types gobble just one value, but pack it as a
string of length count, padding with nulls
or spaces as necessary. (When unpacking, A strips
trailing spaces and nulls, but a does not.) Real
numbers (floats and doubles) are in the native machine format only;
due to the multiplicity of floating formats, and the lack of a
standard network representation, no facility for interchange has been
made.
Generally, the same template may also be used in the
unpack function. If you want to join variable
length fields with a delimiter, use the join
function.
Declares that the
rest of the innermost enclosing block, subroutine,
eval, or file belongs to the indicated
namespace. (The scope of a
package declaration is thus the same as the scope
of a local or my declaration.)
All subsequent references to unqualified global identifiers will be
resolved by looking them up in the declared packages symbol table. A
package declaration affects only global
variables—including those you've used
local on—but not lexical variables created
with my.
Using package without an argument is possible, but
since its semantics are unclear, package; has been
depracated in Perl 5.8. If you intend to disallow variables that
aren't fully qualified, use
strict; instead.
Typically, you put a package declaration as the
first thing in a file that will be included by the
require or use operator, but
you can put one anywhere that a statement would be legal. When
defining a class or a module file, it is customary to name the
package the same name as the file, to avoid confusion.
(It's also customary to name such packages beginning
with a capital letter, because lowercase modules are, by convention,
interpreted as pragmas.)
pipe readhandle, writehandle
| |
Opens a pair of
connected pipes. This call is almost always used right before a
fork, after which the pipes reader should close
writehandle, and the writer should close
readhandle. (Otherwise, the pipe
won't indicate end-of-file to the reader when the
writer closes it.) Note that if you set up a loop of piped processes,
deadlock can occur unless you are very careful. In addition, note
that Perl's pipes use standard I/O buffering, so you
may need to set $| on your
writehandle to flush after each output
command, depending on the application. See select
filehandle.
Treats an array like a
stack, popping and returning the last value of the array and
shortening the array by one element. If
array is omitted, the function pops
@ARGV (in the main program) or
@_ (in subroutines).
If there are no elements in the array, pop returns
the undefined value. See also push and
shift. If you want to pop more than one element,
use splice.
Returns the location
in scalar where the last
m//g search over scalarleft off. It returns the offset of the character after the last one
matched. This is the offset where the next m//g
search on that string will start. Remember that the offset of the
beginning of the string is 0. For example:
$grafitto = "fee fie foe foo";
while ($grafitto =~ m/e/g) {
print pos $grafitto, "\n";
}
prints 2, 3,
7, and 11, the offsets of each
of the characters following an "e".
The pos function may be assigned a value to tell
the next m//g where to start.
Prints a string or a
comma-separated list of strings to the specified
filehandle. If no filehandle is given, the
function prints to the currently open filehandle (STDOUT initially).
The function returns 1 if successful,
0 otherwise. filehandlemay be a scalar variable name (unsubscripted), in which case the
variable contains either the name of the actual filehandle or a
reference to a filehandle object from one of the object-oriented
filehandle packages. filehandle may also
be a block that returns either kind of value:
print { $OK ? "STDOUT" : "STDERR" } "stuff\n";
print { $iohandle[$i] } "stuff\n";
If list is also omitted,
$_ is printed. Note that because
print takes a list, anything in the
list is evaluated in list context.
printf [filehandle] format, list
| |
Prints a formatted
string of the elements in list to
filehandle or, if omitted, the currently
selected output filehandle. This is similar to the C
library's printf and
fprintf functions, except that the
* field width specifier is not supported. The
function is exactly equivalent to:
print filehandle sprintf(format, list);
printf and sprintf use the same
format syntax, but sprintf returns only a string;
it doesn't print to a filehandle. The
format string contains text with embedded
field specifiers into which the elements of
list are substituted in order, one per
field. Field specifiers follow the form:
%m.nx
A percent sign begins each field, and x is
the type of field. The optional m gives
the minimum field width for appropriate field types (negative
m left-justifies). The
.n gives the precision for a specific
field type, such as the number of digits after a decimal point for
floating-point numbers, the maximum length for a string, and the
minimum length for an integer.
Field specifiers (x) may be the following:
|
Code
|
Meaning
|
|
%
|
Percent sign
|
|
c
|
Character
|
|
d
|
Decimal integer
|
|
e
|
Exponential format floating-point number
|
|
E
|
Exponential format floating-point number with uppercase E
|
|
f
|
Fixed-point format floating-point number
|
|
g
|
Floating-point number, in either exponential or fixed decimal notation
|
|
G
|
Like g with uppercase E (if applicable)
|
|
ld
|
Long decimal integer
|
|
lo
|
Long octal integer
|
|
lu
|
Long unsigned decimal integer
|
|
lx
|
Long hexadecimal integer
|
|
o
|
Octal integer
|
|
s
|
String
|
|
u
|
Unsigned decimal integer
|
|
x
|
Hexadecimal integer
|
|
X
|
Hexadecimal integer with uppercase letters
|
|
p
|
The Perl value's address in hexadecimal
|
|
n
|
Special value that stores the number of characters output so far into
the next variable in the parameter list
|
Returns the
prototype of a function as a string, or undef if
the function has no prototype. function is
the name of the function or a reference to it.
Pushes
the elements of list onto the end of
array. The length of
array increases by the length of
list. The function returns this new
length. See also pop and
unshift.
q/string/
qq/string/
qx/string/
qw/strings/
| |
Generalized forms of quoting.
q// is equivalent to using single quotes (literal,
no variable interpolation). qq// is equivalent to
double quotes (literal, interpolated). qx// is
equivalent to using backticks for commands (interpolated). And
qw// is equivalent to splitting a single-quoted
string on whitespace.
Returns the
value of expr (or $_ if
not specified) with all non-alphanumeric characters backslashed. This
is the internal function implementing the \Q
escape in interpolative contexts (including double-quoted strings,
backticks, and patterns).
Returns
a random fractional number between 0 and the value
of num. ( numshould be positive.) If num is omitted,
the function returns a value between 0 and
1 (including 0, but excluding
1). See also srand.
To get an integral value, combine this with int,
as in:
$roll = int(rand 6) + 1; # $roll is now an integer between 1 and 6
read filehandle, $var, length, [offset]
| |
Attempts to read
length bytes of data into variable
var from the specified
filehandle. The function returns the
number of bytes actually read, or 0 at
end-of-file. It returns the undefined value on error.
var will grow or shrink to the length
actually read. The offset, if specified,
says where in the variable to start putting bytes, so that you can do
a read into the middle of a string.
To copy data from the filehandle FROM into the filehandle TO, you
could say:
while (read FROM, $buf, 16384) {
print TO $buf;
}
Note that the opposite of read is simply
print, which already knows the length of the
string you want to write and can write a string of any length.
Perl's read function is actually
implemented in terms of standard I/O's
fread function, so the actual
read system call may read more than
length bytes to fill the input buffer, and
fread may do more than one system
read to fill the buffer. To gain greater control,
specify the real system call using sysread.
Reads directory
entries from a directory handle opened by opendir.
In scalar context, this function returns the next directory entry, if
any; otherwise, it returns an undefined value. In list context, it
returns all the rest of the entries in the directory, which will of
course be a null list if there are none.
Reads a line or
lines from the specified filehandle. (A
typeglob of the filehandle name should be supplied.) Returns one line
per call in a scalar context. Returns a list of all lines until the
end-of-file in list context.
Returns the name
of a file pointed to by the symbolic link
name. nameshould evaluate to a filename, the last component of which is a
symbolic link. If it is not a symbolic link, or if symbolic links are
not implemented, or if a system error occurs, the undefined value is
returned, and you should check the error code in
$!. If name is omitted,
the function uses $_.
Executes
cmd as a system command and returns the
collected standard output of the command. In a scalar context, the
output is returned as a single, possibly multiline, string. In list
context, a list of output lines is returned.
recv socket, $var, len, flags
| |
Receives a message on
a socket. It attempts to receive len bytes
of data into variable var from the
specified socket filehandle. The function
returns the address of the sender, or the undefined value if
there's an error. varwill grow or shrink to the length actually read. The function takes
the same flags as the recv(2) system call.
Restarts a loop block
identified by label without reevaluating
the conditional. The continue block, if any, is
not executed. If the label is omitted, the
command refers to the innermost enclosing loop.
Returns a
string indicating the type of the object referenced if
var is a reference; returns the null
string otherwise. Built-in types include:
REF
SCALAR
ARRAY
HASH
CODE
GLOB
If the referenced object has been blessed into a package, that
package name is returned instead. You can think of
ref as a
"typeof" operator.
Changes the name of
a file from oldname to
newname. It returns 1
for success, 0 otherwise (and puts the error code
into $!). It will not work across filesystem
boundaries. If there is already a file named
newname, it will be destroyed.
require filename
require num
require package
| |
Asserts a dependency
of some kind depending on its argument. (If an argument is not
supplied, $_ is used.)
If the argument is a string filename, this
function includes and executes the Perl code found in the separate
file of that name. This is similar to performing an
eval on the contents of the file, except that
require checks to see that the library file has
not been included already. The function also knows how to search the
include path stored in the @INC array.
If requires argument is a number
num, the version number of the currently
executing Perl binary (as known by $]) is compared
to num. If it is smaller, execution is
immediately aborted. Thus, a script that requires Perl version 5.003
can have as its first line:
require 5.003;
and earlier versions of Perl will abort. If require's argument is a
package name, require assumes an automatic
.pm suffix, making it easy to load standard
modules. This is like use, except that it happens
at runtime, not compile time, and the import
routine is not called.
Used
at the top of a loop or in a continue block at the
end of a loop to clear global variables or reset
?? searches so they work again.
expr is a list of single characters
(hyphens are allowed for ranges). All scalar variables, arrays, and
hashes beginning with one of those letters are reset to their
pristine state. If expr is omitted,
one-match searches
( ?PATTERN?)
are reset to match again. The function resets variables or searches
for the current package only. It always returns 1.
Lexical variables (created by my) are not
affected. Use of reset is vaguely deprecated.
Returns from a
subroutine (or eval) with the value of
expr. (In the absence of an explicit
return, the value of the last expression evaluated
is returned.) Use of return outside of a
subroutine or eval will result in a fatal error.
The supplied expression will be evaluated in the context of the
subroutine invocation. That is, if the subroutine was called in a
scalar context, expr is also evaluated in
scalar context. If the subroutine was invoked in a list context, then
expr is also evaluated in list context and
can return a list value. A return with no argument returns the
undefined value in scalar context and a null list in list context.
The context of the subroutine call can be determined from within the
subroutine by using the (misnamed) wantarray
function.
Returns a list
value consisting of the elements of listin the opposite order. This is fairly efficient because it just swaps
the pointers around. In scalar context, the function concatenates all
the elements of list together and returns
the reverse of this character by character.
Sets the current
position to the beginning of the directory for the
readdir routine on
dirhandle. The function may not be
available on all machines that support readdir.
rindex str, substr, [position]
| |
Works just like
index except that it returns the position of the
last occurrence of substr in
str (a reverse index).
The function returns -1 if not found.
position, if specified, is the rightmost
position that may be returned, i.e., how far in the string the
function can search.
Deletes the
directory specified by name if it is
empty. If it succeeds, it returns 1; otherwise, it
returns 0 and puts the error code into
$!. If name is omitted,
the function uses $_.
Forces an expression
expr to be evaluated in scalar context.
seek filehandle, offset, whence
| |
Positions the file pointer
for filehandle, just like the
fseek(3) call of standard I/O. The first position
in a file is at offset 0, not offset
1, and offsets refer to byte positions, not line
numbers. The function returns 1 upon success,
0 otherwise. For handiness, the function can
calculate offsets from various file positions for you. The value of
whence specifies which of three file
positions your offset is relative to:
0, the beginning of the file;
1, the current position in the file; or
2, the end of the file.
offset may be negative for a
whence of 1 or
2.
Sets the current
position for the readdir routine on
dirhandle. posmust be a value returned by telldir. This function
has the same caveats about possible directory compaction as the
corresponding system library routine.
Returns the currently
selected output filehandle, and if
filehandle is supplied, sets that as the
current default filehandle for output. This has two effects. First, a
write or a print without a
filehandle argument will default to this
filehandle. Second, special variables
related to output will refer to this output filehandle.
select rbits, wbits, ebits, timeout
| |
The four-argument select operator is totally
unrelated to the previously described select
operator. This operator is for discovering which (if any) of your
file descriptors are ready to do input or output, or to report an
exceptional condition. It calls the select(2)
system call with the bitmasks you've specified,
which you can construct using fileno and
vec, like this:
$rbits = $wbits = $ebits = "";
vec($rbits, fileno(STDIN), 1) = 1;
vec($wbits, fileno(STDOUT), 1) = 1;
$ein = $rin | $win;
The select call blocks until one or more file
descriptors is ready for reading, writing, or reporting an error
condition. timeout is given in seconds and
tells select how long to wait.
semctl id, semnum, cmd, arg
| |
Calls the System V
IPC system call semctl(2). If
cmd is &IPC_STAT or
&GETALL, then argmust be a variable which will hold the returned
semid_ds structure or semaphore value array. The
function returns like ioctl: the undefined value
for error, 0 but true for zero, or the actual
return value otherwise. On error, it puts the error code into
$!. Before calling, you should say:
require "ipc.ph";
require "sem.ph";
This function is available only on machines supporting System V IPC.
semget key, nsems, size, flags
| |
Calls the System V
IPC system call semget(2). The function returns
the semaphore ID, or the undefined value if there is an error. On
error, it puts the error code into $!. Before
calling, you should say:
require "ipc.ph";
require "sem.ph";
This function is available only on machines supporting System V IPC.
Calls the System V
IPC system call semop(2) to perform semaphore
operations such as signaling and waiting.
opstring must be a packed array of
semop structures. You can make each
semop structure by saying pack('s*',
$semnum, $semop, $semflag). The number of semaphore
operations is implied by the length of
opstring. The function returns true if
successful or false if there is an error. On error, it puts the error
code into $!. Before calling, you should say:
require "ipc.ph";
require "sem.ph";
This function is available only on machines supporting System V IPC.
send socket, msg, flags, [dest]
| |
Sends a
message msg on a socket. It takes the same
flags as the system call of the same name (see
send(2)). On unconnected sockets, you must specify
a destination dest to send to, in which
case send works like sendto(2).
The function returns the number of bytes sent, or the undefined value
if there is an error. On error, it puts the error code into
$!.
Some non-Unix systems improperly treat sockets as different objects
than ordinary file descriptors, which means that you must always use
send and recv on sockets rather
than the standard I/O operators.
Opens the hosts
file (usually /etc/hosts on Unix systems) and
resets the "current" selection to
the top of the file. stayopen, if nonzero,
keeps the file open across calls to other functions. Not implemented
on Win32 systems.
Opens the groups
file (usually /etc/group on Unix systems) and
resets the top of the file as the starting point for any read and/or
write functions on the file (with the proper permissions). This
function will reset the getgrent function back to
retrieve group entries from the start of the group file. Not
implemented on Win32 systems.
Opens the
networks file (usually /etc/group) and resets
the "current" selection to the top
of the file. stayopen, if nonzero, keeps
the file open across calls to other functions. Not implemented on
Win32 systems.
Sets the current
process group pgrp for the specified
pid (use a pidof 0 for the current process). Invoking
setpgrp will produce a fatal error if used on a
machine that doesn't implement
setpgrp(2). Some systems will ignore the arguments
you provide and always do setpgrp(0, $$).
Fortunately, those are the arguments you usually provide. (For better
portability, use the setpgid( ) function in the
POSIX module, or if you're really just trying to
daemonize your script, consider the POSIX::setsid(
) function as well.)
setpriority which, who, priority
| |
Sets the
current priority for a process, a process
group, or a user. which must indicate one
of these types: PRIO_PROCESS,
PRIO_PGRP, or PRIO_USER.
who, therefore, identifies the specific
process, process group, or user with its ID.
priority is an integer number that will be
added to or subtracted from the current priority; the lower the
number, the higher the priority. The interpretation of a given
priority may vary from one operating system to the next. See setpriority on your system. Invoking
setpriority will produce a fatal error if used on
a machine that doesn't implement
setpriority.
Opens the
prototypes file (usually /etc/prototypes) and
resets the "current" selection to
the top of the file. stayopen, if nonzero,
keeps the file open across calls to other functions. Not implemented
on Win32 systems.
Opens the
password file (usually /etc/passwd) and resets
the top of the file as the starting point for any read and/or write
functions on the file (with the proper permissions). This function
will reset the getpwent function back to retrieve
group entries from the start of the group file. Not implemented on
Win32 systems.
Opens the
services file (usually /etc/services) and resets
the "current" selection to the top
of the file. stayopen, if nonzero, keeps
the file open across calls to other functions. Not implemented on
Win32 systems.
setsockopt socket, level, optname, optval
| |
Sets the socket
option requested ( optname) to the value
optval. The function returns undefined if
there is an error. optval may be specified
as undef if you don't want to
pass an argument. level specifies the
protocol type used on the socket.
Removes the first
value of @array and
returns it, shortening the array by 1 and moving everything down. If
there are no elements in the array, the function returns the
undefined value. If
@array is omitted, the
function shifts @ARGV (in the main program), or
@_ (in subroutines). See also
unshift, push,
and pop.
shift and unshift functions do
the same thing to the left end of an array that
pop and push do to the right
end.
Calls the System V
IPC system call, shmctl(2), for performing
operations on shared memory segments. If
cmd is &IPC_STAT,
then arg must be a variable that will hold
the returned shmid_ds structure. The function
returns like ioctl: the undefined value for error,
"0 but true" for 0, or the
actual return value otherwise. On error, it puts the error code into
$!. Before calling, you should say:
require "ipc.ph";
require "shm.ph";
This function is available only on machines supporting System V IPC.
Calls the System V
IPC system call, shmget(2). The function returns
the shared memory segment ID, or the undefined value if there is an
error. On error, it puts the error code into $!.
Before calling, you should say:
require "ipc.ph";
require "shm.ph";
This function is available only on machines supporting System V IPC.
shmread id, var, pos, size
| |
Reads from the
shared memory segment id starting at
position pos for size
size (by attaching to it, copying out, and
detaching from it). var must be a variable
that will hold the data read. The function returns true if successful
or false if there is an error. On error, it puts the error code into
$!. This function is available only on machines
supporting System V IPC.
shmwrite id, string, pos, size
| |
Writes to the
shared memory segment ID starting at position
pos for size
size (by attaching to it, copying in, and
detaching from it). If string is too long,
only size bytes are used; if
string is too short, nulls are written to
fill out size bytes. The function returns
true if successful or false if there is an error. On error, it puts
the error code into $!. This function is available
only on machines supporting System V IPC.
Shuts down a
socket connection in the manner indicated by
how. If how is
0, further receives are disallowed. If
how is 1, further sends
are disallowed. If how is
2, everything is disallowed.
This function will not shut down your system; you'll
have to execute an external program to do that. See
system.
Returns
the sine of num (expressed in radians). If
num is omitted, it returns the sine of
$_.
Causes the script to
sleep for n seconds, or forever if no
argument is given. It may be interrupted by sending the process a
SIGALRM. The function returns the number of
seconds actually slept. On some systems, the function sleeps till the
"top of the second." So, for
instance, a sleep 1 may sleep anywhere from 0 to 1
second, depending on when in the current second you started sleeping.
socket socket, domain, type, protocol
| |
Opens a socket of the
specified kind and attaches it to filehandle
socket. domain,
type, and
protocol are specified the same as for
socket(2). Before using this function, your
program should contain the line:
use Socket;
This setting gives you the proper constants. The function returns
true if successful.
socketpair sock1, sock2, domain, type, prtcl
| |
Creates an
unnamed pair of sockets in the specified
domain and of the specified
type. domain,
type, and
protocol are specified the same as for
socketpair(2). If socketpair is
unimplemented, invoking this function yields a fatal error. The
function returns true if successful.
This function is typically used just before a
fork. One of the resulting processes should close
sock1, and the other should close
sock2. You can use these sockets
bidirectionally, unlike the filehandles created by the
pipe function.
Sorts a
list and returns the sorted list value. By
default (without a code argument), it
sorts in standard string comparison order (undefined values sorting
before defined null strings, which sort before everything else).
code, if given, may be the name of a
subroutine or a code block (anonymous subroutine) that defines its
own comparison mechanism for sorting elements of
list. The routine must return to the
sort function an integer less than, equal to, or
greater than 0, depending on how the elements of the list will be
ordered. (The handy <=> and
cmp operators can be used to perform three-way
numeric and string comparisons.)
The normal calling code for subroutines is bypassed, with the
following effects: the subroutine may not be a recursive subroutine,
and the two elements to be compared are passed into the subroutine as
$a and $b, not via
@_. The variables $a and
$b are passed by reference, so
don't modify them in the subroutine.
Do not declare $a and $b as
lexical variables (with my). They are package
globals (though they're exempt from the usual
restrictions on globals when you're using
use strict). However, you do
need to make sure your sort routine is in the same
package, or else you must qualify $a and
$b with the package name of the caller.
In versions preceding 5.005, Perl's
sort is implemented in terms of
C's qsort(3) function. Some
qsort(3) versions will dump core if your sort
subroutine provides inconsistent ordering of values. As of 5.005,
however, this is no longer true.
splice @array, pos, [n], [list]
| |
Removes
n number of elements from
@array starting at
position pos, replacing them with the
elements of list, if provided. The
function returns the elements removed from the array. The array grows
or shrinks as necessary. If n is omitted,
the function removes everything from posonward.
split /pattern/, string, [limit]
| |
Scans a
string for delimiters that match
pattern and splits the string into a list
of substrings, returning the resulting list value in list context, or
the count of substrings in scalar context. The delimiters are
determined by repeated pattern matching, using the regular expression
given in pattern, so the delimiters may be
of any size and need not be the same string on every match. If the
pattern doesn't match at
all, split returns the original string as a single
substring. If it matches once, you get two substrings, and so on.
If limit is specified and is not negative,
the function splits into no more than that many fields. If
limit is negative, it is treated as if an
arbitrarily large limit has been
specified. If limit is omitted, trailing
null fields are stripped from the result (which potential users of
pop would do well to remember). If
string is omitted, the function splits the
$_ string. If patternis also omitted, the function splits on whitespace,
/\s+/, after skipping any leading whitespace.
If the pattern contains parentheses, then
the substring matched by each pair of parentheses is included in the
resulting list, interspersed with the fields that are ordinarily
returned. Here's a simple case:
split /([-,])/, "1-10,20";
This produces the list value: (1, '-', 10, ',', 20)
Returns a string
formatted by the printf conventions. The
format string contains text with embedded
field specifiers into which the elements of
list are substituted, one per field. Field
specifiers are roughly of the form:
%m.nx
in which m and
n are optional sizes with interpretation
that depends on the type of field, and xis one of the following:
|
Code
|
Meaning
|
|
%
|
Percent sign
|
|
c
|
Character
|
|
d
|
Decimal integer
|
|
e
|
Exponential format floating-point number
|
|
E
|
Exponential format floating-point number with uppercase E
|
|
f
|
Fixed-point format floating-point number
|
|
g
|
Floating-point number, in either exponential or fixed decimal notation
|
|
G
|
Like g with uppercase E (if applicable)
|
|
ld
|
Long decimal integer
|
|
lo
|
Long octal integer
|
|
lu
|
Long unsigned decimal integer
|
|
lx
|
Long hexadecimal integer
|
|
o
|
Octal integer
|
|
s
|
String
|
|
u
|
Unsigned decimal integer
|
|
x
|
Hexadecimal integer
|
|
X
|
Hexadecimal integer with uppercase letters
|
|
p
|
The Perl value's address in hexadecimal
|
|
n
|
Special value that stores the number of characters output so far into
the next variable in the parameter list.
|
m is typically the minimum length of the
field (negative for left-justified), and nis precision for exponential formats and the maximum length for other
formats. Padding is typically done with spaces for strings and zeroes
for numbers. The * character as a length specifier
is not supported.
Returns the square
root of num, or $_ if
omitted. For other roots such as cube roots, you can use the
** operator to raise something to a fractional
power.
Sets the random
number seed for the rand operator so that
rand can produce a different sequence each time
you run your program. If expr is omitted,
a default seed is used that is a mix of difficult-to-predict,
system-dependent values. If you call rand and
haven't called srand,
rand calls srand with the
default seed.
Returns
a 13-element list giving the statistics for a
file, indicated by either a filehandle or
an expression that gives its name. It's typically
used as follows:
($dev,$ino,$mode,$nlink,$uid,$gid,$rdev,$size,
$atime,$mtime,$ctime,$blksize,$blocks)
= stat $filename;
Not all fields are supported on all filesystem types. Here are the
meanings of the fields:
|
Field
|
Meaning
|
|
dev
|
Device number of filesystem
|
|
ino
|
Inode number
|
|
mode
|
File mode (type and permissions)
|
|
nlink
|
Number of (hard) links to the file
|
|
uid
|
Numeric user ID of file's owner
|
|
gid
|
Numeric group ID of file's owner
|
|
rdev
|
The device identifier (special files only)
|
|
size
|
Total size of file, in bytes
|
|
atime
|
Last access time since the epoch
|
|
mtime
|
Last modification time since the epoch
|
|
ctime
|
Inode change time (not creation time!) since the epoch
|
|
blksize
|
Preferred blocksize for file system I/O
|
|
blocks
|
Actual number of blocks allocated
|
$dev and $ino, taken together,
uniquely identify a file. The $blksize and
$blocks are likely defined only on BSD-derived
filesystems. The $blocks field (if defined) is
reported in 512-byte blocks. Note that $blocks*512
can differ greatly from $size for files containing
unallocated blocks, or "holes,"
which aren't counted in $blocks.
If stat is passed the special filehandle
consisting of an underline, no actual stat is
done, but the current contents of the stat
structure from the last stat or
stat-based file test (the -x
operators) is returned.
This function takes
extra time to study scalar( $_ if unspecified) in anticipation of doing many
pattern matches on the string before it is next modified. You may
have only one study active at a time—if you
study a different scalar, the first is
"unstudied."
sub name [proto] {block}
sub [proto] name
| |
Declares
and defines a subroutine. name is the name
given to the subroutine; block is the code
that will be executed when the subroutine is called. Without
block, this statement declares only a
subroutine, which must be defined at a later point in your program.
proto is a sequence of symbols that places
constraints on the arguments that the subroutine will receive. See
Section 4.7, "Subroutines".
substr string, pos, [n, replacement]
| |
Extracts and
returns a substring n characters long,
starting at character position pos, from a
given string. If
pos is negative, the substring starts that
far from the end of the string instead. If
n is omitted, everything to the end of the
string is returned. If n is negative, the
length is calculated to leave that many characters off the end of the
string.
You can use substr( ) as an lvalue—replacing
the delimited substring with a new string—if
string is given as an lvalue. You can also
specify a replacement string in the fourth
parameter to replace the substring. The original extracted substring
is still returned.
Creates a new
filename symbolically linked to the old filename. The function
returns 1 for success, 0
otherwise. On systems that don't support symbolic
links, it produces a fatal error at runtime. Be careful if you supply
a relative symbolic link, since it will be interpreted relative to
the location of the symbolic link itself, not your current working
directory. See also link and
readlink.
Calls the system
call specified as the first element of the list, passing the
remaining elements as arguments to the system call. The function
produces a fatal error if syscall(2) is
unimplemented. The arguments are interpreted as follows: if a given
argument is numeric, the argument is passed as a C integer. If not, a
pointer to the string value is passed.
sysopen filehandle, filename, mode, [perms]
| |
Opens the file
given by filename and associates it with
filehandle. This function calls
open(2) with the parameters
filename, mode,
and perms.
The possible values and flag bits of the
mode parameter are system-dependent; they
are available via the Fcntl library module. However, for historical
reasons, some values are universal: 0 means
read-only, 1 means write-only, and
2 means read/write.
If the file named by filename does not
exist, and sysopen creates it (typically because
mode includes the
O_CREAT flag), then the value of
perms specifies the permissions of the
newly created file. If perms is omitted,
the default value is 0666, which allows read and
write for all. This default is reasonable. See
umask.
The FileHandle module provides a more object-oriented approach to
sysopen. See also open.
sysread filehandle, scalar, length, [offset]
| |
Reads
length bytes of data into variable
scalar from the specified
filehandle. The function returns the
number of bytes actually read, or 0 at
end-of-file. It returns the undefined value on error.
scalar will grow or shrink to the length
actually read. The offset, if specified,
says where in the string to start putting the bytes so you can read
into the middle of a string that's being used as a
buffer. You should be prepared to handle the problems (such as
interrupted system calls) that standard I/O normally handles for you.
sysseek filehandle, offset, whence
| |
A variant of
seek( ) that sets and gets the
file's system read/write position using the
lseek(2) system call. It's the
only reliable way to seek before a sysread( ) or
syswrite( ). Returns the new position, or
undef on failure. Arguments are the same as for
seek.
Executes any
program on the system for you. It does exactly the same thing as
exec list except that
it does a fork first, and then, after the
exec, it waits for the execed
program to complete. That is, it runs the program for you and returns
when it's done, unlike exec,
which never returns (if it succeeds). Note that argument processing
varies depending on the number of arguments, as described for
exec. The return value is the exit status of the
program as returned by the wait(2) call. To get
the actual exit value, divide by 256. (The lower eight bits are set
if the process died from a signal.) See exec.
syswrite filehandle, scalar, length, [offset]
| |
Writes
length bytes of data from variable
scalar to the specified
filehandle. The function returns the
number of bytes actually written, or the undefined value on error.
You should be prepared to handle the problems that standard I/O
normally handles for you, such as partial writes. The
offset, if specified, says where in the
string to start writing from, in case you're using
the string as a buffer, for instance, or need to recover from a
partial write.
Do not mix calls to print (or
write) and syswrite on the same
filehandle unless you really know what you're doing.
Returns
the current file position (in bytes, 0-based) for
filehandle. This value is typically fed to
the seek function at a future time to get back to
the current position. If filehandle is
omitted, the function returns the position of the last file read.
File positions are only meaningful on regular files. Devices, pipes,
and sockets have no file position.
Returns the
current position of the readdir routines on a
directory handle ( dirhandle). This value
may be given to seekdir to access a particular
location in a directory. The function has the same caveats about
possible directory compaction as the corresponding system library
routine. This function may not be implemented everywhere that
readdir is. Even if it is, no calculation may be
done with the return value. It's just an opaque
value, meaningful only to seekdir.
tie variable, classname, list
| |
Binds a
variable to a package class,
classname, that will provide the
implementation for the variable. Any additional arguments
( list) are passed to the
"new" method of the class (meaning
TIESCALAR, TIEARRAY, or
TIEHASH). Typically, these are arguments that
might be passed to the dbm_open(3) function of C,
but this is package-dependent. The object returned by the
"new" method is also returned by
the tie function, which can be useful if you want
to access other methods in classname. (The
object can also be accessed through the tied
function.)
A class implementing a hash should provide the following methods: TIEHASH $class, LIST
DESTROY $self
FETCH $self, $key
STORE $self, $key, $value
DELETE $self, $key
EXISTS $self, $key
FIRSTKEY $self
NEXTKEY $self, $lastkey
A class implementing an ordinary array should provide the following
methods:
TIEARRAY $classname, LIST
DESTROY $self
FETCH $self, $subscript
STORE $self, $subscript, $value
A class implementing a scalar should provide the following methods: TIESCALAR $classname, LIST
DESTROY $self
FETCH $self,
STORE $self, $value
Unlike dbmopen, the tie
function will not use or
require a module for you—you need to do that
explicitly yourself.
Returns a reference
to the object underlying variable (the
same value that was originally returned by the tie
call that bound the variable to a package). It returns the undefined
value if variable isn't
tied to a package. So, for example, you can use:
ref tied %hash
to find out which package your hash is currently tied to.
Returns
the number of non-leap seconds since January 1, 1970, UTC. The
returned value is suitable for feeding to gmtime
and localtime, for comparison with file
modification and access times returned by stat,
and for feeding to utime.
Returns a
four-element list giving the user and system CPU times, in seconds
(possibly fractional), for this process and for the children of this
process:
($user, $system, $cuser, $csystem) = times;
For example, to time the execution speed of a section of Perl code: $start = (times)[0];
...
$end = (times)[0];
printf "that took %.2f CPU seconds\n", $end - $start;
Truncates a
file (given as a filehandle or by name) to
the specified length. The function produces a fatal error if
truncate(2) or an equivalent
isn't implemented on your system.
Returns an
uppercased version of string (or
$_ if string is
omitted). This is the internal function implementing the
\U escape in double-quoted strings. POSIX
setlocale(3) settings are respected.
Returns a version
of string (or $_ if
string is omitted) with the first
character uppercased. This is the internal function that implements
the \u escape in double-quoted strings. POSIX
setlocale(3) settings are respected.
Sets the umask for
the process to expr and returns the old
one. (The umask tells Unix which permission bits to disallow when
creating a file.) If expr is omitted, the
function merely returns the current umask. For example, to ensure
that the "other" bits are turned on
and that the "user" bits are turned
off, try something like:
umask((umask( ) & 077) | 7);
Undefines the value
of expr, which must be an lvalue. Use only
on a scalar value, an entire array or hash, or a subroutine name
(using the & prefix). Any storage associated
with the object will be recovered for reuse (though not returned to
the system, for most versions of Unix). The undef
function will probably not do what you expect on most special
variables. The function always returns the undefined value. This is
useful because you can omit the expr, in
which case nothing gets undefined, but you still get an undefined
value that you could, for instance, return from a subroutine to
indicate an error.
You may use undef as a placeholder on the left
side of a list assignment, in which case the corresponding value from
the right side is simply discarded. Apart from that, you may not use
undef as an lvalue.
Deletes a list of
files. (Under Unix, it will remove a link to a file, but the file may
still exist if another link references it.) If
list is omitted, it unlinks the file given
in $_. The function returns the number of files
successfully deleted. Note that unlink will not
delete directories unless you are the superuser and the
-U flag is supplied to Perl. Even if these
conditions are met, be warned that unlinking a directory can inflict
serious damage on your filesystem. Use rmdir
instead.
Takes a string
( string) representing a data structure and
expands it into a list value, returning the list value.
( unpack does the reverse of
pack.) In a scalar context, it can be used to
unpack a single value. The template has
much the same format as the pack function—it
specifies the order and type of the values to be unpacked. See
pack for a more detailed description of
template.
Prepends the
elements of list to the front of the array
and returns the new number of elements in the array.
Breaks the binding
between a variable and a package. See tie.
use Module list
use version
use Module version list
| |
If the
first argument is a number, it is treated as a version number. If the
version of Perl is less than version, an
error message is printed and Perl exits. This provides a way to check
the Perl version at compilation time instead of waiting for runtime.
If version appears between
Module and
list, then use calls
the version method in class
Module with
version as an argument.
Otherwise, use imports some semantics into the
current package from the named Module,
generally by aliasing certain subroutine or variable names into your
package. It is exactly equivalent to the following:
BEGIN { require Module; import Module list; }
The BEGIN forces the require
and import to happen at compile time. The
require makes sure that the module is loaded into
memory if it hasn't been yet. The
import is not a built-in
function—it's just an ordinary static method
call into the package named by Module that
tells the module to import the list of features back into the current
package. The module can implement its import method any way it likes,
though most modules just choose to derive their import method via
inheritance from the Exporter class defined in the Exporter module.
If you don't want your namespace altered, explicitly
supply an empty list:
use Module ( );
This is exactly equivalent to the following: BEGIN { require Module; }
Because this is a wide-open interface, pragmas (compiler directives)
are also implemented this way. (See Chapter 8, "Standard Modules" for
descriptions of the currently implemented pragmas.) These
pseudomodules typically import semantics into the current block
scope, unlike ordinary modules, which import symbols into the current
package. (The latter are effective through the end of the file.)
There's a corresponding declaration,
no, that
"unimports" any meanings originally
imported by use but have since become less
important:
no integer;
no strict 'refs';
utime atime, mtime, files
| |
Changes the access
time ( atime) and modification time
( mtime) on each file in a list of
files. The first two elements must be the
numerical access and modification times,
in that order. The function returns the number of files successfully
changed. The inode change time of each file is set to the current
time. Here's an example of a
utime command:
#!/usr/bin/perl
$now = time;
utime $now, $now, @ARGV;
To read the times from existing files, use stat.
Returns a list
consisting of all the values of the named hash. The values are
returned in an apparently random order, but it is the same order that
the keys or each function would
produce on the same hash. To sort the hash by its values, see the
example under keys. Note that using
values on a hash bound to a very large DBM file
will produce a very large list, causing you to have a very large
process, and leaving you in a bind. You might prefer to use the
each function, which will iterate over the hash
entries one by one without reading them all into a single list.
Treats a
string as a vector of unsigned integers
and returns the value of the element specified by
offset and
bits. The function may also be assigned
to, which causes the element to be modified. The purpose of the
function is to provide compact storage of lists of small integers.
The integers may be very small—vectors can hold numbers that
are as small as one bit, resulting in a bitstring.
The offset specifies the number of
elements to skip over to find the one you want.
bits is the number of bits per element in
the vector, so each element can contain an unsigned integer in the
range
0..(2**bits)-1.
bits must be one of 1,
2, 4, 8,
16, or 32. As many elements as
possible are packed into each byte, and the ordering is such that
vec($vectorstring,0,1) is guaranteed to go into
the lowest bit of the first byte of the string. To find the position
of the byte in which an element will be placed, you have to multiply
the offset by the number of elements per
byte. When bits is 1,
there are eight elements per byte. When
bits is 2, there are
four elements per byte. When bits is
4, there are two elements (called nybbles) per
byte. And so on.
Regardless of whether your system is big-endian or little-endian,
vec($foo, 0, 8) always refers to the first byte of
string $foo. See select for
examples of bitmaps generated with vec.
Vectors created with vec can also be manipulated
with the logical operators |,
&, ^, and
~, which will assume a bit vector operation is
desired when the operands are strings. A bit vector
(bits == 1) can be
translated to or from a string of 1s and
0s by supplying a b* template
to unpack or pack. Similarly, a
vector of nybbles (bits ==
4) can be translated with an h*
template.
Waits
for a child process to terminate and returns the pid of the deceased
process, or -1 if there are no child processes.
The status is returned in $?. If you get zombie
child processes, you are probably calling either this function or
waitpid. A common strategy to avoid such zombies
is:
$SIG{CHLD} = sub { wait };
If you expected a child and didn't find it, you
probably had a call to system, a close on a pipe,
or backticks between the fork and the
wait. These constructs also do a
wait(2) and may have harvested your child process.
Use waitpid to avoid this problem.
Waits for a
particular child process pid to terminate
and returns the pid when the process is dead, or
-1 if there are no child processes or if the
flags specify nonblocking and the process
isn't dead yet. The status of the dead process is
returned in $?. To get valid flag values, do the
following:
use POSIX "sys_wait_h";
On systems that implement neither the waitpid(2)
nor the wait4(2) system call,
flags may be specified only as
0. In other words, you can wait for a specific
pid, but you can't do it
in nonblocking mode.
Returns true if
the context of the currently executing subroutine is looking for a
list value. The function returns false if the context is looking for
a scalar. May also return undef if a
subroutine's return value will not be used at all.
Produces a message on
STDERR just like die, but doesn't
try to exit or throw an exception. For example:
warn "Debug enabled" if $debug;
If the message supplied is null, the message
"Something's wrong" is used. As
with die, a message not ending with a newline will
have file and line number information automatically appended. The
warn operator is unrelated to the
-w switch.
Writes a formatted record
(possibly multiline) to the specified
filehandle, using the format associated
with that filehandle (see Section 4.11, "Unicode"). By default,
the format for a filehandle is the one having the same name as the
filehandle.
If filehandle is unspecified, output goes
to the current default output filehandle, which starts as STDOUT but
may be changed by the select operator. If the
filehandle is an expression, then the
expression is evaluated to determine the actual
filehandle at runtime.
Note that write is not the opposite of
read. Use print for simple
string output. If you want to bypass standard I/O, see
syswrite.
 |  |  | | 5. Function Reference |  | 6. Debugging |

Copyright © 2002 O'Reilly & Associates. All rights reserved.
|