
 |  |
20.2. Computing 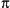 with Parallel Message Passing
with Parallel Message Passing
Scientists demand the most powerful computing machinery available, whether they model global atmospheric conditions, decipher the human genome, study viscous fluid dynamics, visualize plasmas in 3 dimensions, or vibrate strings in 14. Besides tons of disk space (perhaps a terabyte for /tmp alone) and tremendous I/O and memory bandwidth, they want raw CPU power. Since no single CPU will ever suffice, scientists work with vector and massively parallel computers.
In parallel programming, we try to
divide the work of a sequential program into portions so that many
processors can work on the problem simultaneously. For example, this
code[55] computes by integrating the
function 4 / (1 + x2) in the range
-.5 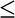 x < .5:
x < .5:
[55] This is a Perl version of the C example from the public domain MPICH distribution, available at http://www-unix.mcs.anl.gov/mpi/mpich/download.html. Notice two optimizations: the factor $h is turned into multiplication because it's faster than division; likewise, multiplying $x by itself is faster than exponentiation.
my $intervals = 1_000;
my $h = 1.0 / $intervals;
my $sum = 0.0;
for(my $i = 1; $i <= $intervals; $i++) {
my $x = $h * ($i - 0.5);
$sum += 4.0 / (1.0 + $x*$x);
}
my $pi = $h * $sum;The variable $intervals defines the granularity of
the summation and, hence, the accuracy of the computation. To get a
good result, the interval must be very finely divided, which, of
course, increases the program's running time. But suppose we
parcel out the work to two processors, with each one integrating only
half of the curve? If we then add the two partial sums, the value of
is the same, but the computational wall-clock time is halved.
In fact, putting 10 processors to work completes the job an order of
magnitude faster, because this problem scales well.
20.2.1. The Message Passing Protocol
Writing parallel code
requires some mechanism through which the processors can communicate
with each other. Generally, there's a master processor that
sets initial conditions and, later, collects results. In our case,
assume the master is responsible for telling the slave processors
which portion of the curve they are to integrate, collecting the
slaves' partial sums, adding them together, and reporting the
value of .
To implement this communication, we use a message passing scheme very similar to that found on parallel supercomputers. The big iron might use shared memory or high-speed interconnects to transfer megabytes of data, but this example just sends a few scalars back and forth.
It's unlikely you have access to a parallel computer, so we'll make do using multiple processes on a single CPU. The first process, the master, creates a MainWindow, menubar, and two Entry widgets that select the number of intervals and slave processes, as shown in Figure 20-2. It's also responsible for starting the helpers, sending them their starting values, and collecting their results.
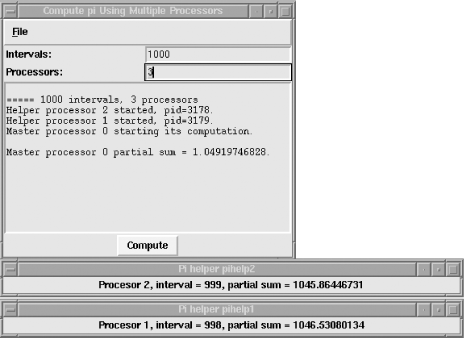
Figure 20-2. Computing pi with a master and two slave processors
Each slave opens a MainWindow and populates it with a Label widget displaying intermediate results. When a slave finishes, it sends its result to the master.
With true message passing, there's a blocking receive command that reads the message queue and synchronizes the processors. There's nothing like that in Tk, but we can simulate it using tkwait variable, the Tcl way of saying waitVariable, which logically suspends a processor until a variable's value changes. As long as each processor understands the protocol—when and what to send, and when and what variable to wait for—we're okay. Protocol details follow in the next two sections, during the examination of the Tcl/Tk code.
20.2.2. Tcl/Tk Slave Processor Code
At less than 25 lines, the slave code pihelp.tcl makes a good starting point. It's simple, concise, and maps well to Perl/Tk, so you should follow it easily. I think you'll find learning a little Tcl/Tk to be worthwhile, and you can add another bullet to your resumé. Plus, there's a lot of Tcl/Tk code out there, and this small diversion might assist you when doing a Perl/Tk port.
wm title . "Pi helper [tk appname]" wm iconname . "pihelp"
In Tcl/Tk, strings identify widgets, not object references, and the MainWindow is always . (dot). These two window manager commands initialize the MainWindow's title and icon name. Tcl has double-quote interpolation just like Perl, as well ascommand substitution, indicated by square brackets. Here, Tcl fetches the program's application name before interpolating the title string and assigning it to the MainWindow.
set status "" label .l -textvariable status -width 80 pack .l
Tcl has scalars just like Perl, and set assigns values to those variables. Notice that, as in shell programming, there's no leading $. The $ is used only when it's time to evaluate a variable. We then pack an 80-character Label widget, .l, a child of the MainWindow, with an associated text variable.
#set numprocs 0 #set proc 0 #set intervals 0 tkwait variable intervals
These three set commands are commented out, because it's up to the master processor to initialize these variables (we need to read them but dare not write them). So we idle, waiting for our master to send the three real set commands. When the set intervals command arrives, it changes the value of intervals, the tkwait completes, and we continue.
set h [expr 1.0 / $intervals]
set helper_sum 0
for {set i [expr $proc + 1]} {$i <= $intervals} {incr i $numprocs} {
set x [expr $h * ($i - 0.5)]
set helper_sum [expr $helper_sum + 4.0 / (1.0 + $x*$x)]
set status "Processor $proc, interval = $i, partial sum = $helper_sum"
update idletasks
}
set helper_sum [expr $h * $helper_sum]
set status "Processor $proc, final sum = $helper_sum"This is a straightforward Tcl translation of the Perl--computing
code we saw earlier. It only sums "one numprocs-th" of
the interval, but that's okay, because the other
"numprocs - 1" processors sum the rest. Notice how the
status label is updated in real time, via update
idletasks, just as in Perl/Tk.
while {1} {
catch {send pi.tcl "set sums($proc) $helper_sum"}
after 1000
}Finally, send the partial sum back to the master, who is expecting to see it appear in its sums associative array, indexed by processor number. A Tcl associative array works the same way as a Perl hash; in fact, Perl used to call its hashes associative arrays too, but we all got lazy and shortened the phrase to simply hash (which is more descriptive anyway).
The catch construct ignores errors (perhaps the sendee has ended?) and works just like Tk::catch. The infinite loop, better written with repeat in Perl/Tk, broadcasts our result until the master receives it and kills us. The send is repeated to keep the master from deadlocking, because it's more likely harvesting another processor's result. The next section clarifies matters, as we bring together all the loose ends.
20.2.3. Tcl/Tk Master Processor Code
For brevity, we'll focus only on the three subroutines from pi.tcl that create the user interface (Figure 20-2) and handle the send/receive transactions.
create_interface places the MainWindow on the display and initializes its title and icon name. It then creates the MainWindow's menubar and adds the File menubutton cascade with a Quit menu item. With the exception of having to explicitly define the cascade menu, we do exactly this in Perl/Tk. Underneath the menubar are, essentially, two labeled Entry widgets, which are created from scratch by packing Label and Entry widgets side-by-side in container frames. (We'd use LabEntry widgets in Perl/Tk.) Finally, it packs a Text widget that displays results and a Compute button that initiates a computation.
proc create_interface {} {
wm geometry . "+100+100"
wm title . "Compute pi Using Multiple Processors"
wm iconname . "pi"
# Create menubar, menubuttons, menus and callbacks.
menu .mb
. configure -menu .mb
.mb add cascade -label File -underline 0 -menu .mb.file
menu .mb.file
.mb.file add command -label Quit -command {destroy .}
# Frame to hold itervals label and entry widgets.
frame .f
pack .f -fill x
label .f.s -text "Intervals: "
entry .f.e -width 25 -textvariable intervals
pack .f.s -side left
pack .f.e -side right
# Frame to hold number of processors label and entry widgets.
frame .f2
pack .f2 -fill x
label .f2.s -text "Processors: "
entry .f2.e -width 25 -textvariable numprocs
pack .f2.s -side left
pack .f2.e -side right
# Text widget to hold results.
text .t -width 50 -height 14
pack .t -fill both -expand 1
button .c -text Compute -command {compute_pi}
pack .c
}; # end create_interfacestart_helpers_calculating first executes all the Tk helper programs, which then wait for a start message, as described in the previous section. It records all the process IDs and ensures that all instances of the helper (pihelp.tcl) have different application names (-name) and appear as nicely spaced columns on the display (-geometry). After a 2-second delay, which gives the helpers time to synchronize on their tkwait variable command, it sends each helper three Tcl set commands. After the set intervals command is evaluated in the context of the helpers, they begin computing their partial sums.
In contrast to the Perl way, note that each Tcl variable is local to a subroutine, and global variables must be explicitly declared with a global command (or, you can poke around the call stack using uplevel and upvar).
proc start_helpers_calculating {} {
global helper intervals numprocs pids proc sums
global wishexe
set proc [expr $numprocs - 1]
set y 420
while {$proc > 0} {
set pids($proc) [exec $wishexe -name pihelp${proc} \
-geometry +100+${y} < $helper &]
status "Helper processor $proc started, pid=$pids($proc)."
incr y 50
incr proc [expr -1]
}
after 2000
set proc [expr $numprocs - 1]
while {$proc > 0} {
send pihelp${proc} "set numprocs $numprocs; \
set proc $proc; set intervals $intervals"
incr proc [expr -1]
}
}; # end start_helpers_calculatingsum_reduce simulates a sum reduction, which is a
message-passing operation that reads data from all helper processors
and reduces the results to a single value by summing. It waits for
each helper, in turn, to store its partial sum in the
sums associative array and kills the helper
afterward. Finally, it adds its own partial sum and returns the
reduced result, .
proc sum_reduce {} {
# Do a sum reduction. Fetch all the partial sums computed
# by the helper processors, and then add them to our partial
# sum. The result is an approximation of pi.
global helper intervals numprocs pids proc sums
set pi 0
for {set proc 1} {$proc < $numprocs} {incr proc} {
tkwait variable sums($proc)
status "Partial sum from processor $proc = $sums($proc)."
set pi [expr $pi + $sums($proc)]
exec kill $pids($proc)
}
return [expr $pi + $sums(0)]
}; # end sum_reduceFigure 20-3 shows the outcome.
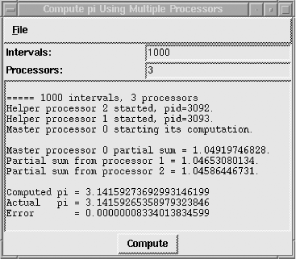
Figure 20-3. An estimated value of pi, with error
|  | |
| 20. IPC with send |  | 20.3. TclRobots |

Copyright © 2002 O'Reilly & Associates. All rights reserved.