
 |  |
3.9. Character Sets and Encodings
No matter how you choose to manage your program's output, you must keep in mind the concept of character encoding -- the protocol your output XML document uses to represent the various symbols of its language, be they an alphabet of letters or a catalog of ideographs and diacritical marks. Character encoding may represent the trickiest part of XML-slinging, perhaps especially so for programmers in Western Europe and the Americas, most of whom have not explored the universe of possible encodings beyond the 128 characters of ASCII.
While it's technically legal for an XML document's encoding declaration to contain the name of any text encoding scheme, the only ones that XML processors are, according to spec, required to understand are UTF-8 and UTF-16. UTF-8 and UTF-16 are two flavors of Unicode, a recent and powerful character encoding architecture that embraces every funny little squiggle a person might care to make.
In this section, we conspire with Perl and XML to nudge you gently into thinking about Unicode, if you're not pondering it already. While you can do everything described in this book by using the legacy encoding of your choice, you'll find, as time passes, that you're swimming against the current.
3.9.1. Unicode, Perl, and XML
Unicode has crept in as the digital age's way of uniting the thousands of different writing systems that have paid the salaries of monks and linguists for centuries. Of course, if you program in an environment where non-ASCII characters are found in abundance, you're probably already familiar with it. However, even then, much of your text processing work might be restricted to low-bit Latin alphanumerics, simply because that's been the character set of choice -- of fiat, really -- for the Internet. Unicode hopes to change this trend, Perl hopes to help, and sneaky little XML is already doing so.
As any Unicode-evangelizing document will tell you,[20] Unicode is great for internationalizing code. It lets programmers come up with localization solutions without the additional worry of juggling different character architectures.
[20]These documents include Chapter 15 of O'Reilly's Programming Perl, Third Edition and the FAQ that the Unicode consortium hosts at http://unicode.org/unicode/faq/.
However, Unicode's importance increases by an order of magnitude when you introduce the question of data representation. The languages that a given program's users (or programmers) might prefer is one thing, but as computing becomes more ubiquitous, it touches more people's lives in more ways every day, and some of these people speak Kurku. By understanding the basics of Unicode, you can see how it can help to transparently keep all the data you'll ever work with, no matter the script, in one architecture.
3.9.2. Unicode Encodings
We are careful to separate the words "architecture" and "encoding" because Unicode actually represents one of the former that contains several of the latter.
In Unicode, every discrete squiggle that's gained
official recognition, from A to  to
to 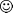 , has its own code point -- a unique positive integer that serves as its address in the whole map of Unicode. For example, the first letter of the Latin alphabet, capitalized, lives at the hexadecimal address 0x0041 (as it does in ASCII and friends), and the other two symbols, the lowercase Greek alpha and the smileyface, are found in 0x03B1 and 0x263A, respectively. A character can be constructed from any one of these code points, or by combining several of them. Many code points are dedicated to holding the various diacritical marks, such as accents and radicals, that many scripts use in conjunction with base alphabetical or ideographic glyphs.
, has its own code point -- a unique positive integer that serves as its address in the whole map of Unicode. For example, the first letter of the Latin alphabet, capitalized, lives at the hexadecimal address 0x0041 (as it does in ASCII and friends), and the other two symbols, the lowercase Greek alpha and the smileyface, are found in 0x03B1 and 0x263A, respectively. A character can be constructed from any one of these code points, or by combining several of them. Many code points are dedicated to holding the various diacritical marks, such as accents and radicals, that many scripts use in conjunction with base alphabetical or ideographic glyphs.
These addresses, as well as those of the tens of thousands (and, in time, hundreds of thousands) of other glyphs on the map, remain true across Unicode's encodings. The only difference lies in the way these numbers are encoded in the ones and zeros that make up the document at its lowest level.
Unicode officially supports three types of encoding, all named UTF (short for Unicode Transformation Format), followed by a number representing the smallest bit-size any character might take. The encodings are UTF-8, UTF-16, and UTF-32. UTF-8 is the most flexible of all, and is therefore the one that Perl has adopted.
3.9.2.1. UTF-8
The UTF-8 encoding, arguably the most Perlish in its impish trickery, is also the most efficient since it's the only one that can pack characters into single bytes. For that reason, UTF-8 is the default encoding for XML documents: if XML documents specify no encoding in their declarations, then processors should assume that they use UTF-8.
Each character appearing within a document encoded with UTF-8 uses as
many bytes as it has to in order to represent that
character's code point, up to a maximum of six
bytes. Thus, the character A, with the itty-bitty address of
0x41, gets one byte to represent it, while our
friend lives way up the street in one of Unicode's blocks of miscellaneous doohickeys, with the address 0x263A. It takes three bytes for itself -- two for the character's code point number and one that signals to text processors that there are, in fact, multiple bytes to this character. Several centuries from now, after Earth begrudgingly joins the Galactic Friendship Union and we find ourselves needing to encode the characters from countless off-planet civilizations, bytes four through six will come in quite handy.
3.9.2.2. UTF-16
The UTF-16 encoding uses a full two bytes to represent the character in question, even if its ordinal is small enough to fit into one (which is how UTF-8 would handle it). If, on the other hand, the character is rare enough to have a very high ordinal, then it gets an additional two bytes tacked onto it (called a surrogate pair), bringing that one character's total length to four bytes.
TIP: Because Unicode 2.0 used a 16-bits-per-character style as its sole supported encoding, many people, and the programs they write, talk about the "Unicode encoding" when they really mean Unicode UTF-16. Even new applications' "Save As..." dialog boxes sometimes offer "Unicode" and "UTF-8" as separate choices, even though these labels don't make much sense in Unicode 3.2 terminology.
3.9.2.3. UTF-32
UTF-32 works a lot like UTF-16, but eliminates any question of variable character size by declaring that every invoked Unicode-mapped glyph shall occupy exactly four bytes. Because of its maximum maximosity, this encoding doesn't see much practical use, since all but the most unusual communication would have significantly more than half of its total mass made up of leading zeros, which doesn't work wonders for efficiency. However, if guaranteed character width is an inflexible issue, this encoding can handle all the million-plus glyph addresses that Unicode accommodates. Of the three major Unicode encodings, UTF-32 is the one that XML parsers aren't obliged to understand. Hence, you probably don't need to worry about it, either.
3.9.3. Other Encodings
The XML standard defines 21 names for character sets that parsers might use (beyond the two they're required to know, UTF-8 and UTF-16). These names range from ISO-8859-1 (ASCII plus 128 characters outside the Latin alphabet) to Shift_JIS, a Microsoftian encoding for Japanese ideographs. While they're not Unicode encodings per se, each character within them maps to one or more Unicode code points (and vice versa, allowing for round-tripping between common encodings by way of Unicode).
XML parsers in Perl all have their own ways of dealing with other encodings. Some may need an extra little nudge. XML::Parser, for example, is weak in its raw state because its underlying library, Expat, understands only a handful of non-Unicode encodings. Fortunately, you can give it a helping hand by installing Clark Cooper's XML::Encoding module, an XML::Parser subclass that can read and understand map files (themselves XML documents) that bind the character code points of other encodings to their Unicode addresses.
3.9.3.1. Core Perl support
As with XML, Perl's relationship with Unicode has heated up at a cautious but inevitable pace.[21] Generally, you should use Perl version 5.6 or greater to work with Unicode properly in your code. If you do have 5.6 or greater, consult its perlunicode manpage for details on how deep its support runs, as each release since then has gradually deepened its loving embrace with Unicode. If you have an even earlier Perl, whew, you really ought to consider upgrading it. You can eke by with some of the tools we'll mention later in this chapter, but hacking Perl and XML means hacking in Unicode, and you'll notice the lack of core support for it.
[21]The romantic metaphor may start to break down for you here, but you probably understand by now that Perl's polyamorous proclivities help make it the language that it is.
Currently, the most recent stable Perl release, 5.6.1, contains partial support for Unicode. Invoking the use utf8 pragma tells Perl to use UTF-8 encoding with most of its string-handling functions. Perl also allows code to exist in UTF-8, allowing identifiers built from characters living beyond ASCII's one-byte reach. This can prove very useful for hackers who primarily think in glyphs outside the Latin alphabet.
Perl 5.8's Unicode support will be much more complete, allowing UTF-8 and regular expressions to play nice. The 5.8 distribution also introduces the Encode module to Perl's standard library, which will allow any Perl programmer to shift text from legacy encodings to Unicode without fuss:
use Encode 'from_to'; from_to($data, "iso-8859-3", "utf-8"); # from legacy to utf-8
Finally, Perl 6, being a redesign of the whole language that includes everything the Perl community learned over the last dozen years, will naturally have an even more intimate relationship with Unicode (and will give us an excuse to print a second edition of this book in a few years). Stay tuned to the usual information channels for continuing developments on this front as we see what happens.
3.9.4. Encoding Conversion
If you use a version of Perl older than 5.8, you'll need a little extra help when switching from one encoding to another. Fortunately, your toolbox contains some ratchety little devices to assist you.
3.9.4.1. iconv and Text::Iconv
iconv is a library and program available for Windows and Unix (inlcuding Mac OS X) that provides an easy interface for turning a document of type A into one of type B. On the Unix command line, you can use it like this:
$ iconv -f latin1 -t utf8 my_file.txt > my_unicode_file.txt
If you have iconv on your system, you can also grab the Text::Iconv Perl module from CPAN, which gives you a Perl API to this library. This allows you to quickly re-encode on-disk files or strings in memory.
3.9.4.2. Unicode::String
A more portable solution comes in the form of the Unicode::String module, which needs no underlying C library. The module's basic API is as blissfully simple as all basic APIs should be. Got a string? Feed it to the class's constructor method and get back an object holding that string, as well as a bevy of methods that let you squash and stretch it in useful and amusing ways. Example 3-12 tests the module.
Example 3-12. Unicode test
use Unicode::String; my $string = "This sentence exists in ASCII and UTF-8, but not UTF-16. Darn!\n"; my $u = Unicode::String->new($string); # $u now holds an object representing a stringful of 16-bit characters # It uses overloading so Perl string operators do what you expect! $u .= "\n\nOh, hey, it's Unicode all of a sudden. Hooray!!\n" # print as UTF-16 (also known as UCS2) print $u->ucs2; # print as something more human-readable print $u->utf8;
The module's many methods allow you to downgrade your strings, too -- specifically, the utf7 method lets you pop the eighth bit off of UTF-8 characters, which is acceptable if you need to throw a bunch of ASCII characters at a receiver that would flip out if it saw chains of UTF-8 marching proudly its way instead of the austere and solitary encodings of old.
WARNING: XML::Parser sometimes seems a little too eager to get you into Unicode. No matter what a document's declared encoding is, it silently transforms all characters with higher Unicode code points into UTF-8, and if you ask the parser for your data back, it delivers those characters back to you in that manner. This silent transformation can be an unpleasant surprise. If you use XML::Parser as the core of any processing software you write, be aware that you may need to use the convertion tools mentioned in this section to massage your data into a more suitable format.
3.9.4.3. Byte order marks
If, for some reason, you have an XML document from an unknown source and have no idea what its encoding might be, it may behoove you to check for the presence of a byte order mark (BOM) at the start of the document. Documents that use Unicode's UTF-16 and UTF-32 encodings are endian-dependent (while UTF-8 escapes this fate by nature of its peculiar protocol). Not knowing which end of a byte carries the significant bit will make reading these documents similar to reading them in a mirror, rendering their content into a garble that your programs will not appreciate.
Unicode defines a special code point, U+FEFF, as the byte order mark. According to the Unicode specification, documents using the UTF-16 or UTF-32 encodings have the option of dedicating their first two or four bytes to this character.[22] This way, if a program carefully inspecting the document scans the first two bits and sees that they're 0xFE and 0xFF, in that order, it knows it's big-endian UTF-16. On the other hand, if it sees 0xFF 0xFE, it knows that document is little-endian because there is no Unicode code point of U+FFFE. (UTF-32's big- and little-endian BOMs have more padding: 0x00 0x00 0xFE 0xFF and 0xFF 0xFE 0x00 0x00, respectively.)
[22]UTF-8 has its own byte order mark, but its purpose is to identify the document at UTF-8, and thus has little use in the XML world. The UTF-8 encoding doesn't have to worry about any of this endianness business since all its characters are made of strung-together byte sequences that are always read from first to last instead of little boxes holding byte pairs whose order may be questionable.
The XML specification states that UTF-16- and UTF-32-encoded documents must use a BOM, but, referring to the Unicode specification, we see that documents created by the engines of sane and benevolent masters will arrive to you in network order. In other words, they arrive to you in a big-endian fashion, which was some time ago declared as the order to use when transmitting data between machines. Conversely, because you are sane and benevolent, you should always transmit documents in network order when you're not sure which order to use. However, if you ever find yourself in doubt that you've received a sane document, just close your eyes and hum this tune:
open XML_FILE, $filename or die "Can't read $filename: $!";
my $bom; # will hold possible byte order mark
# read the first two bytes
read XML_FILE, $bom, 2;
# Fetch their numeric values, via Perl's ord() function
my $ord1 = ord(substr($bom,0,1));
my $ord2 = ord(substr($bom,1,1));
if ($ord1 == 0xFE && $ord2 == 0xFF) {
# It looks like a UTF-16 big-endian document!
# ... act accordingly here ...
} elsif ($ord1 == 0xFF && $ord2 == 0xEF) {
# Oh, someone was naughty and sent us a UTF-16 little-endian document.
# Probably we'll want to effect a byteswap on the thing before working with it.
} else {
# No byte order mark detected.
}You might run this example as a last-ditch effort if your parser complains that it can't find any XML in the document. The first line might indeed be a valid <?xml ... > declaration , but your parser sees some gobbledygook instead.
|  | |
| 3.8. XML::Writer |  | 4. Event Streams |

Copyright © 2002 O'Reilly & Associates. All rights reserved.