
 |  |
2.2. Markup, Elements, and Structure
A markup language provides a way to embed instructions inside data to help a computer program process the data. Most markup schemes, such as troff, TeX, and HTML, have instructions that are optimized for one purpose, such as formatting the document to be printed or to be displayed on a computer screen. These languages rely on a presentational description of data, which controls typeface, font size, color, or other media-specific properties. Although such markup can result in nicely formatted documents, it can be like a prison for your data, consigning it to one format forever; you won't be able to extract your data for other purposes without significant work.
That's where XML comes in. It's a generic markup language that describes data according to its structure and purpose, rather than with specific formatting instructions. The actual presentation information is stored somewhere else, such as in a stylesheet. What's left is a functional description of the parts of your document, which is suitable for many different kinds of processing. With proper use of XML, your document will be ready for an unlimited variety of applications and purposes.
Now let's review the basic components of XML. Its most important feature is the element. Elements are encapsulated regions of data that serve a unique role in your document. For example, consider a typical book, composed of a preface, chapters, appendixes, and an index. In XML, marking up each of these sections as a unique element within the book would be appropriate. Elements may themselves be divided into other elements; you might find the chapter's title, paragraphs, examples, and sections all marked up as elements. This division continues as deeply as necessary, so even a paragraph can contain elements such as emphasized text, quotations, and hypertext links.
Besides dividing text into a hierarchy of regions, elements associate a label and other properties with the data. Every element has a name, or element type, usually describing its function in the document. Thus, a chapter element could be called a "chapter" (or "chapt" or "ch" -- whatever you fancy). An element can include other information besides the type, using a name-value pair called an attribute. Together, an element's type and attributes distinguish it from other elements in the document.
Example 2-1 shows a typical piece of XML.
Example 2-1. An XML fragment
<list id="eriks-todo-47"> <title>Things to Do This Week</title> <item>clean the aquarium</item> <item>mow the lawn</item> <item priority="important">save the whales</item> </list>
This is, as you've probably guessed, a to-do list with three items and a title. Anyone who has worked with HTML will recognize the markup. The pieces of text surrounded by angle brackets ("<" and ">") are called tags, and they act as bookends for elements. Every nonempty element must have both a start and end tag, each containing the element type label. The start tag can optionally contain a number of attributes (name-value pairs like priority="important"). Thus, the markup is pretty clear and unambiguous -- even a human can read it.
A human can read it, but more importantly, a computer program can read it very easily. The framers of XML have taken great care to ensure that XML is easy to read by all XML processors, regardless of the types of tags used or the context. If your markup follows all the proper syntactic rules, then the XML is absolutely unambiguous. This makes processing it much easier, since you don't have to add code to handle unclear situations.
Consider HTML, as it was originally defined (an application of XML's predecessor, SGML).[5] For certain elements, it was acceptable to omit the end tag, and it's usually possible to tell from the context where an element should end. Even so, making code robust enough to handle every ambiguous situation comes at the price of complexity and inaccurate output from bad guessing. Now imagine how it would be if the same processor had to handle any element type, not just the HTML elements. Generic XML processors can't make assumptions about how elements should be arranged. An ambiguous situation, such as the omission of an end tag, would be disastrous.
[5]Currently, XHTML is an XML-legal variant of HTML that HTML authors are encouraged to adopt in support of coming XML tools. XML enables different kinds of markup to be processed by the same programs (e.g., editors, syntax-checkers, or formatters). HTML will soon be joined on the Web by such XML-derived languages as DocBook and MathML.
Any piece of XML can be represented in a diagram called a tree, a structure familiar to most programmers. At the top (since trees in computer science grow upside down) is the root element. The elements that are contained one level down branch from it. Each element may contain elements at still deeper levels, and so on, until you reach the bottom, or "leaves" of the tree. The leaves consist of either data (text) or empty elements. An element at any level can be thought of as the root of its own tree (or subtree, if you prefer to call it that). A tree diagram of the previous example is shown in Figure 2-1.
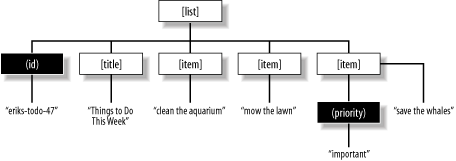
Figure 2-1. A to-do list represented as a tree structure
Besides the arboreal analogy, it's also useful to speak of XML genealogically. Here, we describe an element's content (both data and elements) as its descendants, and the elements that contain it as its ancestors. In our list example, each <item> element is a child of the same parent, the <list> element, and a sibling of the others. (We generally don't carry the terminology too far, as talking about third cousins twice-removed can make your head hurt.) We will use both the tree and family terminology to describe element relationships throughout the book.
|  | |
| 2. An XML Recap |  | 2.3. Namespaces |

Copyright © 2002 O'Reilly & Associates. All rights reserved.